DISK IOPS / Input/Output Operations Per Second
http://baike.baidu.com/view/2302083.htm
IOPS (Input/Output Operations Per Second),即每秒进行读写(I/O)操作的次数,多用于数据库等场合,衡量随机访问的性能。存储端的IOPS性能和主机端的IO是不同的,IOPS是指存储每秒可接受多少次主机发出的访问,主机的一次IO需要多次访问存储才可以完成。例如,主机写入一个最小的数据块,也要经过“发送写入请求、写入数据、收到写入确认”等三个步骤,也就是3个存储端访问。
IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
http://blog.csdn.net/historyasamirror/article/details/5778378
当你发现自己最受欢迎的一篇blog其实大错特错时,这绝对不是一件让人愉悦的事。
《 IO - 同步,异步,阻塞,非阻塞 》是我在开始学习epoll和libevent的时候写的,主要的思路来自于文中的那篇link 。写完之后发现很多人都很喜欢,我还是非常开心的,也说明这个问题确实困扰了很多人。随着学习的深入,渐渐的感觉原来的理解有些偏差,但是还是没引起自己 的重视,觉着都是一些小错误,无伤大雅。直到有位博友问了一个问题,我重新查阅了一些更权威的资料,才发现原来的文章中有很大的理论错误。我不知道有多少 人已经看过这篇blog并受到了我的误导,鄙人在此表示抱歉。俺以后写技术blog会更加严谨的。
一度想把原文删了,最后还是没舍得。毕竟每篇blog都花费了不少心血,另外放在那里也可以引以为戒。所以这里新补一篇。算是亡羊补牢吧。
言归正传。
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为 asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,我先 限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。
本文最重要的参考文献是Richard Stevens的“UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking ”,6.2节“I/O Models ”,Stevens在这节中详细说明了各种IO的特点和区别,如果英文够好的话,推荐直接阅读。Stevens的文风是有名的深入浅出,所以不用担心看不懂。本文中的流程图也是截取自参考文献。
为什么服务器磁盘io会这么慢
http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=24347291&id=4563094
如何让linux服务器磁盘io性能翻倍
http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=24347291&id=4563042
定位IOWait高的一些方法和工具:
http://blog.csdn.net/guoguo1980/article/details/2333817
在Linux性能分析时经常使用的工具包括:top, iostat, vmstat等
IOWait高的一些处理方法
1、检查RAID的状态,比如是否正在重建或者没有初始化
2、替换操作系统的内核,最好使用发行版标准的Linux kernel,因为有比较多的补丁
3、检查/proc/sys/vm下面是否可以优化
4、是否使用了文件系统,文件系统是否有优化的选项,比如在RAID5上采用xfs文件系统时,
可以调节一些参数优化性能
5、客户端程序是否产生了过大的压力,比如磁盘的读写性能只有10MB/s,每个线程的读写
速度为5MB/s,那么如果读写线程数为20的话,无疑会造成IOWait过高
6、查看进程状态
ps -eo pid,user,wchan=WIDE-WCHAN-COLUMN -o s,cmd|awk ' $4 ~ /D/ {print $0}'
lsof -p $pid
7、使用block_dump
/etc/init.d/syslog stop
echo 1 > /proc/sys/vm/block_dump
sleep 60
dmesg | awk '/(READ|WRITE|dirtied)/ {process[$1]++} END {for (x in process) /
print process[x],x}' |sort -nr |awk '{print $2 " " $1}' | /
head -n 10
echo 0 > /proc/sys/vm/block_dump
/etc/init.d/syslog start
Stevens在文章中一共比较了五种IO Model:
blocking IO
nonblocking IO
IO multiplexing
signal driven IO
asynchronous IO
由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
blocking IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
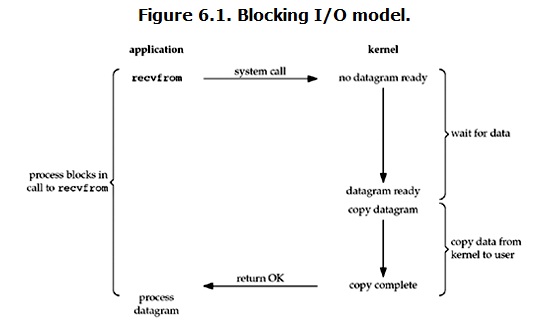
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整 个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除 block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
non-blocking IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
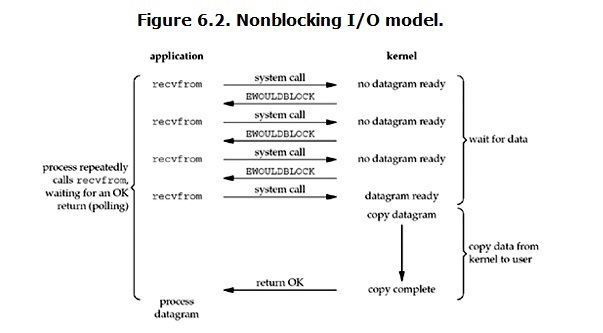
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个 error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次 发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
