前言
网上分析golang中map的源码的博客已经非常多了,随便一搜就有,而且也非常详细,所以如果我再来写就有点画蛇添足了(而且我也写不好,手动滑稽)。但是我还是要写,略略略,这篇博客的意义在于能从几张图片,然后用我最通俗的文字,让没看过源码的人最快程度上了解golang中map是怎么样的。
当然,因为简单,所以不完美。有很多地方省略了细节问题,如果你觉得没看够,或者本来就想了解详细情况的话在文末给出了一些非常不错的博客,当然有能力还是自己去阅读源码比较靠谱。
那么下面我将从这几个方面来说明,你先记住有下面几个方向,这样可以有一个大致的思路:
- 基础结构:golang中的map是什么样子的,是由什么数据结构组成的?
- 初始化:初始化之后map是怎么样的?
- get:如何获取一个元素?
- put:如何存放一个元素?
- 扩容:当存放空间不够的时候扩容是怎么扩的?
基础结构
图解

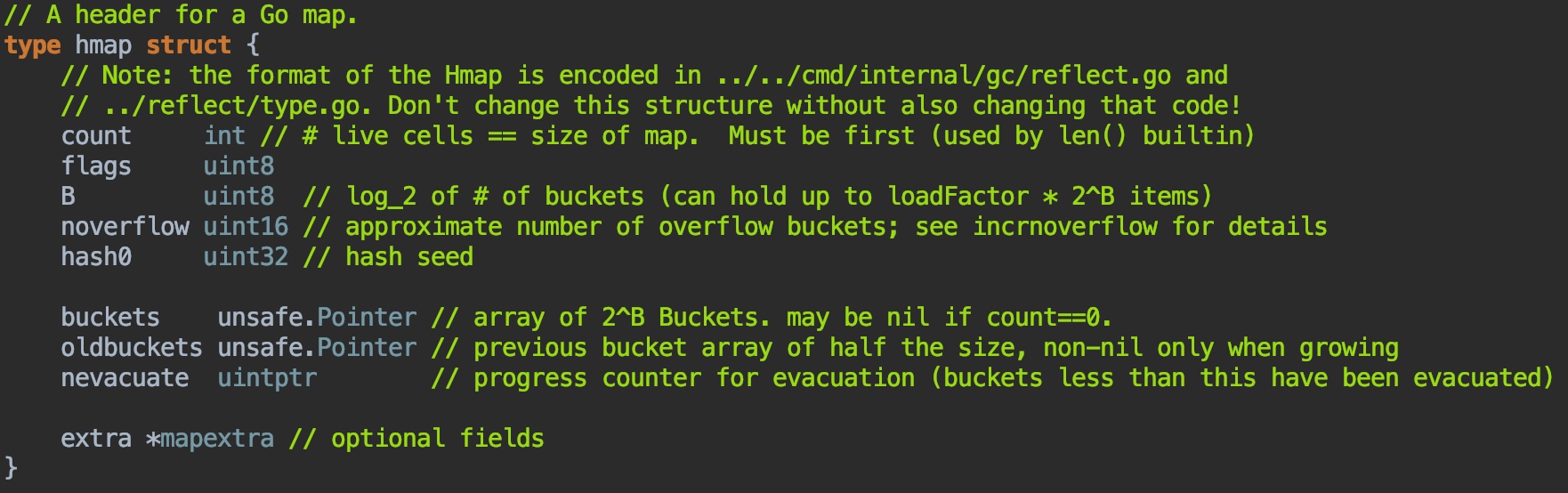
这个就是golang中map的结构,其实真的不复杂,我省略了其中一些和结构关系不大的字段,就只剩下这些了。
大话
大话来描述一些要点:
- 最外面是hmap结构体,用buckets存放一些名字叫bmap的桶(数量不定,是2的指数倍)
- bmap是一种有8个格子的桶(一定只有8个格子),每个格子存放一对key-value
- bmap有一个overflow,用于连接下一个bmap(溢出桶)
