调度中的负载概念,与平时熟知的cpu占用率并不是一回事,两者间有较大差别。本文分析了cpu负载和系统负载,并非CPU使用率。代码基于CAF- SM8250 - kernel 4.19。
负载计算中,其实主要分为3大部分,由小到大依次为:
1、调度实体负载:update_load_avg()----PELT
2、CPU负载:update_cpu_load_active()
3、系统负载:calc_global_load_tick()
这3个级别的负载计算分别体现了不同维度下的当前负载情况。
之前blog分析了调度实体sched entity级别的负载计算,是通过PELT机制来统计的。它体现了每一个调度实体的对cpu产生的负载情况,并进行了实时统计更新。(这块之前分析,复盘了下,还是不太详细和明确,后续还要再总结一下)
这次主要分析余下2个:CPU负载和系统负载的计算原理。
CPU负载计算原理
CPU负载是用来体现当前CPU的工作任务loading情况,和CPU繁忙程度的。其主要通过统计CPU rq上task处于runnable的平均时间(runnable_load_avg = runnable_load_sum / LOAD_AVG_MAX)。并根据不同周期,统计出不同的k线,来体现CPU负载的变化趋势。
我们知道单个task处于runnable的平均时间是由PELT算法机制来完成统计的。所以,我们此次分析更偏向于如何利用统计出的单个task数据,再进一步统计出不同周期的均线,来表示CPU负载。
代码路径如下:
scheduler_tick()
-> cpu_load_update_active()
void cpu_load_update_active(struct rq *this_rq) { unsigned long load = weighted_cpuload(this_rq); //load = cfs_rq->avg.runnable_load_avg if (tick_nohz_tick_stopped()) cpu_load_update_nohz(this_rq, READ_ONCE(jiffies), load); //(1) else cpu_load_update_periodic(this_rq, load); //(2) }
上面根据是否配置nohz而可能停止了tick走向不同的分支:
(1)cpu_load_update_nohz(this_rq, READ_ONCE(jiffies), load) //更新cpu负载,基于no HZ场景
(2)cpu_load_update_periodic() //周期性更新cpu负载,基于有HZ场景
NO_HZ的情况下,会走这个分支。pending_updates表示jiffies数是否更新,即表示tick数。 经过的秒数 = jiffies / HZ(平台当前HZ=250);一个tick为HZ倒数,即4ms。
/* * There is no sane way to deal with nohz on smp when using jiffies because the * CPU doing the jiffies update might drift wrt the CPU doing the jiffy reading * causing off-by-one errors in observed deltas; {0,2} instead of {1,1}. * * Therefore we need to avoid the delta approach from the regular tick when * possible since that would seriously skew the load calculation. This is why we * use cpu_load_update_periodic() for CPUs out of nohz. However we'll rely on * jiffies deltas for updates happening while in nohz mode (idle ticks, idle * loop exit, nohz_idle_balance, nohz full exit...) * * This means we might still be one tick off for nohz periods. */ static void cpu_load_update_nohz(struct rq *this_rq, unsigned long curr_jiffies, unsigned long load) { unsigned long pending_updates; pending_updates = curr_jiffies - this_rq->last_load_update_tick; //计算pending_updates if (pending_updates) { this_rq->last_load_update_tick = curr_jiffies; //更新时间戳 /* * In the regular NOHZ case, we were idle, this means load 0. * In the NOHZ_FULL case, we were non-idle, we should consider * its weighted load. */ cpu_load_update(this_rq, load, pending_updates); //(2-1)更新cpu rq的cpu load数据 } }
我们再看(2)这个分支:
``` static void cpu_load_update_periodic(struct rq *this_rq, unsigned long load) { #ifdef CONFIG_NO_HZ_COMMON /* See the mess around cpu_load_update_nohz(). */ this_rq->last_load_update_tick = READ_ONCE(jiffies); //记录更新的时间戳 #endif cpu_load_update(this_rq, load, 1); //(2-1)更新cpu rq的cpu load数据 } ```
最终都是调用了cpu_load_update()来更新cpu rq的cpu load数据。
(2-1)更新cpu rq的cpu load数据
