面试官都这么问了,我能说不能吗?
生产服务器变慢了,一般都是从这几点去分析:服务器整体情况, CPU 使用情况,内存,磁盘,磁盘 IO ,网络 IO
一一来说
top
看服务器整体使用情况,一般都是 top 命令搞定
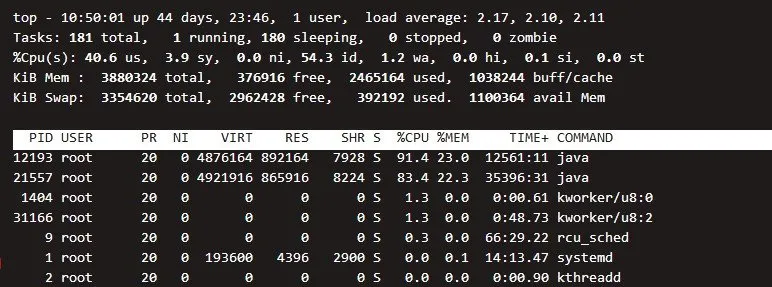
我知道当你看到这张图的时候,肯定有点儿懵,特别是一个个的数字,这都是个啥?
阿粉带你一行一行的看
第 1 行:系统时间、运行时间、登录终端数、系统负载(三个数值分别为1分钟、5分钟、15分钟内的平均值,数值越小意味着负载越低)
第 2 行:进程总数、运行中的进程数、睡眠中的进程数、停止的进程数、僵死的进程数。一般情况下,只要没有僵死的进程,就没啥大问题。
第 3 行:用户占用资源百分比、系统内核占用资源百分比、改变过优先级的进程资源百分比、空闲的资源百分比等。
第 4 行:物理内存总量、内存空闲量、内存使用量、作为内核缓存的内存量
第 5 行:虚拟内存总量、虚拟内存空闲量、虚拟内存使用量、已被提前加载的内存量
第 6 行里面主要看 PID 和 COMMAND 这两个参数,其中 PID 就是进程 ID , COMMAND 就是执行的命令,能够看到比较靠前的两个进程都是 java 进程
在当前这个界面,按下数字键盘 1 能够看到各个 CPU 的详细利用率
vmstat
想要了解 CPU 使用情况的话,常用的命令就是 vmstat 。

一般 vmstat 工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔,单位是秒,第二个参数是采样的次数,阿粉这次的命令是:vmstat -n 3 2意思就是隔 3 秒取样一次,一共取样 2 次
其中主要关注 procs 和 cpu 这两个参数
procs :
- r :运行和等待 CPU 时间片的进程数,一般来说整个系统的运行队列不要超过总核数的 2 倍,要不然系统压力太大了
- b : 等待资源的进程数,比如正在等待磁盘 IO ,网络 IO 这种
cpu :
- us :用户进程消耗 CPU 时间百分比, us 值高的话,说明用户进程消耗 CPU 时间比较长,如果长期大于 50% 的话,那就说明程序还有需要优化的地方
- sy :内核进程消耗的 CPU 时间百分比
- us + sy 参考值为 80% ,如果大于 80% 的话,说明可能存在 CPU 不足
free
查看内存情况用的就是 free , 它主要有三个命令:freefree -gfree -m,阿粉是推荐free -m为啥呢,咱们瞅瞅它们各自的运行结果就知道了
其中:free命令运行结果显示的非常不友好,看到 3880324 可以快速告诉我它是多大吗?free -g这个命令四舍五入了,明明给的内存是 4G ,结果使用free -g一查看,竟然成了 3G ?excuse me ?如果线上环境出问题了,你说因为内存给的不够,运维说,这锅我可不背
相对来说,free -m是比较容易看,而且结果也是比较精确的
如果应用程序可用内存/系统物理内存大于 70% 的话,说明内存是充足的,没啥问题,但是如果小于 20% 的话,就要考虑增加内存了
linux 出错 “INFO: task xxxxxx: 634 blocked for more than 120 seconds.”
