为什么需要per-CPU变量
假设系统中有4个cpu, 同时有一个变量在各个CPU之间是共享的,每个cpu都有访问该变量的权限。
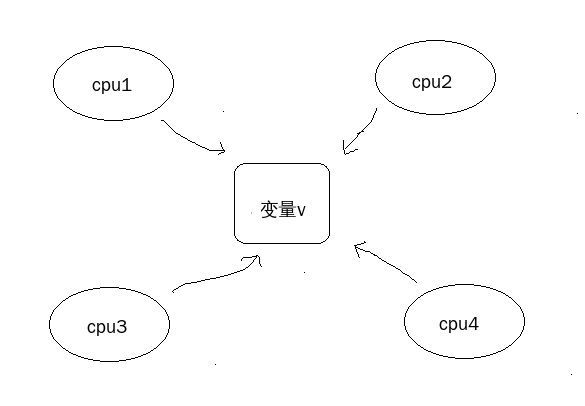
当cpu1在改变变量v的值的时候,cpu2也需要改变变量v的值。这时候就会导致变量v的值不正确。这时候机智的你就会说,在cpu1访问变量v的时候可以使用原子操作加锁,cpu2访问变量v的时候需要等待。可是机智的是否考虑过加锁对性能的影响,原子操作对cpu是极耗cpu的。
再考虑一种情况,现在高速的cpu都带有高速缓冲cache。它介于cpu和主存之间,主要作用是加快cpu的访问速度。因为主存的访问速度相比cpu读写比较慢,在之间引入cache之后,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
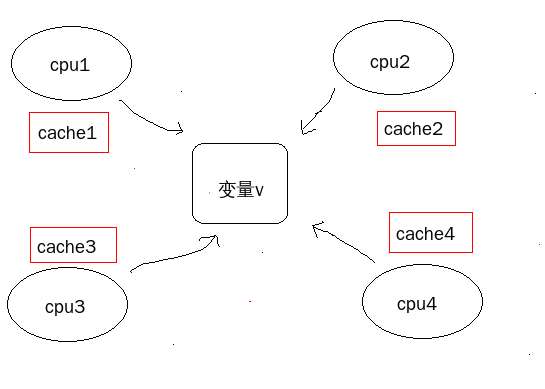
比如cpu1对变量v操作子后,变量v的值就发生了变化。而cpu2, cpu3, cpu4的cache中的值还是以前的值,所以这时候就需要将cpu2, cpu3, cpu4的cache中的值变为无效的,当cpu2读取变量v的时候就需要从内存中读取v。所以当某一个cpu对共享数据v做操作后,比较对其余的cache做无效操作,这也是对性能有所损耗的。
所以,就引入了per-cpu变量。
什么是per-CPU变量
per-CPU变量是linux系统一个非常有趣的特性,它为系统中的每个处理器都分配了该变量的副本。这样做的好处是,在多处理器系统中,当处理器操作属于它的变量副本时,不需要考虑与其他处理器的竞争的问题,同时该副本还可以充分利用处理器本地的硬件缓冲cache来提供访问速度。
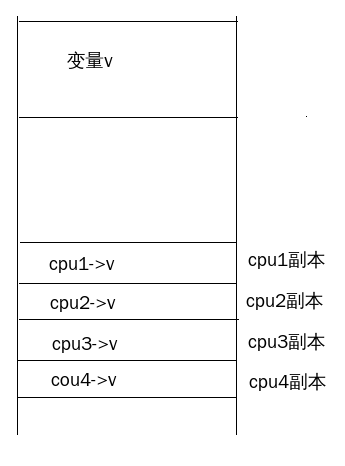
per-CPU按照存储变量的空间来源分为静态per-CPU变量和动态per-CPU变量,前者的存储空间是在代码编译时静态分配的,而后者的存储空间则是在代码的执行期间动态分配的。
静态per-CPU变量声明和定义
声明DECLARE_PER_CPU宏:
<include/linux/percpu-defs.h>
----------------------------------------------------------------
#define DECLARE_PER_CPU(type, name)
DECLARE_PER_CPU_SECTION(type, name, "")
#define DECLARE_PER_CPU_SECTION(type, name, sec)
extern __PCPU_ATTRS(sec) __typeof__(type) name
#define __PCPU_ATTRS(sec)
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec)))
PER_CPU_ATTRIBUTES
<include/asm-generic/percpu.h>
-----------------------------------------------------
#ifndef PER_CPU_BASE_SECTION
#ifdef CONFIG_SMP
#define PER_CPU_BASE_SECTION ".data..percpu"
#else
#define PER_CPU_BASE_SECTION ".data"
#endif
#endif
对上的宏定义DECLARE_PER_CPU使用例子: DECLARE_PER_CPU(int, val)来详细说明。
DECLARE_PER_CPUT(int, val)
-> DECLARE_PER_CPU_SECTION(int, val, "")
-> extern __PCPU_ATTRS("") __typeof__(int) val
-> extern __percpu __attribute__((section(".data..percpu"))) int val
从上面的分析可以看出,该宏在源代码中声明了__percpu int val变量,该变量放在一个名为”.data..percpu”的section中。
定义DEFINE_PER_CPU宏:
<include/linux/percpu-defs.h>
----------------------------------------------------------------
#define DEFINE_PER_CPU(type, name)
DEFINE_PER_CPU_SECTION(type, name, "")
#define DEFINE_PER_CPU_SECTION(type, name, sec)
__PCPU_ATTRS(sec) PER_CPU_DEF_ATTRIBUTES
__typeof__(type) name
#ifndef PER_CPU_DEF_ATTRIBUTES