/** * __cpu_load_update - update the rq->cpu_load[] statistics * @this_rq: The rq to update statistics for * @this_load: The current load * @pending_updates: The number of missed updates * * Update rq->cpu_load[] statistics. This function is usually called every * scheduler tick (TICK_NSEC). * * This function computes a decaying average: * * load[i]' = (1 - 1/2^i) * load[i] + (1/2^i) * load * * Because of NOHZ it might not get called on every tick which gives need for * the @pending_updates argument. * * load[i]_n = (1 - 1/2^i) * load[i]_n-1 + (1/2^i) * load_n-1 * = A * load[i]_n-1 + B ; A := (1 - 1/2^i), B := (1/2^i) * load * = A * (A * load[i]_n-2 + B) + B * = A * (A * (A * load[i]_n-3 + B) + B) + B * = A^3 * load[i]_n-3 + (A^2 + A + 1) * B * = A^n * load[i]_0 + (A^(n-1) + A^(n-2) + ... + 1) * B * = A^n * load[i]_0 + ((1 - A^n) / (1 - A)) * B * = (1 - 1/2^i)^n * (load[i]_0 - load) + load * * In the above we've assumed load_n := load, which is true for NOHZ_FULL as * any change in load would have resulted in the tick being turned back on. * * For regular NOHZ, this reduces to: * * load[i]_n = (1 - 1/2^i)^n * load[i]_0 * * see decay_load_misses(). For NOHZ_FULL we get to subtract and add the extra * term. */ static void cpu_load_update(struct rq *this_rq, unsigned long this_load, unsigned long pending_updates) { unsigned long __maybe_unused tickless_load = this_rq->cpu_load[0]; //获取之前周期为0的均线cpu load int i, scale; this_rq->nr_load_updates++; //统计cpu load更新次数 /* Update our load: */ this_rq->cpu_load[0] = this_load; /* Fasttrack for idx 0 */ //更新cpu load[0] for (i = 1, scale = 2; i < CPU_LOAD_IDX_MAX; i++, scale += scale) { //更新cpu load[1-4] unsigned long old_load, new_load; /* scale is effectively 1 << i now, and >> i divides by scale */ old_load = this_rq->cpu_load[i]; #ifdef CONFIG_NO_HZ_COMMON old_load = decay_load_missed(old_load, pending_updates - 1, i); //(2-1-1)将原先的old load做老化;如果pending_update == 1,就不用做负载老化 if (tickless_load) { //如果之前cpu load[0]有负载 old_load -= decay_load_missed(tickless_load, pending_updates - 1, i); //那么还要对tickless_load进行老化【针对这里为什么要添加tickless_load的考虑,后面说明】 /* * old_load can never be a negative value because a * decayed tickless_load cannot be greater than the * original tickless_load. */ old_load += tickless_load; } #endif new_load = this_load; /* * Round up the averaging division if load is increasing. This * prevents us from getting stuck on 9 if the load is 10, for * example. */ if (new_load > old_load) //这里是做了一个补偿,防止由于old load小于new load情况下,最终的cpu load都不可能达到最大值 new_load += scale - 1; this_rq->cpu_load[i] = (old_load * (scale - 1) + new_load) >> i; //计算当前新的cpu load } }
最后计算更新当前新的cpu load,实际为5份数据。分别对应不同周期长度的均线数据:
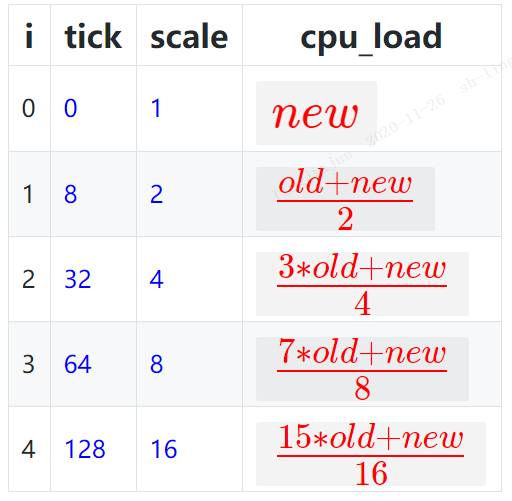
解释一下上面表格的意思:
针对CPU负载计算,会统计5条不同周期的均线,周期分别为{0,8,32,64,128},单位为tick。可以理解为统计了从当前tick开始往前推周期tick个数的load数据,周期内没有load,则load就会归0。
而在更新时,采用的计算公式:load = (2^idx - 1) / 2^idx * load + 1 / 2^idx * cur_load ----idx就是表格中【i】,load为old load,cur_load为新的load
那么整理后,为:当前load = 更新系数 * 旧的load + (1-更新系数)* 新的load ---更新系数为 (2^idx - 1) / 2^idx,最终参考【cpu_load】计算公式