现象服务器负载很高,但是CPU利用率不高。服务器经常夯住,网站打不开,SSH连接非常不稳定,输入命令夯住。

一般情况下,linux会把可用内存的40%的空间作为文件系统的缓存。当缓存快满时,文件系统将缓存中的数据整体同步到磁盘中。但是系统对同步时间有最大120秒的限制。如果文件系统不能在时间限制之内完成数据同步,则会发生上述的错误。这通常发生在内存很大的系统上。系统内存大,则缓冲区大,同步数据所需要的时间就越长,超时的概率就越大。
解决方法:缩小文件系统缓存大小
此种方案是降低缓存占内存的比例,比如由40%降到10%,这样的话需要同步到磁盘上的数据量会变小,IO写时间缩短,会相对比较平稳。
文件系统缓存的大小是由内核参数vm.dirty_ratio 和 vm.dirty_backgroud_ratio控制决定的。
vm.dirty_background_ratio指定当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存。
vm.dirty_ratio则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存),在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
通常情况下,vm.dirty_ratio的值要大于vm.dirty_background_ratio的值。
下面说一下修改这两个参数的流程。
(1)首先查看系统当前的vm.dirty_ratio 和 vm.dirty_ background_ratio的值。
sysctl -a | grep dirty
由上可知,当前环境下,vm.dirty_ratio=20 ,vm.dirty_ background_ratio=10。在此情况下,会出现上述问题。
(2)修改vm.dirty_ratio和vm.dirty_ background_ratio的值。
把vm.dirty_ratio修改为10 ,vm.dirty_background_ratio修改为5。在命令行输入如下命令:
./sbin/sysctl -w vm.dirty_ratio=10
./sbin/sysctl -w vm.dirty_background_ratio=5
(3)使参数修改立即生效。
sysctl -p
(4)永久修改内核参数
可以修改系统信息配置文件sysctl.conf,此配置文件在/etc目录下。打开配置文件在最后添加如下两行代码:
vm.dirty_background_ratio=5
vm.dirty_ratio=10
手动释放内存
/proc/sys/vm/drop_caches (since Linux 2.6.16) Writing to this file causes the kernel to drop clean caches, dentries and inodes from memory, causing that memory to become free.
To free pagecache, use echo 1 > /proc/sys/vm/drop_caches; to free dentries and inodes, use echo 2 > /proc/sys/vm/drop_caches; to free pagecache, dentries and inodes, use echo 3 > /proc/sys/vm/drop_caches.
Because this is a non-destructive operation and dirty objects are not freeable, the user should run sync first. (尽量不要更改内核参数)
在释放之前,通过sync命令将内存同步到磁盘
MESSAGE导致内存变大
原因是syslog记录了许多Info日志,而应用程序因不严谨也会被统计到Message里面去,处理方法是清空 /var/log/messages,重启systemctl restart rsyslog
df
如果排查磁盘问题的话,首先要看的就是磁盘空间够不够,还记得阿粉在上家公司的时候,用的还是 svn 出现了一个很神奇的问题,就是哪里都不报错,就是提交不上代码,排查到最后是磁盘空间不够...
所以别问阿粉为啥排查磁盘问题时,第一就是看磁盘空间够不够!!!
