背景
2016年Q3季度初,在美团外卖上单2.0项目上线后,商家和商品数量急速增长,预估商品库的容量和写峰值QPS会很快遇到巨大压力。随之而来也会影响线上服务的查询性能、DB(数据库,以下统一称DB)主从延迟、表变更困难等一系列问题。
要解决上面所说的问题,通常有两种方案。第一种方案是直接对现有的商品库进行垂直拆分,可以缓解目前写峰值QPS过大、DB主从延迟的问题。第二种方案是对现有的商品库大表进行分库分表,从根本上解决现有问题。方案一实施起来周期较短,但只能解决一时之痛,由此可见,分库分表是必然的。
在确定分库分表的方案之后,我们调研了外卖订单、结算以及主站等业务的分库分表实现方案,也调研了业界很多分库分表中间件。在综合考虑性能、稳定性及实现成本的前提下,最终决定自主研发客户端分库分表中间件MTDDL来支撑外卖商品分库分表项目,这也就是MTDDL的由来。
当然,在MTDDL的设计研发过程中,我们充分考虑了MTDDL的通用性、可扩展性、功能的全面性和接入的便利性。到目前为止一共开发了四期,实现了MySQL动态数据源、读写分离、分布式唯一主键生成器、分库分表、连接池及SQL监控、动态化配置等一系列功能,支持分库分表算法、分布式唯一主键生成算法的高可扩展性,而且支持全注解的方式接入,业务方不需要引入任何配置文件。
下面就部分业界方案及MTDDL的设计目标详细展开下,然后从源码的角度来剖析下MTDDL的整个逻辑架构和具体实现。
业界调研
| 业界组件 | 简介 | 实现方案 | 功能特性 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Atlas | Qihoo 360开发维护的一个基于MySQL协议的数据中间层项目。它实现了MySQL的客户端与服务端协议,作为服务端与应用程序通信,同时作为客户端与MySQL通信 | proxy-based | 实现读写分离、单库分表 | 功能简单,性能跟稳定性较好 | 不支持分库分表 |
| MTAtlas | 原美团DBA团队在开源Atlas基础上做的一系列升级改造 | proxy-based | 在读写分离、单库分表的基础上,完成了分库分表的功能开发 | 在Atlas基础上支持了分库分表 | 当时还处于测试阶段,暂不推荐业务方使用 |
| TDDL | 淘宝根据自己的业务特点开发了TDDL框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的JDBC datasource实现 | client-based | 实现动态数据源、读写分离、分库分表 | 功能齐全 | 分库分表功能还未开源,当前公布文档较少,并且需要依赖diamond(淘宝内部使用的一个管理持久配置的系统) |
| Zebra | Zebra是原点评内部使用数据源、DAO以及监控等和数据库打交道的中间件集 | client-based | 实现动态数据源、读写分离、分库分表、CAT监控 | 功能齐全且有监控 | 接入较为复杂,当时只支持c3p0、Druid、Tomcat JDBC等连接池,且分库分表算法只支持Groovy表达式不易扩展 |