#define PER_CPU_DEF_ATTRIBUTES
#endif
| 声明和定义 | 解释 |
|---|---|
| DECALRE_PER_CPU(type, name)/DEFINE_PER_CPU(type, name) | 普通的per-CPU声明和定义 |
| DECLARE_PER_CPU_FIRST(type, name)/DEFINE_PER_CPU_FIRST(type, name) | 该per-CPU变量会在整个serction的最前面,所谓的first |
| DECLARE_PER_CPU_SHARED_ALIGNED(type, name)/DEFINE_PER_CPU_SHARED_ALIGNED(type, name) | 该per-CPU在SMP系统下会对齐到cache line,在UP系统下不需要对齐 |
| DECLARE_PER_CPU_ALIGNED(type, name)/DEFINE_PER_CPU_ALIGNED(type, name) | 在SMP和UP系统都对齐到cache line |
| DECLARE_PER_CPU_PAGE_ALIGNED(type, name)/DEFINE_PER_CPU_PAGE_ALIGNED(type, name) | 该per-CPU变量必须页对齐 |
| DECLARE_PER_CPU_READ_MOSTLY(type, name)/DEFINE_PER_CPU_READ_MOSTLY(type, name) | 该per-CPU变量必须是read mostly |
静态per-CPU变量的链接脚本
在上一节per-CPU变量的声明和定义中,可以看到最后的变量都是存在一个”.data..percpu”段中。
. = ALIGN((1 << 12));
.data..percpu : AT(ADDR(.data..percpu) - 0)
{
__per_cpu_load = .;
__per_cpu_start = .;
*(.data..percpu..first) . = ALIGN((1 << 12));
*(.data..percpu..page_aligned) . = ALIGN(64);
*(.data..percpu..read_mostly) . = ALIGN(64);
*(.data..percpu)
*(.data..percpu..shared_aligned)
__per_cpu_end = .;
}
可见,内核在编译链接的时候会把所有静态定义的per-CPU变量统一放到”.data..percpu”section中。链接器生成__per_cpu_start和__per_cpu_end两个变量表示该section的起始和结束地址。
动态分配per-CPU变量
- 分配函数
#define alloc_percpu(type)
(typeof(type) __percpu *)__alloc_percpu(sizeof(type),
__alignof__(type))
根据类型type,分配per-CPU变量
- 释放函数
void free_percpu(void __percpu *ptr)
释放ptr所指向的per-CPU变量。
使用静态per-CPU变量
因为per-CPU不能像一般的变量那样访问,必须使用内核提供的函数:
#define get_cpu_var(var)
(*({
preempt_disable();
this_cpu_ptr(&var);
}))
#define put_cpu_var(var)
do {
(void)&(var);
preempt_enable();
} while (0)
机智的你可能会问,为什么还需要关闭抢占,因为对于per-CPU来说已经是单处理器了。但是机智的你没有想到的是,在cpu访问per-CPU的时候,突然系统发生了一次紧急抢占,这时候cpu还在处理per-CPU变量,一旦被抢占了cpu资源,可能当前进程会换出处理器。所以关闭抢走还是必要的。
如果需要访问其他处理器的副本,可以使用函数per_cpu(var, cpu)
#define per_cpu(var, cpu) (*per_cpu_ptr(&(var), cpu))
使用动态per-CPU变量
#define get_cpu_ptr(var)
({
preempt_disable();
this_cpu_ptr(var);
})
#define put_cpu_ptr(var)
do {
(void)(var);
preempt_enable();
} while (0)
#define per_cpu_ptr(ptr, cpu) ({ (void)(cpu); VERIFY_PERCPU_PTR(ptr); })
以上get_cpu_ptr和put_cpu_ptr是在有抢占的情况下,需要关闭抢占使用。
而per_cpu_ptr(ptr, cpu)是根据per cpu变量的地址和cpu number,返回指定CPU number上该per cpu变量的地址。