
安装 pip3 install pandas
pip3 install openpyxl
创建数据表和文件
from PyQt5.QtWidgets import QApplication,QWidget import sys import pandas as pd class win(QWidget): def __init__(self): super().__init__() self.resize(500,500) self.setWindowTitle('Excel学习') #df=pd.DataFrame() #创建数据表--空数据表 df = pd.DataFrame({'姓名':['张三','李四','王五'],'物理':[56,98,45]}) # 创建数据表 df.to_excel('D:/ss/ss.xlsx') #把数据表保存为xlsx文件 if __name__=='__main__': app=QApplication(sys.argv) w=win() w.show() sys.exit(app.exec_())
此时在指定目录中生成一个xlsx文件
打开后

第一列是pandas自动产生的索引列
自定义索引列
df = pd.DataFrame({'ID':[1,2,3],'姓名':['张三','李四','王五'],'物理':[56,98,45]})
df=df.set_index('ID') #设置索引列--这样不会单独产生索引列
df.to_excel('D:/ss/ss.xlsx')
df.set_index('ID',inplace=True) #设置索引列--这样不会单独产生索引列
读取文件
df = pd.read_excel('D:/ss/ss.xlsx',header=0,index_col='ID') #读取文件 #参数header 第几行是标题栏---有的文件第一行不是标题栏--0开始--默认0 #如果是空行能自动识别 #如果没有标题栏 header=None #参数index_col 指明索引列,这样pandas不会自动产生索引列
df = pd.read_excel('D:/ss/ss.xlsx',header=3,usecols='C:H',dtype={'学号':str,'日期':str,'字符串':str})
#skiprows=3 跳过最上边的n行
#usecols='C:H' 读取C到H列
#dtype={'学号':str} 指定某列的数据类型,不能是int--float64不能转成int
df1 = pd.read_excel('D:/ss/ss.xlsx',index_col='ID',sheet_name='Sheet1') #读取指定表格--默认第一张
【可以连续使用这条语句,但是后面的会覆盖掉前面的数据】
返回工作簿中的所有表格
import openpyxl
wb = openpyxl.load_workbook('D:ssss.xlsx') #打开工作簿
sheets = wb.sheetnames # 获取wb中所有的表格
#返回值:列表--['Sheet1', 'Sheet2']
print(sheets)
wb.close()
返回总行数和总列数
s=df.shape #返回总行数和总列数---(3, 3)
#不包括标题行
返回所有列标题
s=df.columns #返回所有列标题 #Index(['ID', '姓名', '物理'], dtype='object')
返回头n行数据或末尾n行数据
s=df.head(4) #返回头n行数据---观察表格结构--默认5行 s = df.tail(4) #返回末尾n行数据
添加或修改标题
df.columns=['学号','姓名','数学'] #添加或修改标题
创建序列
s1=pd.Series() #创建一个空序列 #序列的三个属性:data(现在不用了)、index、name d={'x':100,'y':200,'z':300} s1 = pd.Series(d) #创建一个序列---字典转化成序列 #把字典的keys转化为index,把values转化为data L1=[10,20,30] L2=['x','y','z'] s1 = pd.Series(L1,index=L2) #把列表转化为序列 #注意:在pandas里行和列都是一个序列
把序列加到数据表
import pandas as pd s1 = pd.Series([1,2,3],index=[1,2,3],name='A') #创建序列 #index相当于行号 name相当于列标 s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name='B') s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name='C') df=pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3}) #把序列以列形式加到数据表 print(df)

df=pd.DataFrame([s1,s2,s3]) #index做为列,name做为行

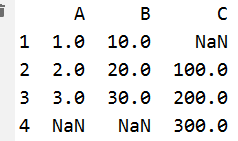
import pandas as pd s1 = pd.Series([1,2,3],index=[1,2,3],name='A') s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name='B') s3 = pd.Series([100, 200, 300], index=[2, 3,4], name='C') df=pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3}) print(df) #index不同时取并集,空位子用NaN
返回指定列数据的序列(Series)
s=df['学号'] #返回指定列数据的序列(Series)
给指定单元格赋值
df['学号'].at[0]=1 #给指定单元格赋值
df.at[1,'学号']=2 #给指定单元格赋值
计算公式
df['总分']=df['物理']+df['数学'] #总分列=物理列+数学列
import pandas as pd def add(x): return x+10 df = pd.read_excel('D:/ss/ss.xlsx',index_col='ID') df['总分']=df['物理'].apply(add) #把df['物理']中的每个元素做为add参数进行计算
排序
df.sort_values(by='物理',inplace=True,ascending=False) #排序--根据数据排序 #by='物理'--排序的列 #inplace=True---在原数据表排序,不生成新数据表 #ascending=False 降序;ascending=True(默认) 升序
df.sort_values(by=['合格','物理'],inplace=True,ascending=[False,True]) #多重排序--根据数据排序
筛选
def saixuan(x):
s=60<=x<=100
return s
df=df.loc[df['物理'].apply(saixuan)] #筛选
#参数为 True的行留下,false的行放弃
柱状图
import pandas as pd import matplotlib.pyplot as plt #2D制图库 #允许显示中文 plt.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei为黑体 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 df = pd.read_excel('D:/ss/ss.xlsx',index_col='ID') df.plot.bar(x='姓名',y='数学',color='r',width=0.2,label="数学成绩",alpha=0.8,title='成绩对比图') #柱状图 #参数1 x轴;参数2 y轴 #color 设置颜色 #width设置条形图的宽度 #alpha设置透明度 #label题注文本 #title图标题 plt.tight_layout() #紧凑型布局---横坐标的文本全部显示 plt.show()
合并数据表
import pandas as pd df1 = pd.read_excel('D:/ss/ss.xlsx',index_col='ID',sheet_name='Sheet1') #读取指定表格--默认第一张 df2 = pd.read_excel('D:/ss/ss.xlsx',index_col='ID',sheet_name='Sheet2') df3=df1.merge(df2,on='ID',how='left') #合并数据表 #df3=pd.merge(df1,df2,on='ID') #把df1和df2两张表的数据进行合并 #on='ID' 根据这列合并 两个表这个列必须有 #有相同名称的列,会自动改名,前面的加_x,后面的加_y #how='outer' 两个表的数据都合并进来 #how='inner' 只合并on='ID'相同的数据----默认 #how='right' 在'inner'的基础上右数据表全部合并进来 #how='left' 在'inner'的基础上左数据表全部合并进来 df3=df3.fillna(0) #把NaN用改成0 # https://www.cnblogs.com/liming19680104/p/10468767.html df3.物理_y=df3.物理_y.astype(int) #数据类型转换 print(df3)
