partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,分区函数一般与排名函数一起使用。
准备测试数据:
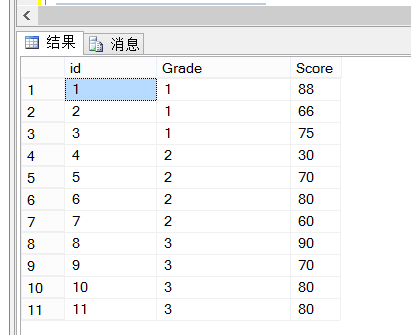
create table Student --学生成绩表 ( id int, --主键 Grade int, --班级 Score int --分数 ) go insert into Student values(1,1,88) insert into Student values(2,1,66) insert into Student values(3,1,75) insert into Student values(4,2,30) insert into Student values(5,2,70) insert into Student values(6,2,80) insert into Student values(7,2,60) insert into Student values(8,3,90) insert into Student values(9,3,70) insert into Student values(10,3,80) insert into Student values(11,3,80)
一、分区函数Partition By的与row_number()的用法
1、不分班按学生成绩排名
select *,row_number() over(order by Score desc) as Sequence from Student
执行结果:

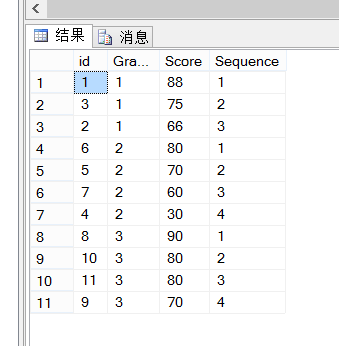
2、分班后按学生成绩排名
select *,row_number() over(partition by Grade order by Score desc) as Sequence from Student
执行结果:
3、获取每个班的前1(几)名
select * from ( select *,row_number() over(partition by Grade order by Score desc) as Sequence from Student )T where T.Sequence<=1
执行结果:

二、分区函数Partition By与排序rank()的用法
1、分班后按学生成绩排名 该语句是对分数相同的记录进行了同一排名,例如:两个80分的并列第2名,第4名就没有了
select *,rank() over(partition by Grade order by Score desc) as Sequence from Student
执行结果:

2、获取每个班的前2(几)名 该语句是对分数相同的记录进行了同一排名,例如:两个80分的并列第2名,第4名就没有了
select * from ( select *,rank() over(partition by Grade order by Score desc) as Sequence from Student )T where T.Sequence<=2
执行结果:
