https://blog.csdn.net/rachel_luo/article/details/8920596
最近在做性能测试,需要对线程堆栈进行分析,在网上收集了一些资料,学习完后,将相关知识整理在一起,输出文章如下。
一、Thread Dump介绍
1.1什么是Thread Dump?
Thread Dump是非常有用的诊断Java应用问题的工具。每一个Java虚拟机都有及时生成所有线程在某一点状态的thread-dump的能力,虽然各个 Java虚拟机打印的thread dump略有不同,但是大多都提供了当前活动线程的快照,及JVM中所有Java线程的堆栈跟踪信息,堆栈信息一般包含完整的类名及所执行的方法,如果可能的话还有源代码的行数。
1.2 Thread Dump特点
1. 能在各种操作系统下使用
2. 能在各种Java应用服务器下使用
3. 可以在生产环境下使用而不影响系统的性能
4. 可以将问题直接定位到应用程序的代码行上
1.3 Thread Dump 能诊断的问题
1. 查找内存泄露,常见的是程序里load大量的数据到缓存;
2. 发现死锁线程;
1.4如何抓取Thread Dump
一般当服务器挂起,崩溃或者性能底下时,就需要抓取服务器的线程堆栈(Thread Dump)用于后续的分析. 在实际运行中,往往一次 dump的信息,还不足以确认问题。为了反映线程状态的动态变化,需要接连多次做threaddump,每次间隔10-20s,建议至少产生三次 dump信息,如果每次 dump都指向同一个问题,我们才确定问题的典型性。
有很多方式可用于获取ThreadDump, 下面列出一部分获取方式:
操作系统命令获取ThreadDump:
Windows:
1.转向服务器的标准输出窗口并按下Control + Break组合键, 之后需要将线程堆栈复制到文件中;
UNIX/ Linux:
首先查找到服务器的进程号(process id), 然后获取线程堆栈.
1. ps –ef | grep java
2. kill -3 <pid>
注意:一定要谨慎, 一步不慎就可能让服务器进程被杀死。kill -9 命令会杀死进程。
JVM 自带的工具获取线程堆栈:
JDK自带命令行工具获取PID,再获取ThreadDump:
1. jps 或 ps –ef|grepjava (获取PID)
2. jstack [-l ]<pid> | tee -a jstack.log (获取ThreadDump)
二、java线程的状态转换介绍(为后续分析做准备)
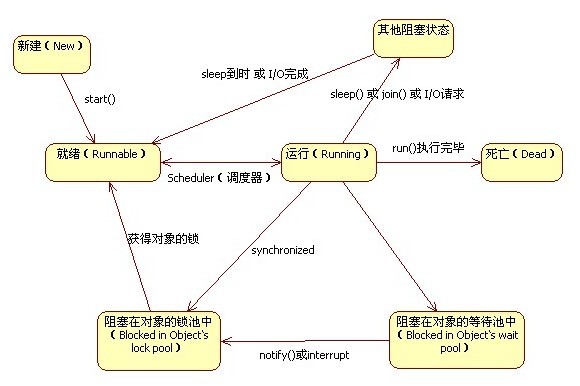
2.1 新建状态(New)
用new语句创建的线程处于新建状态,此时它和其他Java对象一样,仅仅在堆区中被分配了内存。
2.2 就绪状态(Runnable)
当一个线程对象创建后,其他线程调用它的start()方法,该线程就进入就绪状态,Java虚拟机会为它创建方法调用栈和程序计数器。处于这个状态的线程位于可运行池中,等待获得CPU的使用权。
2.3 运行状态(Running)
处于这个状态的线程占用CPU,执行程序代码。只有处于就绪状态的线程才有机会转到运行状态。
2.4 阻塞状态(Blocked)
阻塞状态是指线程因为某些原因放弃CPU,暂时停止运行。当线程处于阻塞状态时,Java虚拟机不会给线程分配CPU。直到线程重新进入就绪状态,它才有机会转到运行状态。
阻塞状态可分为以下3种:
1)位于对象等待池中的阻塞状态(Blocked in object’s wait pool):当线程处于运行状态时,如果执行了某个对象的wait()方法,Java虚拟机就会把线程放到这个对象的等待池中,这涉及到“线程通信”的内容。
2)位于对象锁池中的阻塞状态(Blocked in object’s lock pool):当线程处于运行状态时,试图获得某个对象的同步锁时,如果该对象的同步锁已经被其他线程占用,Java虚拟机就会把这个线程放到这个对象的锁池中,这涉及到“线程同步”的内容。
3)其他阻塞状态(Otherwise Blocked):当前线程执行了sleep()方法,或者调用了其他线程的join()方法,或者发出了I/O请求时,就会进入这个状态。
2.5 死亡状态(Dead)
当线程退出run()方法时,就进入死亡状态,该线程结束生命周期。
三、Thread Dump分析
通过前面1.4部分的方法,获取Thread Dump信息后,对其进行分析;
3.1 首先介绍一下Thread Dump信息的各个部分
时间,jvm信息
2011-11-02 19:05:06
Full thread dump Java HotSpot(TM) Server VM (16.3-b01 mixed mode):
线程info信息块:
1. "Timer-0" daemon prio=10tid=0xac190c00 nid=0xaef in Object.wait() [0xae77d000]
2. java.lang.Thread.State: TIMED_WAITING (on object monitor)
3. atjava.lang.Object.wait(Native Method)
4. -waiting on <0xb3885f60> (a java.util.TaskQueue) ###继续wait
5. atjava.util.TimerThread.mainLoop(Timer.java:509)
6. -locked <0xb3885f60> (a java.util.TaskQueue) ###已经locked
7. atjava.util.TimerThread.run(Timer.java:462)
* 线程名称:Timer-0
* 线程类型:daemon
* 优先级: 10,默认是5
* jvm线程id:tid=0xac190c00,jvm内部线程的唯一标识(通过java.lang.Thread.getId()获取,通常用自增方式实现。)
* 对应系统线程id(NativeThread ID):nid=0xaef,和top命令查看的线程pid对应,不过一个是10进制,一个是16进制。(通过命令:top -H -p pid,可以查看该进程的所有线程信息)
* 线程状态:in Object.wait().