现在我们来看,关于tickless系统(我们当前就是tickless/NO_HZ系统),错过了一些tick,那么就需要先将old load先老化,再考虑new load,重新计算当前的cpu load[1-4]。这里使用了查表法来减少计算量,提升性能。
PS:因为NO_HZ一般是出现休眠。那么休眠时,load是被认为为0的,所以,其实只需要考虑将旧的load进行衰减就可以了。
(2-1-1)将原先的old load做老化;如果pending_update == 1,就不用做负载老化
/* * The exact cpuload calculated at every tick would be: * * load' = (1 - 1/2^i) * load + (1/2^i) * cur_load * * If a CPU misses updates for n ticks (as it was idle) and update gets * called on the n+1-th tick when CPU may be busy, then we have: * * load_n = (1 - 1/2^i)^n * load_0 * load_n+1 = (1 - 1/2^i) * load_n + (1/2^i) * cur_load * * decay_load_missed() below does efficient calculation of * * load' = (1 - 1/2^i)^n * load * * Because x^(n+m) := x^n * x^m we can decompose any x^n in power-of-2 factors. * This allows us to precompute the above in said factors, thereby allowing the * reduction of an arbitrary n in O(log_2 n) steps. (See also * fixed_power_int()) * * The calculation is approximated on a 128 point scale. */ #define DEGRADE_SHIFT 7 static const u8 degrade_zero_ticks[CPU_LOAD_IDX_MAX] = {0, 8, 32, 64, 128}; static const u8 degrade_factor[CPU_LOAD_IDX_MAX][DEGRADE_SHIFT + 1] = { { 0, 0, 0, 0, 0, 0, 0, 0 }, { 64, 32, 8, 0, 0, 0, 0, 0 }, { 96, 72, 40, 12, 1, 0, 0, 0 }, { 112, 98, 75, 43, 15, 1, 0, 0 }, { 120, 112, 98, 76, 45, 16, 2, 0 } }; /* * Update cpu_load for any missed ticks, due to tickless idle. The backlog * would be when CPU is idle and so we just decay the old load without * adding any new load. */ static unsigned long decay_load_missed(unsigned long load, unsigned long missed_updates, int idx) { int j = 0; if (!missed_updates) return load; if (missed_updates >= degrade_zero_ticks[idx]) //不同的统计周期,超过了一定tick数,说明系统已经sleep这么长时间,那么old load就需要被清空了 return 0; if (idx == 1) return load >> missed_updates; //如果是周期为2均线,就直接根据missed_updates的个数,除以2次幂就行了,因为old和new的占比是各为1/2 while (missed_updates) { if (missed_updates % 2) load = (load * degrade_factor[idx][j]) >> DEGRADE_SHIFT; missed_updates >>= 1; j++; } return load; }
针对不同周期线的均线数据,老化的计算都是使用同一个公式:
load_n = (1 - 1/2^i)^n * load_0 ---i就是idx,n则是pending_update-1,也就是missed_updates
tickless_load
再说说tickless_load,我发现在之前的kernel版本上是没有的。也就是说,原先cpu负载的老化是完全按照上述2个公式严格计算的。
而现在加入了tickless_load,是考虑了上一次更新tick中cpu_load[0]的负载数据。将其也更新进了旧load(old_load)中。
个人认为这样做的目的是这样的,假设如下场景:
1. 上一次该均线load更新,此时load较小-----这部分load视作旧load
2. 期间有短暂的load剧增------这部分load视作tickless_load
3. 还没有到该均线load更新,进入休眠
4. 唤醒时刻load也比较小
5. 此次该均线load更新,此时load也比较小(与唤醒时刻load一致)
但是此时,如果不考虑ticklees load。那么该均线load此次更新会仅考虑旧load的衰减,再加上更新均线此时load,经过算法计算得出。但是此时的load与实际体现有较大差距,因为周期越长,那么新load更新时所占比例小,旧load所占比例大。所以,导致此时最终load结果与平均load有一部分相差,因为没有考虑到tickless load的负载,无法体现CPU平均负载真实情况。
而加入tickless_load之后,即将休眠前那部分load也会加入旧load计算。这样避免了那部分短暂load的计算缺失。
所以考虑tickless_load的最终老化的公式应该是这样的:
load_n = (1 - 1/2^i)^n * load_0 + [1 - (1 - 1/2^i)^n ] * tickless_load
最后结果load_n就是更新后的old_load,最后再用上面表格【cpu_load】计算公式,计算出最新的cpu负载数据。
tickless load这块的理解属于我个人理解,最好还是通过检查kernel提交记录查看commit信息。如有理解不对的地方,请指出。
CPU负载为何如此设计?
