分词(tokenizing)
对于一个句子,首先需要将其分为多个单词或多个词组。
例如, “I come from New York" => "I/come from/New York"
通过标准语料库,为了简化计算,通常使用马尔科夫假设,即每一个分词出现的概率仅仅和前一个分词有关,可以近似的计算出所有的分词之间的二元条件概率。
利用语料库建立的统计概率,对于一个新的句子,我们就可以通过计算各种分词方法对应的联合分布概率,找到最大概率对应的分词方法,即为最优分词。
常用的分词工具
向量化(vectorize)与Hash Trick
词袋模型
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。向量化完毕后一般也会使用TF-IDF进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习算法进行分类聚类了。
每一维的向量依次对应了下面的19个词。另外由于词"I"在英文中是停用词,不参加词频的统计。一共有19个词,所以4个文本都是19维的特征向量。
["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
###
[[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0]
[0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0]
[1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
由于大部分的文本都只会使用词汇表中的很少一部分的词,因此我们的词向量中会有大量的0。也就是说词向量是稀疏的。在实际应用中一般使用稀疏矩阵来存储。
由于词汇量很大,所以向量化后的维度就很大,将对应的样本对应特征矩阵载入内存,有可能将内存撑爆,要进行特征的降维,而Hash Trick就是非常常用的文本特征降维方法。
Hash Trick 降维
在Hash Trick里,我们会定义一个特征Hash后对应的哈希表的大小,这个哈希表的维度会远远小于我们的词汇表的特征维度,因此可以看成是降维。具体的方法是,对应任意一个特征名,我们会用Hash函数找到对应哈希表的位置,然后将该特征名对应的词频统计值累加到该哈希表位置。
如果用数学语言表示,假如哈希函数h使第i个特征哈希到位置j,即h(i)=j,则第i个原始特征的词频数值ϕ(i)将累加到哈希后的第j个特征的词频数值ϕ上 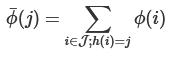
TF-IDF (Term Frequency - Inverse Document Frequency)
- TF 词频统计:文本中各个词的出现频率统计。
- IDF 逆文本频率:N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数。
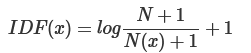
由以上可得,TF−IDF(x)=TF(x)∗IDF(x)
TF-IDF是非常常用的文本挖掘预处理基本步骤,但是如果预处理中使用了Hash Trick,则一般就无法使用TF-IDF了,因为Hash Trick后我们已经无法得到哈希后的各特征的IDF的值。使用了IF-IDF并标准化以后,我们就可以使用各个文本的词特征向量作为文本的特征,进行分类或者聚类分析。
英文文本挖掘预处理
-
除去数据中非文本部分:直接用Python的正则表达式(re)删除
-
拼写检查:pyenchant
-
拼写更正:pyspellchecker
-
词干提取(stemming)和词形还原(lemmatization): 在实际的英文文本挖掘预处理的时候,建议使用基于wordnet的词形还原就可以。nltk中的WordNetLemmatizer类
-
转化为小写:lower()
-
引入停用词: 在英文文本中有很多无效的词,比如“a”,“to”,一些短词,还有一些标点符号,这些我们不想在文本分析的时候引入,因此需要去掉,这些词就是停用词。download link
-
特征处理: [1] Sklearn中的TfidfVectorizer类可以帮助我们完成向量化,TF-IDF和标准化三步。[2] word2vec