一、读取文件
1)读取文件内容



import pandas info = pandas.read_csv('1.csv',encoding='gbk') # 获取文件信息 print(info) print(type(info)) # 查看文件类型 print(info.dtypes) # 查看每列文件的类型 print(help(pandas.read_csv))

2)获取文件的信息
import pandas info = pandas.read_csv('1.csv',encoding='gbk') print(info.head(3)) # 获取前 3 行的信息 print(info.tail(3)) # 获取后 3 行的信息 print(info.columns) # 获取到每列的名字 print(info.shape) # 获取行列,(29, 10) 29行10列 print(info.loc[1]) # 获取第一行的数据 print(info.loc[0:2]) # 切面,获取前3行数据 print(info.loc[[2,5,10]]) # 获取指定行的数据 print(info["承诺完成时间点"]) # 获取该列的数据 print(info[["提交人","承诺完成时间点"]]) # 获取多列的信息 print(info.loc[22,"提交人"]) # 定位到具体的某一个位置
获取以什么结尾的列的信息
import pandas info = pandas.read_csv('1.csv',encoding='gbk') # 获取以“人”为结尾的列的信息 col_names = info.columns.tolist() # print(col_names) gram_columns = [] for c in col_names: if c.endswith("人"): gram_columns.append(c) gram_df = info[gram_columns] print(gram_df)
3)获取经过调整的文件信息
import pandas info = pandas.read_csv('1.csv',encoding='gbk') print(info['完成状态']*10) # 该列的每一个值都乘以100 print(info['完成状态'].max()) # 获取该列的最大值 print(info['完成状态'].min()) # 获取该列的最小值 # ################################ # 调整排序顺序 info.sort_values("完成状态",inplace=True,ascending=False) # 默认是升序排序。ascending=False 设置了这个,则是降序 print(info["完成状态"])
重新按照索引值排序
info = pd.read_csv('1.csv',encoding='gbk')
.........
# 顺序被打乱后
info2 = info.reset_index(drop=True) # 重做索引
4)查看缺失值
import pandas as pd info = pd.read_csv('1.csv',encoding='gbk') date = info["完成状态"] # print(date_ti) date_ti_null = pd.isnull(date) # 获取到每一个值是否有,有就返回False,没有返回True print(date_ti_null) date_ti_true = date[date_ti_null] # 获取到缺失值的信息位置 print(date_ti_true) age_null_count = len(date_ti_true) # 计算缺少值的个数 print(age_null_count)
5)计算平均值,需要去掉缺失值
import pandas as pd info = pd.read_csv('1.csv',encoding='gbk') average = sum(info["完成状态"]) / len(info["完成状态"]) print(average) # nan 因为有缺失值,所有不能直接计算 date = info['完成状态'] date_ti_null = pd.isnull(date) good_date = info['完成状态'][date_ti_null == False] print(good_date) correct_average = sum(good_date) / len(good_date) print(correct_average) # 计算正确的平均值 # =============================================== print(info["完成状态"].mean()) # 直接计算平均值
6)计算关联信息直接的数据
import pandas as pd import numpy as np info = pd.read_csv('1.csv',encoding='gbk') message = info.pivot_table(index="提交人",values="完成状态",aggfunc=np.sum) # 分析数据,计算index与value的关系的和,np.sum是和,np.mean是平均值 print(message) message2 = info.pivot_table(index="预估工时(天)",values="完成状态") # aggfunc=np.mean 默认计算平均值 print(message2)
8)删除掉有缺失值的行
import pandas as pd info = pd.read_csv('1.csv',encoding='gbk') drop_columns = info.dropna(axis=1) print(drop_columns) new_info = info.dropna(axis=0,subset=["任务名称","提交人"]) # 删除掉有缺失值的行 print(new_info)
9)利用函数来简化操作
import pandas as pd info = pd.read_csv('1.csv',encoding='gbk') # 自定义含义获取该行的信息 def hundredth_row(column): hundredth_item = column.loc[22] return hundredth_item hundredth_row = info.apply(hundredth_row) print(hundredth_row) # 查看所有列缺失值的个数 def not_null_count(column): column_null = pd.isnull(column) null = column[column_null] return len(null) column_null_count = info.apply(not_null_count) print(column_null_count) # 修改获取到值的状态 def which_class(row): pclass = row["完成状态"] if pd.isnull(pclass): return "Unknown" elif pclass == 1: return "First Class" elif pclass == 2: return "Second Class" else: return "Third Class" classes = info.apply(which_class,axis = 1) print(classes) # 修改某一阶段的值 def is_minor(row): if row["完成状态"] < 2: return True else: return False minors = info.apply(is_minor,axis=1) print(minors)
二、总结
info = pandas.read_csv('1.csv',encoding='gbk') # 获取文件信息 type(info) # 查看文件类型 info.dtypes # 查看每列文件的类型 info.head(3) # 获取前 3 行的信息 info.tail(3) # 获取后 3 行的信息 info.columns # 获取到每列的名字 info.shape # 获取行列,(29, 10) 29行10列 info.loc[1] # 获取第一行的数据 info.loc[0:2] # 切面,获取前3行数据 info.loc[[2,5,10]] # 获取指定行的数据 info["承诺完成时间点"] # 获取该列的数据 info[["提交人","承诺完成时间点"]] # 获取多列的信息 ==================================================== info = pandas.read_csv('1.csv',encoding='gbk') info['完成状态']*10 # 该列的每一个值都乘以100 info['完成状态'].max() # 获取该列的最大值 info['完成状态'].min() # 获取该列的最小值 info.sort_values("完成状态",inplace=True,ascending=False) # 默认是升序排序。ascending=False 设置了这个,则是降序 print(info["完成状态"]) # 查看上面排序的情况 pd.isnull(info["完成状态"]) # 查看是否有缺失值 info["完成状态"].mean() # 直接计算平均值 ============================================== info.pivot_table(index="提交人",values="完成状态",aggfunc=np.sum) # 分析关联信息直接的数据 info.dropna(axis=0,subset=["任务名称","提交人"]) # 删除掉有缺失值的行 info.loc[22,"提交人"] # 定位 ============================== import pandas info = pandas.read_csv('1.csv',encoding='gbk') print(info.head(3)) # 获取前 3 行的信息 print(info.tail(3)) # 获取后 3 行的信息 print(info.columns) # 获取到每列的名字 print(info.shape) # 获取行列,(29, 10) 29行10列 print(info.loc[1]) # 获取第一行的数据 print(info.loc[0:2]) # 切面,获取前3行数据 print(info.loc[[2,5,10]]) # 获取指定行的数据 print(info["承诺完成时间点"]) # 获取该列的数据 print(info[["提交人","承诺完成时间点"]]) # 获取多列的信息 print(info.loc[22,"提交人"]) # 定位到具体的某一个位置 from pandas import Series:Series结构,前面熟练了,再了解
相关文章链接 : https://www.cnblogs.com/why957/p/9303780.html
三、数据分析,绘制单图形
1)生成绘图栏
import matplotlib.pylab as plt plt.plot() plt.show()
2)将下面数据绘制成折线图
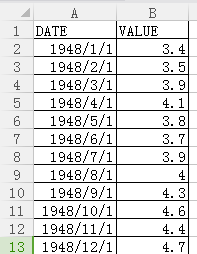
使用pandas模块拿到数据
import pandas as pd info = pd.read_csv('2.csv',encoding='gbk') info["DATE"] = pd.to_datetime(info["DATE"]) print(info.head(12))
相当于拿这些数据绘制折线图
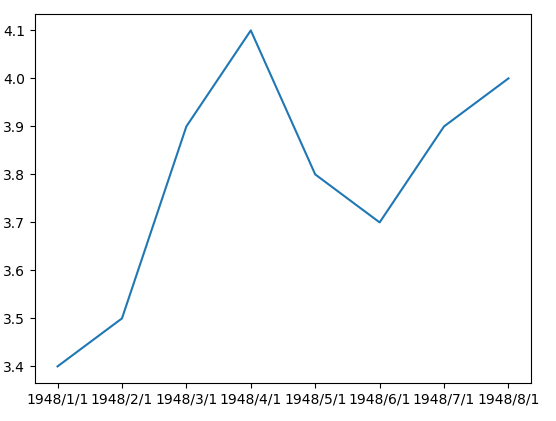
使用数据绘制图形
import pandas as pd import matplotlib.pylab as plt info = pd.read_csv('2.csv',encoding='gbk') first_twelve = info[0:8] plt.plot(first_twelve["DATE"],first_twelve["VALUE"]) plt.show()
可以更改坐标的倾斜度。plt.xticks(rotation=45)
import pandas as pd import matplotlib.pylab as plt info = pd.read_csv('2.csv',encoding='gbk') first_twelve = info[0:9] plt.plot(first_twelve["DATE"],first_twelve["VALUE"]) plt.xticks(rotation=45) plt.show()

可以增加标题
import pandas as pd import matplotlib.pylab as plt info = pd.read_csv('2.csv',encoding='gbk') first_twelve = info[0:9] plt.plot(first_twelve["DATE"],first_twelve["VALUE"]) plt.xticks(rotation=45) plt.xlabel('Month') plt.ylabel('Money') plt.title('1948.Month and Money') plt.show()
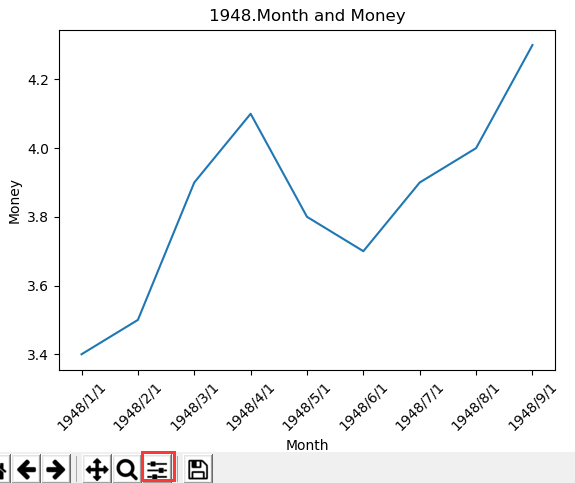
对于横坐标的bug调整,日期格式,以及如果要求显示的的长度过长,会出现线性故障
import pandas as pd import matplotlib.pylab as plt unrate = pd.read_csv('2.csv',encoding='gbk') unrate["DATE"] = pd.to_datetime(unrate["DATE"]) # 调整坐标日期格式 first_twelve = unrate[0:12] # 坐标出现的长度 plt.plot(first_twelve["DATE"],first_twelve["VALUE"]) plt.xticks(rotation=45) plt.xlabel('Month') plt.ylabel('Money') plt.title('1948.Month and Money') plt.show()

