1. cpusets
1.1 什么是cpusets
cpusets基本功能是限制某一组进程只运行在某些cpu和内存节点上,举个简单例子:系统中有4个进程,4个内存节点,4个cpu.利用cpuset可以让第1,2个进程只运行在第1,2颗cpu上并且只在第1,2个内存节点上分配内存。cpuset是基于cgroup子系统实现(关于cgroup子系统可以参考内核文档 Documentation/cgroups/cgroups.txt.)使用cpuset上述功能可以让系统管理员动态调整进程运行所在的cpu和内存节点。
cpusets是cgroup文件系统中的一个子系统。
1.2 为什么需要cpusets
在大型的计算机系统中,有多颗cpu,若干内存节点。尤其在NUMA架构下,cpu访问不同内存节点的速度不同,这种情况增加了进程调度和进程内存分配目标node管理的难度。比较新的小型系统使用linux内核自带的调度功能和内存管理方案就能得到很好表现,但是在比较大的系统中如果精心调整不同应用所在的cpu和内存节点会大大提高性能表现。
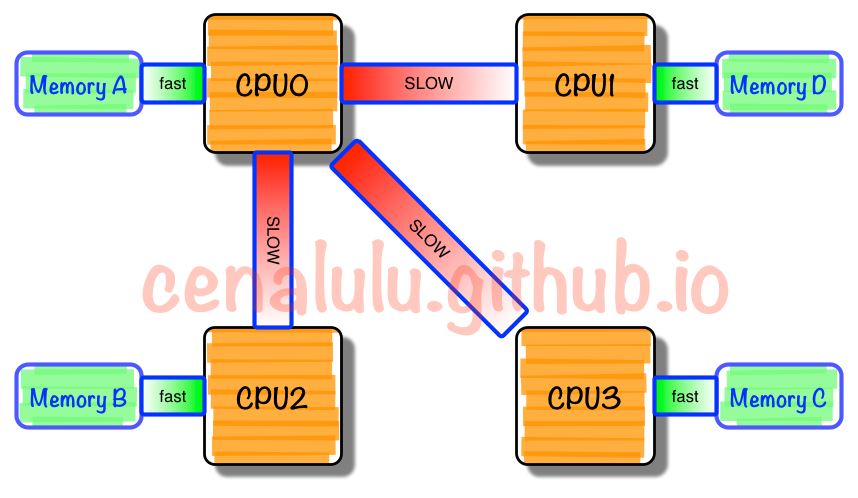 (NUMA架构)
(NUMA架构)
cpuset在以下场景会更有价值:
1. 对于跑了很多相同的应用实例的大型web server
2. 对于跑了不同应用的大型server(例如:同时跑了web server相关应用,又跑了数据库应用)
3. 大型NUMA系统
cpuset必须允许动态调整,并且不影其他不相关cpuset中运行的进程。比如:可以将某个cpu动态的加入到某个cpuset,可以从某个cpuset中将某个cpu移除,可以将进程加入到cpuset,也可以将某个进程从一个cpuset迁移到另一个cpuset。内核的cpuset补丁,提供了最基本的实现上述功能的机制,在实现上最大限度使用原有的cpu和内存节点分配机制,尽可能避免影响现有的调度器,以及内存分配核心功能的代码。
1.3 cpusets是如何实现的
cpusets整体为层级树结构。由一个根节点(root)包含了系统所有的cpu和内存节点资源。由根节点,可以分支出一个或者多个子节点,同时子节点也可以在分支出孙子节点,以此类推。每个子节点所包含的资源都是父节点资源的子集。
为了理解层级树的概念:其实cpuset做为cgroup一个子系统实现,也遵循了cgroup层级树的概念。举个例子:有一个cpuset /,可以在cpuset /下再建立若干个cpuset。比如:建立background,foreground两个子cpuset。background和foreground互为兄弟,cpuset /属于父。子cpuset中的cpu和node节点集合必须是父亲cpuset中cpu和内存节点集合的子集。
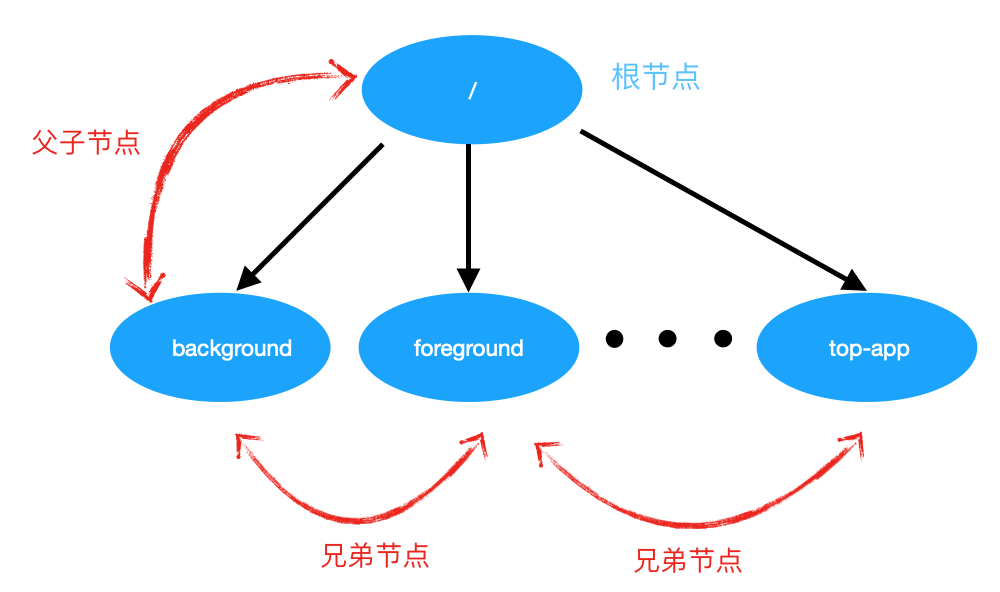
对cpuset的操作都是通过cpuset文件系统来完成的,内核没有提供额外的系统调用对cpuset做修改、查看操作。在android下,cpusets的文件系统路径:
/dev/cpuset
在/proc/#pid/status中如下几行也可以说明一个进程运行在哪些cpu上,并且进程分配内存必须在哪些内存节点上:
Cpus_allowed: ffffffff,ffffffff,ffffffff,ffffffff
Cpus_allowed_list: 0-127
Mems_allowed: ffffffff,ffffffff
Mems_allowed_list: 0-63
例如(android平台只有8个cpu core,1个内存节点):
Cpus_allowed: ff Cpus_allowed_list: 0-7 Mems_allowed: 1 Mems_allowed_list: 0
每一个cpuset对应cgroup文件系统中的子系统,,目录下有些文件,用来描述cpuset的属性。对应的文件里列表如下:
1.cpuset.cpus //cpuset中的cpu列表
2.cpuset.mems //cpuset中的内存节点列表
3.cpuset.memory_migrate //cpuset内存迁移,见1.9
4.cpuset.cpu_exclusive //cpuset是否是cpu互斥的,见1.4
5.cpuset.mem_exclusive //cpuset是否是内存互斥的,见1.4
6.cpuset.mem_hardwall //cpuset是否是hardwalled的,见1.4
7.cpuset.memory_pressure //内存使用的紧张程度,见1.5
8.cpuset.memory_spread_page //如果被设置了,将该cpuset中进程上下文申请的page cache平均分布到cpuset中的各个节点,见1.6
9.cpuset.memory_spread_slab //如果被设置了,将该cpuset中进程上下文申请到的slab对象平均分布到cpuset中的各个内存节点,见1.6
10.cpuset.sched_load_balance //如果被设置了,负载均衡会在cpuset配置的cpus中进行,见1.7
11.cpuset.sched_relax_domain_level //当要task迁移时,搜索的范围,见1.8
下面文件只有在根cpuset中才有:
12.cpuset.memory_pressure_enabled //使能memory pressure测量的flag
其实在cpusets之前,已经有一套机制来限制某个进程只能被调度到某些cpu上运行(sched_setaffinity),限制某些进程的内存申请只能在某些内存节点上分配(mbind,set_mempolicy)。
而cpusets进行了扩展:
- cpusets是cpu和memory节点的集合,并且对kernel可见的。
- 每个task struct中有一个指针指向了cgroup数据结构(cpuset是cgroup的一个子系统),通过这个指针,将进程添加到具体的cpuset中。
- 调用sched_setaffinity、mbind/set_mempolicy对应的cpu必须在对应task的cpuset中
- 根节点的cpuset包含了所有cpu和memory节点
- 对任意cpuset,都可以再定义其子cpuset,子cpuset中包含的cpu和内存节点是父cpuset的子集
- cpusets的层级结构可以mount到/dev/cpuset,user space可以通过其进行查看和操作
- 如果一个cpuset被标记为专有,则该cpuset的兄弟cpuset中包含的cpu和内存节点不能和它的cpu和memory节点有交集
- 可以查看到任一cpuset上所有task的pid
cpusets的实现,需要在现有kernel中添加一些hook函数,而这些hook函数不会添加到kernel关键热点路径上(不影响性能):
1.3.1 在init/main.c中,当系统boot时,初始化根节点的cpuset:
start_kernel()--> cpuset_init()
start_kernel()--> rest_init()--> kernel_thread(kernel_init, NULL, CLONE_FS) --> kernel_init() --> kernel_init_freeable() --> do_basic_setup() --> cpuset_init_smp()
struct cpuset { struct cgroup_subsys_state css; unsigned long flags; /* "unsigned long" so bitops work */ /* * On default hierarchy: * * The user-configured masks can only be changed by writing to * cpuset.cpus and cpuset.mems, and won't be limited by the * parent masks. * * The effective masks is the real masks that apply to the tasks * in the cpuset. They may be changed if the configured masks are * changed or hotplug happens. * * effective_mask == configured_mask & parent's effective_mask, * and if it ends up empty, it will inherit the parent's mask. * * * On legacy hierachy: * * The user-configured masks are always the same with effective masks. */ /* user-configured CPUs and Memory Nodes allow to tasks */ cpumask_var_t cpus_allowed; cpumask_var_t cpus_requested; nodemask_t mems_allowed; /* effective CPUs and Memory Nodes allow to tasks */ cpumask_var_t effective_cpus; nodemask_t effective_mems; /* * This is old Memory Nodes tasks took on. * * - top_cpuset.old_mems_allowed is initialized to mems_allowed. * - A new cpuset's old_mems_allowed is initialized when some * task is moved into it. * - old_mems_allowed is used in cpuset_migrate_mm() when we change * cpuset.mems_allowed and have tasks' nodemask updated, and * then old_mems_allowed is updated to mems_allowed. */ nodemask_t old_mems_allowed; struct fmeter fmeter; /* memory_pressure filter */ /* * Tasks are being attached to this cpuset. Used to prevent * zeroing cpus/mems_allowed between ->can_attach() and ->attach(). */ int attach_in_progress; /* partition number for rebuild_sched_domains() */ int pn; /* for custom sched domain */ int relax_domain_level; };