IO multiplexing
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select /epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
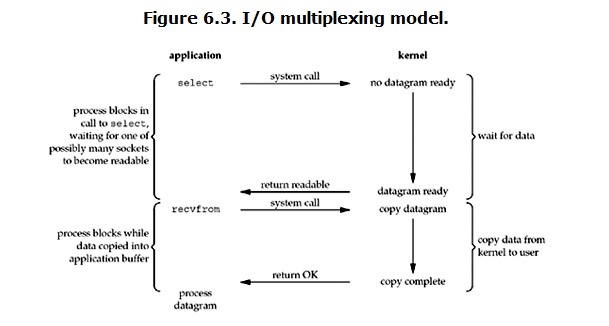
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个 socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句。所以,如果处理的连接数不是很高的话,使用 select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被 block的。只不过process是被select这个函数block,而不是被socket IO给block。
Asynchronous I/O
linux下的asynchronous IO其实用得很少。先看一下它的流程:
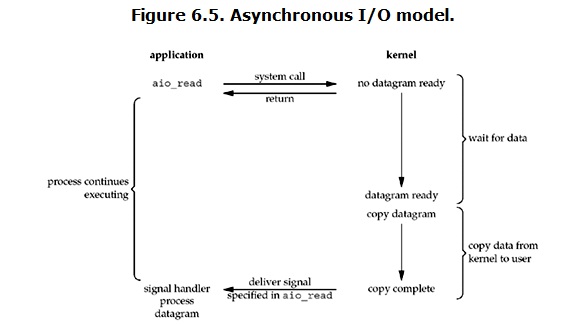
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。
先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从 kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用 recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的 状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
MacBookPro 373 / Mac OS X Snow Lepard 10.6.8 / SSD Samsung 830 7PC512B/WW 512GB 6Gb/s


MacBookPro 373 / Mac OS X Snow Lepard 10.6.8 / Raid0=Toshiba 500G 3Gb/s + Hitachi 500G 3Gb/s
http://dl.iteye.com/upload/attachment/0076/4111/eafadeaf-2539-39df-940f-e8959a423e22.png

# iotop
# iostat -x 1 5
http://shixm.iteye.com/blog/1454711
如果%util 接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果idle小于70%,I/O的压力就比较大了,说明读取进程中有较多的wait。
Linux 2.6.18-92.el5xen 02/03/2009
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 0.00 4.82 39.54 0.07 54.46
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08
sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36
sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘
可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
磁盘恢复软件
富士通 134G 10000转/分
pc-3000
http://www.1huifu.com/Get/dr-doc/14_31_28_8592.htm
ufs explorer
北京江民下层
http://www.fix.com.cn
fix ?
- Recover My Files V3.98.6408 汉化绿色特别版 媒体数据以及zip文件恢复
- Smart Flash Recovery V4.2 汉化绿色版 U盘文件恢复工具
- Recuva v1.26.416 汉化绿色免费版 恢复误删除文件
- EasyRecovery Pro 超强数据恢复工具 6.12.02 绿色版
- 易我硬盘数据恢复 2.1.0 绿色版
- FinalData v2.0.1.1028 汉化绿色特别版
- CardRecovery V5.20 英文绿色特别版 数码记忆卡的照片恢复软件
- EasyRecovery Pro V6.12.02 汉化绿色精简版
- Recover4all Pro V2.32 绿色版
- CardRecovery V5.20 汉化绿色特别版 用于相机使用的数码记忆卡照片恢复软件
禁止U盘复制本机文件
http://www.17zmeng.com/Article/?2371.html

操作步骤
第一步:在开始菜单打开“运行”输入“regedit”打开注册表编辑器。展开 [HKEY_LOCAL_MACHINESYSTEMCurrentControLSetControl],在该分支下新建一个名为 “StorageDevicePolicies”的子项,在该子项中右侧的新建名为“WriteProtect”的DWORD值,并将此值设置为0。
第二步:右键“StorageDevicePolicies”子项,选择”导出,将该键值导出为“y.reg”。然后将“WriteProtect”的DWORD值,并将此值设置为“1”,同时导出为“U盘只读”(禁止使用U盘),放在桌面上。
第三步:启动“记事本”,制作一个批处理文件“YES.bat” ,放置在C:WINDOWSSYSTEM32下,代码如下:
Echo off
Reg import c:y.reg
OK,现在双击“U盘只读.reg”,再插入U盘从本机复制文件时,系统就会出现图2所示。

如果自己想复制文件到U盘时,只要在“开始”-“运行”里输入“YES”后,再插入U盘即可可以复制文件了,只要再双击“U盘只读.reg”,即可禁止U盘复制,是不是很方便啊。快点试一试吧!