* 起始栈地址:[0xae77d000]
* Java thread statck trace:是上面2-7行的信息。到目前为止这是最重要的数据,Java stack trace提供了大部分信息来精确定位问题根源。
对于thread dump信息,主要关注的是线程的状态和其执行堆栈。现在针对这两个重点部分进行讲解:
1)Java thread statck trace详解:
堆栈信息应该逆向解读:程序先执行的是第7行,然后是第6行,依次类推。
- locked <0xb3885f60> (a java.util.ArrayList)
- waiting on <0xb3885f60> (a java.util.ArrayList)
也就是说对象先上锁,锁住对象0xb3885f60,然后释放该对象锁,进入waiting状态。
为啥会出现这样的情况呢?看看下面的java代码示例,就会明白:
synchronized(obj) {
.........
obj.wait();
.........
}
在堆栈的第一行信息中,进一步标明了线程在代码级的状态,例如:
java.lang.Thread.State: TIMED_WAITING (parking)
解释如下:
|blocked|
This thread tried to enter asynchronized block, but the lock was taken by another thread. This thread isblocked until the lock gets released.
|blocked (on thin lock)|
This is the same state asblocked, but the lock in question is a thin lock.
|waiting|
This thread calledObject.wait() on an object. The thread will remain there until some otherthread sends a notification to that object.
|sleeping|
This thread calledjava.lang.Thread.sleep().
|parked|
This thread calledjava.util.concurrent.locks.LockSupport.park().
|suspended|
The thread's execution wassuspended by java.lang.Thread.suspend() or a JVMTI agent call.
2) 线程状态详解:
Runnable
_The thread is either running or ready to run when it gets its CPU turn._
Wait on condition
_The thread is either sleeping or waiting to be notified by another thread._
该状态出现在线程等待某个条件的发生或者sleep。具体是什么原因,可以结合 stacktrace来分析。最常见的情况是线程在等待网络的读写,比如当网络数据没有准备好读时,线程处于这种等待状态,而一旦有数据准备好读之后,线程会重新激活,读取并处理数据。在Java引入 New IO之前,对于每个网络连接,都有一个对应的线程来处理网络的读写操作,即使没有可读写的数据,线程仍然阻塞在读写操作上,这样有可能造成资源浪费,而且给操作系统的线程调度也带来压力。在 New IO里采用了新的机制,编写的服务器程序的性能和可扩展性都得到提高。
如果发现有大量的线程都处在 Wait on condition,从线程 stack看, 正等待网络读写,这可能是一个网络瓶颈的征兆。因为网络阻塞导致线程无法执行。一种情况是网络非常忙,几乎消耗了所有的带宽,仍然有大量数据等待网络读写;另一种情况也可能是网络空闲,但由于路由等问题,导致包无法正常的到达。所以要结合系统的一些性能观察工具来综合分析,比如 netstat统计单位时间的发送包的数目,看是否很明显超过了所在网络带宽的限制;观察cpu的利用率,看系统态的CPU时间是否明显大于用户态的CPU时间;如果程序运行在 Solaris 10平台上,可以用dtrace工具看系统调用的情况,如果观察到 read/write的系统调用的次数或者运行时间遥遥领先;这些都指向由于网络带宽所限导致的网络瓶颈。另外一种出现 Wait on condition的常见情况是该线程在 sleep,等待 sleep的时间到了,将被唤醒。
Waiting for Monitor Entry and in Object.wait()
_The thread is waiting to getthe lock for an object (some other thread may be holding the lock). Thishappens if two or more threads try to execute synchronized code. Note that thelock is always for an object and not for individual methods._
在多线程的 JAVA程序中,实现线程之间的同步,就要说说 Monitor。 Monitor是Java中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 Class的锁。每一个对象都有,也仅有一个 monitor。每个 Monitor在某个时刻,只能被一个线程拥有,该线程就是 “ActiveThread”,而其它线程都是 “Waiting Thread”,分别在两个队列 “ Entry Set”和 “Wait Set”里面等候。在 “Entry Set”中等待的线程状态是 “Waiting for monitorentry”,而在 “Wait Set”中等待的线程状态是“in Object.wait()”。
先看 “Entry Set”里面的线程。我们称被 synchronized保护起来的代码段为临界区。当一个线程申请进入临界区时,它就进入了 “Entry Set”队列。对应的 code就像:
synchronized(obj) {
.........
