内存管理内幕:
http://www.ibm.com/developerworks/cn/linux/l-memory/
linux进程内存布局:
http://mqzhuang.iteye.com/
http://mqzhuang.iteye.com/blog/901602
内存管理是操作系统的核心之一,最近在研究内核的内存管理以及 C 运行时库对内存的分配和管理,涉及到进程在内存的布局,在此对进程的内存布局做一下总结:
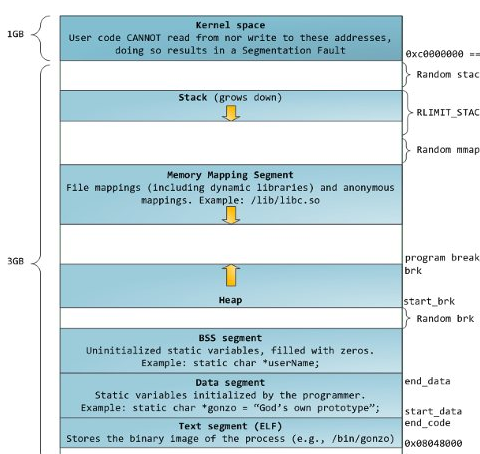
1. 32 位模式下的 linux 内存布局

图上的各个部分描述得比较清楚,不需再做过多的描述。从上图可以看到,栈至顶向下扩展,并且栈是有界的。堆至底向上扩展, mmap 映射区域至顶向下扩展, mmap 映射区域和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域,这种结构便于 C 运行时库使用 mmap 映射区域和堆进行内存分配。上图的布局形式是在内核 2.6.7 以后才引入的,这是 32 位模式下的默认内存布局形式。看看 cat 命令在 2.6.36 上内存布局:
08048000-08051000 r-xp 00000000 08:01 786454 /bin/cat
08051000-08052000 r--p 00008000 08:01 786454 /bin/cat
08052000-08053000 rw-p 00009000 08:01 786454 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
b73e3000-b75e3000 r--p 00000000 08:01 400578 /usr/lib/locale/locale-archive
b75e3000-b75e4000 rw-p 00000000 00:00 0
b75e4000-b773b000 r-xp 00000000 08:01 1053967 /lib/libc-2.12.1.so
b773b000-b773c000 ---p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b773c000-b773e000 r--p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b773e000-b773f000 rw-p 00159000 08:01 1053967 /lib/libc-2.12.1.so
b773f000-b7742000 rw-p 00000000 00:00 0
b774f000-b7750000 r--p 002a1000 08:01 400578 /usr/lib/locale/locale-archive
b7750000-b7752000 rw-p 00000000 00:00 0
b7752000-b7753000 r-xp 00000000 00:00 0 [vdso]
b7753000-b776f000 r-xp 00000000 08:01 1049013 /lib/ld-2.12.1.so
b776f000-b7770000 r--p 0001b000 08:01 1049013 /lib/ld-2.12.1.so
b7770000-b7771000 rw-p 0001c000 08:01 1049013 /lib/ld-2.12.1.so
bfbed000-bfc0e000 rw-p 00000000 00:00 0 [stack]
可以看到,栈和 mmap 映射区域并不是从一个固定地址开始,并且每次的值都不一样,这是程序在启动时随机改变这些值的设置,使得使用缓冲区溢出进行攻击更加困难。当然也可以让程序的栈和 mmap 映射区域从一个固定位置开始,只需要设置全局变量 randomize_v a_space 值为 0 ,这个变量默认值为 1 。用户可以通过设置/proc/sys/kernel/randomize_va_space 来停用该特性,也可以用如下命令:
sudo sysctl -w kernel.randomize_va_space=0
设置 randomize_va_space 为 0 后,再看看 cat 的内存布局:
08048000-08051000 r-xp 00000000 08:01 786454 /bin/cat
08051000-08052000 r--p 00008000 08:01 786454 /bin/cat
08052000-08053000 rw-p 00009000 08:01 786454 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
b7c72000-b7e72000 r--p 00000000 08:01 400578 /usr/lib/locale/locale-archive
b7e72000-b7e73000 rw-p 00000000 00:00 0
b7e73000-b7fca000 r-xp 00000000 08:01 1053967 /lib/libc-2.12.1.so
b7fca000-b7fcb000 ---p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b7fcb000-b7fcd000 r--p 00157000 08:01 1053967 /lib/libc-2.12.1.so
b7fcd000-b7fce000 rw-p 00159000 08:01 1053967 /lib/libc-2.12.1.so
b7fce000-b7fd1000 rw-p 00000000 00:00 0
b7fde000-b7fdf000 r--p 002a1000 08:01 400578 /usr/lib/locale/locale-archive
b7fdf000-b7fe1000 rw-p 00000000 00:00 0
b7fe1000-b7fe2000 r-xp 00000000 00:00 0 [vdso]
b7fe2000-b7ffe000 r-xp 00000000 08:01 1049013 /lib/ld-2.12.1.so
b7ffe000-b7fff000 r--p 0001b000 08:01 1049013 /lib/ld-2.12.1.so