如果觉得上述方法比较麻烦,可以把下列文字(橘黄色)复制到“记事本”,分别保存为“Y.reg”、“U盘只读.reg”
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlStorageDevicePolicies]
"WriteProtect"=dword:00000000
--------------------------------------------------------------------------------
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlStorageDevicePolicies]
"WriteProtect"=dword:00000001
orico 229rsh内置双硬盘raid 阵列盒支持 raid0,1 免工具抽取盒
淘宝链接:http://item.taobao.com/item.htm?id=7115730046
http://we.pcinlife.com/forum.php?mod=viewthread&tid=1539702
选择Orico2232RUS硬盘存储的理由:RAID0 / RAID1 / JBOD /BIG


以上四种Raid模式,会有相应的指示灯,下面大概解释一下Raid的基本作用:
1、FAST模式(即RAID 0)
FAST状态也就是我们熟悉的RAID 0模式。在RAID 0状态下,存储数据被分割成两部分,分别存储在两块硬盘上,此时移动硬盘的理论存储速度是单块硬盘的2倍,实际容量等于两块硬盘中较小一块硬盘的容量的2倍。RAID 0的不足之处在于,任何一块硬盘发生故障,整个RAID上的数据将不可恢复。
备注:copy高清电影比较适合
2、SAFE模式(即RAID 1)
SAFE模式即RAID 1模式,在此种模式下,两块硬盘互为镜像。移动硬盘的实际容量等于较小一块硬盘的容量,存储速度与单块硬盘相同。RAID 1的优势在于任何一块硬盘出现故障是,所存储的数据都不会丢失,缺点在于硬盘容量损失较大。
备注:非常重要的资料,如数据库,个人资料,是万无一失的存储方案
3、JBOD模式
在JBOD设置下,硬盘盒不使用任何RAID模式。在JBOD状态下,硬盘盒内的2块硬盘模式均出于独立运行的状态,在系统中也被识别为两颗独立的硬盘,用户可以任意选择存储文件的硬盘。如果其中一块硬盘损坏,另一块硬盘上的数据不受干扰。
备注:相当于普通的硬盘盒模式,同时可以用一根USB或是eSATA认为两个硬盘,如果用eSATA的话,电脑host必须支持PM(端口倍增)功能,如不支持,请购买一个eSATA扩展卡,一般的SYBA原装的eSATA扩展卡都支持的!(不能用档板)
4、BIG模式
BIG模式是即硬盘盒的默认模式,在这种模式下,两块硬盘将被简单地捆绑合并为一块硬盘,硬盘的性能和读写速度与单块硬盘相同,移动硬盘的总容量等于两块硬盘容量之和。当写入数据时,系统会指定数据从第一个磁盘开始存储,当第一个磁盘的存储空间用完后,再依次从后面的磁盘开始存储数据。如果第一块磁盘的数据出现损坏,那么两块硬盘的数据将完全丢失。
以上四种模式,各位烧友,可以根据自己的情况进行选择,注意事项如下:
1,使用前请先备分该硬盘内的资料,一旦进行RAID设定或是变更RAID模式,将会清除原先硬盘里的所有资料,并要求您重新格式化硬盘,并将无法恢复!
2,RAID1功能主要适合重要资料备份并不适合做为对拷使用,不能将两个硬盘互置使用,建立RAID时,我们建议使用相同品牌,型号跟大小的硬盘,以确保稳定性经及性能,一般情况下请不要随意更换或取出硬盘以避免造成资料的丢失
3,建议采用全新硬盘,如果旧硬盘曾经在RAID模式下使用,请先进行完整清除的动作,让硬盘回复至出厂状态,以免建立Raid模式失败
4,当使用旧硬盘作RAID功能时,我们建议先重新格式化硬盘(新硬盘可以省略)
5,RAID0/BIG模式下,其中一个硬盘损坏时,其它硬盘所有资料都将丢失。
6,更换RAID模式时,需要在电源开启状态下进行,更换完成后,按Reset按键(资料将被清除)
7,Raid1(SAFE)模式下,会先进行硬盘重建,此为正常现像,会需要一定的时间,一般100GB大约需要1个小时左右(具体视环境而定)
8,初次使用或更换RAID模式,在开启电源的同时会将硬盘内的档案清除,请在此之前备份您的资料
9,请确认您的硬盘是否支持RAID功能,目前已知Western Digital Desktop Edition的硬盘不支持Raid功能
10,如果您是需要两个硬盘对拷,建议您使用JBOD功能
disk raid / raid0 / raid1 / raid5 / raid50 / raid10
http://baike.baidu.com/view/7102.htm
http://www.iteye.com/topic/320113
http://xiaohui.iteye.com/blog/169847