- hmap还有oldbuckets,用于存放老数据(用于扩容时)
- mapextra用于存放非指针数据(用于优化存储和访问),内部的overflow和oldoverflow实际还是bmap的数组。
这就是map的结构,然后我们稍微对比总结一下。
我们常见的map如java中的map是直接拿数组,数组中直接对应出了key-value,而在golang中,做了多加中间一层,buckets;java中如果key的哈希相同会采用链表的方式连接下去,当达到一定程度会转换红黑树,golang中直接类似链表连接下去,只不过连接下去的是buckets。
源码一瞥
- 下面附上源码中它们的样子,方便之后你自己阅读的时候有个印象(注意源码中的样子和编译之后是不同的哟,golang会根据map存放的类型不同来搞定它们实际的样子)
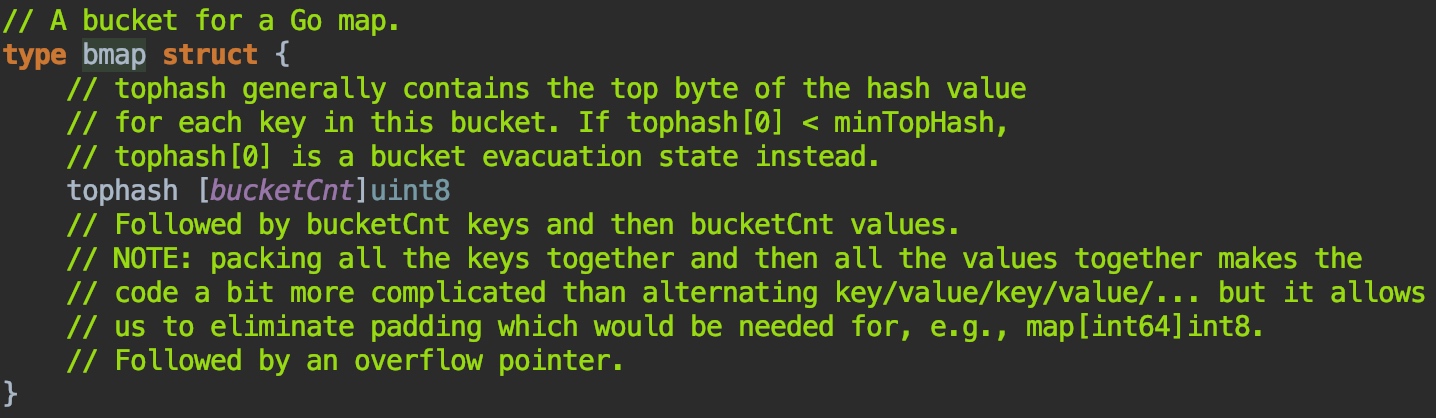
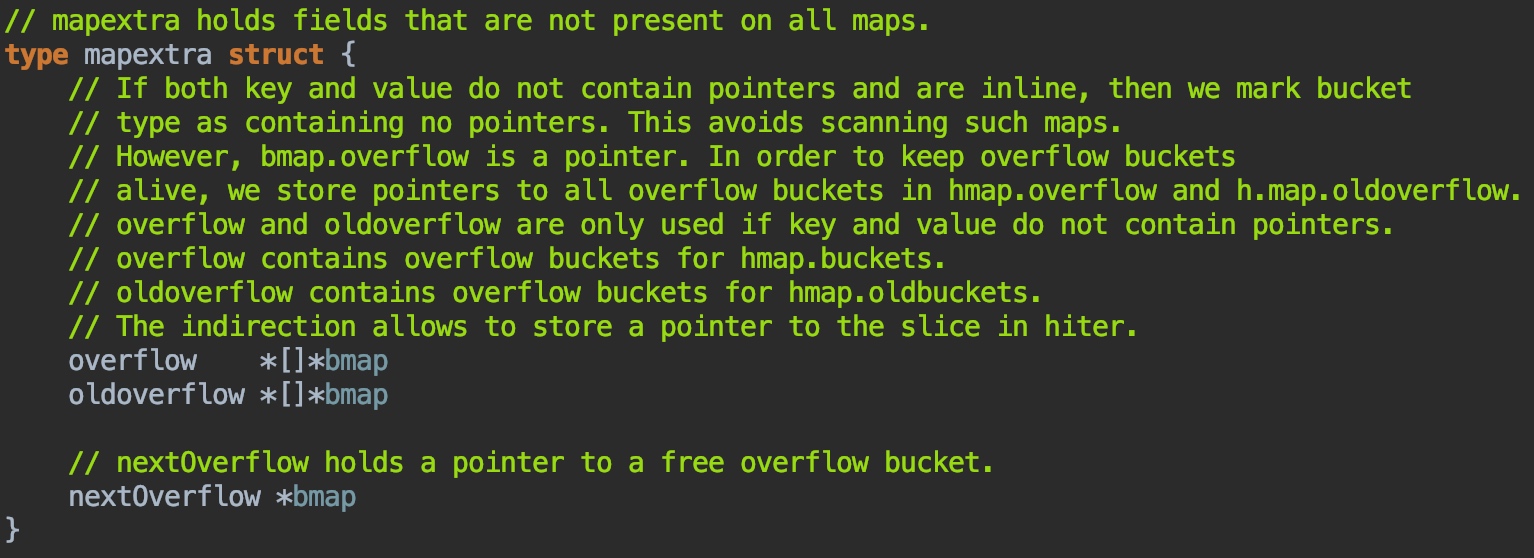
那么看完结构你肯定会有疑问?为什么要多一层8个格子的bucket呢?我们怎么确定放在8个格子其中的哪个呢?带着问题往下看。
初始化
源码一瞥
初始化就不需要图去说明了,因为初始化之后就是产生基础的一个结构,根据map中存放的类型不同。这里主要说明一下,初始化的代码放在什么位置。我也删除了其中一些代码,大致看看就好。