b7fff000-b8000000 rw-p 0001c000 08:01 1049013 /lib/ld-2.12.1.so
bffdf000-c0000000 rw-p 00000000 00:00 0 [stack]
可以看出,栈和 mmap 区域都从固定位置开始了, stack 的起始位置为 0x c0000000 , mmap 区域的起始位置为 0xb8000000 ,可见系统为 stack 区域保留了 128M 内存地址空间。
在某些情况下,设置 randomize_va_space 为 0 ,便于对系统做一些针对性的研究,例如:进程的内存映射有个叫vdso 的区域,也就是用 ldd 命令看到的那个” linux-gate.so.1 “,这块区域可以看成是内核用于实现 vsyscall 而创建的 virtual shared object ,遵循 elf 的格式,并且可以被用户程序访问。在设置 randomize_va_space 为 0 的情况下,使用如下命令就可以把这个区域 dump 出来看过究竟。如果不设置 randomize_va_space ,每次 vdso 的地址都是随机的,下面的命令也无能为力。
zhuang@ubuntu:~$ dd if=/proc/self/mem of=gate.so bs=4096 skip=$[0xb7fe1] count=1
dd: `/proc/self/mem': cannot skip to specified offset
1+0 records in
1+0 records out
4096 bytes (4.1 kB) copied, 0.00144225 s, 2.8 MB/s
zhuang@ubuntu:~$ objdump -d gate.so
gate.so: file format elf32-i386
Disassembly of section .text:
ffffe400 <__kernel_sigreturn>:
ffffe400: 58 pop %eax
ffffe401: b8 77 00 00 00 mov $0x77,%eax
ffffe406: cd 80 int $0x80
ffffe408: 90 nop
ffffe409: 8d 76 00 lea 0x0(%esi),%esi
ffffe40c <__kernel_rt_sigreturn>:
ffffe40c: b8 ad 00 00 00 mov $0xad,%eax
ffffe411: cd 80 int $0x80
ffffe413: 90 nop
ffffe414 <__kernel_vsyscall>:
ffffe414: 51 push %ecx
ffffe415: 52 push %edx
ffffe416: 55 push %ebp
ffffe417: 89 e5 mov %esp,%ebp
ffffe419: 0f 34 sysenter
ffffe41b: 90 nop
ffffe41c: 90 nop
ffffe41d: 90 nop
ffffe41e: 90 nop
ffffe41f: 90 nop
ffffe420: 90 nop
ffffe421: 90 nop
ffffe422: eb f3 jmp ffffe417 <__kernel_vsyscall+0x3>
ffffe424: 5d pop %ebp
ffffe425: 5a pop %edx
ffffe426: 59 pop %ecx
ffffe427: c3 ret
2. 32 为模式下的经典布局:

这种布局 mmap 区域与栈区域相对增长,这意味着堆只有 1GB 的虚拟地址空间可以使用,继续增长就会进入mmap 映射区域,这显然不是我们想要的。这是由于 32 模式地址空间限制造成的,所以 内核引入了前一种虚拟地址空间的布局形式。但是对 64 位模式,提供了巨大的虚拟地址空间,这个布局就相当好。如果要在 2.6.7 以后的内核上使用 32 位模式内存经典布局,有两种办法可以设置:
方法一: sudo sysctl -w vm.legacy_va_layout=1
方法二: ulimit -s unlimited
同时设置 randomize_va_space 为 0 后, cat 的内存布局已经回到经典形式了:
08048000-08051000 r-xp 00000000 08:01 786454 /bin/cat
08051000-08052000 r--p 00008000 08:01 786454 /bin/cat
08052000-08053000 rw-p 00009000 08:01 786454 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
40000000-4001c000 r-xp 00000000 08:01 1049013 /lib/ld-2.12.1.so
4001c000-4001d000 r--p 0001b000 08:01 1049013 /lib/ld-2.12.1.so
4001d000-4001e000 rw-p 0001c000 08:01 1049013 /lib/ld-2.12.1.so
4001e000-4001f000 r-xp 00000000 00:00 0 [vdso]
4001f000-40021000 rw-p 00000000 00:00 0
40021000-40022000 r--p 002a1000 08:01 400578 /usr/lib/locale/locale-archive
4002f000-40186000 r-xp 00000000 08:01 1053967 /lib/libc-2.12.1.so
40186000-40187000 ---p 00157000 08:01 1053967 /lib/libc-2.12.1.so
40187000-40189000 r--p 00157000 08:01 1053967 /lib/libc-2.12.1.so
40189000-4018a000 rw-p 00159000 08:01 1053967 /lib/libc-2.12.1.so
4018a000-4018e000 rw-p 00000000 00:00 0
4018e000-4038e000 r--p 00000000 08:01 400578 /usr/lib/locale/locale-archive
