注1:本文旨在梳理汇总出我们在建模过程中遇到的零碎小问题及解决方案(即当作一份答疑文档),会不定期更新,不断完善, 也欢迎大家提问,我会填写进来。
注2:感谢阅读。为方便您查找想要问题的答案,可以就本页按快捷键Ctrl+F,搜索关键词查找,谢谢。
1. 读写csv文件时,存在新的一列,Unnamed:0?
答:read_csv()时,防止出现,设置参数index_col=0;写入csv文件时,防止出现,设置参数index=False。
2. 日期类型和其他类型互转。
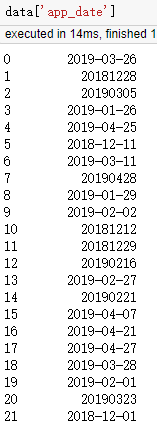
场景1:我们从数据库取得的数据往往不是规整的,如存在‘19900807,1992-04-12’格式,且数据类型为str。
答:引入datetime模块。举例如下:
数据如图:
代码如下,即可解决:
1 data['app_date'] = data['app_date'].apply(lambda x: x.replace('-', '')) # 20190326,20181228 2 data['app_date'] = data['app_date'].apply(lambda x: datetime.datetime.strptime(x,'%Y%m%d')) # %Y%m%d or %Y-%m-%d的选择,取决于x格式带不带'-' 3 data['app_date'] = data['app_date'].apply(lambda x: x.strftime('%y%m')) # %y%m: 1903,1812...; %Y%m:201903, 201812...
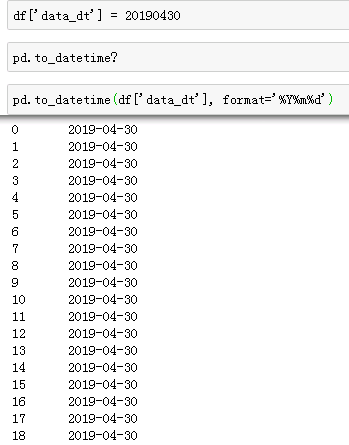
场景2:将int型转为时间格式。pd.to_datetime()
3. (简写)字符串格式化,两种方式
①%


1 for i in range(3): 2 s = '%d' %i 3 print(s) # 依次输出 1, 2, 3
②{}.format()
1 s = '等级考试' 2 y = '-' 3 4 print ('{0:{1}^25}'.format(s, y)) # ----------等级考试-----------
4. 建模时,对于python删除变量的两种小思路
1) 针对dataframe格式的data
data.drop(col, aixs= 1, inplace = True)
#col为想要删除的变量名--列名,方法:DataFrame.drop(self, labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
2) 针对series格式的columns行索引
cols = data.columns cols = cols.drop(col) #有个方法:cols.drop(labels, errors='raise')
5. 我们在预处理及特征工程阶段会分析各变量属于什么类别,都有哪些呢?
我们接触到的统计学变量(variables)可以分为数值变量(Numerical Variables)和分类变量(Categorical Variables)。
数值变量又可以分为---离散型变量(discrete)、连续型变量(continuous)。
分类变量又可以分为---有序分类变量(ordinal)、无序分类变量(nominal)。
6. python读写文件时模式mode选择的异同(多用于open('xx')、to_csv('xx')等地方)
1). r模式
只读模式,该模式下打开的文件如果不存在,将会出错;并且打开后,只能读取,不能写入
2). r+模式
在上述特点上增加一条:可以向文件中写入。
3). w模式
该模式打开的文件如果已经存在,会先清空,如果没有,会新建一个文件,然后只能写入数据,不能读取
4). w+模式
在上述特点上增加一条:可以读取。
5). a模式
该模式打开的文件如果已经存在,不会清空,写入的内容追加到文件尾,但不能读取文件;文件不存在就会新建一个,然后写入。(以追加的方式写入)
6). a+模式
在上述特点上增加一条:可以读取数据。
7). 二进制模式,在上述后面加上b,如'rb',读取二进制文件。
7. 排序取最大(小)值对应的索引,argmin,idxmin,argmax,argmin
numpy分析: numpy 的 ndarray.argmin 的 Series 版
Series分析: argmin=idxmin,argmax=idxmax
DataFrame分析: 没有arg,只有idxmin,idxmax
8. 经常要用到映射方法,apply,applymap,map,定义如下
apply: 使用在DataFrame上,用于对row或者column进行计算; applymap: 用于DataFrame上,是元素级操作(常用); map: 用于series上,是元素级操作。
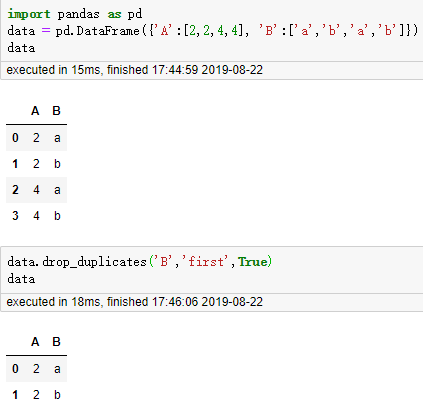
9. 删除特定列的重复行,drop_duplicates()
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
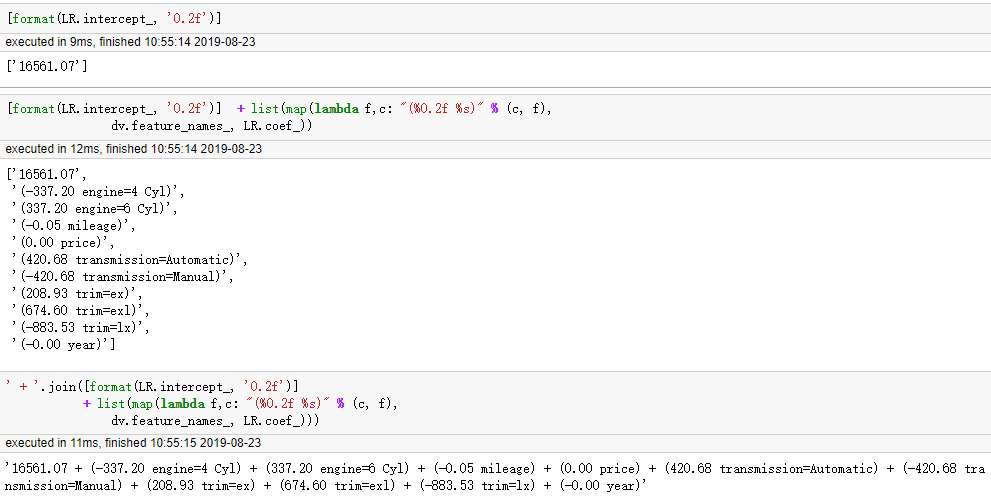
10. 记录一个map,str的join的示例
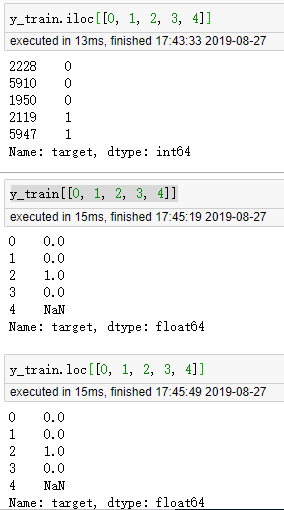
11. DataFrame/Series 索引问题。iloc,loc,直接索引[[]]
(y_train是个Series类型,且我没有reset_index)
12. 把python中的DataFrame中的object对象转换成我们需要的类型,convert
df.infer_objects
13. 去除字符串中指定字符
①python中的strip()可以去除头尾指定字符,基本用法:
ss.strip()参数为空时,默认去除ss字符串中头尾 , , , 空格等字符
ss.lstrip()删除ss字符串开头处的指定字符,ss.rstrip()删除ss结尾处的指定字符
②想要去除中间字符,可以使用replace()函数
基本用法:replace(old, new[, max])
14. DataFrame中某些列值替换,如y值替换为0,1 (两种方法)
①-- np.where()

