1 VOC2007基本信息
作为标准数据集, VOC 2007是衡量图像分类识别能级的基准。
Faster-rcnn, yolo-V1, yolo-v2都以此数据集作为演示样例,因此,有必要了解本数据集的组成构架。
VOC数据集包含:训练集(5011幅),测试集(4952幅),共计9963幅,共包含20个种类
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
2 各类别统计信息
20个类别中,后面数字代表数据集中对应的正样本图像个数(非目标个数)
训练集
aeroplane 238
bicycle 243
bird 330
boat 181
bottle 244
bus 186
car 713
cat 337
chair 445
cow 141
diningtable 200
dog 421
horse 287
motorbike 245
person 2008
pottedplant 245
sheep 96
sofa 229
train 261
tvmonitor 256
测试集
aeroplane 204
bicycle 239
bird 282
boat 172
bottle 212
bus 174
car 721
cat 322
chair 417
cow 127
diningtable 190
dog 418
horse 274
motorbike 222
person 2007
pottedplant 224
sheep 97
sofa 223
train 259
tvmonitor 229
可以看出,除了person数量较多,其他类别样本个数不算多,在如此小的数据集上,深度学习能获得较高的分类识别结果,足以说明深度学习的强大性能。
3. VOC2007具体信息
PASCAL VOC2012作为例子,下载地址为:host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
下载完之后解压,可以在VOCdevkit目录下的VOC2012中看到如下的文件:
数据集的组成结构如下:
Annotations--目标真值(金标准,Ground Truth)区域
ImageSets -- 类别标签
JPEGImages--图像
SegmentationClass
SegmentationObject
具体结构如下:
- Annotation
- *.xml
- ImageSets
- Action
- *_train.txt
- *_trainval.txt
- *_val.txt
- Layout
- train.txt
- trainval.txt
- val.txt
- Main
- *_train.txt
- *_trainval.txt
- *_val.txt
- Segmentation
- train.txt
- trainval.txt
- val.txt
- Action
- JPEGImages
- *.jpg
- SegmentationClass
- *.png
- SegmentationObject
- *.png
①JPEGImages
JPEGImages 文件夹中包含了PASCAL VOC所提供的所有图片信息,包括了训练图片和测试图片
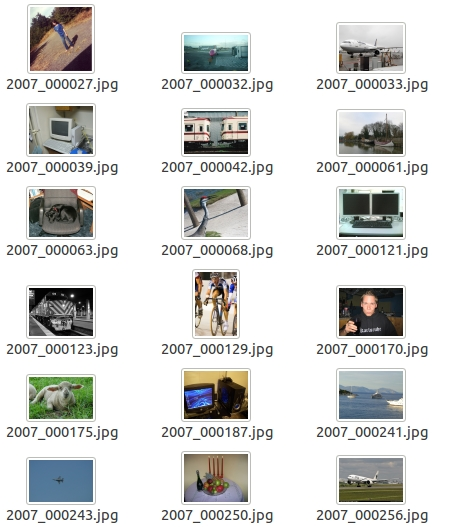
JPEGImages中存放原始图像,这些图像都是以“年份_编号.jpg”格式命名。图片的像素尺寸大小不一,一般为(横向图)500*375或(纵向图)375*500;基本不会偏差超过100。(在之后的训练中,第一步就是将这些图片都resize到300*300或500*500,所有原始图片不能远离标准过多。)这些图像就是用来进行训练和测试验证的图像数据集。
②Annotations
Annotations文件夹存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
xml文件的格式具体如下:(对于2007_000392.jpg)
<annotation>
<folder>VOC2012</folder>
<filename>2007_000392.jpg</filename> //文件名
<source> //图像来源(不重要)
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> //图像尺寸(长宽以及通道数)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> //是否用于分割(在图像物体识别中01无所谓)
<object> //检测到的物体
<name>horse</name> //物体类别
<pose>Right</pose> //拍摄角度
<truncated>0</truncated> //是否被截断(0表示完整)
<difficult>0</difficult> //目标是否难以识别(0表示容易识别)
<bndbox> //bounding-box(包含左下角和右上角xy坐标)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> //检测到多个物体
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
对应的图片为:

③ImageSets
ImageSets中有四个文件夹【Action】【Layout】【Main】【Segmentation】
ImageSets存放的每一个种类型的challenge对应的图像数据
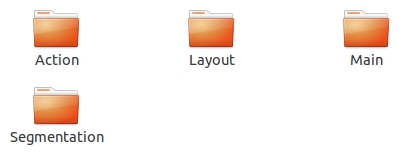
Action下存放的是人的动作(例如running, jumping等等,这也是VOC challenge的一部分)
Layout下存放的是具有人体部位的数据(人的head, hand, feet等等,这也是VOC challenge的一部分)
Main下存放的是图像物体识别的数据,总共分类20类
Segmentation下存放的是可用于分割的数据
分类识别只关注【Main】,它内部存储20个分类类别的标签,-1表示负样本,+1位正样本
*_train.txt训练样本集
*_val.txt评估样本集
*_trainval.txt训练与评估样本汇总
这些txt中的内容都差不多如下:
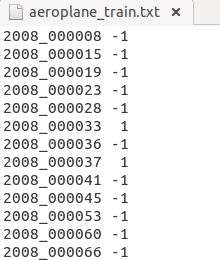
前面的表示图像的name,后面的1代表正样本,-1代表负样本
_train中存放的是训练使用的数据,每一个class的train数据都有5717个。
_val中存放的是验证结果使用的数据,每一个class有11540个。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据时,也应该是随机产生的。