bffdf000-c0000000 rw-p 00000000 00:00 0 [stack]
3. 64 位模式下的内存布局
在 64 位模式下各个区域的起始位置是什么呢?对于 AMD64 , 内存布局采用的是经典模式, text 的起始地址为0x0000000000400000 ,堆紧接着 BSS 段向上增长, mmap 映射区域开始位置一般设为 TASK_SIZE/3 ,
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
#define TASK_SIZE (test_thread_flag(TIF_IA32) ?
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define STACK_TOP TASK_SIZE
#define TASK_UNMAPPED_BASE (PAGE_ALIGN(TASK_SIZE / 3))
计算一下可知, mmap 的开始区域地址为 0x0000 2AAAAAAAA000,栈顶地址为 0x0000 7FFFFFFFF000

brk(), sbrk() 用法详解:
http://blog.csdn.net/sgbfblog/article/details/7772153
brk() , sbrk() 的声明如下:
- #include <unistd.h>
- int brk(void *addr);
- void *sbrk(intptr_t increment);
这两个函数都用来改变 "program break" (程序间断点)的位置,这个位置可参考下图:
如 man 里说的:
引用brk() and sbrk() change the location of the program break, which defines the end of the process's data segment (i.e., the program break is the first location after the end of the uninitialized data segment).
brk() 和 sbrk() 改变 "program brek" 的位置,这个位置定义了进程数据段的终止处(也就是说,program break 是在未初始化数据段终止处后的第一个位置)。
如此翻译过来,似乎会让人认为这个 program break 是和上图中矛盾的,上图中的 program break 是在堆的增长方向的第一个位置处(堆和栈的增长方向是相对的),而按照说明手册来理解,似乎是在 bss segment 结束那里(因为未初始化数据段一般认为是 bss segment)。
首先说明一点,一个程序一旦编译好后,text segment ,data segment 和 bss segment 是确定下来的,这也可以通过 objdump 观察到。下面通过一个程序来测试这个 program break 是不是在 bss segment 结束那里:
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <sys/time.h>
- #include <sys/resource.h>
- int bssvar; //声明一个味定义的变量,它会放在 bss segment 中
- int main(void)
- {
- char *pmem;
- long heap_gap_bss;
- printf ("end of bss section:%p ", (long)&bssvar + 4);
- pmem = (char *)malloc(32); //从堆中分配一块内存区,一般从堆的开始处获取
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p ", pmem);
- //计算堆的开始地址和 bss segment 结束处得空隙大小,注意每次加载程序时这个空隙都是变化的,但是在同一次加载中它不会改变
- heap_gap_bss = (long)pmem - (long)&bssvar - 4;
- printf ("1-gap between heap and bss:%lu ", heap_gap_bss);
- free (pmem); //释放内存,归还给堆
- sbrk(32); //调整 program break 位置(假设现在不知道这个位置在堆头还是堆尾)
- pmem = (char *)malloc(32); //再一次获取内存区
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p ", pmem); //检查和第一次获取的内存区的起始地址是否一样
- heap_gap_bss = (long)pmem - (long)&bssvar - 4; //计算调整 program break 后的空隙
- printf ("2-gap between heap and bss:%lu ", heap_gap_bss);
- free(pmem); //释放
- return 0;
- }
下面,我们分别运行两次程序,并查看其输出:
引用[beyes@localhost C]$ ./sbrk
end of bss section:0x8049938
pmem:0x82ec008
1-gap between heap and bss:2762448
pmem:0x82ec008
2-gap between heap and bss:2762448
[beyes@localhost C]$ ./sbrk
end of bss section:0x8049938
pmem:0x8dbc008
1-gap between heap and bss:14100176
pmem:0x8dbc008
2-gap between heap and bss:14100176
从上面的输出中,可以发现几点:
1. bss 段一旦在在程序编译好后,它的地址就已经规定下来。
2. 一般及简单的情况下,使用 malloc() 申请的内存,释放后,仍然归还回原处,再次申请同样大小的内存区时,还是从第 1 次那里获得。
3. bss segment 结束处和堆的开始处的空隙大小,并不因为 sbrk() 的调整而改变,也就是说明了 program break 不是调整堆头部。