二、绘制多图形
1)生成子图形
import matplotlib.pylab as plt fig = plt.figure() ax1 = fig.add_subplot(2,2,1) ax2 = fig.add_subplot(2,2,2) ax3 = fig.add_subplot(2,2,4) plt.show()
ax1 = fig.add_subplot(2,2,1) # 图形为2行2列的第1个图形
ax2 = fig.add_subplot(2,2,2) # 图形为2行2列的第2个图形
ax3 = fig.add_subplot(2,2,4) # 图形为2行2列的第4个图形

2)figsize=(3,6) 绘图的长度,长宽
import numpy as np import matplotlib.pylab as plt fig = plt.figure(figsize=(3,6)) # figsize=(3,6) 绘图的长度,长宽 ax1 = fig.add_subplot(2,1,1) ax2 = fig.add_subplot(2,1,2) ax1.plot(np.random.randint(1,5,5),np.arange(5)) ax2.plot(np.arange(10)*3,np.arange(10)) plt.show()
3)在同一个图绘制2条折线图
import pandas as pd import matplotlib.pylab as plt unrate = pd.read_csv('2.csv',encoding='gbk') unrate["DATE"] = pd.to_datetime(unrate["DATE"]) # 调整坐标日期格式 fig = plt.figure(figsize=(6,3)) plt.plot(unrate[0:12]['DATE'],unrate[0:12]['VALUE'],c='red') plt.plot(unrate[12:24]['DATE'],unrate[12:24]['VALUE'],c='blue') plt.show()
4)循环绘制多条折线图
import pandas as pd import matplotlib.pylab as plt unrate = pd.read_csv('2.csv',encoding='gbk') unrate["DATE"] = pd.to_datetime(unrate["DATE"]) # 调整坐标日期格式 fig = plt.figure(figsize=(10,6)) colors = ['red','blue','green','orange','black'] for i in range(5): start_index = i*4 end_index = (i+1)*4 subset = unrate[start_index:end_index] plt.plot(subset['DATE'],subset['VALUE'],c = colors[i]) plt.show()
5)定义折现的含义
import pandas as pd import matplotlib.pylab as plt unrate = pd.read_csv('2.csv',encoding='gbk') unrate["DATE"] = pd.to_datetime(unrate["DATE"]) # 调整坐标日期格式 fig = plt.figure(figsize=(10,6)) colors = ['red','blue','green','orange','black'] for i in range(5): start_index = i*4 end_index = (i+1)*4 subset = unrate[start_index:end_index] label = str(1948 + i) plt.plot(subset['DATE'],subset['VALUE'],c = colors[i],label=label) # label=label 定义图标的名字 plt.legend(loc='best') # 定义图标放在哪个位置,best 系统感觉放在哪个位置好,就放哪 print(help(plt.legend)) plt.show()