}
这时有两种可能性:
该 monitor不被其它线程拥有, Entry Set里面也没有其它等待线程。本线程即成为相应类或者对象的 Monitor的 Owner,执行临界区的代码。
该 monitor被其它线程拥有,本线程在 Entry Set队列中等待。
在第一种情况下,线程将处于 “Runnable”的状态,而第二种情况下,线程 DUMP会显示处于 “waiting for monitor entry”。
临界区的设置,是为了保证其内部的代码执行的原子性和完整性。但是因为临界区在任何时间只允许线程串行通过,这和我们多线程的程序的初衷是相反的。如果在多线程的程序中,大量使用 synchronized,或者不适当的使用了它,会造成大量线程在临界区的入口等待,造成系统的性能大幅下降。如果在线程 DUMP中发现了这个情况,应该审查源码,改进程序。
再看“Wait Set”里面的线程。当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(一般就是被 synchronized 的对象)的 wait() 方法,放弃 Monitor,进入 “Wait Set”队列。只有当别的线程在该对象上调用了 notify() 或者 notifyAll(),“Wait Set”队列中线程才得到机会去竞争,但是只有一个线程获得对象的Monitor,恢复到运行态。在 “Wait Set”中的线程, DUMP中表现为: in Object.wait()。
一般,Cpu很忙时,则关注runnable的线程,Cpu很闲时,则关注waiting for monitor entry的线程。
3.2 JVM线程介绍
在Thread Dump中,有一些 JVM内部的后台线程,来执行譬如垃圾回收,或者低内存的检测等等任务,这些线程往往在 JVM初始化的时候就存在,如下所示:
HotSpot VM Thread
被HotSpot VM管理的内部线程为了完成内部本地操作,一般来说不需要担心它们,除非CPU很高。
"VM Periodic Task Thread" prio=10tid=0xad909400 nid=0xaed waiting on condition
HotSpot GC Thread
当使用HotSpot parallel GC,HotSpot VM默认创建一定数目的GC thread。
"GC task thread#0 (ParallelGC)"prio=10 tid=0xf690b400 nid=0xade runnable
"GC task thread#1 (ParallelGC)"prio=10 tid=0xf690cc00 nid=0xadf runnable
"GC task thread#2 (ParallelGC)"prio=10 tid=0xf690e000 nid=0xae0 runnable
……
当面对过多GC,内存泄露等问题时,这些是关键的数据。使用native id,可以将从OS/Java进程观测到的高CPU与这些线程关联起来。
JNI global references count
JNI global reference是基本的对象引用,从本地代码到被Java GC管理的Java对象的引用。其角色是阻止仍然被本地代码使用的对象集合,但在Java代码中没有引用。在探测JNI相关内存泄露时,关注JNI references很重要。如果你的程序直接使用JNI或使用第三方工具,如检测工具,检测本地内存泄露。
JNI global references: 832
Java Heap utilization view
从jdk1.6开始在thread dump快照底部,可以找到崩溃点的内存空间利用情况:YongGen,OldGen和PermGen。目前我测试的系统导出的thread dump,还未见到这一部分内容(sun jdk1.6)。以下例子,摘自他人文章:
Heap
PSYoungGen total 466944K, used 178734K [0xffffffff45c00000, 0xffffffff70800000, 0xffffffff70800000)
eden space 233472K, 76% used [0xffffffff45c00000,0xffffffff50ab7c50,0xffffffff54000000)
from space 233472K, 0% used [0xffffffff62400000,0xffffffff62400000,0xffffffff70800000)
to space 233472K, 0% used [0xffffffff54000000,0xffffffff54000000,0xffffffff62400000)