1、不同周期的均线用来反应不同时间窗口长度下的负载情况,主要供load_balance()在不同场景判断是否负载平衡的比较基准,常用为cpu_load[0]和cpu_load[1](这块后续分析load_balance时,需要check清楚)
2、使用不同周期的均线目的在于平滑样本的抖动,确定趋势的变化方向
系统负载计算原理
系统级的平均负载(load average)可以通过以下命令(uptime、top、cat /proc/loadavg)查看:
$ uptime 16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46 $ top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37 $ cat /proc/loadavg 25.72 23.19 23.35 42/3411 43603
“load average:”后面的3个数字分别表示1分钟、5分钟、15分钟的load average。可以从几方面去解析load average:
If the averages are 0.0, then your system is idle.
If the 1 minute average is higher than the 5 or 15 minute averages, then load is increasing.
If the 1 minute average is lower than the 5 or 15 minute averages, then load is decreasing.
If they are higher than your CPU count, then you might have a performance problem (it depends).
最早的系统级平均负载(load average)只会统计runnable状态,但是linux后面觉得这种统计方式代表不了系统的真实负载。
举一个例子:系统换一个低速硬盘后,他的runnable负载还会小于高速硬盘时的值;linux认为睡眠状态(TASK_INTERRUPTIBLE/TASK_UNINTERRUPTIBLE)也是系统的一种负载,系统得不到服务是因为io/外设的负载过重。
系统级负载统计函数calc_global_load_tick()中会把(this_rq->nr_running+this_rq->nr_uninterruptible)都计入负载;
代码解析如下:
scheduler_tick()
-> calc_global_load_tick()
/* * Called from scheduler_tick() to periodically update this CPU's * active count. */ void calc_global_load_tick(struct rq *this_rq) { long delta; if (time_before(jiffies, this_rq->calc_load_update)) //过滤系统负载已经更新了的情况 return; delta = calc_load_fold_active(this_rq, 0); //(1)更新nr_running + uninterruptible的task数量 if (delta) atomic_long_add(delta, &calc_load_tasks); //统计task数量到系统全局变量calc_load_tasks中 this_rq->calc_load_update += LOAD_FREQ; //下一次更新系统负载的时间(当前时间+5s) }
//(1)更新nr_running + uninterruptible的task数量
long calc_load_fold_active(struct rq *this_rq, long adjust) { long nr_active, delta = 0; nr_active = this_rq->nr_running - adjust; nr_active += (long)this_rq->nr_uninterruptible; //统计所有nr_running和uninterruptible的task数量 if (nr_active != this_rq->calc_load_active) { //this_rq->calc_load_active表示当前nr_running + uninterruptible的task数量 delta = nr_active - this_rq->calc_load_active; //计算差值 this_rq->calc_load_active = nr_active; //更新task数量 } return delta; }
上面这部分主要是每隔5s以上,更新系统中nr_running + uninterruptible的task数量的,并统计到全局变量calc_load_tasks中。
此外,还有一部分是在系统jiffies更新时,触发计算系统负载动作。
系统中注册了tick_setup_sched_timer,用于模拟tick、高精度定时器、以及更新jiffies等,其中也会对系统负载进行计算。
当timer触发时,就会执行tick_sched_timer。当前cpu为tick_do_timer_cpu时,就会进行系统负载计算。所以,计算负载仅由一个从cpu完成,它就是tick_do_timer_cpu。
tick_sched_timer() -> tick_sched_do_timer() ->tick_do_update_jiffies64() -> do_timer() -> calc_global_load()
/* * calc_load - update the avenrun load estimates 10 ticks after the * CPUs have updated calc_load_tasks. * * Called from the global timer code. */ void calc_global_load(unsigned long ticks) { unsigned long sample_window; long active, delta; sample_window = READ_ONCE(calc_load_update); //获取scheduler_tick中更新的新时间戳 if (time_before(jiffies, sample_window + 10)) //确保在时间戳之后的10个tick后(确保所有cpu都更新完calc_load_tasks),进行系统负载计算(所以总的间隔时间时5s + 10 tick) return; /* * Fold the 'old' NO_HZ-delta to