RAID是英文Redundant Array of Independent Disks的缩写,翻译成中文意思是“独立磁盘冗余阵列”,有时也简称磁盘阵列(Disk Array)。
简单的说,RAID是一种把多块独立的硬盘(物理硬盘)按不同的方式组合起来形成一个硬盘组(逻辑硬盘),从而提供比单个硬盘更高的存储性能和提供数据备份技术。组成磁盘阵列的不同方式成为RAID级别(RAID Levels)。数据备份的功能是在用户数据一旦发生损坏后,利用备份信息可以使损坏数据得以恢复,从而保障了用户数据的安全性。在用户看起来,组成的磁盘组就像是一个硬盘,用户可以对它进行分区,格式化等等。总之,对磁盘阵列的操作与单个硬盘一模一样。不同的是,磁盘阵列的存储速度要比单个硬盘高很多,而且可以提供自动数据备份。
RAID技术的两大特点:一是速度、二是安全,由于这两项优点,RAID技术早期被应用于高级服务器中的SCSI接口的硬盘系统中,随着近年计算机技术的发展,PC机的CPU的速度已进入GHz 时代。IDE接口的硬盘也不甘落后,相继推出了ATA66和ATA100硬盘。这就使得RAID技术被应用于中低档甚至个人PC机上成为可能。RAID通常是由在硬盘阵列塔中的RAID控制器或电脑中的RAID卡来实现的。
RAID技术经过不断的发展,现在已拥有了从 RAID 0 到 6 七种基本的RAID 级别。另外,还有一些基本RAID级别的组合形式,如RAID 10(RAID 0与RAID 1的组合),RAID 50(RAID 0与RAID 5的组合)等。不同RAID 级别代表着不同的存储性能、数据安全性和存储成本。但我们最为常用的是下面的几种RAID形式。
(1) RAID 0
(2) RAID 1
(3) RAID 0+1
(4) RAID 3
(5) RAID 5
RAID级别的选择有三个主要因素:可用性(数据冗余)、性能和成本。如果不要求可用性,选择RAID0以获得最佳性能。如果可用性和性能是重要的而成本不是一个主要因素,则根据硬盘数量选择RAID 1。如果可用性、成本和性能都同样重要,则根据一般的数据传输和硬盘的数量选择RAID3、RAID5。
一.RAID定义
RAID(Redundant Array of Independent Disk 独立冗余磁盘阵列)技术是加州大学伯克利分校1987年提出,最初是为了组合小的廉价磁盘来代替大的昂贵磁盘,同时希望磁盘失效时不会使对数据的访问受损失而开发出一定水平的数据保护技术。RAID就是一种由多块廉价磁盘构成的冗余阵列,在操作系统下是作为一个独立的大型存储设备出现。RAID可以充分发挥出多块硬盘的优势,可以提升硬盘速度,增大容量,提供容错功能够确保数据安全性,易于管理的优点,在任何一块硬盘出现问题的情况下都可以继续工作,不会受到损坏硬盘的影响。
二、RAID的几种工作模式(仅讨论RAID0,RAID1,RAID5,RAID10这四种,这四种比较典型 )
1、RAID0 (又称为Stripe或Striping--分条)
即Data Stripping数据分条技术。RAID 0可以把多块硬盘连成一个容量更大的硬盘群,可以提高磁 盘的性能和吞吐量。RAID 0没有冗余或错误修复能力,成本低,要求至少两个磁盘,一般只是在那些对数 据安全性要求不高的情况下才被使用。
特点:
| 容错性: | 没有 | 冗余类型: | 没有 |
| 热备盘选项: | 没有 | 读性能: | 高 |
| 随机写性能: | 高 | 连续写性能: | 高 |
| 需要的磁盘数: | 只需2个或2*N个(这里应该是多于两个硬盘都可以) | 可用容量: | 总的磁盘的容量 |
| 典型应用: | 无故障的迅速读写,要求安全性不高,如图形工作站等。 | ||
RAID 0的工作方式:

图1
如图1所示:系统向三个磁盘组成的逻辑硬盘(RADI 0 磁盘组)发出的I/O数据请求被转化为3项操作,其中的每一项操作都对应于一块物理硬盘。我们从图中可以清楚的看到通过建立RAID 0,原先顺序的数据请求被分散到所有的三块硬盘中同时执行。
从理论上讲,三块硬盘的并行操作使同一时间内磁盘读写速度提升了3倍。 但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,但是,大量数据并行传输与串行传输比较,提速效果显著显然毋庸置疑。
RAID 0的缺点 是不提供数据冗余,因此一旦用户数据损坏,损坏的数据将无法得到恢复。
RAID 0具有的特点 ,使其特别适用于对性能要求较高,而对数据安全不太在乎的领域,如图形工作站等。对于个人用户,RAID 0也是提高硬盘存储性能的绝佳选择。
计算机技术发展迅速,但硬盘传输率也成了性能的瓶颈。怎么办?IDE RAID技术的成熟让我们轻松打造自己的超高速硬盘。在实际应用中,RAID 0硬盘阵列能比普通IDE 7200转ATA 133硬盘快得多,时至今日,在大多数的高端或者玩家主板上我们都能找到一颗PROMISE或者HighPoint的RAID芯片,同时发现它们提供的额外几个IDE接口。没错,RAID已经近在眼前,难道你甘心放弃RAID为我们带来的性能提升吗?答案当然是否定的!