PSOldGen total 1400832K, used 1400831K [0xfffffffef0400000, 0xffffffff45c00000, 0xffffffff45c00000)
object space 1400832K, 99% used [0xfffffffef0400000,0xffffffff45bfffb8,0xffffffff45c00000)
PSPermGen total 262144K, used 248475K [0xfffffffed0400000, 0xfffffffee0400000, 0xfffffffef0400000)
object space 262144K, 94% used [0xfffffffed0400000,0xfffffffedf6a6f08,0xfffffffee0400000)
还有一些其他的线程(如下),不一一介绍了,有兴趣,可查看文章最后的附件信息。
"Low Memory Detector" daemon prio=10tid=0xad907400 nid=0xaec runnable [0x00000000]
"CompilerThread1" daemon prio=10tid=0xad905400 nid=0xaeb waiting on condition [0x00000000]
"CompilerThread0" daemon prio=10tid=0xad903c00 nid=0xaea waiting on condition [0x00000000]
"Signal Dispatcher" daemon prio=10tid=0xad902400 nid=0xae9 runnable [0x00000000]
"Finalizer" daemon prio=10tid=0xf69eec00 nid=0xae8 in Object.wait() [0xaf17d000]
"Reference Handler" daemon prio=10tid=0xf69ed800 nid=0xae7 in Object.wait() [0xae1e7000]
"VM Thread" prio=10 tid=0xf69e9800nid=0xae6 runnable
四、案例分析:
4.1、使用方案
方案:
* 一个请求过程中多次dump
* 对比多次dump文件的runnable线程,如果执行的方法有比较大变化,说明比较正常。如果在执行同一个方法,就有一些问题了。
查找占用cpu最多的线程信息
方案:
* 使用命令: top -H -p pid(pid为被测系统的进程号),找到导致cpu高的线程id。
上述Top命令找到的线程id,对应着dump thread信息中线程的nid,只不过一个是十进制,一个是十六进制。
* 在thread dump中,根据top命令查找的线程id,查找对应的线程堆栈信息。
方案:
* 进行dump,查看是否有很多thread struck在了i/o、数据库等地方,定位瓶颈原因。
方案:
* 多次dump,对比是否所有的runnable线程都一直在执行相同的方法,如果是的,恭喜你,锁住了!
1.死锁:
死锁经常表现为程序的停顿,或者不再响应用户的请求。从操作系统上观察,对应进程的CPU占用率为零,很快会从top或prstat的输出中消失。
在thread dump中,会看到类似于这样的信息:
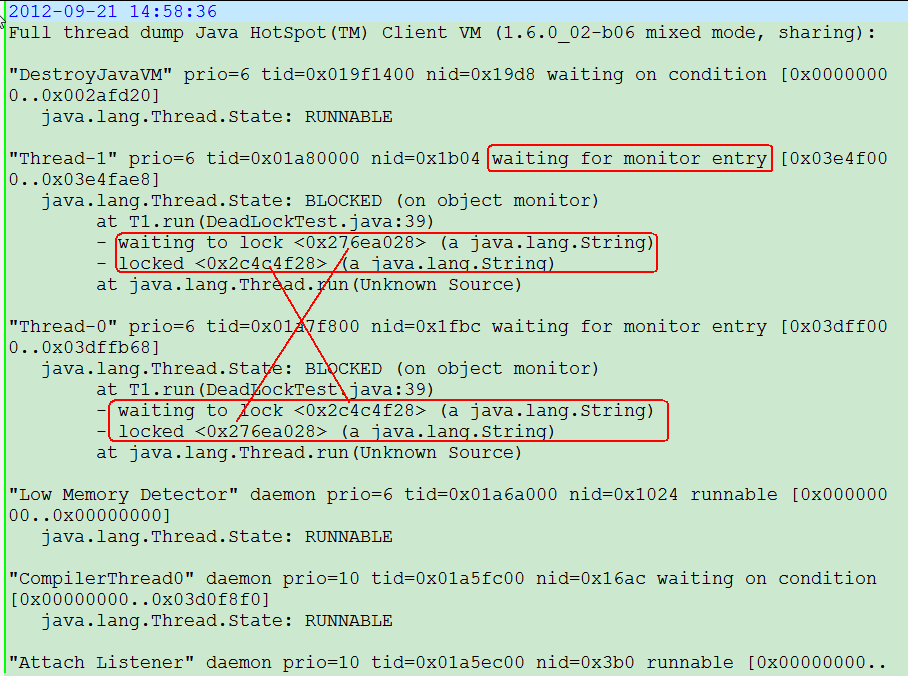
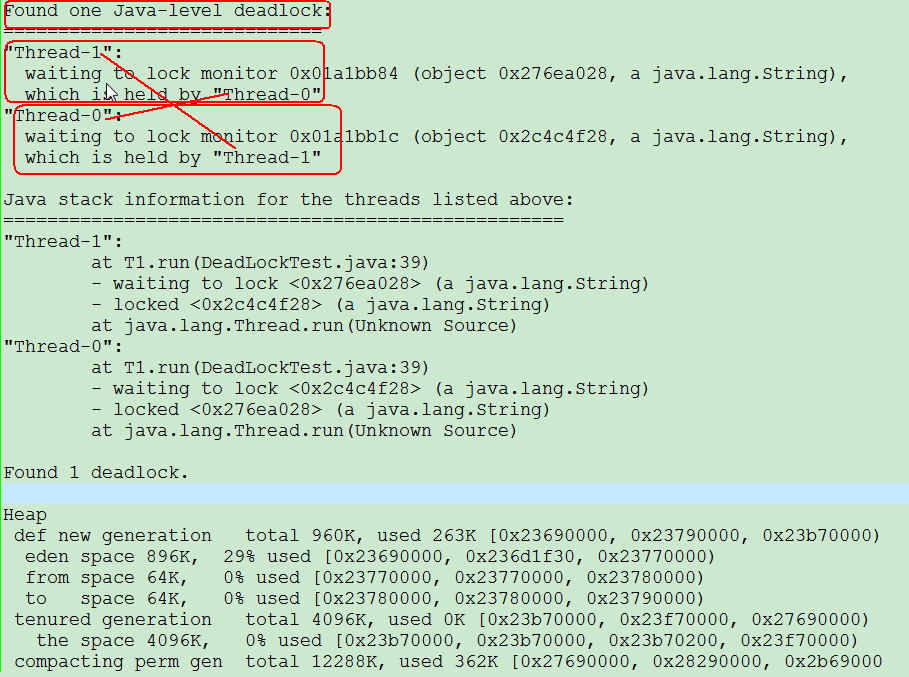
(图2)
说明:
(图1)中有一个“Waiting formonitor entry”,可以看出,两个线程各持有一个锁,又在等待另一个锁,很明显这两个线程互相持有对方正在等待的锁。所以造成了死锁现象;
(图2)中对死锁的现象做了说明,可以看到,是“DeadLockTest.java”的39行造成的死锁现象。这样就能到相应的代码下去查看,定位问题。
2.热锁
热锁,也往往是导致系统性能瓶颈的主要因素。其表现特征为:由于多个线程对临界区,或者锁的竞争,可能出现:
* 频繁的线程的上下文切换:从操作系统对线程的调度来看,当线程在等待资源而阻塞的时候,操作系统会将之切换出来,放到等待的队列,当线程获得资源之后,调度算法会将这个线程切换进去,放到执行队列中。
* 大量的系统调用:因为线程的上下文切换,以及热锁的竞争,或者临界区的频繁的进出,都可能导致大量的系统调用。
* 大部分CPU开销用在“系统态 ”:线程上下文切换,和系统调用,都会导致 CPU在 “系统态 ”运行,换而言之,虽然系统很忙碌,但是 CPU用在 “用户态 ”的比例较小,应用程序得不到充分的 CPU资源。