int __init cpuset_init(void) { int err = 0; BUG_ON(!alloc_cpumask_var(&top_cpuset.cpus_allowed, GFP_KERNEL)); BUG_ON(!alloc_cpumask_var(&top_cpuset.effective_cpus, GFP_KERNEL)); BUG_ON(!alloc_cpumask_var(&top_cpuset.cpus_requested, GFP_KERNEL)); cpumask_setall(top_cpuset.cpus_allowed); cpumask_setall(top_cpuset.cpus_requested); nodes_setall(top_cpuset.mems_allowed); cpumask_setall(top_cpuset.effective_cpus); nodes_setall(top_cpuset.effective_mems); fmeter_init(&top_cpuset.fmeter); set_bit(CS_SCHED_LOAD_BALANCE, &top_cpuset.flags); top_cpuset.relax_domain_level = -1; //以上这些都是在初始化根节点cpuset的参数 err = register_filesystem(&cpuset_fs_type); //注册文件系统 if (err < 0) return err; BUG_ON(!alloc_cpumask_var(&cpus_attach, GFP_KERNEL)); return 0; }
/** * cpuset_init_smp - initialize cpus_allowed * * Description: Finish top cpuset after cpu, node maps are initialized */ void __init cpuset_init_smp(void) { cpumask_copy(top_cpuset.cpus_allowed, cpu_active_mask); top_cpuset.mems_allowed = node_states[N_MEMORY]; //node_states[N_MEMORY]是存放了所有online的内存节点,当内存hotplug时,会发生变化 top_cpuset.old_mems_allowed = top_cpuset.mems_allowed; cpumask_copy(top_cpuset.effective_cpus, cpu_active_mask); top_cpuset.effective_mems = node_states[N_MEMORY]; //在cpu、memory表初始化后,完成cpuset剩余参数的初始化 register_hotmemory_notifier(&cpuset_track_online_nodes_nb); //注册了一个notify,当cpuset中cpu或者memory发现改变了(hotplug),就会工作 cpuset_migrate_mm_wq = alloc_ordered_workqueue("cpuset_migrate_mm", 0); //创建了一个工作队列 BUG_ON(!cpuset_migrate_mm_wq); }
1.3.2 在进程fork/exit时,会从对应的cpuset中执行attach/detach:
fork调用路径1:_do_fork() -> copy_process() -> cgroup_fork()
/** * cgroup_fork - initialize cgroup related fields during copy_process() * @child: pointer to task_struct of forking parent process. * * A task is associated with the init_css_set until cgroup_post_fork() * attaches it to the parent's css_set. Empty cg_list indicates that * @child isn't holding reference to its css_set. */ void cgroup_fork(struct task_struct *child) { RCU_INIT_POINTER(child->cgroups, &init_css_set); //初始化子进程的css_set(cgroup subsystem set) INIT_LIST_HEAD(&child->cg_list); }
fork调用路径2:_do_fork() -> copy_process() -> cgroup_post_fork() -> css_set_move_task() -> cgroup_move_task() -> rcu_assign_pointer(task->cgroups, to);
其中,cgroup_move_task()中,会将子进程移动到父进程的cgroup中,操作由css_set指针赋值完成:
to指针为父进程的css_set指针,而task->cgroups则是child的css_set指针,最后通过指针赋值,子进程将attach到父进程的cgroup set中。
fork调用路径3:_do_fork() -> copy_process() -> cgroup_post_fork() -> 调用每个cgroup子系统的fork(): ss->fork(child) -> cpuset_fork()
/* * Make sure the new task conform to the current state of its parent, * which could have been changed by cpuset just after it inherits the * state from the parent and before it sits on the cgroup's task list. */ static void cpuset_fork(struct task_struct *task) { if (task_css_is_root(task, cpuset_cgrp_id)) return; set_cpus_allowed_ptr(task, ¤t->cpus_allowed); task->mems_allowed = current->mems_allowed; //继承父进程current的mem_allowed }
接着:cpuset_fork() ->set_cpus_allowed_ptr() -> __set_cpus_allowed_ptr()如下 -> do_set_cpus_allowed() -> p->sched_class->set_cpus_allowed(p, new_mask);
/* * Change a given task's CPU affinity. Migrate the thread to a * proper CPU and schedule it away if the CPU it's executing on * is removed from the allowed bitmask. * * NOTE: the caller must have a valid reference to the task, the * task must not exit() & deallocate itself prematurely. The * call is not atomic; no spinlocks may be held. */ static int __set_cpus_allowed_ptr(struct task_struct *p, const struct cpumask *new_mask, bool check) { const struct cpumask *cpu_valid_mask = cpu_active_mask; unsigned int dest_cpu; struct rq_flags rf; struct rq *rq; int ret = 0; cpumask_t allowed_mask; rq = task_rq_lock(p, &rf); update_rq_clock(rq); if (p->flags & PF_KTHREAD) { //所有kernel进程默认可以运行在所有online的cpu上 /* * Kernel threads are allowed on online && !active CPUs */ cpu_valid_mask = cpu_online_mask; } /* * Must re-check here, to close a race against __kthread_bind(), * sched_setaffinity() is not guaranteed to observe the flag. */ if (check && (p->flags & PF_NO_SETAFFINITY)) { //thread不允许改变cpu亲和度 ret = -EINVAL; goto out; } if (cpumask_equal(&p->cpus_allowed, new_mask)) //当前可运行的cpu和要设置的cpu相等,那就不需要重复设置 goto out; cpumask_andnot(&allowed_mask, new_mask, cpu_isolated_mask); //将父进程的cpus_allowed中去掉isolate的cpu cpumask_and(&allowed_mask, &allowed_mask, cpu_valid_mask); //再从中筛选可以进行task迁移的cpu dest_cpu = cpumask_any(&allowed_mask); //最后再筛选出的结果中挑选一个dest_cpu if (dest_cpu >= nr_cpu_ids) { //如果dest_cpu的index超过最大cpu的index,则需要重新挑选 cpumask_and(&allowed_mask, cpu_valid_mask, new_mask); dest_cpu = cpumask_any(&allowed_mask); if (!cpumask_intersects(new_mask, cpu_valid_mask)) { ret = -EINVAL; goto out; } } do_set_cpus_allowed(p, new_mask); //详细见下 if (p->flags & PF_KTHREAD) { /* * For kernel threads that do indeed end up on online && * !active we want to ensure they are strict per-CPU threads. */ WARN_ON(cpumask_intersects(new_mask, cpu_online_mask) && !cpumask_intersects(new_mask, cpu_active_mask) && p->nr_cpus_allowed != 1); } /* Can the task run on the task's current CPU? If so, we're done */ if (cpumask_test_cpu(task_cpu(p), &allowed_mask)) //如果task能运行在task本来运行的cpu上,则直接退出 goto out; if (task_running(rq, p) || p->state == TASK_WAKING) { //判断task是否处于running或者waking状态(不同task状态,不同的迁移方式) struct migration_arg arg = { p, dest_cpu }; /* Need help from migration thread: drop lock and wait. */ task_rq_unlock(rq, p, &rf); stop_one_cpu(cpu_of(rq), migration_cpu_stop, &arg); //在当前cpu上执行migration_cpu_stop函数,arg为函数的参数,执行完后stop当前cpu tlb_migrate_finish(p->mm); return 0; } else if (task_on_rq_queued(p)) { //task是否在rq中 /* * OK, since we're going to drop the lock immediately * afterwards anyway. */ rq = move_queued_task(rq, &rf, p, dest_cpu); //把task迁移到dest_cpu上 } out: task_rq_unlock(rq, p, &rf); return ret; }
调用至对应sched class的set_cpu_allowed(除deadline class,其余class都调用的是set_cpus_allowed_common()),如下:
void set_cpus_allowed_common(struct task_struct *p, const struct cpumask *new_mask) { cpumask_copy(&p->cpus_allowed, new_mask); //继承父进程的cpus_allowed p->nr_cpus_allowed = cpumask_weight(new_mask); //计算子进程的cpus_allowed数量 }
/* * migration_cpu_stop - this will be executed by a highprio stopper thread * and performs thread migration by bumping thread off CPU then * 'pushing' onto another runqueue. */ static int migration_cpu_stop(void *data) { struct migration_arg *arg = data; struct task_struct *p = arg->task; struct rq *rq = this_rq(); struct rq_flags rf; /* * The original target CPU might have gone down and we might * be on another CPU but it doesn't matter. */ local_irq_disable(); /* * We need to explicitly wake pending tasks before running * __migrate_task() such that we will not miss enforcing cpus_allowed * during wakeups, see set_cpus_allowed_ptr()'s TASK_WAKING test. */ sched_ttwu_pending(); raw_spin_lock(&p->pi_lock); rq_lock(rq, &rf); /* * If task_rq(p) != rq, it cannot be migrated here, because we're * holding rq->lock, if p->on_rq == 0 it cannot get enqueued because * we're holding p->pi_lock. */ if (task_rq(p) == rq) { if (task_on_rq_queued(p)) rq = __migrate_task(rq, &rf, p, arg->dest_cpu); //迁移到dest_cpu else p->wake_cpu = arg->dest_cpu; } rq_unlock(rq, &rf); raw_spin_unlock(&p->pi_lock); local_irq_enable(); return 0; }
然后,在_do_fork() -> wake_up_new_task() -> select_task_rq()中,选择满足cpus_allowed的cpu来执行子进程:
/* * The caller (fork, wakeup) owns p->pi_lock, ->cpus_allowed is stable. */ static inline int select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags, int sibling_count_hint) { bool allow_isolated = (p->flags & PF_KTHREAD); lockdep_assert_held(&p->pi_lock); if (p->nr_cpus_allowed > 1) cpu = p->sched_class->select_task_rq(p, cpu, sd_flags, wake_flags, //通过调用对应sched class的select_task_rq来选择执行子进程的cpu sibling_count_hint); else cpu = cpumask_any(&p->cpus_allowed); /* * In order not to call set_task_cpu() on a blocking task we need * to rely on ttwu() to place the task on a valid ->cpus_allowed * CPU. * * Since this is common to all placement strategies, this lives here. * * [ this allows ->select_task() to simply return task_cpu(p) and * not worry about this generic constraint ] */ if (unlikely(!is_cpu_allowed(p, cpu)) || (cpu_isolated(cpu) && !allow_isolated)) cpu = select_fallback_rq(task_cpu(p), p, allow_isolated); //筛选执行cpu满足cpu_allowed return cpu; }