设计目标
MTDDL(Meituan Distributed Data Layer),美团点评分布式数据访问层中间件,旨在为全公司提供一个通用数据访问层服务,支持MySQL动态数据源、读写分离、分布式唯一主键生成器、分库分表、动态化配置等功能,并且支持从客户端角度对数据源的各方面(比如连接池、SQL等)进行监控,后续考虑支持NoSQL、Cache等多种数据源。
功能特性
- 动态数据源
- 读写分离
- 分布式唯一主键生成器
- 分库分表
- 连接池及SQL监控
- 动态化配置
逻辑架构
下图是一次完整的DAO层insert方法调用时序图,简单阐述了MTDDL的整个逻辑架构。其中包含了分布式唯一主键的获取、动态数据源的路由以及SQL埋点监控等过程:
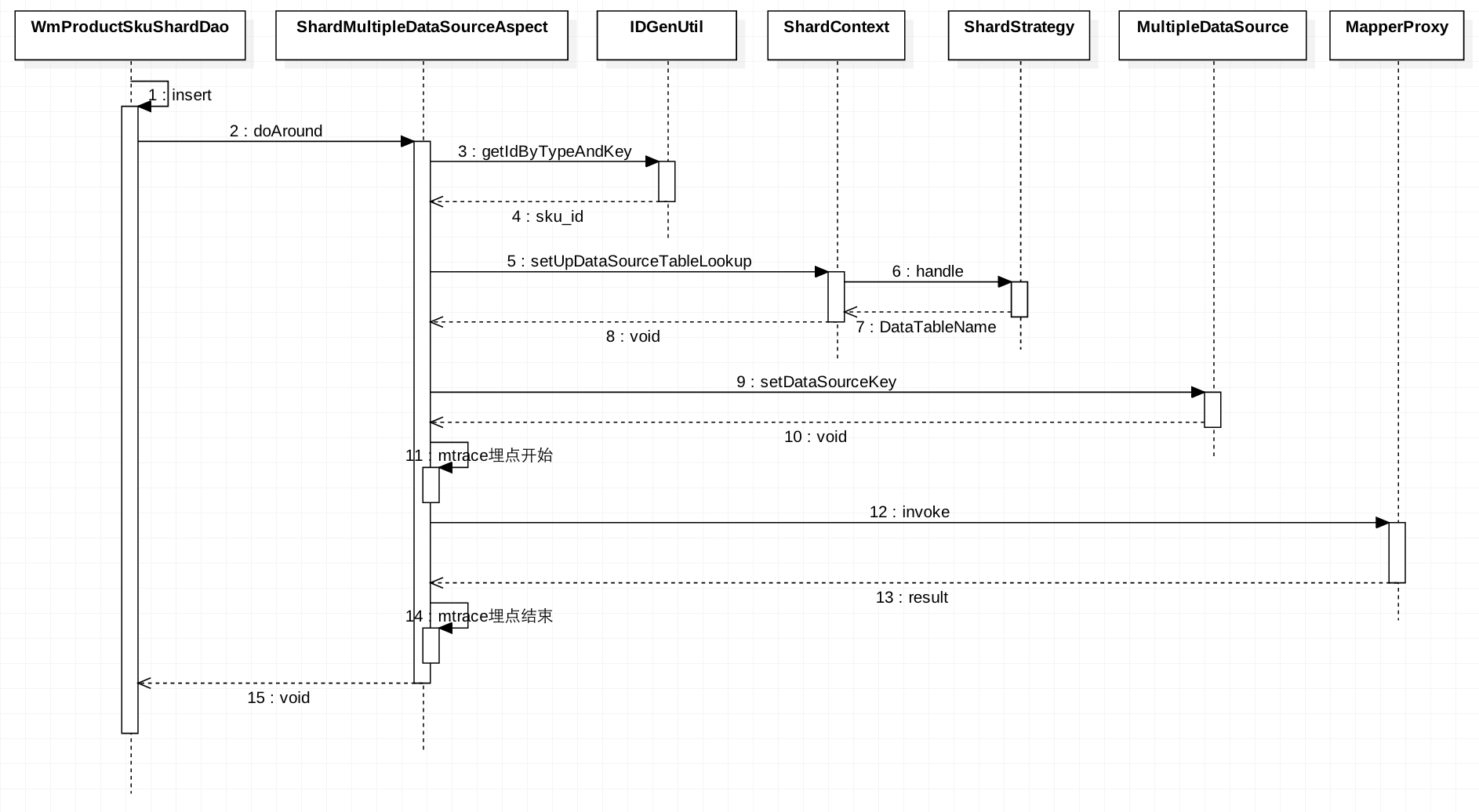
具体实现
动态数据源及读写分离
在Spring JDBC AbstractRoutingDataSource的基础上扩展出MultipleDataSource动态数据源类,通过动态数据源注解及AOP实现。
动态数据源
MultipleDataSource动态数据源类,继承于Spring JDBC AbstractRoutingDataSource抽象类,实现了determineCurrentLookupKey方法,通过setDataSourceKey方法来动态调整dataSourceKey,进而达到动态调整数据源的功能。其类图如下:
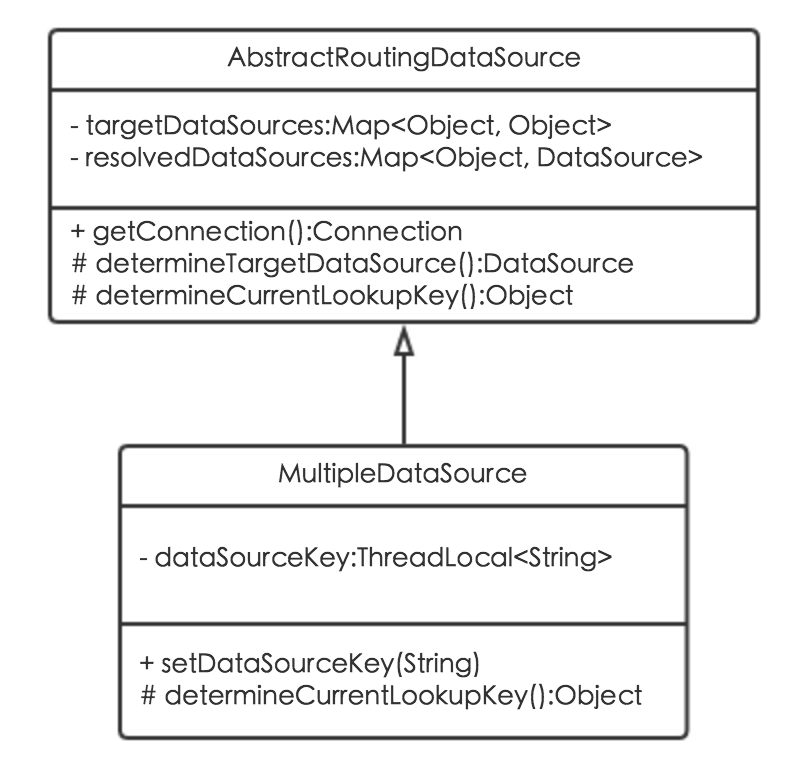
动态数据源AOP
ShardMultipleDataSourceAspect动态数据源切面类,针对DAO方法进行功能增强,通过扫描DataSource动态数据源注解来获取相应的dataSourceKey,从而指定具体的数据源。具体流程图如下:
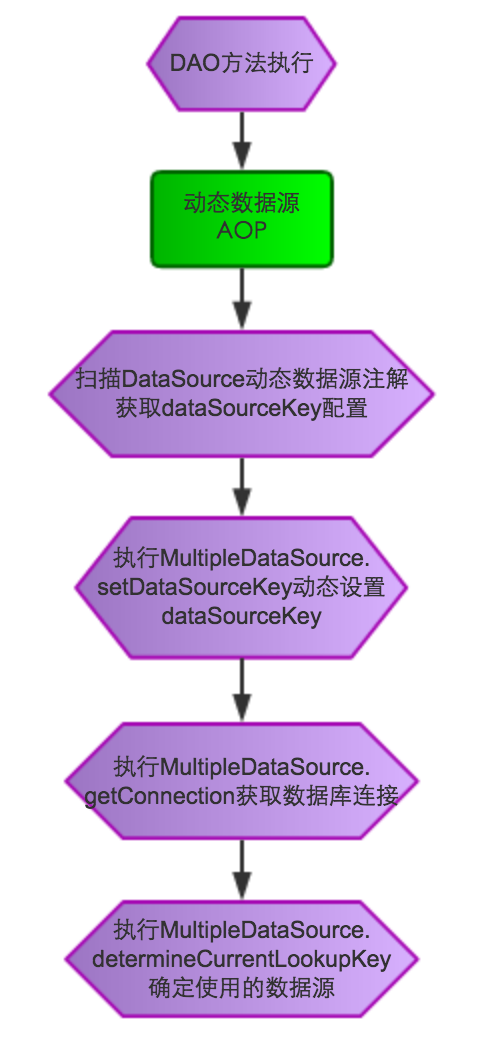
配置和使用方式举例
/**
* 参考配置
*/
<bean id="multipleDataSource" class="com.sankuai.meituan.waimai.datasource.multi.MultipleDataSource">
/** 数据源配置 */
<property name="targetDataSources">
<map key-type="java.lang.String">
/** 写数据源 */
<entry key="dbProductWrite" value-ref="dbProductWrite"/>
/** 读数据源 */
<entry key="dbProductRead" value-ref="dbProductRead"/>
</map>
</property>
</bean>
/**
* DAO使用动态数据源注解
*/
public interface WmProductSkuDao {