实用的IDE RAID
RAID可以通过软件或硬件实现。像Windows 2000就能够提供软件的RAID功能,但是这样需要消耗不小的CPU资源,降低整机性能。而硬件实现则是一般由RAID卡实现的,高档的SCSI RAID卡有着自己专用的缓存和I/O处理器,但是对于家庭用户来说这样的开销显然是承受不了的,毕竟为了实现RAID买两个或者更多的HDD已经相当不容易了。我们还有一种折中的办法——IDE RAID。或许这才是普通人最容易接受的方法。虽然IDE RAID在功能和性能上都有所折中,但相对于低廉的价格,普通用户看来并不在意。
为什么要用RAID 0
RAID 0至少需要两块硬盘才能够实现,它的容量为组成这个系统的各个硬盘容量之和,这几块硬盘的容量要相同,在家用IDE RAID中一般级联两块硬盘,一定要用同型号同容量的硬盘。RAID 0模式向硬盘写入数据的时候把数据一分为二,分别写入两块硬盘,读取数据的时候则反之,这样的话,每块硬盘只要负担一半的数据传输任务,得到的结果也就是速度的增加。
实现方式:
(1)、 RAID 0最简单方式(我觉得这个方式不是它本意所提倡的)
就是把x块同样的硬盘用硬件的形式通过智能磁盘控制器或用操作系统中的磁盘驱动程序以软件的方式串联在一起,形成一个独立的逻辑驱动器,容量是单独硬盘的x倍,在电脑数据写时被依次写入到各磁盘 中,当一块磁盘的空间用尽时,数据就会被自动写入到下一块磁盘中,它的好处是可以增加磁盘的容量。
速度与其中任何一块磁盘的速度相同,如果其中的任何一块磁盘出现故障,整个系统将会受到破坏,可靠
性是单独使用一块硬盘的1/n。
(2)、 RAID 0的另一方式(常指的RAID 0就是指的这个)
是用n块硬盘选择合理的带区大小创建带区集,最好是为每一块硬盘都配备一个专门的磁盘控制器,在 电脑数据读写时同时向n块磁盘读写数据,速度提升n倍。提高系统的性能。
2、RAID 1 (又称为Mirror或Mirroring--镜像)
RAID 1称为磁盘镜像:把一个磁盘的数据镜像到另一个磁盘上,在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,具有很高的数据冗余能力,但磁盘利用率为50%,故成本最高,多用在保存关键性的重要数据的场合。RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。
RAID 1有以下特点 :
(1)、RAID 1的每一个磁盘都具有一个对应的镜像盘,任何时候数据都同步镜像,系统可以从一组 镜像盘中的任何一个磁盘读取数据。
(2)、磁盘所能使用的空间只有磁盘容量总和的一半,系统成本高。
(3)、只要系统中任何一对镜像盘中至少有一块磁盘可以使用,甚至可以在一半数量的硬盘出现问题时系统都可以正常运行。
(4)、出现硬盘故障的RAID系统不再可靠,应当及时的更换损坏的硬盘,否则剩余的镜像盘也出现问题,那么整个系统就会崩溃。
(5)、更换新盘后原有数据会需要很长时间同步镜像,外界对数据的访问不会受到影响,只是这时整个系统的性能有所下降。
(6)、RAID 1磁盘控制器的负载相当大,用多个磁盘控制器可以提高数据的安全性和可用性。
RAID 1的工作方式:

图2
如图2所示:当读取数据时,系统先从RAID1的源盘读取数据,如果读取数据成功,则系统不去管备份盘上的数据;如果读取源盘数据失败,则系统自动转而读取备份盘上的数据,不会造成用户工作任务的中断。当然,我们应当及时地更换损坏的硬盘并利用备份数据重新建立Mirror,避免备份盘在发生损坏时,造成不可挽回的数据损失。
raid 1的优缺点
由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而Mirror(镜像)的磁盘空间利用率低,存储成本高。Mirror虽不能提高存储性能,但由于其具有的高数据安全性,使其尤其适用于存放重要数据,如服务器和数据库存储等领域。
3、RAID 5 (可以理解为是RAID 0和RAID 1的折衷方案,但没有完全使用RAID 1镜像理念,而是使用了“奇偶校验信息”来作为数据恢复的方式,与下面的RAID10不同。)
| 容错性: | 有 | 冗余类型: | 奇偶校验 |
| 热备盘选项: | 有 | 读性能: | 高 |
| 随机写性能: | 低 | 连续写性能: | 低 |
| 需要的磁盘数: | 三个或更多 | ||
| 可用容量: | (n-1)/n的总磁盘容量(n为磁盘数) | ||
| 典型应用: | 随机数据传输要求安全性高,如金融、数据库、存储等。 | ||

图3
RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。 以四个硬盘组成的RAID 5为例,其数据存储方式如图4所示:图中,Ap为A1,A2和A3的奇偶校验信息,其它以此类推。由图中可以看出,RAID 5不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低。
4、RAID 5 (可以理解为是RAID 0和RAID 1的折衷方案,但没有完全使用RAID 1镜像理念,而是使用了“奇偶校验信息”来作为数据恢复的方式)

图4
RAID10也被称为镜象阵列条带。象RAID0一样,数据跨磁盘抽取;象RAID1一样,每个磁盘都有一个镜象磁盘, 所以RAID 10的另一种会说法是 RAID 0+1。RAID10提供100%的数据冗余,支持更大的卷尺寸,但价格也相对较高。对大多数只要求具有冗余度而不必考虑价格的应用来说,RAID10提供最好的性能。使用RAID10,可以获得更好的可靠性,因为即使两个物理驱动器发生故障(每个阵列中一个),数据仍然可以得到保护。RAID10需要4 + 2*N 个磁盘驱动器(N >=0), 而且只能使用其中一半(或更小, 如果磁盘大小不一)的磁盘用量, 例如 4 个 250G 的硬盘使用RAID10 阵列, 实际容量是 500G。
个人总结 :
| 类型 | 读写性能 | 安全性 | 磁盘利用率 | 成本 | 应用方面 |
| RAID0 | 最好(因并行性而提高) | 最差(完全无安全保障) | 最高(100%) | 最低 | 个人用户 |
| RAID1 | 读和单个磁盘无分别,写则要写两边 | 最高(提供数据的百分之百备份) | 差(50%) | 最高 | 适用于存放重要数据,如服务器和数据库存储等领域。 |
| RAID5 | 读:RAID 5=RAID 0(相近似的数据读取速度) 写:RAID 5<对单个磁盘进行写入操作(多了一个奇偶校验信息写入) | RAID 5<RAID 1 | RAID 5>RAID 1 | RAID 5<RAID 1 | 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。 |
| RAID10 | 读:RAID10=RAID0 写:RAID10=RAID1 | RAID10=RAID1 | RAID10=RAID1(50%) | RAID10=RAID1 | 集合了RAID0,RAID1的优点,但是空间上由于使用镜像,而不是类似RAID5的“奇偶校验信息”,磁盘利用率一样是50% |
相关链接:
http://k.pconline.com.cn/question/914468.html
http://hi.baidu.com/caronation/blog/item/a61cbc13e01917896538db1a.html
IOPS
http://hbase.iteye.com/picture/100721

http://en.wikipedia.org/wiki/IOPS
IOPS (Input/Output Operations Per Second) is a common benchmark for harddisks and other computer storage media. Like with any benchmark, IOPS numbers published by drive and SAN vendors are often misleading and do not guarantee real-world application performance.