1.3.3 在设置cpu亲和度(sched_setaffinity)时,会过滤cpuset中配置:
当执行sched_setaffinity设置cpu亲和度的调用路径:sched_setaffinity() -> get_user_cpu_mask()
sched_setaffinity() -> sched_setaffinity()
首先在get_user_cpu_mask()中,从user space获取要设置的cpu mask;
之后在sched_setaffinity()在再进行详细的过滤,从而设置准确的task cpu mask,并挑选出合适的cpu执行task
long sched_setaffinity(pid_t pid, const struct cpumask *in_mask) { cpumask_var_t cpus_allowed, new_mask; struct task_struct *p; int retval; int dest_cpu; cpumask_t allowed_mask; rcu_read_lock(); p = find_process_by_pid(pid); if (!p) { rcu_read_unlock(); return -ESRCH; } /* Prevent p going away */ get_task_struct(p); rcu_read_unlock(); if (p->flags & PF_NO_SETAFFINITY) { retval = -EINVAL; goto out_put_task; } if (!alloc_cpumask_var(&cpus_allowed, GFP_KERNEL)) { retval = -ENOMEM; goto out_put_task; } if (!alloc_cpumask_var(&new_mask, GFP_KERNEL)) { retval = -ENOMEM; goto out_free_cpus_allowed; } retval = -EPERM; if (!check_same_owner(p)) { rcu_read_lock(); if (!ns_capable(__task_cred(p)->user_ns, CAP_SYS_NICE)) { rcu_read_unlock(); goto out_free_new_mask; } rcu_read_unlock(); } retval = security_task_setscheduler(p); if (retval) goto out_free_new_mask; cpuset_cpus_allowed(p, cpus_allowed); //获取task cpuset中allowed_cpu cpumask_and(new_mask, in_mask, cpus_allowed); //将通过user space中获取的cpu mask与task的cpuset进行过滤,找出能同时满足条件的cpu(new_mask) /* * Since bandwidth control happens on root_domain basis, * if admission test is enabled, we only admit -deadline * tasks allowed to run on all the CPUs in the task's * root_domain. */ #ifdef CONFIG_SMP if (task_has_dl_policy(p) && dl_bandwidth_enabled()) { rcu_read_lock(); if (!cpumask_subset(task_rq(p)->rd->span, new_mask)) { retval = -EBUSY; rcu_read_unlock(); goto out_free_new_mask; } rcu_read_unlock(); } #endif again: cpumask_andnot(&allowed_mask, new_mask, cpu_isolated_mask); //从上面得到的new_mask中,过滤掉isolate的cpu,结果保存在allowed_mask dest_cpu = cpumask_any_and(cpu_active_mask, &allowed_mask); //从cpu_active_mask(处于active状态的cpu:可以进行task迁移)和allowed_mask中找到满足条件的dest_cpu if (dest_cpu < nr_cpu_ids) { //如果dest_cpu的index小于当前cpu核最大的index retval = __set_cpus_allowed_ptr(p, new_mask, true); //与fork的路径类似,为设置new_mask为task新的cpus_allowed,并将task执行在dest_cpu上 if (!retval) { cpuset_cpus_allowed(p, cpus_allowed); //再重新获取task的cpus_allowed if (!cpumask_subset(new_mask, cpus_allowed)) { //判断new_mask是否是cpus_allowed的子集,如果不是,则说明cpuset又被修改了。则需要更新task的cpus_allowed /* * We must have raced with a concurrent cpuset * update. Just reset the cpus_allowed to the * cpuset's cpus_allowed */ cpumask_copy(new_mask, cpus_allowed); //赋值new_mask = cpus_allowed goto again; //重复上面步骤 } } } else { retval = -EINVAL; } if (!retval && !(p->flags & PF_KTHREAD)) //PF_KTHREAD代表是否是kernel space创建的进程 cpumask_and(&p->cpus_requested, in_mask, cpu_possible_mask); //将user space设置的cpu mask与cpu_possible_mask(平台支持hotplug,所以它包含所有cpu核) //取同时满足上面2个条件的cpu,存放到task->cpus_requested中 out_free_new_mask: free_cpumask_var(new_mask); out_free_cpus_allowed: free_cpumask_var(cpus_allowed); out_put_task: put_task_struct(p); return retval; }
1.3.4 在task迁移时,会遵循cpuset的配置:
task迁移本质上就是将此cpu rq中的task,放到另一个cpu的rq上。在上面讲到的fork中,子进程就会在创建之后,进行task迁移,当然同时会遵循cpuset的配置;除了fork,还有更一般的调用_migrate_task的进行task迁移的情况,同样也会对cpuset配置进行过滤。
/* * Move (not current) task off this CPU, onto the destination CPU. We're doing * this because either it can't run here any more (set_cpus_allowed() * away from this CPU, or CPU going down), or because we're * attempting to rebalance this task on exec (sched_exec). * * So we race with normal scheduler movements, but that's OK, as long * as the task is no longer on this CPU. */ static struct rq *__migrate_task(struct rq *rq, struct rq_flags *rf, struct task_struct *p, int dest_cpu) { /* Affinity changed (again). */ if (!is_cpu_allowed(p, dest_cpu)) return rq; update_rq_clock(rq); rq = move_queued_task(rq, rf, p, dest_cpu); //迁移task到dest_cpu return rq; }
可以看到有调用is_cpu_allowed()来检测dest_cpu是否在task的cpus_allowed中,并根据是否是内核线程,进行进一步筛选:
/* * Per-CPU kthreads are allowed to run on !actie && online CPUs, see * __set_cpus_allowed_ptr() and select_fallback_rq(). */ static inline bool is_cpu_allowed(struct task_struct *p, int cpu) { if (!cpumask_test_cpu(cpu, &p->cpus_allowed)) //检测dest_cpu是否allow。如果不allow,则return false,且不满足迁移条件 return false; if (is_per_cpu_kthread(p)) //检测task是否是kernel thread,内核进程默认是可以运行在所有online的cpu上 return cpu_online(cpu); //cpu是否online(available to scheduler,可以调度运行) return cpu_active(cpu); //cpu是否active(available to migration,可以迁移) }
1.3.5 在系统调用:mbind、set_mempolicy时,会过滤cpuset中的内存节点:
mbind调用路径:kernel_mbind() -> do_mbind() -> mpol_set_nodemask()
set_mempolicy调用路径:kernel_set_mempolicy() -> do_set_mempolicy() -> mpol_set_nodemask()
函数是在创建新mem policy之后,set up内存node mask
/* * mpol_set_nodemask is called after mpol_new() to set up the nodemask, if * any, for the new policy. mpol_new() has already validated the nodes * parameter with respect to the policy mode and flags. But, we need to * handle an empty nodemask with MPOL_PREFERRED here. * * Must be called holding task's alloc_lock to protect task's mems_allowed * and mempolicy. May also be called holding the mmap_semaphore for write. */ static int mpol_set_nodemask(struct mempolicy *pol, const nodemask_t *nodes, struct nodemask_scratch *nsc) { int ret; /* if mode is MPOL_DEFAULT, pol is NULL. This is right. */ if (pol == NULL) return 0; /* Check N_MEMORY */ nodes_and(nsc->mask1, cpuset_current_mems_allowed, node_states[N_MEMORY]); //获取当前task所允许的内存节点,并与online的节点过滤,找出同时满足条件的节点,存到nsc->mask1中 VM_BUG_ON(!nodes); if (pol->mode == MPOL_PREFERRED && nodes_empty(*nodes)) nodes = NULL; /* explicit local allocation */ else { if (pol->flags & MPOL_F_RELATIVE_NODES) //根据flag不同,将上面得到的nsc->mask1,再次通过不同计算,得到不同的node mask存到nsc->mask2 mpol_relative_nodemask(&nsc->mask2, nodes, &nsc->mask1); else nodes_and(nsc->mask2, *nodes, nsc->mask1); if (mpol_store_user_nodemask(pol)) //根据flag不同,保存不同的node mask结果 pol->w.user_nodemask = *nodes; //保存user space传入的内存节点 else pol->w.cpuset_mems_allowed = cpuset_current_mems_allowed; //保存task允许的内存节点 } if (nodes) ret = mpol_ops[pol->mode].create(pol, &nsc->mask2); //根据不同的policy,调用不同的create方式,allocate内存节点 else ret = mpol_ops[pol->mode].create(pol, NULL); return ret; }
1.3.6 在page_alloc.c中,会限制申请内存节点:
kmalloc() -> kmalloc_large() -> kmalloc_order_trace() -> kmalloc_order() --> alloc_pages() -> alloc_pages_node() -> __alloc_pages_node() -> __alloc_pages() ->__alloc_pages_nodemask() -> get_page_from_freelist() -> __cpuset_zone_allowed()-> __cpuset_node_allowed()
这个函数用于判断是否可以申请一个内存节点。逻辑判断顺序如下:
- 中断中申请内存: ✔
- 申请的节点在task mem_allowed内:✔
- OOM被杀的进程: ✔
- user space申请(user space申请都会设置__GFP_HARDWALL):✖
- 正在退出的进程: ✔
- 未设置__GFP_HARDWALL,但是节点在mems_allowed之外,的内核进程申请:需要往上层寻找带有内存互斥exclusive或者hardwall,并对当前节点有影响的上层节点,并判断当前的node是否在其允许范围内。如果在范围内,则允许申请。
/** * cpuset_node_allowed - Can we allocate on a memory node? * @node: is this an allowed node? * @gfp_mask: memory allocation flags * * If we're in interrupt, yes, we can always allocate. If @node is set in * current's mems_allowed, yes. If it's not a __GFP_HARDWALL request and this * node is set in the nearest hardwalled cpuset ancestor to current's cpuset, * yes. If current has access to memory reserves as an oom victim, yes. * Otherwise, no. * * GFP_USER allocations are marked with the __GFP_HARDWALL bit, * and do not allow allocations outside the current tasks cpuset * unless the task has been OOM killed. * GFP_KERNEL allocations are not so marked, so can escape to the * nearest enclosing hardwalled ancestor cpuset. * * Scanning up parent cpusets requires callback_lock. The * __alloc_pages() routine only calls here with __GFP_HARDWALL bit * _not_ set if it's a GFP_KERNEL allocation, and all nodes in the * current tasks mems_allowed came up empty on the first pass over * the zonelist. So only GFP_KERNEL allocations, if all nodes in the * cpuset are short of memory, might require taking the callback_lock. * * The first call here from mm/page_alloc:get_page_from_freelist() * has __GFP_HARDWALL set in gfp_mask, enforcing hardwall cpusets, * so no allocation on a node outside the cpuset is allowed (unless * in interrupt, of course). * * The second pass through get_page_from_freelist() doesn't even call * here for GFP_ATOMIC calls. For those calls, the __alloc_pages() * variable 'wait' is not set, and the bit ALLOC_CPUSET is not set * in alloc_flags. That logic and the