/** 增删改走写数据源 */
@DataSource("dbProductWrite")
public void insert(WmProductSku sku);
/** 查询走读数据源 */
@DataSource("dbProductRead")
public void getById(long sku_id);
}
分布式唯一主键生成器
众所周知,分库分表首先要解决的就是分布式唯一主键的问题,业界也有很多相关方案:
| 序号 | 实现方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | UUID | 本地生成,不需要RPC,低延时; 扩展性好,基本没有性能上限 |
无法保证趋势递增; UUID过长128位,不易存储,往往用字符串表示 |
| 2 | Snowflake或MongoDB ObjectId | 分布式生成,无单点; 趋势递增,生成效率快 |
没有全局时钟的情况下,只能保证趋势递增; 当通过NTP进行时钟同步时可能会出现重复ID; 数据间隙较大 |
| 3 | proxy服务+数据库分段获取ID | 分布式生成,段用完后需要去DB获取,同server有序 | 可能产生数据空洞,即有些ID没有分配就被跳过了,主要原因是在服务重启的时候发生; 无法保证有序,需要未来解决,可能会通过其他接口方案实现 |
综上,方案3的缺点可以通过一些手段避免,但其他方案的缺点不好处理,所以选择第3种方案。目前该方案已由美团点评技术工程部实现——分布式ID生成系统Leaf,MTDDL集成了此功能。
分布式ID生成系统Leaf
美团点评分布式ID生成系统Leaf,其实是一种基于DB的Ticket服务,通过一张通用的Ticket表来实现分布式ID的持久化,执行update更新语句来获取一批Ticket,这些获取到的Ticket会在内存中进行分配,分配完之后再从DB获取下一批Ticket。整体架构图如下:
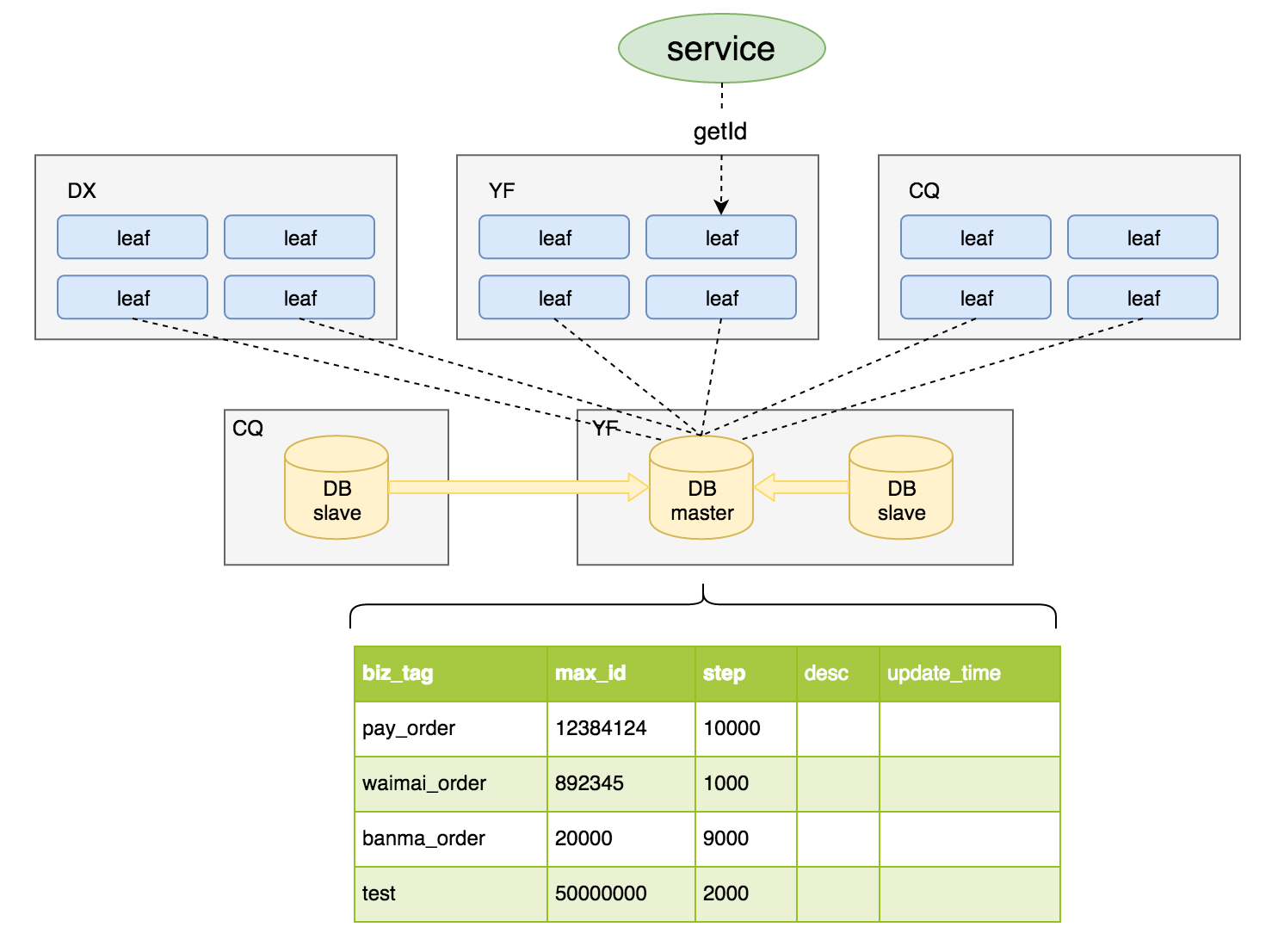
每个业务tag对应一条DB记录,DB MaxID字段记录当前该Tag已分配出去的最大ID值。
IDGenerator服务启动之初向DB申请一个号段,传入号段长度如 genStep = 10000,DB事务置 MaxID = MaxID + genStep,DB设置成功代表号段分配成功。每次IDGenerator号段分配都通过原子加的方式,待分配完毕后重新申请新号段。
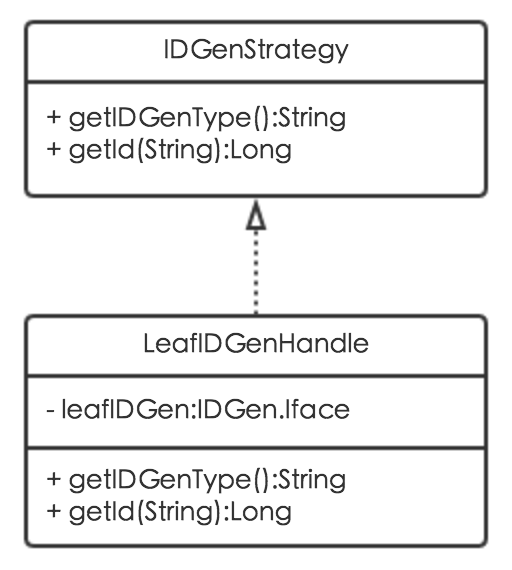
唯一主键生成算法扩展
MTDDL不仅集成了Leaf算法,还支持唯一主键算法的扩展,通过新增唯一主键生成策略类实现IDGenStrategy接口即可。IDGenStrategy接口包含两个方法:getIDGenType用来指定唯一主键生成策略,getId用来实现具体的唯一主键生成算法。其类图如下:
分库分表
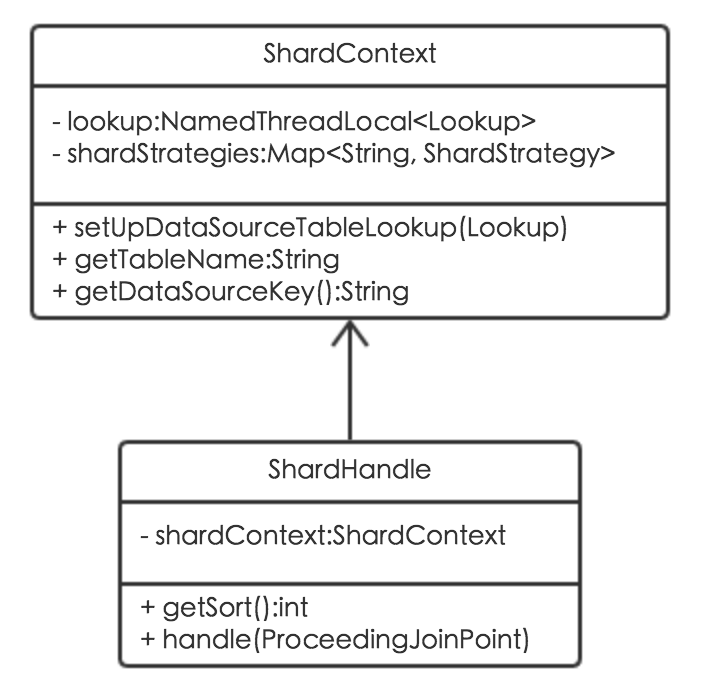
在动态数据源AOP的基础上扩展出分库分表AOP,通过分库分表ShardHandle类实现分库分表数据源路由及分表计算。ShardHandle关联了分库分表上下文ShardContext类,而ShardContext封装了所有的分库分表算法。其类图如下:
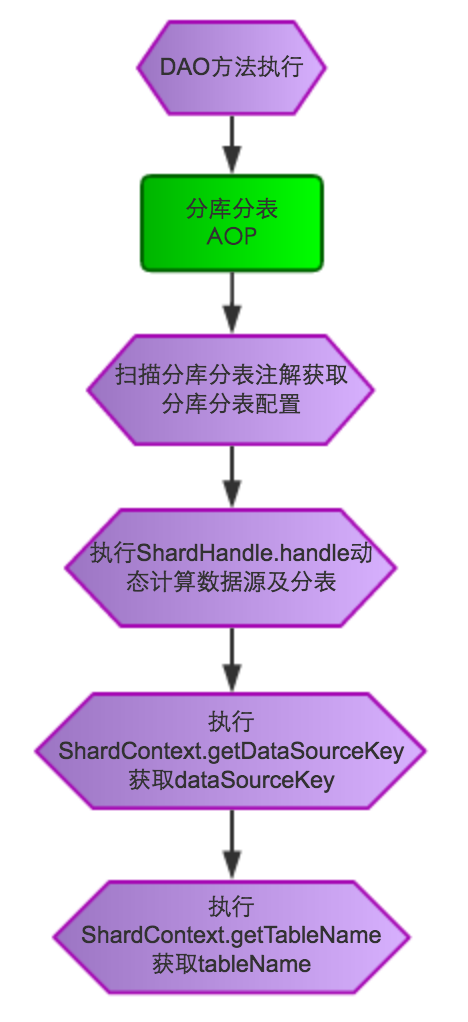
分库分表流程图如下:
分库分表取模算法
分库分表目前默认使用的是取模算法,分表算法为 (#shard_key % (group_shard_num * table_shard_num)),分库算法为 (#shard_key % (group_shard_num * table_shard_num)) / table_shard_num,其中group_shard_num为分库个数,table_shard_num为每个库的分表个数。
例如把一张大表分成100张小表然后散到2个库,则0-49落在第一个库、50-99落在第二个库。核心实现如下:
public class ModStrategyHandle implements ShardStrategy {
@Override
public String getShardType() {
return "mod";
}
@Override
public DataTableName handle(String tableName, String dataSourceKey, int tableShardNum,
int dbShardNum, Object shardValue) {
/** 计算散到表的值 */
long shard_value = Long.valueOf(shardValue.toString());
long tablePosition = shard_value % tableShardNum;
long dbPosition = tablePosition / (tableShardNum / dbShardNum);
String finalTableName = new StringBuilder().append(tableName).append("_").append(tablePosition).toString();
String finalDataSourceKey = new StringBuilder().append(dataSourceKey).append(dbPosition).toString();
return new DataTableName(finalTableName, finalDataSourceKey);
}
}
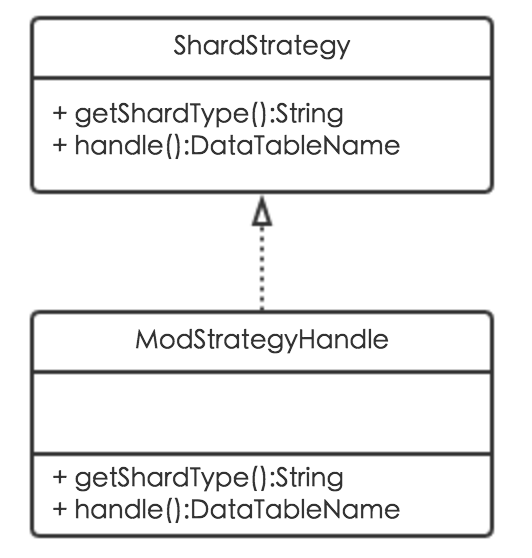
分库分表算法扩展
MTDDL不仅支持分库分表取模算法,还支持分库分表算法的扩展,通过新增分库分表策略类实现ShardStrategy接口即可。ShardStrategy接口包含两个方法:getShardType用来指定分库分表策略,handle用来实现具体的数据源及分表计算逻辑。其类图如下:
全注解方式接入
为了尽可能地方便业务方接入,MTDDL采用全注解方式使用分库分表功能,通过ShardInfo、ShardOn、IDGen三个注解实现。
ShardInfo注解用来指定具体的分库分表配置:包括分表名前缀tableName、分表数量tableShardNum、分库数量dbShardNum、分库分表策略shardType、唯一键生成策略idGenType、唯一键业务方标识idGenKey;ShardOn注解用来指定分库分表字段;IDGen注解用来指定唯一键字段。具体类图如下:
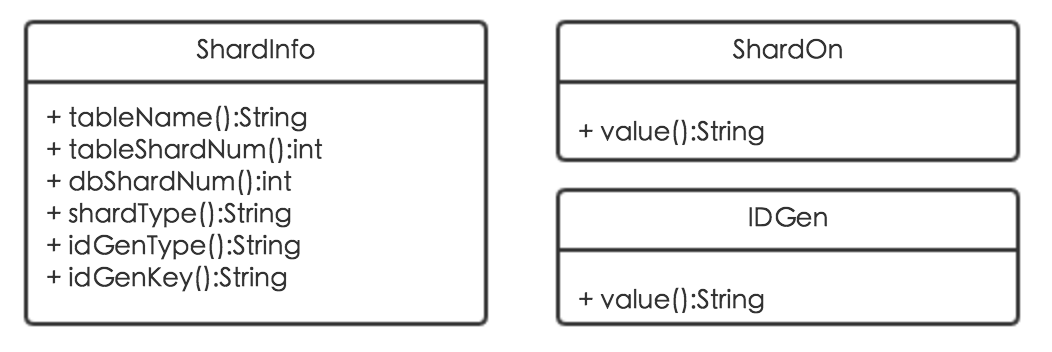
配置和使用方式举例
// 动态数据源
@DataSource("dbProductSku")
// tableName:分表名前缀,tableShardNum:分表数量,dbShardNum:分库数量,shardType:分库分表策略,idGenType:唯一键生成策略,idGenKey:唯一键业务方标识
@ShardInfo(tableName="wm_food", tableShardNum=100, dbShardNum=1, shardType="mod", idGenType=IDGenType.LEAF, idGenKey=LeafKey.SKU)
@Component
public interface WmProductSkuShardDao {
// @ShardOn("wm_poi_id") 将该注解修饰的对象的wm_poi_id字段作为shardValue
// @IDGen("id") 指定要设置唯一键的字段
public void insert(@ShardOn("wm_poi_id") @IDGen("id") WmProductSku sku);
// @ShardOn 将该注解修饰的参数作为shardValue
public List<WmProductSku> getSkusByWmPoiId(@ShardOn long wm_poi_id);
}
连接池及SQL监控
DB连接池使用不合理容易引发很多问题,如连接池最大连接数设置过小导致线程获取不到连接、获取连接等待时间设置过大导致很多线程挂起、空闲连接回收器运行周期过长导致空闲连接回收不及时等等,如果缺乏有效准确的监控,会造成无法快速定位问题以及追溯历史。
再者,如果缺乏SQL执行情况相关监控,会很难及时发现DB慢查询等潜在风险,而慢查询往往就是DB服务端性能恶化乃至宕机的根源(关于慢查询,推荐阅读《MySQL索引原理及慢查询优化》一文)。MTDDL从1.0.2版本开始正式引入连接池及SQL监控等相关功能。
连接池监控
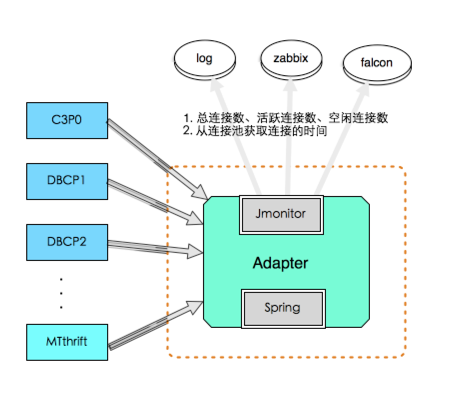
实现方案
结合Spring完美适配c3p0、dbcp1、dbcp2、mtthrift等多种方案,自动发现新加入到Spring容器中的数据源进行监控,通过美团点评统一监控组件JMonitor上报监控数据。整体架构图如下:
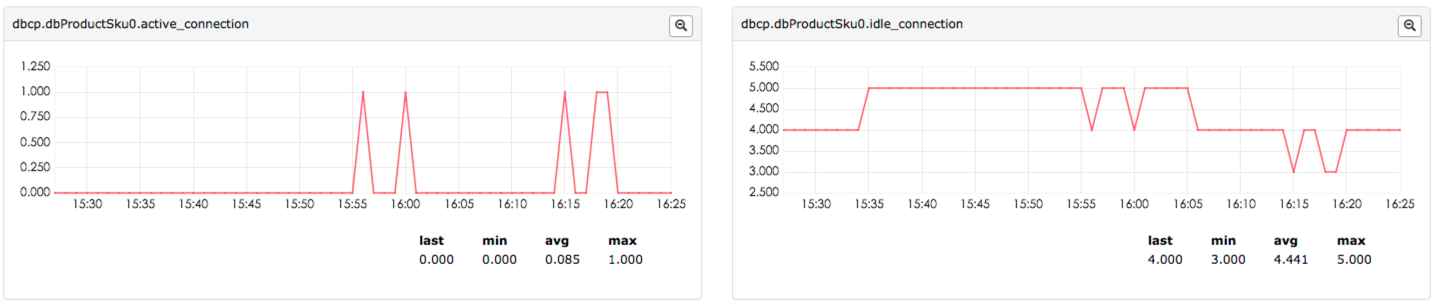
连接数量监控
监控连接池active、idle、total连接数量,Counter格式:(连接池类型.数据源.active/idle/total_connection),效果图如下:
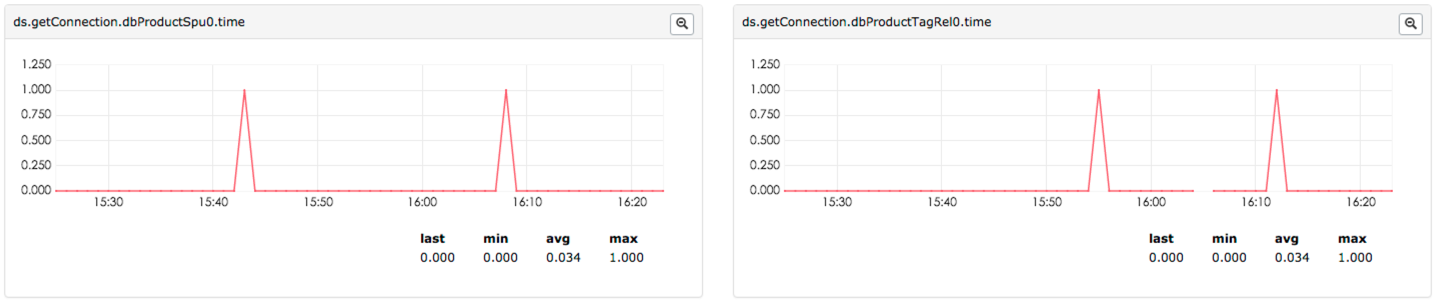
获取连接时间监控
监控获取空闲连接时间,Counter格式:(ds.getConnection.数据源.time),效果图如下:
SQL监控
实现方案
采用Spring AOP技术对所有DAO方法进行功能增强处理,通过美团点评分布式会话跟踪组件MTrace进行SQL调用数据埋点及上报,进而实现从客户端角度对SQL执行耗时、QPS、调用量、超时率、失败率等指标进行监控。整体架构图如下:
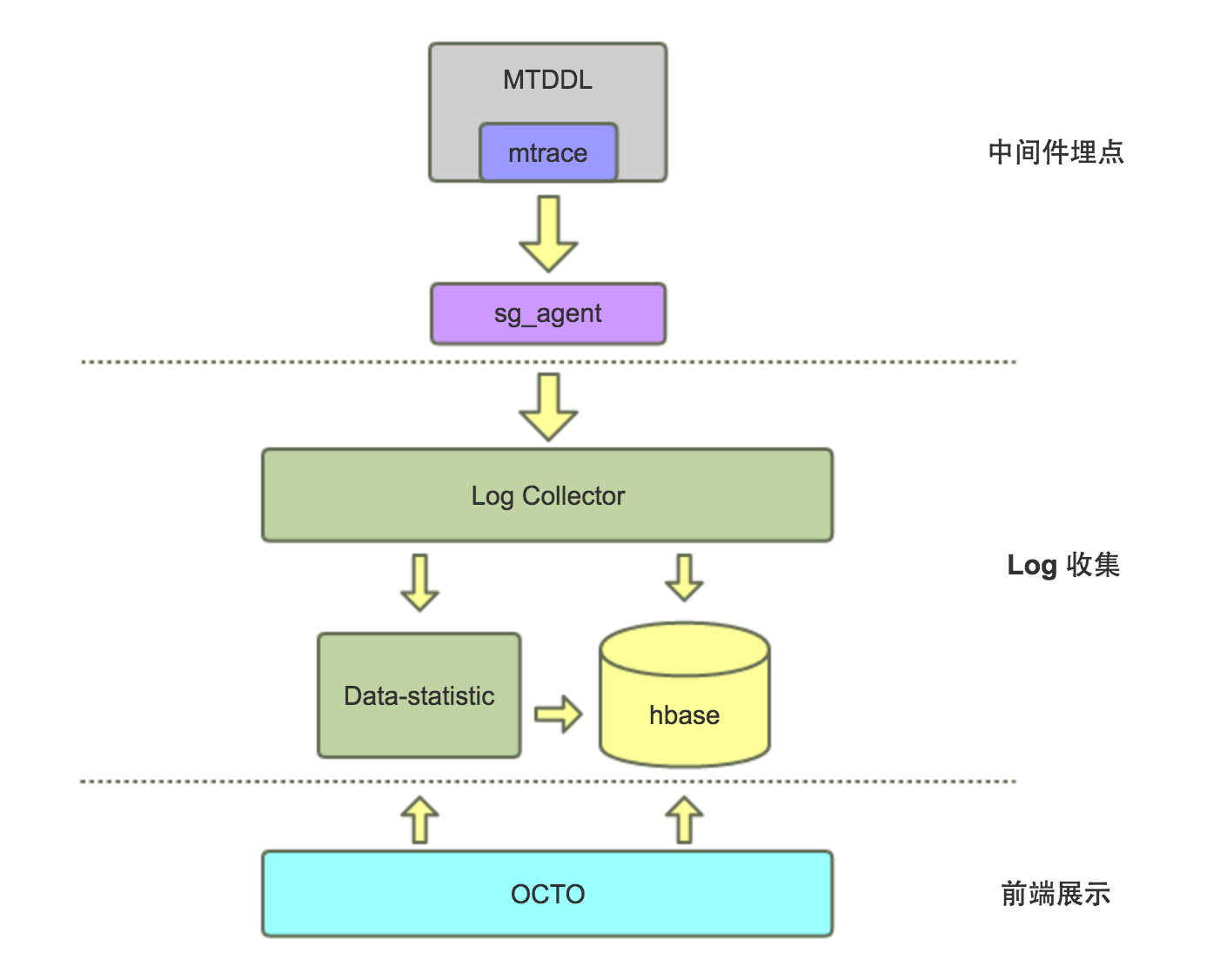
实现效果
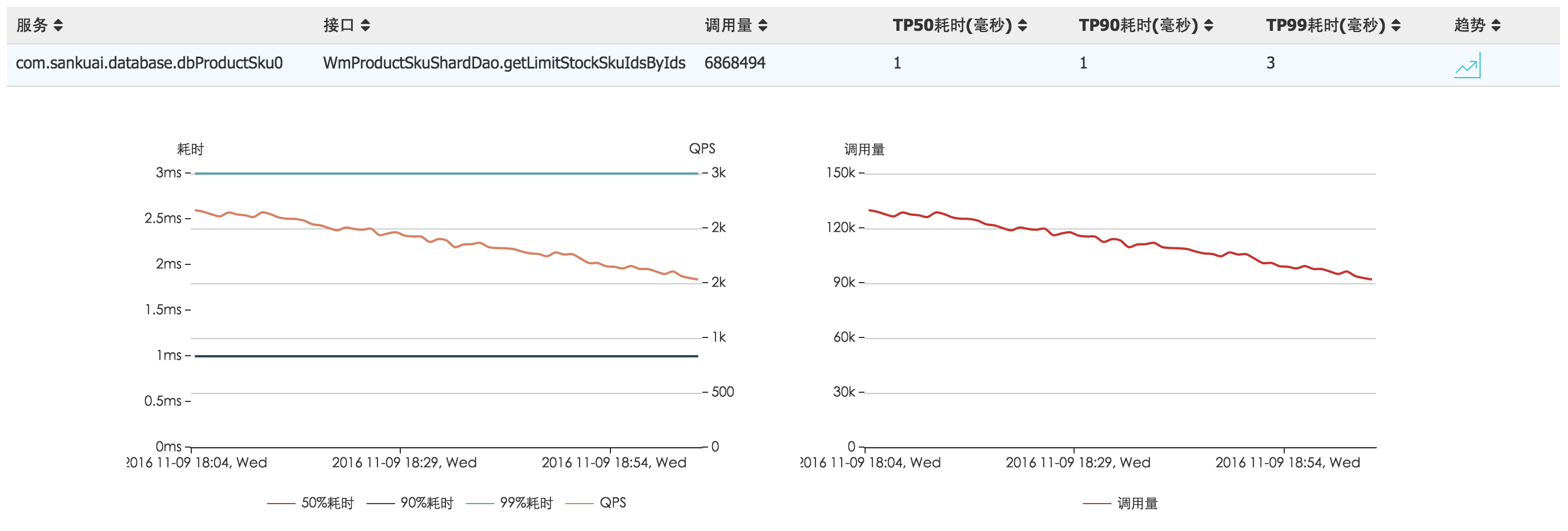
登录美团点评的服务治理平台OCTO选择服务查看去向分析,效果图如下:
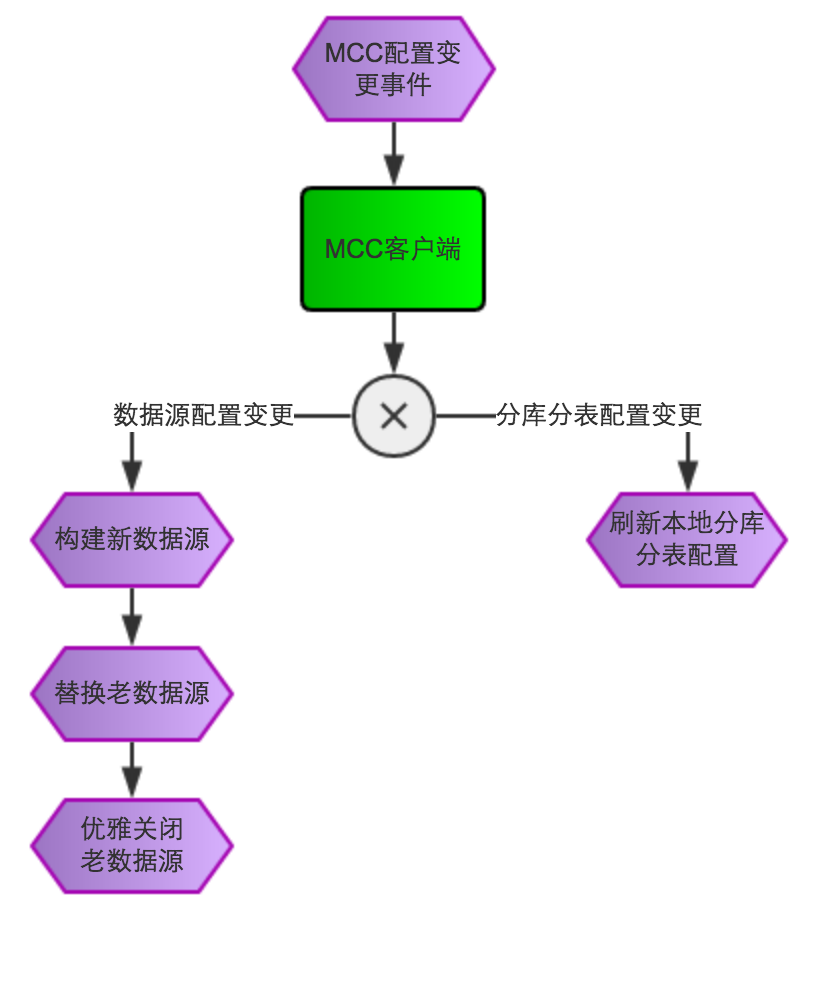
动态化配置
为了满足业务方一些动态化需求,如解决线上DB紧急事故需动态调整数据源或者分库分表相关配置,要求无需重启在线修改立即生效,MTDDL从1.0.3版本开始正式引入动态化配置相关功能。
实现方案
在Spring容器启动的时候自动注册数据源及分库分表相关配置到美团点评的统一配置中心MCC,在MCC配置管理页面可以进行动态调整,MCC客户端在感知到变更事件后会刷新本地配置,如果是数据源配置变更会根据新的配置构造出一个新数据源来替换老数据源,最后再将老的数据源优雅关闭掉。具体流程图如下:
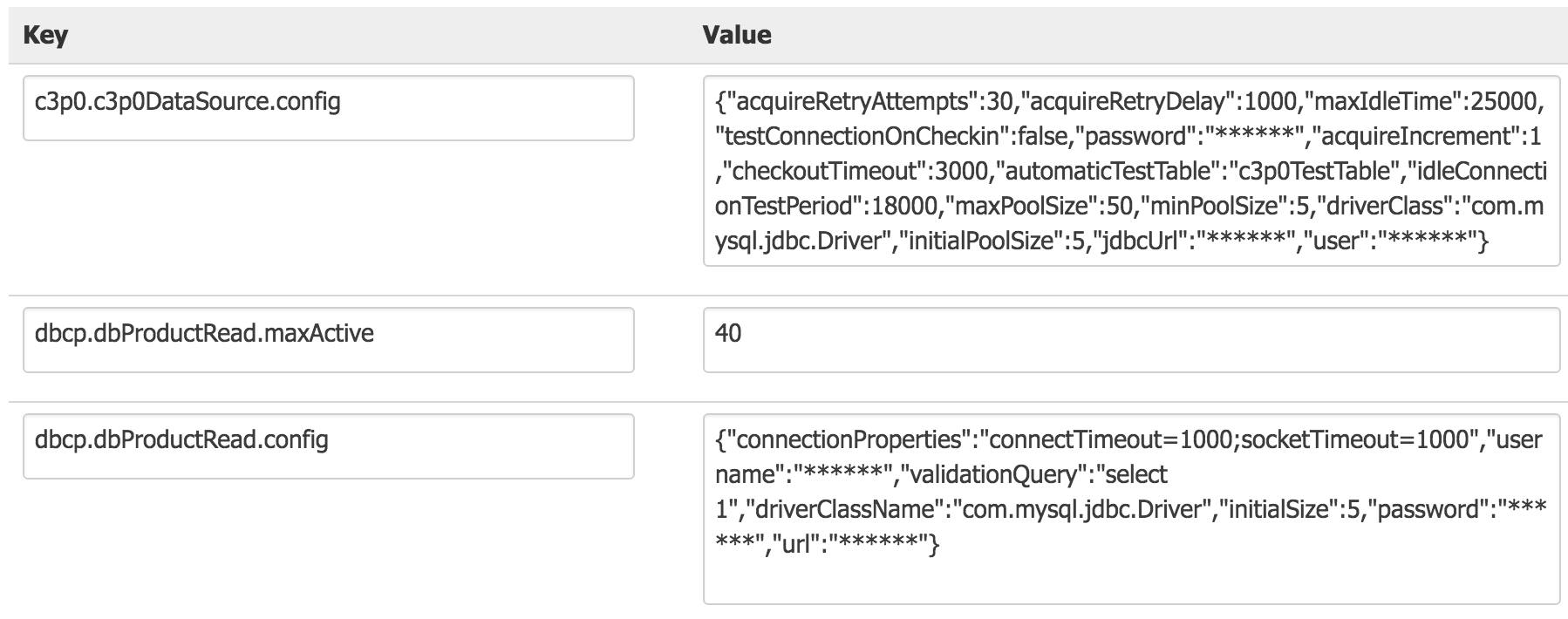
动态化数据源
目前支持dbcp、dbcp2、c3p0等数据源,效果图如下:
分库分表动态化
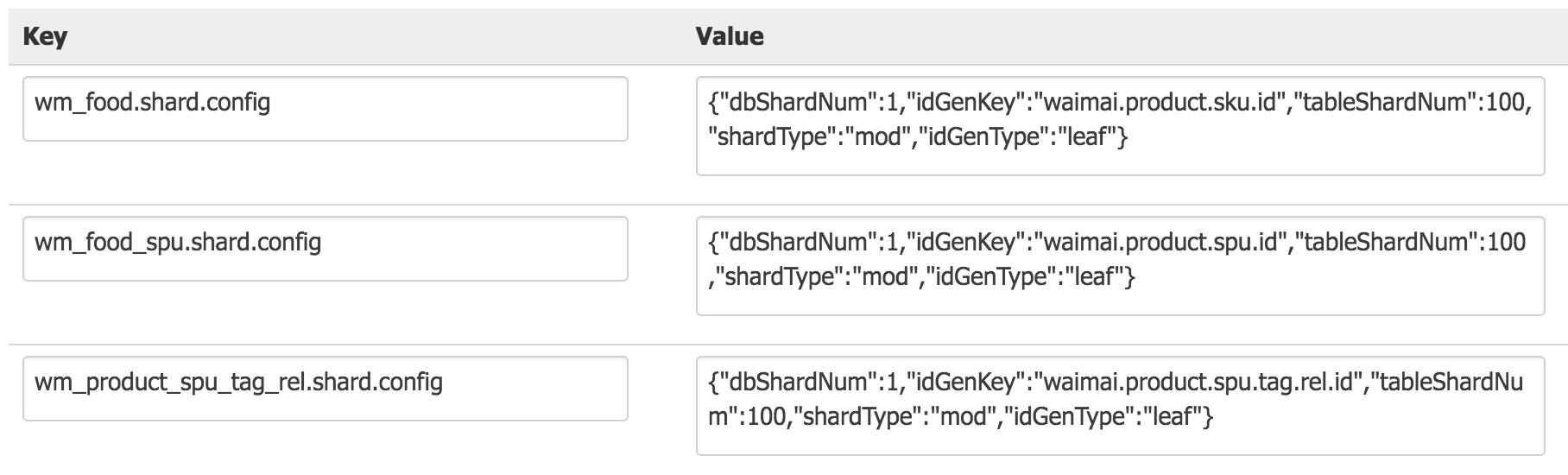
支持动态化配置分库分表数量、分库分表策略、唯一键生成策略、唯一键业务方标识等,效果图如下:
版本迭代
MTDDL到目前为止总共开发了四期,后续考虑逐步开源,具体版本迭代如下:
| 项目名 | 功能 | 开始时间 | 结束时间 | 正式版本 | 快照版本 | 版本备注 |
|---|---|---|---|---|---|---|
| MTDDL一期 | 动态数据源 读写分离 分布式唯一主键生成器 分库分表 |
2016.05.30 | 2016.06.16 | 0.0.1 | 0.0.1-SNAPSHOT | MTDDL第一版 |
| MTDDL二期 | 分布式唯一主键生成算法可扩展 支持零配置接入MTDDL 优化shardkey配置方式 |
2016.08.23 | 2016.09.05 | 1.0.1 | 1.0.1-SNAPSHOT | MTDDL接入优化 |