// makehmap_small implements Go map creation for make(map[k]v) and // make(map[k]v, hint) when hint is known to be at most bucketCnt // at compile time and the map needs to be allocated on the heap. func makemap_small() *hmap { h := new(hmap) h.hash0 = fastrand() return h } // makemap implements Go map creation for make(map[k]v, hint). // If the compiler has determined that the map or the first bucket // can be created on the stack, h and/or bucket may be non-nil. // If h != nil, the map can be created directly in h. // If h.buckets != nil, bucket pointed to can be used as the first bucket. func makemap(t *maptype, hint int, h *hmap) *hmap { ..... // initialize Hmap if h == nil { h = (*hmap)(newobject(t.hmap)) } h.hash0 = fastrand() // find size parameter which will hold the requested # of elements B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B ...... return h }
其中需要注意一个点:“B”,还记得刚才说名字叫bmap的桶数量是不确定的吗?这个B一定程度上表示的就是桶的数量,当然不是说B是3桶的数量就是3,而是2的3次方,也就是8;当B为5,桶的数量就是32;记住这个B,后面会用到它。
其实你想嘛,初始化还能干什么,最重要的肯定就是确定一开始要有多少个桶,初始的大小还是很重要的,还有一些别的初始化哈希种子等等,问题不大。我们的重点还是要放在存/取上面。
GET
图解
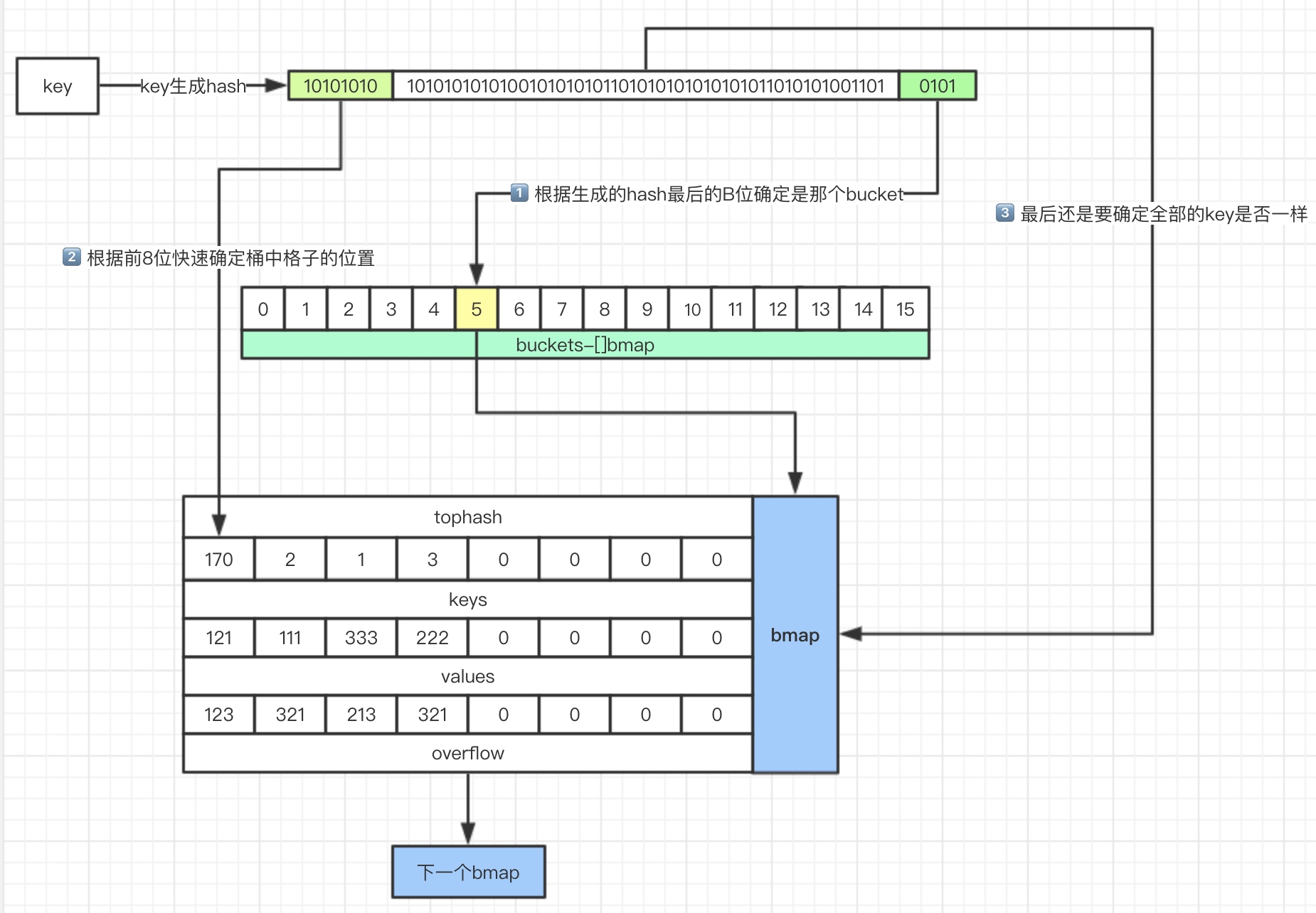
其实从结构上面来看,我们已经可以摸到一些门道了。先自己想一下,要从一个hashmap中获取一个元素,那么一定是通过key的哈希值去定位到这个元素,那么想着这个大致方向,看下面一张流程图来详细理解golang中是如何实现的。
大话
下面说明要点:
- 计算出key的hash
- 用最后的“B”位来确定在哪个桶(“B”就是前面说的那个,B为4,就有16个桶,0101用十进制表示为5,所以在5号桶)
- 根据key的前8位快速确定是在哪个格子(额外说明一下,在bmap中存放了每个key对应的tophash,是key的前8位)