四、绘制柱状图

1)获取csv文件的信息
import pandas as pd reviews = pd.read_csv('3.csv',encoding='gbk') cols = ['FILM','爱奇艺','哔哔站','优酷','土豆','凤凰卫士'] norm_reviews = reviews[cols] print(norm_reviews[:1])
FILM 爱奇艺 哔哔站 优酷 土豆 凤凰卫士
0 火影 7 6 8 9 8
将这些信息转换成图形
2)绘制成型的柱状图
import matplotlib.pyplot as plt from numpy import arange import pandas as pd reviews = pd.read_csv('3.csv',encoding='gbk') num_cols = ['爱奇艺','哔哔站','优酷','土豆','凤凰卫士'] norm_reviews = reviews[num_cols] bar_heights = norm_reviews.ix[0, num_cols].values print(bar_heights) bar_positions = arange(5) + 1 print(bar_positions) fig,ax = plt.subplots() ax.bar(bar_positions,bar_heights, 0.3) plt.show()
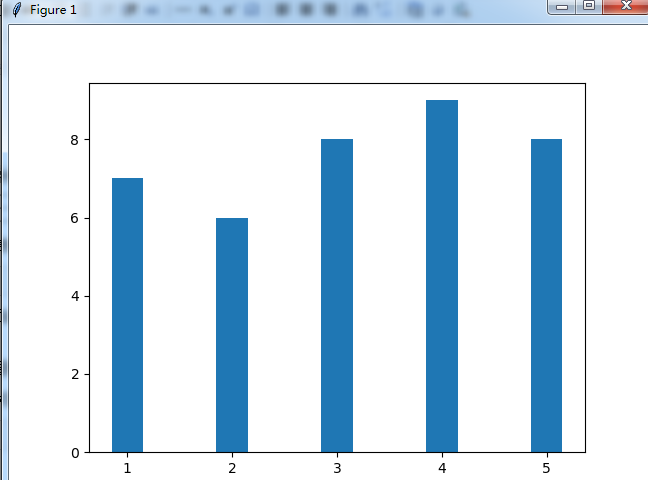
3)加上标题,坐标名称。注意不识别中文
import matplotlib.pyplot as plt from numpy import arange import pandas as pd reviews = pd.read_csv('3.csv',encoding='gbk') num_cols = ['aiqiyi','哔哔站','优酷','土豆','凤凰卫士'] norm_reviews = reviews[num_cols] bar_heights = norm_reviews.ix[0, num_cols].values print(bar_heights) bar_positions = arange(5) + 1 print(bar_positions) tick_positions = range(1,6) fig,ax = plt.subplots() ax.bar(bar_positions,bar_heights, 0.3) ax.set_xticks(tick_positions) ax.set_xticklabels(num_cols,rotation=45) ax.set_xlabel('source') ax.set_ylabel('TV') ax.set_title('ping web') plt.show() plt.close()
4)横向柱状图。只需要修改这里即可。ax.barh(bar_positions,bar_heights, 0.3)
import matplotlib.pyplot as plt from numpy import arange import pandas as pd reviews = pd.read_csv('3.csv',encoding='gbk') num_cols = ['aiqiyi','哔哔站','优酷','土豆','凤凰卫士'] norm_reviews = reviews[num_cols] bar_heights = norm_reviews.ix[0, num_cols].values print(bar_heights) bar_positions = arange(5) + 1 print(bar_positions) tick_positions = range(1,6) fig,ax = plt.subplots() ax.barh(bar_positions,bar_heights, 0.3) ax.set_xticks(tick_positions) ax.set_xticklabels(num_cols,rotation=45) ax.set_xlabel('source') ax.set_ylabel('TV') ax.set_title('ping web') plt.show() plt.close()

5)绘制散点图,横坐标是一个网站的评分,纵坐标是另一个网站的评分
import matplotlib.pyplot as plt import pandas as pd reviews = pd.read_csv('3.csv',encoding='gbk') num_cols = ['aiqiyi','哔哔站','优酷','土豆','凤凰卫士'] norm_reviews = reviews[num_cols] fig,ax = plt.subplots() ax.scatter(norm_reviews['aiqiyi'],norm_reviews['哔哔站']) ax.set_xlabel('Fandango') ax.set_ylabel('Rotten Tommtoes') plt.show() plt.close()

6)绘制多条散点图
import matplotlib.pyplot as plt import pandas as pd reviews = pd.read_csv('3.csv',encoding='gbk') num_cols = ['aiqiyi','哔哔站','优酷','土豆','凤凰卫士'] norm_reviews = reviews[num_cols] fig = plt.figure(figsize=(5,10)) ax1 = fig.add_subplot(2,1,1) ax2 = fig.add_subplot(2,1,2) ax1.scatter(norm_reviews['aiqiyi'],norm_reviews['哔哔站']) ax1.set_xlabel('Fandango') ax1.set_ylabel('Rotten Tommtoes') ax2.scatter(norm_reviews['优酷'],norm_reviews['凤凰卫士']) ax2.set_xlabel('Fandango') ax2.set_ylabel('Rotten Tommtoes') plt.show() plt.close()