checks below have the combined * affect that: * in_interrupt - any node ok (current task context irrelevant) * GFP_ATOMIC - any node ok * tsk_is_oom_victim - any node ok * GFP_KERNEL - any node in enclosing hardwalled cpuset ok * GFP_USER - only nodes in current tasks mems allowed ok. */ bool __cpuset_node_allowed(int node, gfp_t gfp_mask) { struct cpuset *cs; /* current cpuset ancestors */ int allowed; /* is allocation in zone z allowed? */ unsigned long flags; if (in_interrupt()) //在中断中,永远允许内存申请 return true; if (node_isset(node, current->mems_allowed)) //节点在task的允许范围内 return true; /* * Allow tasks that have access to memory reserves because they have * been OOM killed to get memory anywhere. */ if (unlikely(tsk_is_oom_victim(current))) //oom被kill掉的进程,允许申请 return true; if (gfp_mask & __GFP_HARDWALL) /* If hardwall request, stop here */ //如果是user space的申请request,并且设置了__GFP_HARDWALL,那么不允许 return false; if (current->flags & PF_EXITING) /* Let dying task have memory */ //正在退出的进程,允许申请 return true; /* Not hardwall and node outside mems_allowed: scan up cpusets */ spin_lock_irqsave(&callback_lock, flags); rcu_read_lock(); cs = nearest_hardwall_ancestor(task_cs(current)); //往上层寻找带有内存互斥exclusive或者hardwall,并对当前节点有影响的上层节点 allowed = node_isset(node, cs->mems_allowed); //判断当前的node是否在上层节点的允许范围内 rcu_read_unlock(); spin_unlock_irqrestore(&callback_lock, flags); return allowed; }
1.3.7 在vmscan.c中,限制page恢复到当前cpuset:
调用路径:shrink_zones() -> cpuset_zone_allowed() -> __cpuset_zone_allowed() -> __cpuset_node_allowed()
shrink_zones()函数是linux内存页回收的核心函数。而对于cpuset中内存节点的限制判断逻辑,与page_alloc.c中的完全一样。
/* * This is the direct reclaim path, for page-allocating processes. We only * try to reclaim pages from zones which will satisfy the caller's allocation * request. * * If a zone is deemed to be full of pinned pages then just give it a light * scan then give up on it. */ static void shrink_zones(struct zonelist *zonelist, struct scan_control *sc) { struct zoneref *z; struct zone *zone; unsigned long nr_soft_reclaimed; unsigned long nr_soft_scanned; gfp_t orig_mask; pg_data_t *last_pgdat = NULL; /* * If the number of buffer_heads in the machine exceeds the maximum * allowed level, force direct reclaim to scan the highmem zone as * highmem pages could be pinning lowmem pages storing buffer_heads */ orig_mask = sc->gfp_mask; if (buffer_heads_over_limit) { sc->gfp_mask |= __GFP_HIGHMEM; sc->reclaim_idx = gfp_zone(sc->gfp_mask); } for_each_zone_zonelist_nodemask(zone, z, zonelist, sc->reclaim_idx, sc->nodemask) { /* * Take care memory controller reclaiming has small influence * to global LRU. */ if (global_reclaim(sc)) { if (!cpuset_zone_allowed(zone, GFP_KERNEL | __GFP_HARDWALL)) //设置了__GFP_HARDWALL,所以只能是在task允许的范围内,或者在中断,或者是oom受害者,才可以进行内存回收 continue; /* * If we already have plenty of memory free for * compaction in this zone, don't free any more. * Even though compaction is invoked for any * non-zero order, only frequent costly order * reclamation is disruptive enough to become a * noticeable problem, like transparent huge * page allocations. */ if (IS_ENABLED(CONFIG_COMPACTION) && sc->order > PAGE_ALLOC_COSTLY_ORDER && compaction_ready(zone, sc)) { sc->compaction_ready = true; continue; } /* * Shrink each node in the zonelist once. If the * zonelist is ordered by zone (not the default) then a * node may be shrunk multiple times but in that case * the user prefers lower zones being preserved. */ if (zone->zone_pgdat == last_pgdat) continue; /* * This steals pages from memory cgroups over softlimit * and returns the number of reclaimed pages and * scanned pages. This works for global memory pressure * and balancing, not for a memcg's limit. */ nr_soft_scanned = 0; nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(zone->zone_pgdat, sc->order, sc->gfp_mask, &nr_soft_scanned); sc->nr_reclaimed += nr_soft_reclaimed; sc->nr_scanned += nr_soft_scanned; /* need some check for avoid more shrink_zone() */ } /* See comment about same check for global reclaim above */ if (zone->zone_pgdat == last_pgdat) continue; last_pgdat = zone->zone_pgdat; shrink_node(zone->zone_pgdat, sc); } /* * Restore to original mask to avoid the impact on the caller if we * promoted it to __GFP_HIGHMEM. */ sc->gfp_mask = orig_mask; }
init cpusets代码分析中,还要分析hotplug部分。。。。。。。。待续
1.4 什么是互斥cpuset?