- 最终还是需要比对key完整的hash是否匹配,如果匹配则获取对应value
- 如果都没有找到,就去下一个overflow找
总结一下:通过后B位确定桶,通过前8位确定格子,循环遍历连着的所有桶全部找完为止。
那么为什么要有这个tophash呢?因为tophash可以快速确定key是否正确,你可以把它理解成一种缓存措施,如果前8位都不对了,后面就没有必要比较了。
源码一瞥
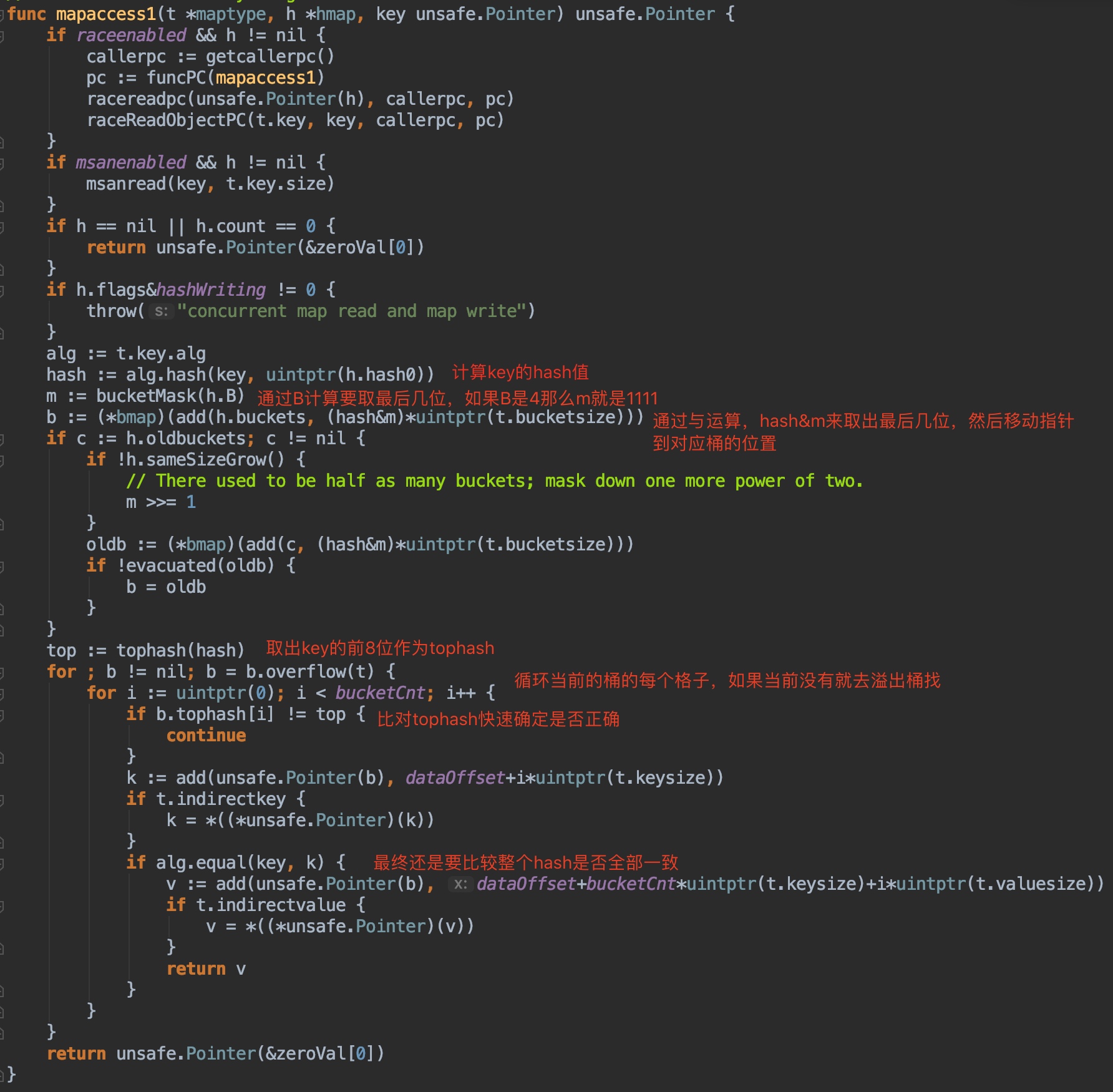
其中红色的字标出的地方说明了上面的关键点,最后有关key和value具体的存放方式和取出的定位不做深究,有兴趣可以看最后的参考博客。
PUT
其实当你知道了如何GET,那么PUT就没有什么难度了,因为本质是一样的。PUT的时候一样的方式去定位key的位置:
- 通过key的后“B”位确定是哪一个桶
- 通过key的前8位快速确定是否已经存在
- 最终确定存放位置,如果8个格子已经满了,没地方放了,那么就重新创建一个bmap作为溢出桶连接在overflow
图解
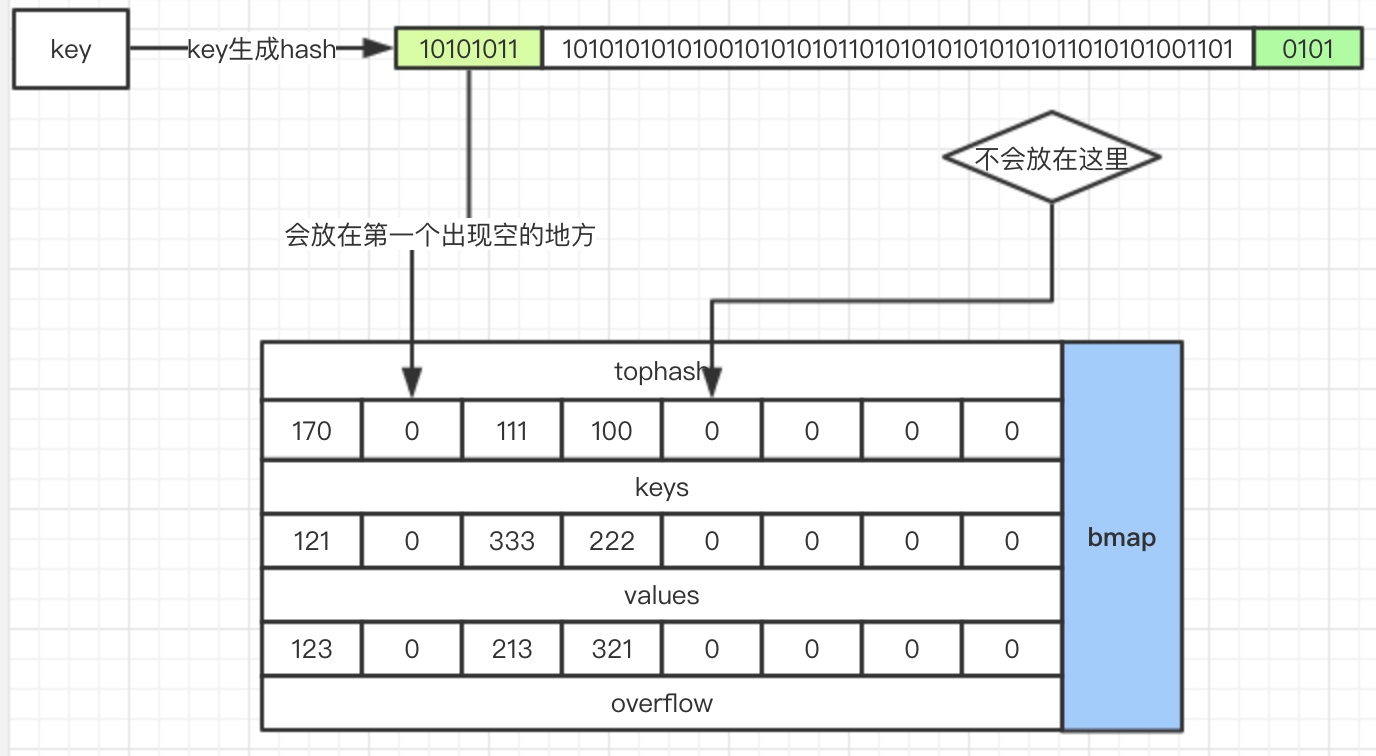
这里主要图解说明一下,如果新来的key发现前面有一个格子空着(这个情况是删除造成的),就会记录这个位置,当全部扫描完成之后发现自己确实是新来的,那么就会放前面那个空着的,而不会放最后(我把这个称为紧凑原则,尽可能保证数据存放紧凑,这样下次扫描会快)