include all NO_HZ CPUs. */ delta = calc_load_nohz_fold(); //(2)统计NO_HZ cpu的task数量(是否因为idle而错过了统计task数量,所以在这里更新一下?) if (delta) atomic_long_add(delta, &calc_load_tasks); //更新nr_running + uninterrunptible的task数量全局变量 active = atomic_long_read(&calc_load_tasks); //获取nr_running + uninterrunptible的task数量全局变量 active = active > 0 ? active * FIXED_1 : 0; //乘FIXED_1系数 avenrun[0] = calc_load(avenrun[0], EXP_1, active); //(3)计算1分钟的系统负载 avenrun[1] = calc_load(avenrun[1], EXP_5, active); //计算5分钟的系统负载 avenrun[2] = calc_load(avenrun[2], EXP_15, active); //计算15分钟的系统负载 WRITE_ONCE(calc_load_update, sample_window + LOAD_FREQ); //更新时间戳 /* * In case we went to NO_HZ for multiple LOAD_FREQ intervals * catch up in bulk. */ calc_global_nohz(); //(4) }
(2)统计NO_HZ cpu的task数量(是否因为idle而错过了统计task数量,所以在这里更新一下?)
static long calc_load_nohz_fold(void) { int idx = calc_load_read_idx(); long delta = 0; if (atomic_long_read(&calc_load_nohz[idx])) delta = atomic_long_xchg(&calc_load_nohz[idx], 0); return delta; }
/* * Handle NO_HZ for the global load-average. * * Since the above described distributed algorithm to compute the global * load-average relies on per-CPU sampling from the tick, it is affected by * NO_HZ. * * The basic idea is to fold the nr_active delta into a global NO_HZ-delta upon * entering NO_HZ state such that we can include this as an 'extra' CPU delta * when we read the global state. * * Obviously reality has to ruin such a delightfully simple scheme: * * - When we go NO_HZ idle during the window, we can negate our sample * contribution, causing under-accounting. * * We avoid this by keeping two NO_HZ-delta counters and flipping them * when the window starts, thus separating old and new NO_HZ load. * * The only trick is the slight shift in index flip for read vs write. * * 0s 5s 10s 15s * +10 +10 +10 +10 * |-|-----------|-|-----------|-|-----------|-| * r:0 0 1 1 0 0 1 1 0 * w:0 1 1 0 0 1 1 0 0 * * This ensures we'll fold the old NO_HZ contribution in this window while * accumlating the new one. * * - When we wake up from NO_HZ during the window, we push up our * contribution, since we effectively move our sample point to a known * busy state. * * This is solved by pushing the window forward, and thus skipping the * sample, for this CPU (effectively using the NO_HZ-delta for this CPU which * was in effect at the time the window opened). This also solves the issue * of having to deal with a CPU having been in NO_HZ for multiple LOAD_FREQ * intervals. * * When making the ILB scale, we should try to pull this in as well. */ static atomic_long_t calc_load_nohz[2]; static int calc_load_idx;
(3)计算1分钟的系统负载。5分钟和15分钟的负载也是类似计算方法
/* * a1 = a0 * e + a * (1 - e) */ static inline unsigned long calc_load(unsigned long load, unsigned long exp, unsigned long active) { unsigned long newload; newload = load * exp + active * (FIXED_1 - exp); if (active >= load) newload += FIXED_1-1; return newload / FIXED_1; } #define FSHIFT 11 /* nr of bits of precision */ #define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */ #define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */ #define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */ #define EXP_5 2014 /* 1/exp(5sec/5min) */ #define EXP_15 2037 /* 1/exp(5sec/15min) */