cpu/mem互斥
cpuset中有两个bool类型的参数cpuset.mem_exclusive,cpuset.cpu_exclusive,分别表示当前的cpuset是否是内存互斥和cpu互斥的,自此同一层级的cpuset不能共享互斥的资源。
我们在上面已经理解了层级树的概念,那么cpu互斥就是:如果某个cpuset是cpu互斥的,那么该cpuset中的cpu是不能被该cpuset的兄弟cpuset共享的,当然该cpuset中的cpu是能够和该cpuset的祖先cpuset和子孙cpuset共享的。
注意:设置exclusive时,需要其父节点也为exclusive。否则会设置失败。所以,最终还是说明cpuset的互斥,就是从根节点开始,就已经互斥了。(当前android平台下,默认并没有设置cpu/内存互斥)
内存互斥也是一样,只不过互斥的资源换成了内存节点。
内存mem_hardwall
cpuset还有一个bool类型的参数cpuset.mem_hardwall,如果cpuset被设置成内存互斥(mem_exclusive)或者被设置了cpuset.mem_hardwall,那么都认为这个cpuset是mem_hardwalled。
mem_hardwalled的cpuset中的进程在内核态申请的内存(主要有直接申请的页,以及通过slab系统分配的内存,还有文件系统page cache)会受到cpuset的限制,进而在该cpuset内的内存节点中分配内存。对比:不管cpuset是否是mem_hardwalled,cpuset中的进程在用户态申请的内存都会受到cpuset中内存节点的限制。所以得出:而mem_exclusive除了提供了内存互斥的功能,也包含了cpuset.mem_hardwall的功能。
通过上面,得到如下结论:
1、cpuset.mem_hardwall限制的是cpuset中进程在内核态申请的内存(必须符合cpuset的内存限制)。而用户态申请内存,不管有没有设置mem_hardwall,都会受到cpuset限制。
2、cpuset mem_hardwall=1,那么进程内核态的内存分配会受cpuset中内存节点的限制;反之,内核态则不受cpuset中内存节点的限制。
3、mem_exclusive包含了mem_hardwall的功能。
1.5 memory_pressure
memory_pressure提供了一个监控cpuset内存压力的方法。它会记录为了满足内存足够剩余空间的要求,释放cpuset中内存节点的次数。它是一个int型数值,单位为:每秒该cpuset尝试回收内存的次数*1000,半衰期为10秒。
这个属性可以有助于监控和管理当前cpuset下,各个任务对内存的影响,从而进行进一步地内存节点调配,或任务分配。
使能这个功能需要提前对节点:/dev/cpuset/memory_pressure_enabled,写入1之后,memory_pressure才会开始计算。
数据的计算可以被任何一个attach到该cpuset上的进程执行。当进行调用页回收时,就会执行计算。因为在每组查询上避免对任务列表进行扫描,系统上减少了监视此度量标准的批处理调度程序所施加的系统负载。
1.6 memory spread
有2个flag在cpuset中用于控制kernel从哪里申请内存,并将之用于文件系统得buffer或者相关的kernel内核数据结构。它们分别是cpuset.memory_spread_page 和 cpuset.memory_spread_slab。对其,写入1,则使能;写入0,则关闭使能。
如果cpuset.memory_spread_page被设置了,文件系统的buffer(page cache)将会允许从所有内存mem_allowed的节点中,而不是仅在task所在的节点中寻找free page。
如果cpuset.memory_spread_slab被设置了,slab cache(例如inode,dentry)将会允许从所有内存mem_allowed的节点中,而不是仅在task所在的节点中寻找free page。
默认情况下,flag是disable状态,内存申请会遵循NUMA mempolicy和cpuset的配置;而当打开了memory spread之后,会忽视NUMA mempolicy,并进行spread。一旦再次disable flag,则会继续遵循NUMA mempolicy。
1.7 sched_load_balance
负载均衡(load balance)
kernel调度器会自动进行均衡task的负载:一个cpu没有被充分利用,那么在此CPU上的kernel code就会去寻找overload的CPU,并把task移到空闲的CPU上。分配任务(Task Placement)遵循cpuset配置和cpu亲和度相关系统调用(sched_setaffinity)。
调度域(sched domain)
但是负载均衡算法的开销,以及对一些kernel共享的核心数据结构(比如task list)的影响,会随着执行负载均衡cpu核数的增加而成倍增加。所以调度器会将cpu分为几个调度域,而负载均衡仅会作用在每一个调度域之内。简而言之,在2个更小的调度域内进行负载均衡的开销,比在一个大的调度域内进行负载均衡的开销更小。但是在调度域之间就不会进行负载均衡了。不同调度域之间没有重叠部分,有的cpu可能不在任何调度域内,因为它不需要进行负载均衡。
cpuset.sched_load_balance
cpuset.sched_load_balance被设置之后,需要当前cpuset.cpus中的cpu是在同一个的调度域中,从而在内cpuset.cpus内进行负载均衡。
cpuset.sched_load_balance被disable之后,就是停止cpuset.cpus内的负载均衡。但是如果cpuset.cpus与其他cpuset中配置有重叠,并且设置了cpuset.sched_load_balance,那么仍然会在其cpus中进行负载均衡,例如,在根节点的cpuset中设置cpuset.sched_load_balance,那么就会在在所有cpu中进行负载均衡。
因此,在设置cpuset.sched_load_balance的时候,应该保持top层的节点不设置cpuset.sched_load_balance,而只在child层或者一些更小的cpuset中,进行设置。
同时,由于cpuset是呈层级网状结构的;而cpuset.sched_load_balance是一维flat结构,它们不会出现重叠,每个cpu最多只会出现在一个调度域中。
那么假如在2个cpuset中有出现cpus部分重叠,并且都设置了cpuset.sched_load_balance,那么我们应该重新构造一个单独的、包含这2个cpuset的扩展集合。因为我们遵循不将task移出当前cpuset中的规则,这样可以防止调度器产生多余的开销。
假如在2个cpuset中有出现cpus部分重叠,并且其中之一设置了cpuset.sched_load_balance,那么就会出现负载均衡仅在重叠的cpu中进行。针对这样的情况,我们就不能把一些可能需要较多CPU资源的task放在这样的cpuset中。
我们当前SDM845 Android平台,是在top cpuset下,已经打开fully负载均衡的。也就是一个调度域涵盖了整个系统,其他cpuset的设置已经不生效了。
1.8 sched_relax_domain_level
在调度域中,主要有2种触发迁移task的方式:1. tick周期性负载均衡 2. 出现某些调度events。
当一个task被唤醒,就会被迁移到idle cpu上。例如:当task A在CPU X上运行,并唤醒了同在CPU X上的另一个task B。那么调度器就会把task B迁移到CPU Y(CPU Y为CPU X的兄弟)。这样task B可以直接在CPU Y上运行,避免了等待task A执行的情况。当CPU的task跑完了,在进入idle之前,会尝试从其他繁忙的CPU上迁移一些task,帮繁忙的CPU分担一些task。
当然,寻找可迁移的task和需要迁移的CPU会产生一些开销,但调度器并不是每次都会在域中搜索所有的CPU。实际上,在一些架构下,因调度events触发时,搜索的范围会被限制在cpu所在的socket或者node节点;而在周期性负载均衡时,搜索范围则是所有cpu。例如:假设CPU Z与CPU X相对较远(非兄弟),那么尽管CPU Z处于idle,而CPU X以及其兄弟CPU都很繁忙,调度器还是不会将刚唤醒的task B迁移到CPU Z上,因为CPU Z不在搜索范围内。最后,要么task B等待task A执行结束后被执行,要么等到下次周期性负载均衡时进行迁移。
cpuset.sched_relax_domain_level
sched_relax_domain_level属性允许了用户对搜索范围的修改。它用int型的值来体现搜索范围的设置,如下:
-1 : no request. use system default or follow request of others.
