-
异步、接口、削峰
-
每个Broker启动时都要向所有的Namesrv注册。
-
MQ的生产者和消费者都是主动去Namesrv拉取Broker路由信息。
-
Broker会每隔30秒向所有的Namserver发送心跳。同时Namesrv会每隔10s运行一个任务,检查Broker最近一次心跳时间,若某个Broker超过120s都没发送心跳,那么就认为这个Broker挂了。
-
若Broker挂了,那么生产者如何感知到挂了呢?重试3次,循环负载。其中一台broker挂了,如果存在另外一台broker有这个topic则往这台发送。可以布署多组master,slave。每组master都有这个topic。这样保证某个组的broker master挂了后,业务还能正常进行。
-
整个MQ的功能实际上全部体现在Broker上面,通过Broker主从架构来解决可用性,Slave不断地主动向Master拉取消息。
-
MQ实现读写分离了吗?实际上消费者拉取消息的时候,有可能是在Master节点拉取,也有可能在Slave节点拉取。作为消费者的系统在获取消息的时候会先发送请求到Master Broker上去,请求获取一批消息,此时Master Broker是会返回一批消息给消费者系统的。然后Master Broker在返回消息给消费者系统的时候,会根据当时Master Broker的负载情况和Slave Broker的同步情况,向消费者系统建议下一次拉取消息的时候是从Master Broker拉取还是从Slave Broker拉取。
举个例子,要是这个时候Master Broker负载很重,本身要抗10万写并发了,你还要从他这里拉取消息,给他加重负担,那肯定是不合
适的。
所以此时Master Broker就会建议你从Slave Broker去拉取消息。
-
若Slave挂掉了,有什么影响?读写压力全来到Master节点。
-
MQ不能完成Master和slave的自动切换。
若master挂了,如何切换?需要运维人员手动修改slave的一些配置,将其转换为master。所以这种模式不是彻底的高可用。
在4.5版本之后,加入了Dledger(基于Raft)实现高可用自动切换
-
Broker主从同步有没有数据不一致的问题?
-
下订单功能的异步优化处理:
下订单一般包括下面几个步骤:
更改订单状态、扣库存、增加级分、发优惠券、发短信、通知收货。
其实我们可以将除更改订单状态和扣库存等核心环节修改为异步调用就可以提高性能。
-
什么是Push模式和Pull模式?
Push模式是Broker主动将消息推送给消费者;
Pull模式是消费者主动去Broker拉取消息。
-
大数据的几百行SQL直接查询数据库造成数据库负载100%,如何避免?
在订单系统修改订单数据库的时候,同时发送消息到MQ中,数仓消费消息,落库到自己的数仓,统计的时候统计数仓自己的数据库。
那么消息体是什么结构呢?
简单的可以将对订单库的增删改操作都发送到MQ中,另一种方案是利用canel同步binlog日志到MQ中。
-
高并发系统下的秒杀结构:
简单粗暴的方式是直接扩展数据库,利用负载均衡落库。
但成本较高。
高并发秒杀可以分为2部分:高并发读和高并发写
高并发读中的页面部分可以通过页面静态化处理,提前就从数据库里把这个页面需要的数据都提取出来组装
成一份静态数据放在别的地方,避免每次访问这个页面都要访问后端数据库。CDN + Nginx + Redis的多级缓存架构
- 不同地方的用户在加载这个秒杀商品的详情页数据时,都是从就近的CDN上加载的,不需要每次请求都发送到我们公司在上海的机
房去。 - Nginx中是可以基于Lua脚本实现本地缓存的,我们可以提前把秒杀商品详情页的数据放到Nginx中进行缓存,如果请求发送过来,
可以从Nginx中直接加载缓存数据,不需要把请求转发到我们商品系统上去。 - Nginx中的Lua脚本发送请求到Redis集群中去加载我们提前放进去的秒杀商品数据。
- 不同地方的用户在加载这个秒杀商品的详情页数据时,都是从就近的CDN上加载的,不需要每次请求都发送到我们公司在上海的机
-
基于Redis实现下单时精准扣库存:
如果还是由订单系统直接调用库存服务的接口,那么势必会造成瞬时压力过大。
通常在秒杀场景下,一般会将每隔秒杀商品的库存写入到Redis中,当请求过来时,就直接对Redis中的库存进行扣除。如果发现库存没了就无法抢购到商品了。
抢购完毕后提前过滤无效请求?
一旦商品抢购完毕,可以在ZooKeeper中写入一个秒杀完毕的标志位,然后ZK会反向通知Nginx中我们自己写的Lua脚本,通过
Lua脚本后续在请求过来的时候直接过滤掉,不要向后转发了。 -
瞬时高并发下单请求进入MQ:
对于秒杀系统而言,如果判断发现通过Redis完成了库存扣减,此时库存还大于0,说明成功,需要创建订单,此时就直接发送一个消息到MQ中,然后让订单系统消费消息进行常规性的流程处理。比如创建订单等等。这样瞬时压力来到MQ这边。
-
Topic、MessageQueue以及Broker之间到底是什么关系?