所以,man 手册里所说的 “program break 是在未初始化数据段终止处后的第一个位置” ,不能将这个位置理解为堆头部。这时,可以猜想应该是在堆尾部,也就是堆增长方向的最前方。下面用程序进行检验:
当 sbrk() 中的参数为 0 时,我们可以找到 program break 的位置。那么根据这一点,检查一下每次在程序加载时,系统给堆的分配是不是等同大小的:
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <sys/time.h>
- #include <sys/resource.h>
- int main(void)
- {
- void *tret;
- char *pmem;
- pmem = (char *)malloc(32);
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p ", pmem);
- tret = sbrk(0);
- if (tret != (void *)-1)
- printf ("heap size on each load: %lu ", (long)tret - (long)pmem);
- return 0;
- }
运行上面的程序 3 次:
引用[beyes@localhost C]$ ./sbrk
pmem:0x80c9008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x9682008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x9a7d008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x8d92008
heap size on each load: 135160
[beyes@localhost C]$ vi sbrk.c
从输出可以看到,虽然堆的头部地址在每次程序加载后都不一样,但是每次加载后,堆的大小默认分配是一致的。但是这不是不能改的,可以使用 sysctl 命令修改一下内核参数:
引用#sysctl -w kernel/randomize_va_space=0
这么做之后,再运行 3 次这个程序看看:
引用[beyes@localhost C]$ ./sbrk
pmem:0x804a008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x804a008
heap size on each load: 135160
[beyes@localhost C]$ ./sbrk
pmem:0x804a008
heap size on each load: 135160
从输出看到,每次加载后,堆头部的其实地址都一样了。但我们不需要这么做,每次堆都一样,容易带来缓冲区溢出攻击(以前老的 linux 内核就是特定地址加载的),所以还是需要保持 randomize_va_space 这个内核变量值为 1 。
下面就来验证 sbrk() 改变的 program break 位置在堆的增长方向处:
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <sys/time.h>
- #include <sys/resource.h>
- int main(void)
- {
- void *tret;
- char *pmem;
- int i;
- long sbrkret;
- pmem = (char *)malloc(32);
- if (pmem == NULL) {
- perror("malloc");
- exit (EXIT_FAILURE);
- }
- printf ("pmem:%p ", pmem);
- for (i = 0; i < 65; i++) {
- sbrk(1);
- printf ("%d ", sbrk(0) - (long)pmem - 0x20ff8); //0x20ff8 就是堆和 bss段 之间的空隙常数;改变后要用 sbrk(0) 再次获取更新后的program break位置
- }
- free(pmem);
- return 0;
- }
运行输出:
引用[beyes@localhost C]$ ./sbrk
pmem:0x804a008
1
2
3
4
5
... ...
61
62
63
64
从输出看到,sbrk(1) 每次让堆往栈的方向增加 1 个字节的大小空间。
而 brk() 这个函数的参数是一个地址,假如你已经知道了堆的起始地址,还有堆的大小,那么你就可以据此修改 brk() 中的地址参数已达到调整堆的目的。
实际上,在应用程序中,基本不直接使用这两个函数,取而代之的是 malloc() 一类函数,这一类库函数的执行效率会更高。 还需要注意一点,当使用 malloc() 分配过大的空间,比如超出 0x20ff8 这个常数(在我的系统(Fedora15)上是这样,别的系统可能会有变)时,malloc 不再从堆中分配空间,而是使用 mmap() 这个系统调用从映射区寻找可用的内存空间。
mmap详解:
http://kenby.iteye.com/blog/1164700
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式, 因为进程可以直接读写内存,而不需要任何
数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则
只拷贝两次数据: 一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内
存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直
到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映
射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
一. 传统文件访问
UNIX访问文件的传统方法是用open打开它们, 如果有多个进程访问同一个文件, 则每一个进程在自己的地址空间都包含有该
文件的副本,这不必要地浪费了存储空间. 下图说明了两个进程同时读一个文件的同一页的情形. 系统要将该页从磁盘读到高
速缓冲区中, 每个进程再执行一个存储器内的复制操作将数据从高速缓冲区读到自己的地址空间.