代码位置
go/src/runtime/hashmap.go的mapassign函数就是map的put方法,因为代码很长这里就不多赘述了。
扩容
这个就是最复杂的地方了,但是呢?Don't worry我这里还是会省略其中某些部分,将最重要的地方拎出来。
扩容的方式
- 相同容量扩容
- 2倍容量扩容
啥意思呢?第一种出现的情况是:因为map不断的put和delete,出现了很多空格,这些空格会导致bmap很长,但是中间有很多空的地方,扫描时间变长。所以第一种扩容实际是一种整理,将数据整理到前面一起。第二种呢:就是真的不够用了,扩容两倍。
扩容的条件
装载因子
如果你看过Java的HashMap实现,就知道有个装载因子,同样的在golang中也有,但是不一样哦。装载因子的定义是这个样子:
loadFactor := count / (2B)
其中count为map中元素的个数,B就是之前个那个“B”
翻译一下就是装载因子 = (map中元素的个数)/(map当前桶的个数)
扩容条件1
装载因子 > 6.5(这个值是源码中写的)
其实意思就是,桶只有那么几个,但是元素很多,证明有很多溢出桶的存在(可以想成链表拉的太长了),那么扫描速度会很慢,就要扩容。
扩容条件2
overflow 的 bucket 数量过多:当 B 小于 15,如果 overflow 的 bucket 数量超过 2B ;当 B >= 15,如果 overflow 的 bucket 数量超过 215 。