0 : no search.
1 : search siblings (hyperthreads in a core).
2 : search cores in a package.
3 : search cpus in a node [= system wide on non-NUMA system]
4 : search nodes in a chunk of node [on NUMA system]
5 : search system wide [on NUMA system]
这个属性影响的是cpuset所在的调度域,所以sched_load_balance这个flag不能disable,因为disable了的话,就没有调度域了。
如果有多个cpuset部分重叠,因此他们会形成一个单独的调度域,那么sched_relax_domain_level就会使用其中的最大值。注:如果有1个设置的值为0,而其他都为-1,那么生效的值为0。
修改这个属性,会同时产生正面和负面影响,当我们不确定的时候,不要改动此值。
1.9 cpuset.memory_migrate
一般情况下,allocate一个page之后,只要它一直保持着allocate,那么这个page就会一直保持着,即便cpuset.mems后来发生了改变。
而当设置了这个flag之后,当task迁移到新的cpuset下时,就会将在原先cpuset所allocate的内存迁移到新的cpuset下,并且是与原先相对应的page位置。
比如,原先内存申请在原cpuset的第2个内存节点;那么在新cpuset也会使用第2个内存节点。迁移操作时,就会尽可能地将新cpuset中的第2个节点释放出来。
2. 使用example和语法
Andoird下cpuset的路径:
htc_imedugl:/ # ls /dev/cpuset
audio-app effective_cpus mems
background effective_mems notify_on_release
camera-daemon foreground release_agent
camera-video mem_exclusive restricted
cgroup.clone_children mem_hardwall sched_load_balance
cgroup.procs memory_migrate sched_relax_domain_level
cgroup.sane_behavior memory_pressure system-background
cpu_exclusive memory_pressure_enabled tasks
cpus memory_spread_page top-app
memory_spread_slab
查看cpus和mems资源:
htc_imedugl:/dev/cpuset # cat cpus 0-7 htc_imedugl:/dev/cpuset # cat mems 0
当前Android下,内存节点mems资源仅有一个。所以可以理解为cpuset仅控制了cpu core资源的分配。
2.1 创建新cpuset
在根节点下,创建一个新的cpuset,命名为 cpuset-test:
mkdir /dev/cpuset/cpuset-test
创建好后,目录如下:
htc_imedugl:/ # ls /dev/cpuset/cpuset-test
cgroup.clone_children mem_exclusive mems
cgroup.procs mem_hardwall notify_on_release
cpu_exclusive memory_migrate sched_load_balance
cpus memory_pressure sched_relax_domain_level
effective_cpus memory_spread_page tasks
effective_mems memory_spread_slab
但是其中cpus,mems都为空。这个需要手动设置填充:
未设置前,为空(此时进程是不能attach进来的): htc_imedugl:/ # cat dev/cpuset/cpuset-test/mems htc_imedugl:/ # cat dev/cpuset/cpuset-test/cpus
2.2 修改cpuset
预设cpus为2-3,那么attach到此cpuset下的进程,就会限制在CPU 2-3上运行;而mems则是使用根节点的值 0,不受限制。
填充: htc_imedugl:/dev/cpuset/cpuset-test # echo 2-3 > cpus htc_imedugl:/dev/cpuset/cpuset-test # echo 0 > mems htc_imedugl:/dev/cpuset/cpuset-test # cat cpus 2-3 htc_imedugl:/dev/cpuset/cpuset-test # cat mems 0
2.3 进程attach
假设我们创建一个sh进程,获得它的pid:
htc_imedugl:/dev/cpuset/ljj # while true; do a=a+1; done & [1] 25035
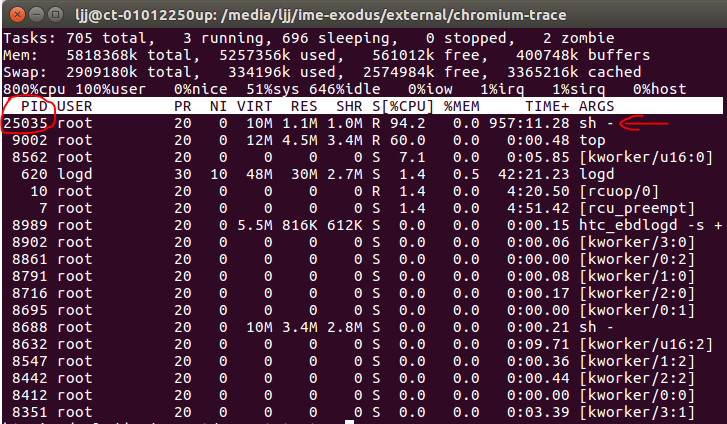
此时默认该进程是挂在根节点的cpuset下:
htc_imedugl:/dev/cpuset/cpuset-test # cat /proc/25035/cgroup 4:cpuset:/ 3:cpu:/ 2:schedtune:/ 1:cpuacct:/uid_0/pid_5099 0::/
再把该进程attach到cpuset-test下面:
把进程的pid echo到cpuset-test/tasks,就可以完成attach:
htc_imedugl:/dev/cpuset/cpuset-test # echo 25035 > tasks htc_imedugl:/dev/cpuset/cpuset-test # cat tasks 25035 并且查看进程信息: htc_imedugl:/dev/cpuset/cpuset-test # cat /proc/25035/cgroup 4:cpuset:/cpuset-test 3:cpu:/ 2:schedtune:/ 1:cpuacct:/uid_0/pid_5099 0::/
抓取systrace,可以看到进程确实运行在CPU2,CPU3上:

假如再修改cpus限制为core 7:
htc_imedugl:/dev/cpuset/cpuset-test # echo 7 > cpus htc_imedugl:/dev/cpuset/cpuset-test # cat cpus 7
再抓取systrace,可以看到25035进程已经被限制运行在CPU 7上:

2.4 删除cpuset
当cpuset中仍然有进程attach,是无法删除的:
rmdir: cpuset-test/: Device or resource busy
所以,我们先要把tasks移出,然后执行:
htc_imedugl:/dev/cpuset # rmdir cpuset-test/
就可以把cpuset删除了
2.5 其他flag设置
设置flag的方法都是写入int值的方式。
例如,cpu互斥:
echo 1 > cpu_exclusive