二. 共享存储映射
现在考虑另一种处理方法: 进程A和进程B都将该页映射到自己的地址空间, 当进程A第一次访问该页中的数据时, 它生成一
个缺页中断. 内核此时读入这一页到内存并更新页表使之指向它.以后, 当进程B访问同一页面而出现缺页中断时, 该页已经在
内存, 内核只需要将进程B的页表登记项指向次页即可. 如下图所示:

三、mmap()及其相关系统调用
mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以向访
问普通内存一样对文件进行访问,不必再调用read(),write()等操作。
mmap()系统调用形式如下:
void* mmap ( void * addr , size_t len , int prot , int flags , int fd , off_t offset )
mmap的作用是映射文件描述符fd指定文件的 [off,off + len]区域至调用进程的[addr, addr + len]的内存区域, 如下图所示:

参数fd为即将映射到进程空间的文件描述字,一般由open()返回,同时,fd可以指定为-1,此时须指定flags参数中的
MAP_ANON,表明进行的是匿名映射(不涉及具体的文件名,避免了文件的创建及打开,很显然只能用于具有亲缘关系的
进程间通信)。
len是映射到调用进程地址空间的字节数,它从被映射文件开头offset个字节开始算起。
prot 参数指定共享内存的访问权限。可取如下几个值的或:PROT_READ(可读) , PROT_WRITE (可写), PROT_EXEC (可执行), PROT_NONE(不可访问)。
flags由以下几个常值指定:MAP_SHARED , MAP_PRIVATE , MAP_FIXED,其中,MAP_SHARED , MAP_PRIVATE必
选其一,而MAP_FIXED则不推荐使用。
offset参数一般设为0,表示从文件头开始映射。
参数addr指定文件应被映射到进程空间的起始地址,一般被指定一个空指针,此时选择起始地址的任务留给内核来完成。函
数的返回值为最后文件映射到进程空间的地址,进程可直接操作起始地址为该值的有效地址。
- aaaaaaaaa
- bbbbbbbbb
- ccccccccc
- ddddddddd
- #include <sys/mman.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <error.h>
- #define BUF_SIZE 100
- int main(int argc, char **argv)
- {
- int fd, nread, i;
- struct stat sb;
- char *mapped, buf[BUF_SIZE];
- for (i = 0; i < BUF_SIZE; i++) {
- buf[i] = '#';
- }
- /* 打开文件 */
- if ((fd = open(argv[1], O_RDWR)) < 0) {
- perror("open");
- }
- /* 获取文件的属性 */
- if ((fstat(fd, &sb)) == -1) {
- perror("fstat");
- }
- /* 将文件映射至进程的地址空间 */
- if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
- PROT_WRITE, MAP_SHARED, fd, 0)) == (void *)-1) {
- perror("mmap");
- }
- /* 映射完后, 关闭文件也可以操纵内存 */
- close(fd);
- printf("%s", mapped);
- /* 修改一个字符,同步到磁盘文件 */
- mapped[20] = '9';
- if ((msync((void *)mapped, sb.st_size, MS_SYNC)) == -1) {
- perror("msync");
- }
- /* 释放存储映射区 */
- if ((munmap((void *)mapped, sb.st_size)) == -1) {
- perror("munmap");
- }
- return 0;
- }
- #include <sys/mman.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <error.h>
- #define BUF_SIZE 100
- int main(int argc, char **argv)
- {
- int fd, nread, i;
- struct stat sb;
- char *mapped, buf[BUF_SIZE];
- for (i = 0; i < BUF_SIZE; i++) {
- buf[i] = '#';
- }
- /* 打开文件 */
- if ((fd = open(argv[1], O_RDWR)) < 0) {
- perror("open");
- }
- /* 获取文件的属性 */
- if ((fstat(fd, &sb)) == -1) {
- perror("fstat");
- }
- /* 将文件映射至进程的地址空间 */
- if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
- PROT_WRITE, MAP_SHARED, fd, 0)) == (void *)-1) {
- perror("mmap");
- }
- /* 文件已在内存, 关闭文件也可以操纵内存 */
- close(fd);
- /* 每隔两秒查看存储映射区是否被修改 */
- while (1) {
- printf("%s ", mapped);
- sleep(2);
- }
- return 0;
- }
- #include <sys/mman.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <error.h>
- #define BUF_SIZE 100
- int main(int argc, char **argv)
- {
- int fd, nread, i;
- struct stat sb;
- char *mapped, buf[BUF_SIZE];
- for (i = 0; i < BUF_SIZE; i++) {
- buf[i] = '#';
- }
- /* 打开文件 */
- if ((fd = open(argv[1], O_RDWR)) < 0) {
- perror("open");
- }
- /* 获取文件的属性 */
- if ((fstat(fd, &sb)) == -1) {
- perror("fstat");
- }