| MTDDL三期 | 连接池及SQL监控 缓存优化 |
2016.09.06 | 2016.09.20 | 1.0.2 | 1.0.2-SNAPSHOT | MTDDL监控完善 |
| MTDDL四期 | 唯一主键生成注解化 动态化配置 |
2016.10.11 | 2016.11.08 | 1.0.3 | 1.0.3-SNAPSHOT | MTDDL配置动态化 |
---------------------------------------------------------------------------
动态切换数据源
前言
在现在开发的过程中应该大多数朋友都有遇到过切换数据源的需求。比如现在常用的数据库读写分离,或者就是有两个数据库的情况,这些都需要用到切换数据源。
手动切换数据源
使用Spring的AbstractRoutingDataSource类来进行拓展多数据源。
该类就相当于一个dataSource的路由,用于根据key值来进行切换对应的dataSource。
下面简单来看下AbstractRoutingDataSource类的几段关键源码:
@Override
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return determineTargetDataSource().getConnection(username, password);
}
/**
* Retrieve the current target DataSource. Determines the
* {@link #determineCurrentLookupKey() current lookup key}, performs
* a lookup in the {@link #setTargetDataSources targetDataSources} map,
* falls back to the specified
* {@link #setDefaultTargetDataSource default target DataSource} if necessary.
* @see #determineCurrentLookupKey()
*/
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
/**
* Determine the current lookup key. This will typically be
* implemented to check a thread-bound transaction context.
* <p>Allows for arbitrary keys. The returned key needs
* to match the stored lookup key type, as resolved by the
* {@link #resolveSpecifiedLookupKey} method.