简单理解,MessageQueue就是Broker的数据分片。
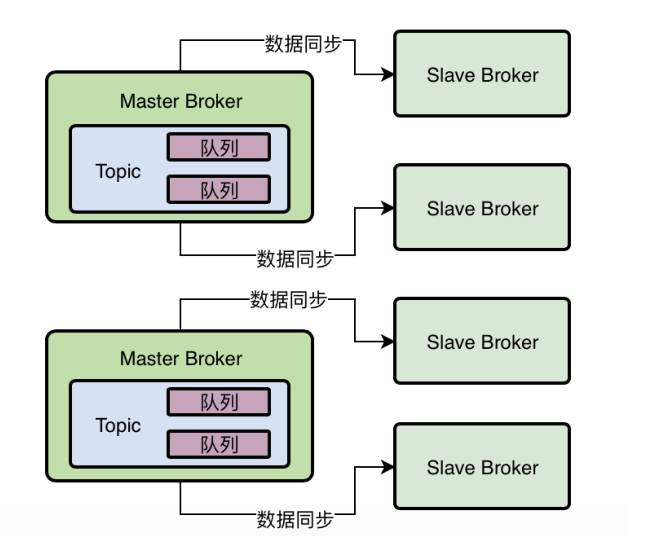
-
生产者发送消息的时候写入哪个MessageQueue?
生产者会跟NameSrv进行通信获取Topic路由数据。所以生产者知道一个topic下面由几个messagequeue,那些messagequeue在哪写机器上。
-
如果某个Broker挂了怎么办?
若Master挂了,那么需要等待Slave自动切换为Master,在这期间,对这一组的Broker就没有Master可以写入了。
通常来说,生产者有一个开关sendLatencyFaultEnable,建议打开,打开后有一个容错机制,比如某一次访问一个broker发现有网络延迟500ms还无法访问,那么就会自动回避访问这个Broker一段时间,比如接下来3000ms内,就不会访问这个broker了。
-
CommitLog顺序写入机制
broker收到消息后,会把消息直接写入到磁盘的一个日志文件,就做CommitLog,直接顺序写入这个文件。
CommitLog是很多磁盘文件,每个文件限定最多1G,收到消息后直接追加文件的末尾,当写满时,会创建一个新的。
-
MessageQueue在数据存储体现在ConsumerQueue文件中。
$HOME/store/consumequeue/{topic}/{queueId}/{fileName}
{topic}指代的就是某个Topic,
{queueId}指代的就是某个MessageQueue。
然后对存储在这台Broker机器上的Topic下的一个MessageQueue,他有很多的ConsumeQueue文件,这个ConsumeQueue文件里
存储的是一条消息对应在CommitLog文件中的offset偏移量、消息长度、tag的hashcode,一条数据是20字节。 -
Broker写性能
通过OS的pageCache和顺序写来提高性能的。
数据写入的时候,并不是直接写磁盘的,而是先写入到OS的pageCache中,然后起一个异步线程将缓存中的数据写入到磁盘中。
-
同步刷盘和异步刷盘的使用场景:
异步刷盘可以提高较高的写入吞吐量,但有丢失数据的风险;
同步刷盘有低吞吐量的风险,但是保证数据不会丢失。
-
Dledger技术
实际上是一种CommitLog机制,不再有Broker节点来管理CommitLog,而是每个Broker节点都有自己的Dledger组件,有这个Dledger来管理CommitLog,基于Raft选举选出Leader。
简单来说,他确保有人可以成为Leader的核心机制就是一轮选举不出来Leader的话,
就让大家随机休眠一下,先苏醒过来的人会投票给自己,其他人苏醒过后发现自己收到选票了,就会直接投票给那个人。只有Leader可以接收数据写入,Follower只能接收Leader同步过来的数据。
首先Leader收到消息后,持久化消息时会将消息的状态设为uncommit状态,然后消息同步给其他节点,其他节点持久化之后需要返回ack给leader,leader收到超半数以上节点的ack后,会将消息设为commited状态。
-
集群模式/广播模式
集群模式:一个消费者组获取到一个消息,只会交给组内的一台机器去处理,不是每台机器都可以获取到这条消息的。
广播模式:组内的每台集器都可以收到这条消息。
原则:一个MessageQueue只能被一个消费者消费,一个消费者可以消费多个MessageQueue,也就是说MessageQueue >= 消费者
-
Push模式如何保证消息的实时性?请求挂起和长轮询
请求挂起:
当请求来到Broker时,会检查是否有消息加入,如果没有,就会将请求挂起,等到有新消息加入时才会将请求唤醒,然后把消息响应。
-
消费者机器如何处理消息、进行ACK以及提交消息消费进度
当处理完消息后,消费者机器会提交我们目前的一个消费进度去Broker中,然后我们就会存储消息进度。
-
消费者刚开始的时候都是从Master节点拉取的消息,如果master节点觉得自己负载比较高,就会告知消费者机器,下次可以从slave节点获取。
-