其实意思就是,可能有一个单独的一条链拉的很长,溢出桶太多了,说白了就是,加入的key不巧,后B位都一样,一直落在同一个桶里面,这个桶一直放,虽然装载因子不高,但是扫描速度就很慢。
扩容条件3
当前不能正在扩容
图解
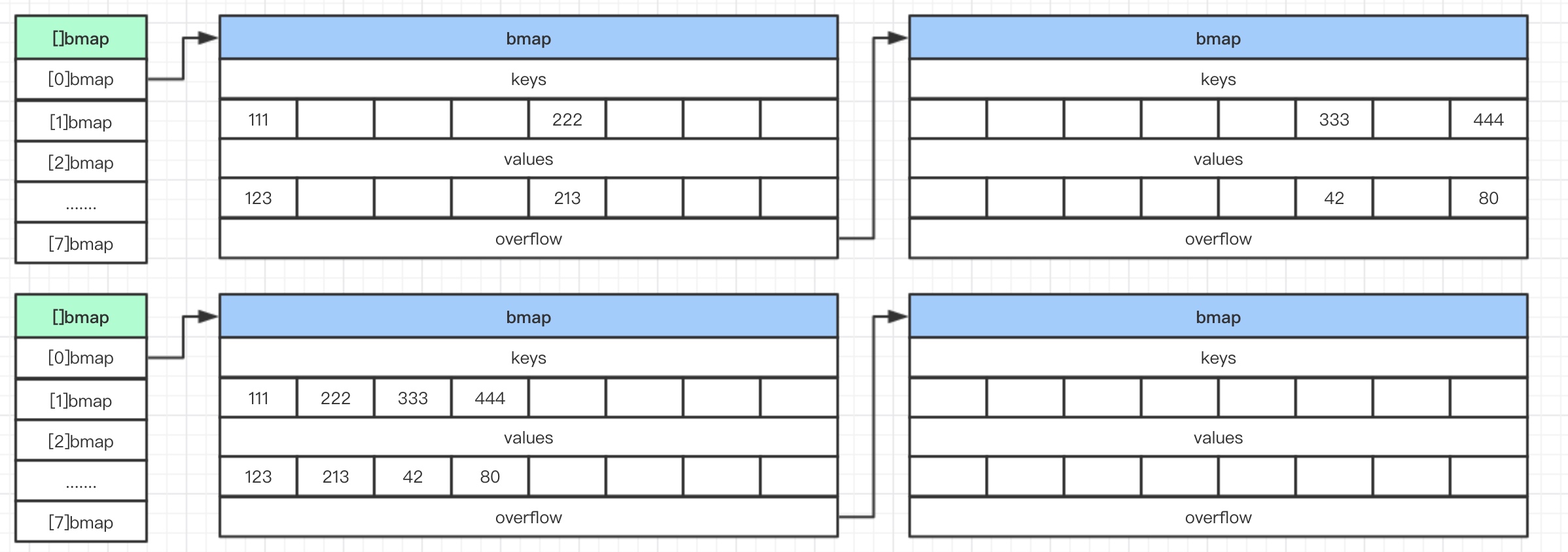
这张图表示的就是相同容量的扩容,实际上就是一种整理,将分散的数据集合到一起,提高扫描效率。(上面表示扩容之前,下面表示扩容之后)
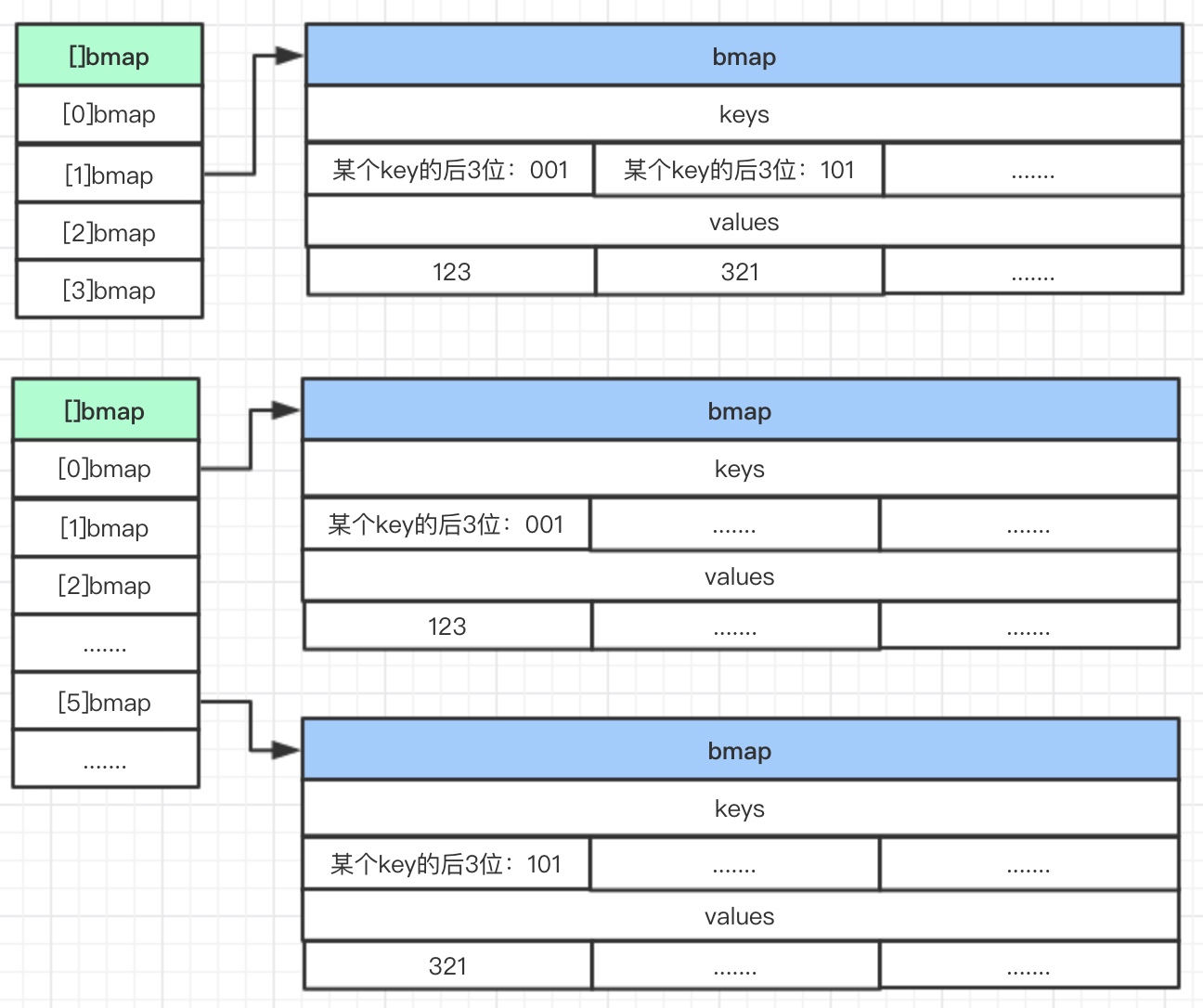
这张图表示的是就是2倍的扩容(上面表示扩容之前,下面表示扩容之后),如果有两个key后三位分别是001和101,当B=2时,只有4个桶,只看最后两位,这两个key后两位都是01所以在一个桶里面;扩容之后B=3,就会有8个桶,看后面三位,于是它们就分到了不同的桶里面。
大话
下面说一些扩容时的细节:
- 扩容不是一次性完成的,还记的我们hmap一开始有一个oldbuckets吗?是先将老数据存到这个里面
- 每次搬运1到2个bucket,当插入或修改、删除key触发
- 扩容之后肯定会影响到get和put,遍历的时候肯定会先从oldbuckets拿,put肯定也要考虑是否要放到新产生的桶里面去
源码一瞥

扩容的三个条件,看到了吗?这个地方在mapassign方法中。
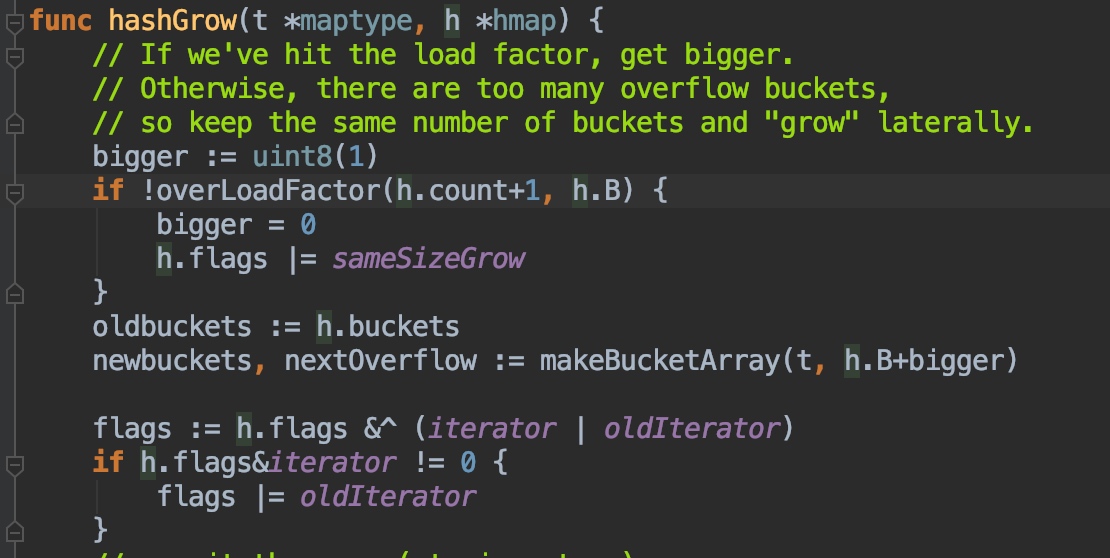