②-- pandas series map()

15. 关于DataFrame赋值注意事项(空表和有值表赋值的差异)

16.Python读取csv文件时编码报错问题
一,读取csv文件:
train= pd.read_csv(train_path)
1. 如果报错OSError: Initializing from file failed,可尝试的方法有:
train= pd.read_csv(open(train_path))
2. 如果是编码报错,如:UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 38: illegal multibyte sequence
可尝试:
train= pd.read_csv(train_path,encoding='gbk')
这里的encoding可以尝试其他的,如utf-8,gb2312,gb18030,ISO-8859-1,反正各种试,总有一个可以通过。
3. 如果上面这些都不行,还是编码报错,试试下面这方法,应该都会通过:
train= pd.read_csv(open(train_path,encoding='utf-8',errors='ignore'))
这里的encoding选什么就试了。
注:train_path 是你要读取的文件路径。
17.Python的zip用法,及在机器学习处理数据时的应用(打乱数据集有用)
1 # zip用法 2 a = [1,2,3] 3 b = [4,5,6] 4 c = [4,5,6,7,8] 5 zipped = zip(a,b) # 打包为元组的列表。为了减少内存返回了一个对象,可以使用 list() 转换来输出列表 6 # zipped,输出<zip at 0x1c583ff4988> 7 list(zip(a,c)) # # 元素个数与最短的列表一致,[(1, 4), (2, 5), (3, 6)] 8 a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式 9 # list(a1),[1, 2, 3],list(a2),[4, 5, 6]
1 # zip在机器学习处理数据方面例子 2 3 import random 4 X = [1, 2, 3, 4, 5, 6] 5 y = [0, 1, 0, 0, 1, 1] 6 zipped_data = list(zip(X, y)) 7 # 将样本和标签一 一对应组合起来,并转换成list类型 方便后续打乱操作 8 # zipped_data 9 random.shuffle(zipped_data) #zipped_data, [(5, 1), (3, 0), (1, 0), (4, 0), (2, 1), (6, 1)] 10 # 使用random模块中的shuffle函数打乱列表,原地操作,没有返回值 11 #zip(*zipped_data) # <zip at 0x1c584b2f388> 12 new_zipped_data = list(map(list, zip(*zipped_data))) # new_zipped_data ,[[5, 3, 1, 4, 2, 6], [1, 0, 0, 0, 1, 1]] 13 # zip(*)反向解压,map()逐项转换类型,list()做最后转换 # a,b = zip(*zipped_data),一样可以输出元素,不过是元组类型,见上面的小栗子 14 15 new_X, new_y = new_zipped_data[0], new_zipped_data[1] 16 # 返回打乱后的新数据 17 18 print('X:',X,' ','y:',y) 19 print('new_X:',new_X, ' ', 'new_y:',new_y)
注:感谢阅读。如果书写风格影响观看体验,还望多多提出来,本人会虚心接受,谢谢