背景 :
在使用搜索引擎和电商的搜索功能时,大家一定遇到过这样的情景:我想搜索博客园,可不小心输成博客员了,不用担心搜不到你想要的结果,因为建立在大数据上的搜索引擎会帮你自动纠错,就这个例子Google和Baidu返回给我的分别是:
显示以下查询字词的结果: 博客园 和 您要找的是不是: 博客园 ,他们都做到了自动纠错,关于自动纠错我之前也写过一篇陋文,当时是自己实现的N-Gram模型,但是效果不是太好,主要是针对不同的语料库算法的精确度是不一样的,我想换个算法试试看,目前主流的计算串间的距离(相反的,你也可以理解为相似度)是Levenshtein,当要实现时,发现lucene已经做了这个事,那咱就站在巨人的肩膀上成长吧。
引用包:
lucene-core-3.1.0.jar + lucene-spellchecker-3.1.0.jar,你可以在这里得到
使用示例:
在类SpellCorrector的main方法中加入以下代码
1 //创建目录 2 File dict = new File(""); 3 Directory directory = FSDirectory.open(dict); 4 5 //实例化拼写检查器 6 SpellChecker sp = new SpellChecker(directory); 8 9 //创建词典 10 File dictionary = new File(SpellCorrecter.class.getResource("dictionary.txt").getFile()); 11 12 //对词典进行索引 13 sp.indexDictionary(new PlainTextDictionary(dictionary)); 15 16 //有错别字的搜索 17 String search = "非常勿扰"; 18 19 20 //建议个数,这里我只想要最接近的那一个,你可以设置成别的数字,如3 21 int suggestionNumber = 1; 22 24 //获取建议的关键字 25 String[] suggestions = sp.suggestSimilar(search, suggestionNumber); 27 28 //显示结果 29 System.out.println("搜索:" + search); 31 32 for (String word : suggestions) { 33 System.out.println("你要找的是不是:" + word); 34 } 35
注:这之前你需要有个语料库,我这里是个存放正确视频名称的文件,格式如下:
1 红颜血泪 2 冰上火一般的激情 3 在敌之手 4 驰风竞艇王第二部 5 钓金龟 6 潇湘路一号 7 戏里戏外第二季 8 草原狼爵士乐 9 拯救大兵瑞恩
好了,接下来就直接运行吧,见下图:
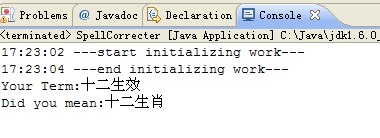
完整代码和字典在这里(限于工作原因,字典只保留部分电影名称,你可以用你自己的语料库)
有问题请联系我jeexianwu#gmail.com
参考文献
- http://lucene.apache.org/java/docs/
- http://today.java.net/pub/a/today/2005/08/09/didyoumean.html
- http://archsofty.blogspot.com/2009/12/adicione-o-recurso-voce-quis-dizer-nas.html
- http://lucene.apache.org/java/3_0_0/api/contrib-spellchecker/index.html
- http://en.wikipedia.org/wiki/Edit_distance
- http://en.wikipedia.org/wiki/Levenshtein_distance
- http://en.wikipedia.org/wiki/Jaro-Winkler_distance