这里可以看到,注释也写的很清楚,如果是加载因子超出了,那么就2倍扩容,如果不是那么就是因为太多溢出桶了,sameSizeGrow表示就是相同容量扩容
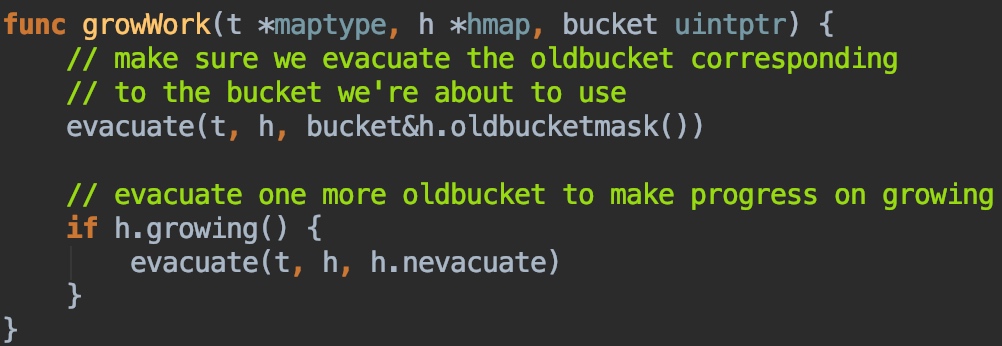
evacuate是搬运方法,这边可以看到,每次搬运是1到2个
evacuate实在是太长了,也非常复杂,但是情况就是图上描述的那样,有兴趣的可以详细去看,这里不截图说明了。
总结和小问题
至此你应该对于golang中的map有一个基本的认识了,你还可以去看看删除,你还可以去看看遍历等等,相信有了上面的基本认识那么应该不会难到你。下面有几个小问题:
- 是否线程安全?否,而且并发操作会抛出异常。
- 源码位置:src/runtime/hashmap.go
- 每次遍历map顺序是否一致?不一致,每次遍历会随机个数,通过随机数来决定从哪个元素开始。
写的仓促,难免疏漏,有问题的地方还请批评指正。
参考资料
如果你希望看到源码的各种细节讲解,下面这几篇是我学习的时候看的,供你参考,希望对你有帮助
https://github.com/qcrao/Go-Questions/tree/master/map
https://github.com/cch123/golang-notes/blob/master/map.md
https://draveness.me/golang-hashmap
https://lukechampine.com/hackmap.html
作者:LinkinStar
未经允许,不得转载