* 随着 CPU数目的增多,系统的性能反而下降。因为CPU数目多,同时运行的线程就越多,可能就会造成更频繁的线程上下文切换和系统态的CPU开销,从而导致更糟糕的性能。
上面的描述,都是一个 scalability(可扩展性)很差的系统的表现。从整体的性能指标看,由于线程热锁的存在,程序的响应时间会变长,吞吐量会降低。
那么,怎么去了解 “热锁 ”出现在什么地方呢?一个重要的方法还是结合操作系统的各种工具观察系统资源使用状况,以及收集Java线程的DUMP信息,看线程都阻塞在什么方法上,了解原因,才能找到对应的解决方法。
我们曾经遇到过这样的例子,程序运行时,出现了以上指出的各种现象,通过观察操作系统的资源使用统计信息,以及线程 DUMP信息,确定了程序中热锁的存在,并发现大多数的线程状态都是 Waitingfor monitor entry或者 Wait on monitor,且是阻塞在压缩和解压缩的方法上。后来采用第三方的压缩包 javalib替代 JDK自带的压缩包后,系统的性能提高了几倍。
五、附件:
JVM运行过程中产生的一些比较重要的线程罗列如下:
|
线程名称 |
所属 |
解释说明 |
|
Attach Listener |
JVM |
Attach Listener 线程是负责接收到外部的命令,而对该命令进行执行的并且吧结果返回给发送者。通常我们会用一些命令去要求jvm给我们一些反馈信息,如:java -version、jmap、jstack等等。 如果该线程在jvm启动的时候没有初始化,那么,则会在用户第一次执行jvm命令时,得到启动。 |
|
Signal Dispatcher |
JVM |
前面我们提到第一个Attach Listener线程的职责是接收外部jvm命令,当命令接收成功后,会交给signal dispather 线程去进行分发到各个不同的模块处理命令,并且返回处理结果。 signal dispather线程也是在第一次接收外部jvm命令时,进行初始化工作。 |
|
CompilerThread0 |
JVM |
用来调用JITing,实时编译装卸class 。 通常,jvm会启动多个线程来处理这部分工作,线程名称后面的数字也会累加,例如:CompilerThread1 |
|
Concurrent Mark-Sweep GC Thread |
JVM |
并发标记清除垃圾回收器(就是通常所说的CMS GC)线程, 该线程主要针对于老年代垃圾回收。ps:启用该垃圾回收器,需要在jvm启动参数中加上: -XX:+UseConcMarkSweepGC |
|
DestroyJavaVM |
JVM |
执行main()的线程在main执行完后调用JNI中的 jni_DestroyJavaVM() 方法唤起DestroyJavaVM 线程。 JVM在 Jboss 服务器启动之后,就会唤起DestroyJavaVM线程,处于等待状态,等待其它线程(java线程和native线程)退出时通知它卸载JVM。线程退出时,都会判断自己当前是否是整个JVM中最后一个非deamon线程,如果是,则通知DestroyJavaVM 线程卸载JVM。 ps: 扩展一下: 1.如果线程退出时判断自己不为最后一个非deamon线程,那么调用thread->exit(false) ,并在其中抛出thread_end事件,jvm不退出。 2.如果线程退出时判断自己为最后一个非deamon线程,那么调用before_exit() 方法,抛出两个事件: 事件1:thread_end 线程结束事件; 事件2:VM的death事件。 然后调用thread->exit(true) 方法,接下来把线程从active list卸下,删除线程等等一系列工作执行完成后,则通知正在等待的DestroyJavaVM 线程执行卸载JVM操作。 |
|
ContainerBackgroundProcessor 线程 |
JBOSS |
它是一个守护线程, 在jboss服务器在启动的时候就初始化了,主要工作是定期去检查有没有Session过期.过期则清除. 参考: |
|
Dispatcher-Thread-3 线程 |
Log4j |
Log4j具有异步打印日志的功能,需要异步打印日志的Appender都需要注册到 AsyncAppender对象里面去,由AsyncAppender进行监听,决定何时触发日志打印操作。 AsyncAppender如果监听到它管辖范围内的Appender有打印日志的操作,则给这个Appender生成一个相应的event,并将该event保存在一个buffuer区域内。 Dispatcher-Thread-3线程负责判断这个event缓存区是否已经满了,如果已经满了,则将缓存区内的所有event分发到Appender容器里面去,那些注册上来的Appender收到自己的event后,则开始处理自己的日志打印工作。 Dispatcher-Thread-3线程是一个守护线程。 |
|
Finalizer线程 |
JVM |
这个线程也是在main线程之后创建的,其优先级为10,主要用于在垃圾收集前,调用对象的finalize()方法;关于Finalizer线程的几点: 1) 只有当开始一轮垃圾收集时,才会开始调用finalize()方法;因此并不是所有对象的finalize()方法都会被执行; 2) 该线程也是daemon线程,因此如果虚拟机中没有其他非daemon线程,不管该线程有没有执行完finalize()方法,JVM也会退出; 3) JVM在垃圾收集时会将失去引用的对象包装成Finalizer对象(Reference的实现),并放入ReferenceQueue,由Finalizer线程来处理;最后将该Finalizer对象的引用置为null,由垃圾收集器来回收; 4) JVM为什么要单独用一个线程来执行finalize()方法呢?如果JVM的垃圾收集线程自己来做,很有可能由于在finalize()方法中误操作导致GC线程停止或不可控,这对GC线程来说是一种灾难; |
|
Gang worker#0 |
JVM |
JVM 用于做新生代垃圾回收(monir gc)的一个线程。#号后面是线程编号,例如:Gang worker#1 |
|
GC Daemon |
JVM |
GC Daemon 线程是JVM为RMI提供远程分布式GC使用的,GC Daemon线程里面会主动调用System.gc()方法,对服务器进行Full GC。 其初衷是当 RMI 服务器返回一个对象到其客户机(远程方法的调用方)时,其跟踪远程对象在客户机中的使用。当再没有更多的对客户机上远程对象的引用时,或者如果引用的“租借”过期并且没有更新,服务器将垃圾回收远程对象。 不过,我们现在jvm启动参数都加上了-XX:+DisableExplicitGC配置,所以,这个线程只有打酱油的份了。 |
|
IdleRemover |
JBOSS |
Jboss连接池有一个最小值, 该线程每过一段时间都会被Jboss唤起,用于检查和销毁连接池中空闲和无效的连接,直到剩余的连接数小于等于它的最小值。 |
|
Java2D Disposer |
JVM |
这个线程主要服务于awt的各个组件。 说起该线程的主要工作职责前,需要先介绍一下Disposer类是干嘛的。 Disposer提供一个addRecord方法。 如果你想在一个对象被销毁前再做一些善后工作,那么,你可以调用Disposer#addRecord方法,将这个对象和一个自定义的DisposerRecord接口实现类,一起传入进去,进行注册。 Disposer类会唤起“Java2D Disposer”线程,该线程会扫描已注册的这些对象是否要被回收了,如果是,则调用该对象对应的DisposerRecord实现类里面的dispose方法。 Disposer实际上不限于在awt应用场景,只是awt里面的很多组件需要访问很多操作系统资源,所以,这些组件在被回收时,需要先释放这些资源。 |
|
InsttoolCacheScheduler_QuartzSchedulerThread |
Quartz |
InsttoolCacheScheduler_QuartzSchedulerThread是Quartz的主线程,它主要负责实时的获取下一个时间点要触发的触发器,然后执行触发器相关联的作业 。 原理大致如下: Spring和Quartz结合使用的场景下,Spring IOC容器初始化时会创建并初始化Quartz线程池(TreadPool),并启动它。刚启动时线程池中每个线程都处于等待状态,等待外界给他分配Runnable(持有作业对象的线程)。 继而接着初始化并启动Quartz的主线程 (InsttoolCacheScheduler_QuartzSchedulerThread),该线程自启动后就会处于等待状态。等待外界给出工作信号之后,该主线程的run方法才实质上开始工作。run中会获取JobStore中下一次要触发的作业,拿到之后会一直等待到该作业的真正触发时间,然后将该作业包装成一个JobRunShell对象(该对象实现了Runnable接口,其实看是上面TreadPool中等待外界分配给他的Runnable),然后将刚创建的JobRunShell交给线程池,由线程池负责执行作业。 线程池收到Runnable后,从线程池一个线程启动Runnable,反射调用JobRunShell中的run方法,run方法执行完成之后, TreadPool将该线程回收至空闲线程中。 |
|
InsttoolCacheScheduler_Worker-2 |