IOPS can be measured with applications such as Iometer (originally developed by Intel) as well as IOZone[1] and FIO[2] and is primarily used with servers to find the best storage configuration.
The specific number of IOPS possible in any server configuration will vary greatly depending upon the variables the tester enters into the program, including the balance of read and write operations, the mix of random or sequential access patterns, the number of worker threads and queue depth, as well as the data block sizes.
存储端的IOPS性能和主机端的IO是不同的,IOPS是指存储每秒可接受多少次主机发出的访问,主机的一次IO需要多次访问存储才可以完成。例如,主机写入一个最小的数据块,也要经过“发送写入请求、写入数据、收到写入确认”等三个步骤,也就是3个存储端访问。
所以到底能支持多少个IO,要看业务系统类型和数据读写方式了。
http://baike.baidu.com/view/2302083.htm
IOPS (Input/Output Operations Per Second),即每秒进行读写(I/O)操作的次数,多用于数据库等场合,衡量随机访问的性能。存储端的IOPS性能和主机端的IO是不同的,IOPS 是指存储每秒可接受多少次主机发出的访问,主机的一次IO需要多次访问存储才可以完成。例如,主机写入一个最小的数据块,也要经过“发送写入请求、写入数 据、收到写入确认”等三个步骤,也就是3个存储端访问。
编辑本段 磁盘阵列吞吐量与IOPS两大瓶颈分析
本文是由 NSIDC 总结的,分析了磁盘阵列的瓶颈,主要体现在2个方面:吞吐量与IOPS。1、吞吐量
吞吐量主要取决于阵列的构架,光纤通道的大小(现在阵列一般都是光纤阵列,至于SCSI这样的SSA阵列,我们不讨论)以及硬盘的个数。阵列的构架与每 个阵列不同而不同,他们也都存在内部带宽(类似于pc的系统总线),不过一般情况下,内部带宽都设计的很充足,不是瓶颈的所在。 光纤通道的影响还是比较大的,如数据仓库环境中,对数据的流量要求很大,而一块2Gb的光纤卡,所能支撑的最大流量应当是2Gb/8(小B)=250MB/s(大B)的实际流量,当4块光纤卡才能达到1GB/s的实际流量,所以数据仓库环境可以考虑换4Gb的光纤卡。 最后说一下硬盘的限制,这里是最重要的,当前面的瓶颈不再存在的时候,就要看硬盘的个数了,我下面列一下不同的硬盘所能支撑的流量大小: 10 K rpm 15 K rpm ATA ——— ——— ——— 10M/s 13M/s 8M/s 那么,假定一个阵列有120块15K rpm的光纤硬盘,那么硬盘上最大的 可以支撑的流量为120*13=1560MB/s,如果是2Gb的光纤卡,可能需要6块才能够,而4Gb的光纤卡,3-4块就够了。2、IOPS
决定IOPS的主要取决与阵列的算法,cache命中率,以及磁盘个数。阵列的算法因为不同的阵列不同而不同,如我们最近遇到在hds usp上面,可能因为ldev(lun)存在队列或者资源限制,而单个ldev的iops就上不去,所以,在使用这个存储之前,有必要了解这个存储的一些 算法规则与限制。 cache的命中率取决于数据的分布,cache size的大小,数据访问的规则,以及cache的算法,如果完整的讨论下来,这里将变得很复杂,可以有一天好讨论了。我这里只强调一个cache的命中率,如果一个阵列,读cache的命中率越 高越 好,一般表示它可以支持更多的IOPS,为什么这么说呢?这个就与我们下面要讨论的硬盘IOPS有关系了。 硬盘的限制,每个物理硬盘能处理的IOPS是有限制的,如 10 K rpm 15 K rpm ATA ——— ——— ——— 100 150 50 同样,如果一个阵列有120块15K rpm的光纤硬盘,那么,它能撑的最大IOPS为120*150=18000,这个为硬件限制的理论值,如果超过这个值,硬盘的响应可能会变的非常缓慢而不能正常提供业务。 在raid5与raid10上,读iops没有差别,但是,相同的业务写iops,最终落在磁盘上的iops是有差别的,而我们评估的却正是磁盘的IOPS,如果达到了磁盘的限制,性能肯定是上不去了。 那我们假定一个case,业务的iops是10000,读cache命中率是30%,读iops为60%,写iops为40%,磁盘个数为120,那么分别计算在raid5与raid10的情况下,每个磁盘的iops为多少。 raid5: 单块盘的iops = (10000*(1-0.3)*0.6 + 4 * (10000*0.4))/120 = (4200 + 16000)/120 = 168 这里的10000*(1-0.3)*0.6表示是读的iops,比例是0.6,除掉cache命中,实际只有4200个iops 而4 * (10000*0.4) 表示写的iops,因为每一个写,在raid5中,实际发生了4个io,所以写的iops为16000个 为了考虑raid5在写操作的时候,那2个读操作也可能发生命中,所以更精确的计算为: 单块盘的iops = (10000*(1-0.3)*0.6 + 2 * (10000*0.4)*(1-0.3) + 2 * (10000*0.4))/120 = (4200 + 5600 + 8000)/120 = 148 计算出来单个盘的iops为148个,基本达到磁盘极限 raid10 单块盘的iops = (10000*(1-0.3)*0.6 + 2 * (10000*0.4))/120 = (4200 + 8000)/120 = 102 可以看到,因为raid10对于一个写操作,只发生2次io,所以,同样的压力,同样的磁盘,每个盘的iops只有102个,还远远低于磁盘的极限iops。 