- /* 私有文件映射将无法修改文件 */
- if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
- PROT_WRITE, MAP_PRIVATE, fd, 0)) == (void *)-1) {
- perror("mmap");
- }
- /* 映射完后, 关闭文件也可以操纵内存 */
- close(fd);
- /* 修改一个字符 */
- mapped[20] = '9';
- return 0;
- }
- #include <sys/mman.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #define BUF_SIZE 100
- int main(int argc, char** argv)
- {
- char *p_map;
- /* 匿名映射,创建一块内存供父子进程通信 */
- p_map = (char *)mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE,
- MAP_SHARED | MAP_ANONYMOUS, -1, 0);
- if(fork() == 0) {
- sleep(1);
- printf("child got a message: %s ", p_map);
- sprintf(p_map, "%s", "hi, dad, this is son");
- munmap(p_map, BUF_SIZE); //实际上,进程终止时,会自动解除映射。
- exit(0);
- }
- sprintf(p_map, "%s", "hi, this is father");
- sleep(2);
- printf("parent got a message: %s ", p_map);
- return 0;
- }

总结一下就是, 文件大小, mmap的参数 len 都不能决定进程能访问的大小, 而是容纳文件被映射部分的最小页面数决定
进程能访问的大小. 下面看一个实例:
- #include <sys/mman.h>
- #include <sys/types.h>
- #include <sys/stat.h>
- #include <fcntl.h>
- #include <unistd.h>
- #include <stdio.h>
- int main(int argc, char** argv)
- {
- int fd,i;
- int pagesize,offset;
- char *p_map;
- struct stat sb;
- /* 取得page size */
- pagesize = sysconf(_SC_PAGESIZE);
- printf("pagesize is %d ",pagesize);
- /* 打开文件 */
- fd = open(argv[1], O_RDWR, 00777);
- fstat(fd, &sb);
- printf("file size is %zd ", (size_t)sb.st_size);
- offset = 0;
- p_map = (char *)mmap(NULL, pagesize * 2, PROT_READ|PROT_WRITE,
- MAP_SHARED, fd, offset);
- close(fd);
- p_map[sb.st_size] = '9'; /* 导致总线错误 */
- p_map[pagesize] = '9'; /* 导致段错误 */
- munmap(p_map, pagesize * 2);
- return 0;
- }
glibc中malloc的详解:
http://blog.csdn.net/eroswang/article/details/4130972
glibc中的malloc实现:
The main properties of the algorithms are:
* For large (>= 512 bytes) requests, it is a pure best-fit allocator,
with ties normally decided via FIFO (i.e. least recently used).
* For small (<= 64 bytes by default) requests, it is a caching
allocator, that maintains pools of quickly recycled chunks.
* In between, and for combinations of large and small requests, it does
the best it can trying to meet both goals at once.
* For very large requests (>= 128KB by default), it relies on system
memory mapping facilities, if supported.
应用程序是从0x8048000开始,那是由linker定的,具体数值在一linker脚本定的,具 体在哪忘了,只在linux上是这样,到其它的平台上,可能就是另外一个值了,这只是个约定。0x804a008到0x8048000之间是程序 的.text,.data,.bss等内容。
而mmap分配的内存地址从0x40000000开始是由linux内核定的(见《深入理解linux内核》第三版最后一章),2.6.9以前的默认开始地址。当要分配的内存小于128K时malloc使用brk()向内核申请内存,所以开始地址离 0x8048000很近,而当要分配的内存大于了128K时,glibc的malloc就用mmap()向内核要内存,所以开始地址离0x40000000很近。
mmap()的开始地址,在2.6.9以后,在/proc中有个开关,可以改变这个地址,新的地址是从0xc0000000开始倒数128到129M中的 一个页对齐的数作为开始地址,具体的请看ULK3的最后一章吧。
从0x40000000~0xc0000000之间是mmap,stack,env,arg。mmap从小向大增涨,从0xc0000000开始为,env,arg(具体顺序记不清了),主程序的stack。
-------------------
在glibc的malloc的实现中, 分配虚存有两种系统调用可用: brk()和mmap(), 如果要分配大块内存, glibc会使用mmap()去分配内存,这种内存靠近栈. 你可以通过:
#include <malloc.h>
mallopt(M_MMAP_THRESHOLD, 内存块大小), 这样只有超过这个"内存块大小"的malloc才会使用mmap(), 其他使用brk, 使用brk()从贴近heap的地方开始分配.