*/
protected abstract Object determineCurrentLookupKey();
可以看到其中获取链接的方法getConnection()调用的determineTargetDataSource则是关键方法。该方法用于返回我们使用的数据源。
其中呢又是determineCurrentLookupKey()方法来返回当前数据源的key值。
之后通过该key值在resolvedDataSources这个map中找到对应的value(该value就是数据源)。
resolvedDataSources这个map则是在:
@Override
public void afterPropertiesSet() {
if (this.targetDataSources == null) {
throw new IllegalArgumentException("Property 'targetDataSources' is required");
}
this.resolvedDataSources = new HashMap<Object, DataSource>(this.targetDataSources.size());
for (Map.Entry<Object, Object> entry : this.targetDataSources.entrySet()) {
Object lookupKey = resolveSpecifiedLookupKey(entry.getKey());
DataSource dataSource = resolveSpecifiedDataSource(entry.getValue());
this.resolvedDataSources.put(lookupKey, dataSource);
}
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource = resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}
这个方法通过targetDataSources这个map来进行赋值的。targetDataSources则是我们在配置文件中进行赋值的,下面会讲到。
再来看看determineCurrentLookupKey()方法,从protected来修饰就可以看出是需要我们来进行重写的。
DynamicDataSource 和 DataSourceHolder
于是我新增了DynamicDataSource类,代码如下:
package com.crossoverJie.util;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* Function:
*
* @author chenjiec
* Date: 2017/1/2 上午12:22
* @since JDK 1.7
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceHolder.getDataSources();
}
}
代码很简单,继承了AbstractRoutingDataSource类并重写了其中的determineCurrentLookupKey()方法。
这里直接用DataSourceHolder返回了一个数据源。
DataSourceHolder代码如下:
package com.crossoverJie.util;
/**
* Function:动态数据源
*
* @author chenjiec
* Date: 2017/1/2 上午12:19
* @since JDK 1.7
*/
public class DataSourceHolder {
private static final ThreadLocal<String> dataSources = new ThreadLocal<String>();
public static void setDataSources(String dataSource) {
dataSources.set(dataSource);
}
public static String getDataSources() {
return dataSources.get();
}
}
这里我使用了ThreadLocal来保存了数据源,关于ThreadLocal的知识点可以查看以下这篇文章:
解密ThreadLocal
之后在Spring的配置文件中配置我们的数据源,就是上文讲到的为targetDataSources赋值:
<bean id="ssm1DataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<!-- 指定连接数据库的驱动 -->
<property name="driverClassName" value="${jdbc.driverClass}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.user}" />
<property name="password" value="${jdbc.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="3" />
<property name="minIdle" value="3" />
<property name="maxActive" value="20" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize"
value="20" />
<!-- 配置监控统计拦截的filters,去掉后监控界面sql无法统计 -->
<property name="filters" value="stat" />
</bean>
<bean id="ssm2DataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<!-- 指定连接数据库的驱动 -->
<property name="driverClassName" value="${jdbc.driverClass}"/>
<property name="url" value="${jdbc.url2}"/>
<property name="username" value="${jdbc.user2}"/>
<property name="password" value="${jdbc.password2}"/>
<property name="initialSize" value="3"/>
<property name="minIdle" value="3"/>
<property name="maxActive" value="20"/>
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000"/>
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000"/>
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000"/>
<property name="validationQuery" value="SELECT 'x'"/>
<property name="testWhileIdle" value="true"/>
<property name="testOnBorrow" value="false"/>
<property name="testOnReturn" value="false"/>
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true"/>
<property name="maxPoolPreparedStatementPerConnectionSize"
value="20"/>
<!-- 配置监控统计拦截的filters,去掉后监控界面sql无法统计 -->
<property name="filters" value="stat"/>
</bean>
<bean id="dataSource" class="com.crossoverJie.util.DynamicDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<entry key="ssm1DataSource" value-ref="ssm1DataSource"/>
<entry key="ssm2DataSource" value-ref="ssm2DataSource"/>
</map>
</property>
<!--默认数据源-->
<property name="defaultTargetDataSource" ref="ssm1DataSource"/>
</bean>
这里分别配置了两个数据源:ssm1DataSource和ssm2DataSource。
之后再通过Spring的依赖注入方式将两个数据源设置进targetDataSources。
接下来的用法相比大家也应该猜到了。
就是在每次调用数据库之前我们都要先通过
DataSourceHolder来设置当前的数据源。看下demo:
@Test
public void selectByPrimaryKey() throws Exception {
DataSourceHolder.setDataSources(Constants.DATASOURCE_TWO);
Datasource datasource = dataSourceService.selectByPrimaryKey(7);
System.out.println(JSON.toJSONString(datasource));
}
详见我的单测。
使用起来也是非常简单。但是不知道大家注意到没有,这样的做法槽点很多:
- 每次使用需要手动切换,总有一些人会忘记写(比如我)。
- 如果是后期需求变了,查询其他的表了还得一个个改回来。
那有没有什么方法可以自动的帮我们切换呢?
肯定是有的,大家应该也想得到。就是利用Spring的AOP了。
自动切换数据源
首先要定义好我们的切面类DataSourceExchange:
package com.crossoverJie.util;
import org.aspectj.lang.JoinPoint;
/**
* Function:拦截器方法
*
* @author chenjiec
* Date: 2017/1/3 上午12:34
* @since JDK 1.7
*/
public class DataSourceExchange {
/**
*
* @param point
*/
public void before(JoinPoint point) {
//获取目标对象的类类型
Class<?> aClass = point.getTarget().getClass();
//获取包名用于区分不同数据源
String whichDataSource = aClass.getName().substring(25, aClass.getName().lastIndexOf("."));
if ("ssmone".equals(whichDataSource)) {
DataSourceHolder.setDataSources(Constants.DATASOURCE_ONE);
} else {
DataSourceHolder.setDataSources(Constants.DATASOURCE_TWO);
}
}
/**
* 执行后将数据源置为空
*/
public void after() {
DataSourceHolder.setDataSources(null);
}
}
逻辑也比较简单,就是在执行数据库操作之前做一个切面。
- 通过
JoinPoint对象获取目标对象。 - 在目标对象中获取包名来区分不同的数据源。
- 根据不同数据源来进行赋值。
- 执行完毕之后将数据源清空。
关于一些JoinPoint的API:
package org.aspectj.lang;
import org.aspectj.lang.reflect.SourceLocation;
public interface JoinPoint {
String toString(); //连接点所在位置的相关信息
String toShortString(); //连接点所在位置的简短相关信息
String toLongString(); //连接点所在位置的全部相关信息
Object getThis(); //返回AOP代理对象
Object getTarget(); //返回目标对象
Object[] getArgs(); //返回被通知方法参数列表
Signature getSignature(); //返回当前连接点签名
SourceLocation getSourceLocation();//返回连接点方法所在类文件中的位置
String getKind(); //连接点类型
StaticPart getStaticPart(); //返回连接点静态部分
}
为了通过包名来区分不同数据源,我将目录结构稍微调整了下:
2
将两个不同的数据源的实现类放到不同的包中,这样今后如果还需要新增其他数据源也可以灵活的切换。
看下Spring的配置:
<bean id="dataSourceExchange" class="com.crossoverJie.util.DataSourceExchange"/>
<!--配置切面拦截方法 -->
<aop:config proxy-target-class="false">
<!--将com.crossoverJie.service包下的所有select开头的方法加入拦截
去掉select则加入所有方法
-->
<aop:pointcut id="controllerMethodPointcut" expression="
execution(* com.crossoverJie.service.*.select*(..))"/>
<aop:pointcut id="selectMethodPointcut" expression="
execution(* com.crossoverJie.dao..*Mapper.select*(..))"/>
<aop:advisor advice-ref="methodCacheInterceptor" pointcut-ref="controllerMethodPointcut"/>
<!--所有数据库操作的方法加入切面-->
<aop:aspect ref="dataSourceExchange">
<aop:pointcut id="dataSourcePointcut" expression="execution(* com.crossoverJie.service.*.*(..))"/>
<aop:before pointcut-ref="dataSourcePointcut" method="before"/>
<aop:after pointcut-ref="dataSourcePointcut" method="after"/>
</aop:aspect>
</aop:config>
这是在我们上一篇整合redis缓存的基础上进行修改的。
这样缓存和多数据源都满足了。
实际使用:
@Test
public void selectByPrimaryKey() throws Exception {
Rediscontent rediscontent = rediscontentService.selectByPrimaryKey(30);
System.out.println(JSON.toJSONString(rediscontent));
}
3
这样看起来就和使用一个数据源这样简单,再也不用关心切换的问题了。
作者:crossoverJie
链接:https://www.jianshu.com/p/9d3d92b37c0a
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。