Quartz |
InsttoolCacheScheduler_Worker-2线程就是ThreadPool线程的一个简单实现,它主要负责分配线程资源去执行 InsttoolCacheScheduler_QuartzSchedulerThread线程交给它的调度任务(也就是JobRunShell)。 |
|
JBossLifeThread |
Jboss |
Jboss主线程启动成功,应用程序部署完毕之后将JBossLifeThread线程实例化并且start,JBossLifeThread线程启动成功之后就处于等待状态,以保持Jboss Java进程处于存活中。 所得比较通俗一点,就是Jboss启动流程执行完毕之后,为什么没有结束? 就是因为有这个线程hold主了它。 |
|
JBoss System Threads(1)-1 |
Jboss |
该线程是一个socket服务,默认端口号为: 1099。 主要用于接收外部naming service(Jboss JNDI)请求。 |
|
JCA PoolFiller |
Jboss |
该线程主要为JBoss内部提供连接池的托管。 简单介绍一下工作原理 : Jboss内部凡是有远程连接需求的类,都需要实现 ManagedConnectionFactory接口,例如需要做JDBC连接的 XAManagedConnectionFactory对象,就实现了该接口。 然后将XAManagedConnectionFactory对象, 还有其它信息一起包装到 InternalManagedConnectionPool 对象里面,接着将 InternalManagedConnectionPool 交给PoolFiller对象里面的列队进行管理。 JCA PoolFiller线程会定期判断列队内是否有需要创建和管理的 InternalManagedConnectionPool 对象,如果有的话,则调用该对象的fillToMin方法, 触发它去创建相应的远程连接,并且将这个连接维护到它相应的连接池里面去。 |
|
JDWP Event Helper Thread |
JVM |
JDWP是通讯交互协议,它定义了调试器和被调试程序之间传递信息的格式。它详细完整地定义了请求命令、回应数据和错误代码,保证了前端和后端的JVMTI和JDI的通信通畅。 该线程主要负责将JDI事件映射成JVMTI信号,以达到调试过程中操作JVM的目的。 |
|
JDWP Transport Listener: dt_socket |
JVM |
该线程是一个Java Debugger的监听器线程,负责受理客户端的debug请求。 通常我们习惯将它的监听端口设置为8787。 |
|
Low Memory Detector |
JVM |
这个线程是负责对可使用内存进行检测,如果发现可用内存低,分配新的内存空间。 |
|
process reaper |
JVM |
该线程负责去执行一个 OS 命令行的操作。 |
|
Reference Handler |
JVM |
JVM在创建main线程后就创建Reference Handler线程,其优先级最高,为10,它主要用于处理引用对象本身(软引用、弱引用、虚引用)的垃圾回收问题 。 |
|
Surrogate Locker Thread (CMS) |
JVM |
这个线程主要用于配合CMS垃圾回收器使用,它是一个守护线程,其主要负责处理GC过程中,Java层的Reference(指软引用、弱引用等等)与jvm 内部层面的对象状态同步。 这里对它们的实现稍微做一下介绍:这里拿 WeakHashMap做例子,将一些关键点先列出来(我们后面会将这些关键点全部串起来): 1.我们知道HashMap用Entry[]数组来存储数据的,WeakHashMap也不例外, 内部有一个Entry[]数组。 2. WeakHashMap的Entry比较特殊,它的继承体系结构为 Entry->WeakReference->Reference 。 3.Reference 里面有一个全局锁对象:Lock, 它也被称为pending_lock.注意:它是静态对象。 4. Reference 里面有一个静态变量:pending。 5. Reference里面有一个静态内部类:ReferenceHandler的线程,它在static块里面被初始化并且启动,启动完成后处于wait状态,它在一个Lock同步锁模块中等待。 6.另外,WeakHashMap里面还实例化了一个ReferenceQueue列队,这个列队的作用,后面会提到。 7.上面关键点就介绍完毕了,下面我们把他们串起来。 假设,WeakHashMap对象里面已经保存了很多对象的引用。 