查看磁盘空间就是df或者df -h这两个命令了
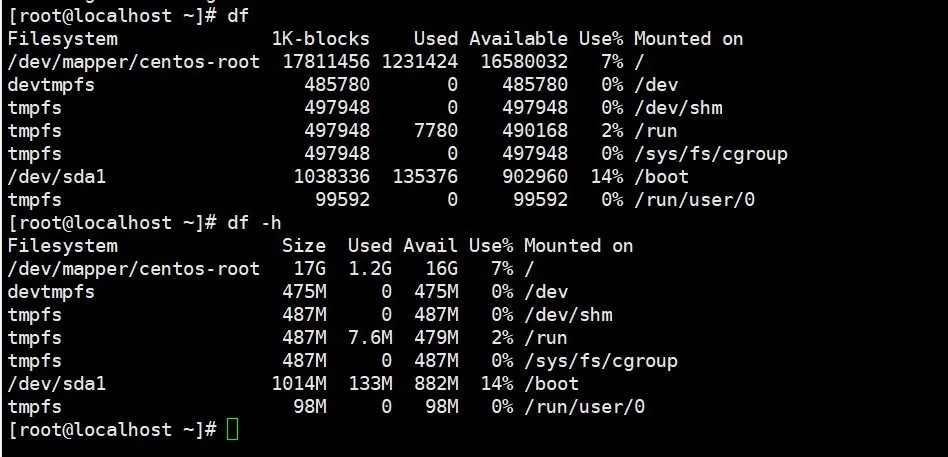
还有一种情况是Inodes节点用完,无法创建文件,找到较多的文件删除就可以释放掉
iostat
说到磁盘 IO 相信你一定能够想到,在对数据库进行操作时,第一要考虑到的就是磁盘 IO 操作,因为相对来说,如果在某个时间段给磁盘进行大量的写入操作会造成程序等待时间长,导致客户端那边好久都没啥反应,用户体验就降低了吗
检查磁盘 IO 情况的命令就是 iostat ,如果你用的时候发现提示:-bash: iostat: command not found,那是因为没有安装 sysstat ,安装一下就可以了:yum install -y sysstat
接下来运行命令:iostat -xdk 3 2,和vmstat命令很像有没有~
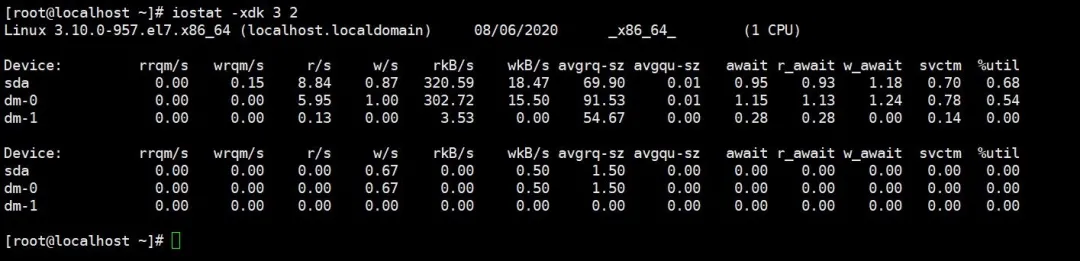
这么多指标咱们不需要都关注,只要看其中这几个就可以了:
- rkB/s :每秒读取数据量 kB ;
- wkB/s :每秒写入数据量 kB ;
- svctm :I/O 请求的平均服务时间,单位毫秒;
- util :一秒中有百分之几的时间用于 I/O 操作,如果接近 100% 说明磁盘带宽跑满了,这个时候就要优化程序或者增加磁盘了
sar
网络 IO 的话,可以通过sar -n DEV 3 2这条命令来看,和上面的差不多,意思就是每隔 3 秒取样一次,一共取样 2 次。
其中:
- IFACE :LAN 接口
- rxpck/s :每秒钟接收的数据包
- txpck/s :每秒钟发送的数据包
- rxKB/s :每秒接收的数据量,单位 KByte
- txKB/s :每秒发出的数据量,单位 KByte
- rxcmp/s :每秒钟接收的压缩数据包
- txcmp/s :每秒钟发送的压缩数据包
- rxmcst/s:每秒钟接收的多播数据包
这种方式特别简单直观,对新手来说比较容易看到
OK ,下次面试官问你生产服务器变慢了,你能谈谈诊断思路吗?咋不能呢,从服务器整体情况开始说,一直到网络 IO ,再也不怕和面试官扯皮了