-------------------------------
在glibc的malloc的实现有一个优化,
1. 当你malloc()一块很小的内存是, glibc调用brk(), 只需要在heap中移动一下指针, 即可获得可用虚存, 这样分配得到的地址较小.
2. 当你malloc()一块较大内存时, glibc调用mmap(), 需要在内核中重新分配vma结构等, 他会在靠近栈的地方分配虚存, 这样返回的地址大.
3. 这个较小和较小的临界值是一个通过mallopt()调整的.
4. 当然, 除了上面的规则, malloc()还有自己的算法, 来判断到底采用mmap()还是brk(), 一般和虚存碎片有关.
---------------------------------
追溯到在 Apple II 上进行汇编语言编程的时代,那时内存管理还不是个大问题。您实际上在运行整个系统。系统有多少内存,您就有多少内存。您甚至不必费心思去弄明白它有多少内 存,因为每一台机器的内存数量都相同。所以,如果内存需要非常固定,那么您只需要选择一个内存范围并使用它即可。
不过,即使是在这样一个简单的计算机中,您也会有问题,尤其是当您不知道程序的每个部分将需要多少内存时。如果您的空间有限,而内存需求是变化的,那么您需要一些方法来满足这些需求:
- 确定您是否有足够的内存来处理数据。
- 从可用的内存中获取一部分内存。
- 向可用内存池(pool)中返回部分内存,以使其可以由程序的其他部分或者其他程序使用。
实现这些需求的程序库称为 分配程序(allocators),因为它们负责分配和回收内存。程序的动态性越强,内存管理就越重要,您的内存分配程序的选择也就更重要。让我们来了解可用于内存管理的不同方法,它们的好处与不足,以及它们最适用的情形。
C 风格的内存分配程序
C 编程语言提供了两个函数来满足我们的三个需求:
- malloc:该函数分配给定的字节数,并返回一个指向它们的指针。如果没有足够的可用内存,那么它返回一个空指针。
- free:该函数获得指向由
malloc分配的内存片段的指针,并将其释放,以便以后的程序或操作系统使用(实际上,一些malloc实现只能将内存归还给程序,而无法将内存归还给操作系统)。
物理内存和虚拟内存
要理解内存在程序中是如何分配的,首先需要理解如何将内存从操作系统分配给程序。计算机上的每一个进程都认为自己可以访问所有的物理内存。显然,由于同时在运行多个程序,所以每个进程不可能拥有全部内存。实际上,这些进程使用的是 虚拟内存。
只是作为一个例子,让我们假定您的程序正在访问地址为 629 的内存。不过,虚拟内存系统不需要将其存储在位置为 629 的 RAM 中。实际上,它甚至可以不在 RAM 中 —— 如果物理 RAM 已经满了,它甚至可能已经被转移到硬盘上!由于这类地址不必反映内存所在的物理位置,所以它们被称为虚拟内存。操作系统维持着一个虚拟地址到物理地址的转 换的表,以便计算机硬件可以正确地响应地址请求。并且,如果地址在硬盘上而不是在 RAM 中,那么操作系统将暂时停止您的进程,将其他内存转存到硬盘中,从硬盘上加载被请求的内存,然后再重新启动您的进程。这样,每个进程都获得了自己可以使用 的地址空间,可以访问比您物理上安装的内存更多的内存。
在 32-位 x86 系统上,每一个进程可以访问 4 GB 内存。现在,大部分人的系统上并没有 4 GB 内存,即使您将 swap 也算上, 每个进程所使用的内存也肯定少于 4 GB。因此,当加载一个进程时,它会得到一个取决于某个称为 系统中断点(system break)的 特定地址的初始内存分配。该地址之后是未被映射的内存 —— 用于在 RAM 或者硬盘中没有分配相应物理位置的内存。因此,如果一个进程运行超出了它初始分配的内存,那么它必须请求操作系统“映射进来(map in)”更多的内存。(映射是一个表示一一对应关系的数学术语 —— 当内存的虚拟地址有一个对应的物理地址来存储内存内容时,该内存将被映射。)
