引自 http://kb.cnblogs.com/page/508336/
编译器的工作过程
码要运行,必须先转成二进制的机器码。这是编译器的任务。
比如,下面这段源码(假定文件名叫 test.c)

要先用编译器处理一下,才能运行。
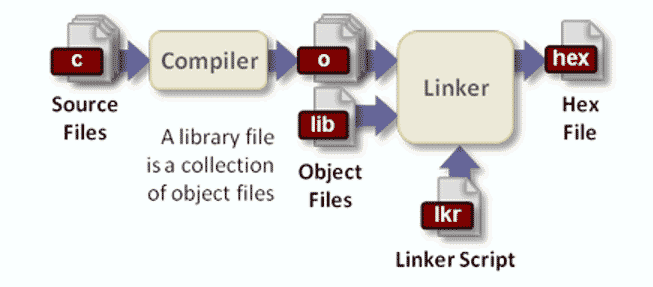
对于复杂的项目,编译器过程还必须分成三步。

这些命令到底是干什么的,好多书本就直接说是这样用,根本没有说原理。
这里主要是针对 gcc 编译器
第一步 配置 (configure)
编译器在开始工作之前,需要知道当前的系统环境,比如标准库在哪里,软件的安装位置在哪里,需要安装哪些组件等等。这是因为不同计算机的系统环境不一样,通过指定编译参数,编译器就可以灵活适应环境,编译出各种环境都能运行的机器码。这个确定编译参数的步骤,就叫做“配置”(configure).
这些配置信息保存在一个配置文件之中,约定俗成是一个叫做configure的脚本文件。通常它是由autoconf工具生成的。编译器通过运行这个脚本,获知编译参数。
configure 脚本已经尽量考虑到不同系统的差异,并且对各种编译参数给出了默认值。如果用户的系统环境比较特别,或者有一些特定的需求,就需要手动向 configure 脚本提供编译参数。

上面代码是 php 源码的一种编译配置,用户指定安装后的文件保存在 www 目录,并且编译时加入 mysql 模块的支持.
第二步 确定标准库和头文件的位置
源码肯定会用到标准库函数(standard library)和头文件(header)。它们可以存放在系统的任意目录中,编译器实际上没办法自动检测它们的位置,只有通过配置文件才能知道。
编译的第二步,就是从配置文件中知道标准库和头文件的位置。一般来说,配置文件会给出一个清单,列出几个具体的目录。等到编译时,编译器就按顺序到这几个目录中寻找目标。
第三步 确定依赖关系
对于大型项目来说,源码文件之间往往存在依赖关系,编译器需要确定编译的先后顺序。假定A文件依赖于B文件,编译器应该保证做到下面两点。
1.只有在B文件编译完成后,才开始编译A文件
2.当B文件发生变化时,A文件会被重新编译。
编译顺序保存在一个叫 makefile 的文件中,里面列出哪个文件先编译,哪个文件后编译。而 makefile 文件由 configure 脚本运行生成,这就是为什么编译时 configure 必须首先运行的原因.
在确定依赖关系的同时,编译器也确定了,编译时会用到哪些头文件。
第四步 头文件的预编译 (precompilation)
不同的源码文件,可能引用同一个头文件(比如 stdio.h).编译的时候,头文件也必须一起编译。为了节省时间,编译器会在编译源码之前,先编译头文件。这保证了头文件只需要编译一次,不必每次用到的时候,都重新编译了。
不过,并不是头文件的所有内容,都会被预编译。用来声明宏的 #define 命令,就不会被预编译.
第五步 预处理 (preprocessing)
预编译完成后,编译器就开始替换源码中的 bash 的头文件和宏。以本文开头的那段源码为例,这包含头文件 stdio.h,替换后的样子如下:
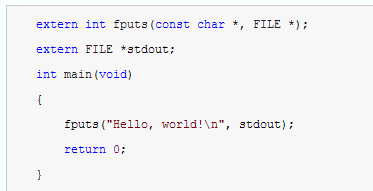
为了便于阅读,上面的代码只截取了头文件中与源码相关的那部分,即 fputs和FILE 的声明,省略了 stdio.h的其它部分。另外,上面代码的头文件没有经过预编译,而实际上,插入源码的是预编译后的结果。编译器在这一步还会移除注释。
这一步称为“预处理”(Preprocessing), 因为完成之后,就要开始真正的处理了。
第六步 编译 (compilation)
预处理之后,编译器就开始生成机器码。对于某些编译器来说,还存在一个中间步骤,会先把源码转为汇编码(assembly),然后再把汇编码转为机器码.
汇编码如下:


这种转码后的文件称为对象文件 (object file).
第七步 连接(Linking)
对象文件还不能运行,必须进一步转成可执行的文件。如果你仔细看上一步的转码结果,会发现其中引用的 stdout 函数和 fwrite 函数。也就是说,程序要正常运行,除了上面的代码以外,还必须有 stdout 和 fwrite 这两个函数的代码,它们是由C语言的标准库提供.
编译器的下一步工作,就是把外部的函数代码(通常是后缀名为 .lib 和 .a 的文件中),添加到可执行文件中。这就叫做连接(linking).这种通过拷贝,将外部函数库添加到可执行文件的方式,叫做静态连接(static linking), 后面会提到还有动态连接(dynamic linking).
make 命令的作用,就是从第四步头文件预编译开始,一直到做完这一步。
第八步 安装(installation)
上一步的连接是在内存中进行的,即编译器在内存中生成了可执行的文件,下一步,必须将可执行文件保存到用户事先指定的安装目录。表面上,这一步很简单,就是将可执行文件(连带相关的数据文件)拷贝过去就行了。但实际上,这一步还必须完成创建目录,保存文件,设置权限等步骤。这整个的保存过程就称为“安装”(installation).
第九步 操作系统连接
可执行文件安装后,必须以某种方式通知操作系统,让其知道可以使用这个过程了。比如,我们安装了一个文件阅读程序,往往希望双击 .txt 文件,该程序就会自动运行。这就要求在操作系统中,登记这个程序的元数据:文件名,文件描述,关联后缀名等等。linux 系统中,这些信息通常保存在 /usr/share/applications 目录下的 .desktop 文件中,另外,在 windows 操作系统中,还需要在 start 启动菜单中,建立一个快捷方式.这些事情就叫做“操作系统连接”.make install 命令,就是完成“安装”和“操作系统连接”这两步.
第十步 生成安装包
写到这里,源码编译的整个过程就基本完成了。可以根据要求生成安装包。这就要求编译器还必须有生成安装包的功能,通常是将可执行文件(连带相关的数据文件),以某种目录结构,保存成压缩文件包.
第十一步 动态连接(dynamic linking)
正常情况下,到这一步,程序已经可以运行了,至于运行期间(runtime)发生的事情,与编译器一概无关。但是,开发者可以在编译阶段选择可执行文件连接外部函数库的方式,到底是静态连接(编译时连接),还是动态连接(运行时连接),以下作说明:
静态连接就是把外部函数库,拷贝到可执行文件中。这样做的好处是,适用范围比较广,不用担心用户机器缺少某个库文件,缺点是安装包会比较大,而且多个应用程序之间,无法共享库文件。动态连接正好相反,外部函数库不进入安装包,只在运行时动态引用。好处是安装包会比较小,多个应用程序可以共享库文件,缺点是用户必须事先安装好库文件,而且版本和安装位置都必须符合要求,否则就不能正常运行,现实中,大部分软采用动态连接,共享库文件。这种动态共享的库文件,linux 平台后缀为.so的文件,windows 平台是 .dll 文件,mac平台是 .dylib文件