在一个实际的case中,一个恢复压力很大的standby(这里主要是写,而且是小io的 写),采用了raid5的方案,发现性能很差,通过分析,每个磁盘的iops在高峰时期,快达到200了,导致响应速度巨慢无比。后来改造成 raid10,就避免了这个性能问题,每个磁盘的iops降到100左右。
SNT ST-2250RU3 5块2.5寸 sata2 9.5mm厚度 1TB*5 max Raid USB3.0 全铝 防撞击
http://www.snt-chubao.com/showart.asp?parentid=3&class_id=623&artid=8395
http://www.gtobal.com/sell/detail-1069502902.html#gTab_detailsId_3
东莞市储宝贸易有限公司
联系人:贺荣 (经理)
联系电话:86-0769-86250303
手机:13713071089
主页:http://superbabies1992.cn.gtobal.com
联系地址:广东省东莞市塘厦骏景花园
Hydra 800+ / 2FireWire 800(1394b)+FireWire 400(1394a)+USB 2.0 / 4块2.5寸硬盘阵列盒
http://diy.pconline.com.cn/power/hq/fj/0906/1683021_1.html
SOHORAID MR2-WBS2 / usb3.0+fireware800 / 2块2.5硬盘阵列盒
http://www.shooting.com.hk/product_details.php?brand_id=54&pcatg_id=&pID=724
Century世特力CRIB25EU2) / USB2.0+eSATA / 4块2.5寸硬盘阵列盒 / USB2.0=60MB/s,eSATA=375MB/s
http://www.it.com.cn/diy/others/review/zb/2010/10/28/08/908283_1.html
http://detail.zol.com.cn/storage_box/index282090.shtml
http://detail.zol.com.cn/283/282090/param.shtml
总体来说,CRIB25EU2 750G+750G组成RAID0阵列后,读取性能较单盘模式下提升了约60%,而写入性能则增长了约40%左右,不过HD TACH的表现有些奇怪,RAID0模式下还略低于单盘,虽然怀疑是HD TACH的自身问题,但是零散小文件拷贝中再次出现了单盘超过RAID0的情况,多次尝试依然如此,因此很难确定问题所在,也许是RAID算法的问题也说 不定。

http://www.mml.com.tw/topic/index?id=142188
| 外接界面 | 1Byte = 8bit Mbps (bit/s) | 1Byte = 8bit MBps (Byte/s) | 接口技术 |
| USB1.1 | 12 | 1.5 | |
| USB2.0 | 480 | 理论60MB/s 实际<30MB/s | |
| USB3.0 | 5Gbps | 理论640MB/s实际120MB/s | |
| 1394a(FireWire400) | 400 | 50 | |
| 1394b(FireWire800) | 800 | 理论100MB/s实际<70MB/s | |
| eSATA 1.5Gb/s | 1200 | 理论150MB/s实际79MB/s | |
| eSATA 3.0Gb/s | 2400 | 300 | |
| SATA1 1.5Gb/s | 150 | ||
| SATA2 3.0Gb/s | 理论300MB/s实际140MB/s | NCQ、Port Multiplier、Staggered Spin-up、Hot Plug | |
| SATA3 6.0Gb/s | 600MB/s (实际值) | ||
| Thunderbolt | 10Gbps | PCI Express x4 + DisplayPort | |
iostat
# iostat 1 5
如果%util 接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果idle小于70%,I/O的压力就比较大了,说明读取进程中有较多的wait。
LSI产品raid阵列卡 , 磁盘创建方式 disk ->pv -> vg -> lv
2015 年前机器磁盘环境为raid 5 ,8块盘
2015 年后机器磁盘环境为raid 50,16块盘,raid50 = raid5 + raid5 ,OpenStack环境
如何让linux服务器磁盘io性能翻倍
http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=24347291&id=4563042
PC用户往往觉得“磁盘挺快的,哥拷1GB的片子也就2分钟嘛”
做服务器的兄弟可能会觉得“磁盘怎么这么慢,才1MB/s就把io跑满了,他喵的磁盘比网速还慢,害我的服务器卡死了”
为什么有时候服务器的磁盘io会这么慢呢?