JVM 在进行CMS GC的时候,会创建一个ConcurrentMarkSweepThread(简称CMST)线程去进行GC,ConcurrentMarkSweepThread线程被创建的同时会创建一个SurrogateLockerThread(简称SLT)线程并且启动它,SLT启动之后,处于等待阶段。CMST开始GC时,会发一个消息给SLT让它去获取Java层Reference对象的全局锁:Lock。 直到CMS GC完毕之后,JVM 会将WeakHashMap中所有被回收的对象所属的WeakReference容器对象放入到Reference 的pending属性当中(每次GC完毕之后,pending属性基本上都不会为null了),然后通知SLT释放并且notify全局锁:Lock。此时激活了ReferenceHandler线程的run方法,使其脱离wait状态,开始工作了。ReferenceHandler这个线程会将pending中的所有WeakReference对象都移动到它们各自的列队当中,比如当前这个WeakReference属于某个WeakHashMap对象,那么它就会被放入相应的ReferenceQueue列队里面(该列队是链表结构)。 当我们下次从WeakHashMap对象里面get、put数据或者调用size方法的时候,WeakHashMap就会将ReferenceQueue列队中的WeakReference依依poll出来去和Entry[]数据做比较,如果发现相同的,则说明这个Entry所保存的对象已经被GC掉了,那么将Entry[]内的Entry对象剔除掉。 |
|
taskObjectTimerFactory |
JVM |
顾名思义,该线程就是用来执行任务的。 当我们把一个认为交给Timer对象,并且告诉它执行时间,周期时间后,Timer就会将该任务放入任务列队,并且通知taskObjectTimerFactory线程去处理任务,taskObjectTimerFactory线程会将状态为取消的任务从任务列队中移除,如果任务是非重复执行类型的,则在执行完该任务后,将它从任务列队中移除,如果该任务是需要重复执行的,则计算出它下一次执行的时间点。 |
|
VM Periodic Task Thread |
JVM |
该线程是JVM周期性任务调度的线程,它由WatcherThread创建,是一个单例对象。 该线程在JVM内使用得比较频繁,比如:定期的内存监控、JVM运行状况监控,还有我们经常需要去执行一些jstat 这类命令查看gc的情况,如下: jstat -gcutil 23483 250 7 这个命令告诉jvm在控制台打印PID为:23483的gc情况,间隔250毫秒打印一次,一共打印7次。 |
|
VM Thread |
JVM |
这个线程就比较牛b了,是jvm里面的线程母体,根据hotspot源码(vmThread.hpp)里面的注释,它是一个单例的对象(最原始的线程)会产生或触发所有其他的线程,这个单个的VM线程是会被其他线程所使用来做一些VM操作(如,清扫垃圾等)。 在 VMThread 的结构体里有一个VMOperationQueue列队,所有的VM线程操作(vm_operation)都会被保存到这个列队当中,VMThread 本身就是一个线程,它的线程负责执行一个自轮询的loop函数(具体可以参考: VMThread.cpp里面的 void VMThread::loop()) ,该loop函数从VMOperationQueue列队中按照优先级取出当前需要执行的操作对象(VM_Operation), 并且调用VM_Operation->evaluate函数去执行该操作类型本身的业务逻辑。 ps:VM操作类型被定义在 vm_operations.hpp文件内,列举几个:ThreadStop、 ThreadDump、 PrintThreads、 GenCollectFull、GenCollectFullConcurrent、CMS_Initial_Mark、CMS_Final_Remark….. |
参考文章:
http://jameswxx.iteye.com/blog/1041173
http://blog.csdn.net/wanyanxgf/article/details/6944987
http://blog.csdn.net/fanshadoop/article/details/8509218
http://www.7dtest.com/site/article-80-1.html
http://blog.csdn.net/a43350860/article/details/8134234
https://weblogs.java.net/blog/mandychung/archive/2005/11/thread_dump_and_1.html