核心算法calc_load()的思想是:old_load * 老化系数 + new_load *(1 - 老化系数)
1分钟负载计算公式:
old_load * (EXP_1/FIXED_1) + new_load * (1 - EXP_1/FIXED_1)
即:

其中,
FIXED_1 = 2^11 = 2048
EXP_1 = 1884
EXP_5 = 2014
EXP_15 = 2037
5分钟和15分钟的计算,只需要将公式中的EXP_1换成EXP_5/EXP_15即可。
从计算来看,系统负载本质实际就是统计nr_running + uninterruptible task数量。
(4)由于NO_HZ可能导致已经错过了多个tick,所以需要将错过的这些tick也考虑在内。根据实际错过的具体tick数,重新计算出准确的负载load
/* * NO_HZ can leave us missing all per-CPU ticks calling * calc_load_fold_active(), but since a NO_HZ CPU folds its delta into * calc_load_nohz per calc_load_nohz_start(), all we need to do is fold * in the pending NO_HZ delta if our NO_HZ period crossed a load cycle boundary. * * Once we've updated the global active value, we need to apply the exponential * weights adjusted to the number of cycles missed. */ static void calc_global_nohz(void) { unsigned long sample_window; long delta, active, n; sample_window = READ_ONCE(calc_load_update); if (!time_before(jiffies, sample_window + 10)) { /* * Catch-up, fold however many we are behind still */ delta = jiffies - sample_window - 10; n = 1 + (delta / LOAD_FREQ); active = atomic_long_read(&calc_load_tasks); active = active > 0 ? active * FIXED_1 : 0; avenrun[0] = calc_load_n(avenrun[0], EXP_1, active, n); avenrun[1] = calc_load_n(avenrun[1], EXP_5, active, n); avenrun[2] = calc_load_n(avenrun[2], EXP_15, active, n); WRITE_ONCE(calc_load_update, sample_window + n * LOAD_FREQ); } /* * Flip the NO_HZ index... * * Make sure we first write the new time then flip the index, so that * calc_load_write_idx() will see the new time when it reads the new * index, this avoids a double flip messing things up. */ smp_wmb(); calc_load_idx++;
最后通过cat proc/loadavg,可以查看系统负载结果:
代码如下:
static int loadavg_proc_show(struct seq_file *m, void *v) { unsigned long avnrun[3]; get_avenrun(avnrun, FIXED_1/200, 0); seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d ", LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]), LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]), LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]), nr_running(), nr_threads, idr_get_cursor(&task_active_pid_ns(current)->idr) - 1); return 0; }
总结
1、cpu负载计算,在每个scheduler_tick中触发。
统计的数据是cpu rq的runnable_load_avg,使用的公式是:当前load = 更新系数 * 旧的load + (1-更新系数)* 新的load ---更新系数为 (2^idx - 1) / 2^idx,idx = 0,1,2,3,4。
同时会统计出5条不同周期的CPU负载均线,来用于不同场景下的cpu负载体现和比较基准,并能体现其变化趋势。
2、系统负载计算,是在scheduler_tick中统计runnable + uninterruptible的task数量(统计间隔5s)。在sched tick timer触发时(统计间隔5s + 10 tick),计算系统负载。
统计的数据是runnable + uninterruptible的task数量,使用的公式是:旧load * 老化系数+新load * (1 - 老化系数)。
同时会统计1分钟、5分钟、15分钟的系统负载数据。可以通过节点查看得知。
PS:乍一看2个负载的计算公式都差不多,其实统计的load天差地别,需要注意区别!
参考:https://blog.csdn.net/pwl999/article/details/78817902
https://blog.csdn.net/wukongmingjing/article/details/82531950