Hadoop Hive概念学习系列之什么是Hive?
参考 《Hadoop大数据分析与挖掘实战》的在线电子书阅读
http://yuedu.baidu.com/ebook/d128cf8e33687e21ae45a935?pn=1&click_type=10010002
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,是建立在Hadoop上的数据仓库基础构架。作为Hadoop的一个数据仓库工具,Hive可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。
Hive作为构建在Hadoop之上的数据仓库,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据。因此,该语言也允许熟悉MapReduce的开发者开发自定义的Mapper和Reducer来处理内建的Mapper和Reducer无法完成的复杂的分析工作。
Hive没有专门的数据格式。Hive可以很好地工作在Thrift(是个服务器)之上,控制分隔符,也允许用户指定数据格式。
Hive具有以下特点:
.支持索引,加快数据查询。
.不同的存储类型,如纯文本文件、HBase中的文件。
.将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.可以直接使用存储在Hadoop文件系统中的数据。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.内置大量用户函数UDF来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作。
如, 3 hql语法及自定义函数 里的 .hive自定义函数
.类SQL的查询方式,将SQL查询转换为MapReducer的Job在Hadoop集群上执行。
Hive构建在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度时需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询。例如,Hive在几百MB的数据集上执行查询一般有分钟级的时间延迟。因此,Hive并不适合那些需要低延迟的应用,如联机事务处理(OLTP)。Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoo监控作业执行过程,然后返回作业执行结果给用户。Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。
Hive的最佳使用场合是大数据集的批处理作业,如网络日志分析。
Hive的架构

图1 Hive的架构
从图1中可以看到,Hive包含用户访问接口(CLI、JDBC/ODBC、GUI和Thrift Server)、元数据存储(Metastore)、驱动组件(包括编译、优化、执行驱动)。
用户访问接口即用户用来访问Hive数据仓库所使用的工具接口。
CLI(command line interface)即命令行接口。
Thrift Server是Facebook开发的一个软件框架,它用来开发可扩展且跨语言的服务,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
Hive客户端提供了通过网页的方式访问Hive提供的服务,这个接口对应Hive的HWI组件(Hive web interface),使用前要启动HWI服务。
Metastore是Hive中的元数据存储,主要存储Hive中的元数据,包括表的名称、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等,一般使用MySQL或Derby数据库。
Metastore和Hive Driver驱动的互联有两种方式,一种是集成模式,如图2所示;一种是远程模式,如图3所示。
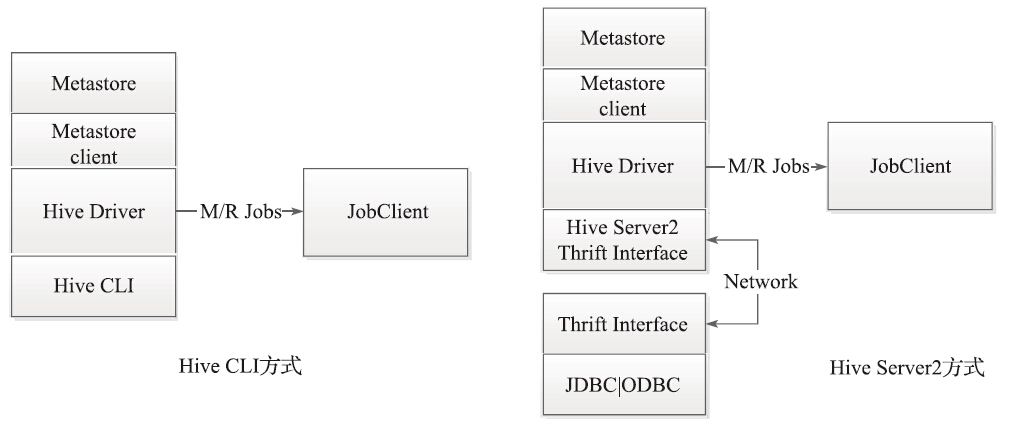
图2 Metastore 和 Driver通信(集成模式)

图3 Metastore 和 Driver通信(远程模式)