基于 UNIX 的系统有两个可映射到附加内存中的基本系统调用:
- brk:
brk()是一个非常简单的系统调用。还记得系统中断点吗?该位置是进程映射的内存边界。brk()只是简单地将这个位置向前或者向后移动,就可以向进程添加内存或者从进程取走内存。 - mmap:
mmap(),或者说是“内存映像”,类似于brk(),但是更为灵活。首先,它可以映射任何位置的内存,而不单单只局限于进程。其次,它不仅可以将虚拟地址映射到物理的 RAM 或者 swap,它还可以将它们映射到文件和文件位置,这样,读写内存将对文件中的数据进行读写。不过,在这里,我们只关心mmap向进程添加被映射的内存的能力。munmap()所做的事情与mmap()相反。
如您所见, brk() 或者 mmap() 都可以用来向我们的进程添加额外的虚拟内存。在我们的例子中将使用 brk(),因为它更简单,更通用。
实现一个简单的分配程序
如果您曾经编写过很多 C 程序,那么您可能曾多次使用过 malloc() 和 free()。不过,您可能没有用一些时间去思考它们在您的操作系统中是如何实现的。本节将向您展示 malloc 和 free 的一个最简化实现的代码,来帮助说明管理内存时都涉及到了哪些事情。
要试着运行这些示例,需要先 复制本代码清单,并将其粘贴到一个名为 malloc.c 的文件中。接下来,我将一次一个部分地对该清单进行解释。
在大部分操作系统中,内存分配由以下两个简单的函数来处理:
void *malloc(long numbytes):该函数负责分配numbytes大小的内存,并返回指向第一个字节的指针。void free(void *firstbyte):如果给定一个由先前的malloc返回的指针,那么该函数会将分配的空间归还给进程的“空闲空间”。
malloc_init 将是初始化内存分配程序的函数。它要完成以下三件事:将分配程序标识为已经初始化,找到系统中最后一个有效内存地址,然后建立起指向我们管理的内存的指针。这三个变量都是全局变量:
清单 1. 我们的简单分配程序的全局变量
|
如前所述,被映射的内存的边界(最后一个有效地址)常被称为系统中断点或者 当前中断点。在很多 UNIX® 系统中,为了指出当前系统中断点,必须使用 sbrk(0) 函数。 sbrk 根据参数中给出的字节数移动当前系统中断点,然后返回新的系统中断点。使用参数 0 只是返回当前中断点。这里是我们的malloc 初始化代码,它将找到当前中断点并初始化我们的变量:
清单 2. 分配程序初始化函数
|
现在,为了完全地管理内存,我们需要能够追踪要分配和回收哪些内存。在对内存块进行了 free 调用之后,我们需要做的是诸如将它们标记为未被使用的等事情,并且,在调用 malloc 时,我们要能够定位未被使用的内存块。因此, malloc 返回的每块内存的起始处首先要有这个结构:
清单 3. 内存控制块结构定义
|
现在,您可能会认为当程序调用 malloc 时这会引发问题 —— 它们如何知道这个结构?答案是它们不必知道;在返回指针之前,我们会将其移动到这个结构之后,把它隐藏起来。这使得返回的指针指向没有用于任何其他用途的内存。那样,从调用程序的角度来看,它们所得到的全部是空闲的、开放的内存。然后,当通过 free() 将该指针传递回来时,我们只需要倒退几个内存字节就可以再次找到这个结构。
在讨论分配内存之前,我们将先讨论释放,因为它更简单。为了释放内存,我们必须要做的惟一一件事情就是,获得我们给出的指针,回退 sizeof(struct mem_control_block) 个字节,并将其标记为可用的。这里是对应的代码:
清单 4. 解除分配函数
|
如您所见,在这个分配程序中,内存的释放使用了一个非常简单的机制,在固定时间内完成内存释放。分配内存稍微困难一些。以下是该算法的略述:
清单 5. 主分配程序的伪代码
|
我们主要使用连接的指针遍历内存来寻找开放的内存块。这里是代码:
清单 6. 主分配程序
|
这就是我们的内存管理器。现在,我们只需要构建它,并在程序中使用它即可。