事务消息就是生产者发送一个half消息给Broker,Broker收到half消息后落盘,但是此时消费者是看不到half消息的,等到Broker成功将half落盘之后会回调生产者的接口,查看是否执行成功,如果执行成功,broker会将消息设为commit状态,最终消费者就可以看到这个消息了。如果长时间没有收到生产者的回应就会重试调用接口。
写入的half消息默认是在”RMQ_SYS_TRANS_HALF_TOPIC“topic中的,所以消费者看不到。
如果是rollback,那么broker会在”OP_TOPIC“ 的topic中写入一个消息,代表这条消息已经rollback了。
假设你一直没有执行commit/rollback,RocketMQ会回调订单系统的接口去判断half消息的状态,但是他最多就
是回调15次,如果15次之后你都没法告知他half消息的状态,就自动把消息标记为rollback。执行rollback完成之后,就会将”OP_TOPIC“的消息表示为commit状态,接着需要把放在RMQ_SYS_TRANS_HALF_TOPIC中的half消息给写入到指定的topic和队列中去。
-
实现全链路消息零丢失方案:
生产发送消息:
- 同步消息+重试
- 事务消息机制
MQ收到消息零丢失:
开启同步刷盘+主从架构同步机制
消费消息的零丢失:
天然可以保证消息零丢失,只需记住不要异步处理消息异步返回ack即可。
以上方案都是有极大的性能损耗,使用场景是金钱、交易等核心链路的情景才适合。
-
如果Comsumer处理完消息,会返回ack并且提交offset给broker。
-
如果Comsumer消费消息没有返回ack,那么broker会重试16次,若仍无法处理,那么这条消息就会进入死信队列。
-
(数仓利用mq,以canel的方式同步订单数据库数据到自己的数仓)当发送的消息是顺序消息时,需要保证这个消息如果消费失败,不能进入死信队列,否则又会造成顺序错乱的问题。因此消费者如果消费失败,返回
SUSPEND_CURRENT_QUEUE_A_MOMENT这个状态。 -
(数仓利用mq,以canel的方式同步订单数据库数据到自己的数仓)mq的tag过滤可用于数仓来同步不同的表,一个tag对应一张表名。
-
mq的延时消息可用于未支付的订单失效的问题。用户下单后30min,如果仍未支付,那么该订单视为过期订单,需要将订单删除。
-
mq生产上的一些经验:
-
利用tag机制来过滤消息
-
基于消息key来定位消息是否丢失
我们可以通过给message设置key的方式来给message加上标识,然后消息在落盘的时候,也会以key的hash值来建立索引,保存在IndexFile中,然后是我们可以通过mqadmin命令来查看消息是否落盘。
-
MQ集群宕机造成消息丢失,需要生产者将消息保存到数据库或者本地磁盘文件中,作冷备,等mq集群恢复正常后在发送消息。
-
提高消费者消费的吞吐量
增加消费者节点,当然也要增加MessageQueue,因为meaagesqueue只能被一个消费者消费,一个消费者可以消费多个messagequeue。
除此之外,还可以设置消费者一次消费消息的数量,默认为1,可以适当增加这个值。
-
要不要消费历史消息
其实consumer是支持设置从哪里开始消费消息的,常见的有两种:一个是从Topic的第一条数据开始消费,一个是从最后一次消费过
的消息之后开始消费。对应的是:CONSUME_FROM_LAST_OFFSET,CONSUME_FROM_FIRST_OFFSET。一般来说,我们都会选择CONSUME_FROM_FIRST_OFFSET,这样你刚开始就从Topic的第一条消息开始消费,但是以后每次重启,
你都是从上一次消费到的位置继续往后进行消费的。
-
-
消息轨迹追溯:我们想要知道消息最终由那么broker落盘,被哪个consumer消费,我们需要开启这个功能需要修改
traceTopicEnable=true这一选项。然后创建生产者和消费者组的时候需要将第二个参数设为true,broker检测到需要追溯的消息会自动创建一个RMQ_SYS_TRACE_TOPIC,用来存储所有的消息轨迹追踪的数据。 -
金融级别高可用方案:
你需要在发送消息时增加trycatch,每次捕获异常时,需要增加重试机制,当重试仍然失败时,需要将消息存储到本地磁盘或者数据中,但是需要保证顺序性。
-
消费者端也要做好限流的措施。令牌桶算法。