我们用的磁盘(IDE/SATA/SCSI等)还有一个名字,叫做“机械磁盘”。
从名字可以看出,磁盘并不是一个纯粹的“电子产品”,它在很大程度上需要依靠一个“机械臂”来读写数据,这个机械臂就是导致磁盘io慢的罪魁祸首。
如上图所示,磁盘中的数据存储在圆形的盘片上,通过磁头读写盘片上的数据,磁头则安装在一个机械臂(磁头臂)上。
当我们需要读写某个文件时,内核会将文件映射到一个线性磁盘地址(LBA)。磁盘首先根据LBA找到盘片上的一个点,然后让磁头对准这个点,再通过磁头将数据读取出来。
读取文件耗费的时间分为两部分:
1 让磁头定位到指定位置的时间(平均寻道时间)
2 磁头从盘片上读出数据的时间(传输时间)
如何让磁头定位到指定位置:
这涉及两个方向的移动。磁头会在机械臂的控制下向圆心移动(或远离圆心);同时盘片会旋转。
磁头移动到合适位置需要的时间叫平均寻道时间,一般在10毫秒左右。盘片旋转到指定位置需要的时间叫平均潜伏时间,对7200转磁盘来说大概是4毫秒。
1秒钟 ÷(4毫秒 + 10毫秒) = 71
这表示什么?
这表示磁盘平均每秒只能定位71次!!!
简单来说,可以理解成磁盘每秒只能读取71个文件(实际情况略有偏差,请参考下面第二章)
假如服务器存储了大量小文件,每个文件10KB,按照每秒71次的磁头定位速度,每秒读文件就只能达到710KB/s的速度。
那为什么PC拷片子的速度这么快呢?
当我们拷片子时,磁头基本不需要移动,主要耗时在于通过盘片的旋转,让磁头从盘片上读出数据。
盘片的旋转速度远远高于磁头移动速度。读取连续文件的速度一般能达到100MB/s以上,所以PC拷片子的时候速度非常快。
文件系统对io性能的损耗
磁盘平均每秒能寻道70次,但是实际读写文件可能达不到70个,因为文件内也是有碎片的,这时读一个文件就需要很多次寻道。
我们可以把磁盘空间想象成一个巨大的内存,LBA(线性磁盘地址)就相当于内存地址。文件系统需要为每个文件分配地址,就像malloc要为每个内存块分配内存一样。
磁盘空间分配有两个特征,会导致文件系统中容易产生碎片:
1 当我们创建文件时,文件是空的,随着我们写入数据,文件变得越来越大。所以磁盘空间分配不是一次性完成的,而是随着文件写入而逐渐追加分配。
2 文件不需要在磁盘空间中连续存储,允许切割成多个碎片。但是不连续的代价是读取时需要多次寻道,性能大幅下降。
windows文件系统一直以大量的文件碎片而闻名;linux主流文件系统的碎片则相对少很多。
有不少朋友认为linux没有文件碎片,这其实是一个误解。
linux主流文件系统相对于windows文件系统,有一个巨大的改进,极大的减少了文件碎片,但这不等于没有文件碎片:
windows在分配LBA时会尽量连续分配:
假设文件A占用了地址0-99KB,然后文件B申请8KB磁盘空间时会占用100-108KB。这样当文件A再次申请磁盘空间时就会产生碎片。
linux在分配LBA时会考虑预留地址:
假设文件A占用了地址0-99KB,然后文件B申请8KB磁盘空间时会隔一段地址,例如可能会占用1GB-1GB+8KB。这样当文件A再次申请磁盘空间时就能保证连续了。
当磁盘有较多剩余空间时,linux主流文件系统能够有效避免文件碎片。对于PC和部分服务器来说,可以认为linux主流文件系统是没有碎片的。
但是对于磁盘空间经常占的比较满,又需要不停的删除-写入文件的linux服务器来说,文件碎片会让磁盘io性能下降数倍。
想深入了解的朋友可以参考:
ext4的碎片整理器设计原理:http://jsmylinux.no-ip.org/applications/using-e4defrag/
xfs文件系统作者讲解如何提升文件系统性能并减少碎片的产生:http://oss.sgi.com/projects/xfs/papers/xfs_usenix/index.html
内核预读取的基本原理:http://os.51cto.com/art/200711/60574.htm
也可以直接看内核代码中的ext4_ext_map_block函数
end