缓存是一种将数据保存在本地,在下一次需要使用它时,无需从数据的源头而是直接本地读取的一种技术。在http中,缓存是非常重要的组成部分。
意义
http 是一种请求->响应的半双工通讯协议,网页的 html 文档以及内部的每一张图片、javascript 脚本文本、css 样式文件等资源都需要向服务器发出请求,然后得到所需资源的响应。
如果没有浏览器缓存

从向服务器发起 TCP 连接请求,到服务器磁盘 IO,计算到响应传输整个过程,对网络带宽,服务器性能都是不小的考验。而一个页面往往会有少则十几,多则几十上百的请求,如果每一个资源都从服务端获取,在并发的情况下会给服务器带来很大的压力。

加入缓存后,如果客户端没有资源,会从服务端获取,取得资源后同时存在本地。下一次请求时如果有有效缓存则取缓存,由于不会向服务器发起请求,可以减少服务器的压力,同时从本地读取,不会占用网络带宽,速度也是极快的。
那么 HTTP 协议是怎么控制缓存的呢?
缓存前提
资源标志
浏览器会把请求的类型Method(通常来说我们只缓存get的请求)和URI完整地址作为一个资源的标志。
例如下面这些浏览器都会认为是不同资源,后者并不会匹配前者的缓存。
https://xxxx/a.js和http://xxxx/a.jshttp://xxxx/a.js和http://yyyy/a.jshttp://xxxx/a.js?v=1和http://xxxx/a.jshttp://xxxx/a.js?v=1和http://xxxx/a.js?v=2
当然上面任意一个请求,如果采取不同的Method获取响应,那么也会视为不同的资源。
条件
并不是所有请求都需要缓存,例如提交一个表单,缓存这种请求返回的数据显然是没有意义的。一般来说,只有这些情况才需要采取缓存。
- 类型为
get响应的状态码为 200 的请求,即成功获取数据的请求,例如文档,图片,js 文件等。 - 永久重定向: 响应状态码:301。
- 错误响应: 响应状态码:404 的一个页面。
- 不完全的响应: 响应状态码 206,只返回局部的信息。
测试
我们建一个最简单的 nodejs web 服务来对缓存进行试验。
1 | - app.js // nodejs web服务 |
1 |
|
1 | // app.js |
测试环境:Chrome 76
缓存控制
浏览器对缓存的控制主要是通过 Http 请求和响应的一些特定头部来实现的。
在浏览器环境下,通常我们不需要在请求中配置缓存头,因为浏览器会根据 Http 协议的规范自动进行设置。缓存的配置更多是依赖于服务端的响应。
Cache-Control
Cache-Control顾名思义就是缓存控制,请求头和响应头都支持这个属性。它有以下这些值
no-store
浏览器不会缓存服务器返回的任何内容,也就是说每一次请求必然是重新从服务器获取,相当于禁用了缓存。
1 | // ... |

每次浏览器都会发现,index.js是从服务端重新拉取的。
即使设置了 Etag,浏览器也会忽略,也不会发送
If-None-Match,后面我们会讲到。
no-cache
no-cache并不是不存储和读取缓存,而是有条件的读取缓存,和no-store纯粹的不存缓存还是有很大区别的。此方式下,每次有请求发出时,缓存会将此请求发到服务器(该请求应该会带有与本地缓存相关的验证字段,如Etag),服务器端会验证请求中所描述的缓存是否过期,若未过期则返回 304,这时缓存才会使用本地缓存副本。
具体细节后续和 Etag 一起说
max-age=<seconds>
max-age 用于设置缓存的有效时间,单位是秒。
如我们设置缓存有效时间为 10 秒。
1 | // ... |
当我们在 10 秒内重复刷新页面,会看到如下结果

max-age只是有效时间长,也就是说它需要有一个时间作为起始时间。即有效时间+起始时间=过期时间,而这个起始时间是响应头内的Date字段
默认Date是 nodejs 服务自动设置的,我们魔改一下来测试对缓存的影响。
1 | res.setHeader('Cache-Control', 'max-age=10'); |

设置后会发现浏览器将始终从服务器获取,不会读取缓存。
s-maxage
和max-age类似,但是仅适用于共享缓存(比如各个代理),私有缓存会忽略它。
max-stale
表示设置的max-age到期后,客户端能接受过期缓存的最长时间,单位也是秒。这个是请求头上设置的,响应头设置此属性无效。
假设有一台代理缓存服务器,某个资源在10月1号设置了缓存,过期时间10月3日(3天)。后续请求会有以下情况
- 请求头设置了
max-age为3天,max-stale没设置。那么过期时间则为10月4日,由于缓存服务器的过期时间更早,所以仍然是10月3日过期。 - 请求头设置了
max-age为1天,max-stale没设置。那么过期时间则为10月2日,由于早于缓存服务器的过期时间,所以在10月2日以后请求会重新验证。 - 请求头设置了
max-age为3天,max-stale为2天。那么过期时间则为10月4日,过期有效期为10月5日,此时缓存服务器会取更小的时间10月4号为过期时间。 - 请求头设置了
max-age为5天,max-stale为2天。那么过期时间则为10月6日,过期有效期为10月5日,此时缓存服务器会取更小的时间10月5号为过期时间。
代理缓存服务器常常会处理请求头中的
Cache-Control。
public
表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容(例如,该响应没有 max-age 指令或 Expires 消息头)。
private
表明响应只能被当前的发起请求的设备缓存,不能作为共享缓存(即中间的 大专栏 理解浏览器缓存代理服务器不能缓存它)。
这个是cache-control未显式设置时的默认值
public 和 private 仅用于告诉代理服务器是否缓存,具体的缓存有效期和校验与此无关。
must-revalidate
缓存过期后,必须向服务器发送验证才能使用后续的响应。
经过我们的测试,max-age设置的时间到期后,浏览器就会发送If-Modified-Since和If-None-Match等校验头部对缓存进行校验。也就是说这个属性可以理解为默认开启的。
proxy-revalidate
与must-revalidate作用相同,但它仅适用于共享缓存(例如代理),并被私有缓存忽略。
分类和组合
按类型我们可以将Cache-Control的值分为以下几种类型
- 可缓存性 public 、private、no-cache、no-store
- 到期 max-age、s-maxage、max-stale、min-fresh
- 重新验证和重新加载 must-revalidate、proxy-revalidate
可以用,号隔开同时设置多个值。
1 | res.setHeader('Cache-Control', 'public, max-age=10'); |
Expires
Expires设置了资源的过期时间(GMT 字符串),超过这个时间了缓存就会过期。
GMT 字符串可以通过 Date.proptotype.toUTCString 方法获取。
Pragma
Pragma是Http1.0用于多种用途一个头,如果在响应中设置成no-cache和cache-control: no-cache效果一样。
Pragma 是HTTP/1.0标准中定义的一个header属性,请求中包含Pragma的效果跟在头信息中定义Cache-Control: no-cache相同,但是HTTP的响应头没有明确定义这个属性的功能,所以它不能拿来完全替代HTTP/1.1中定义的Cache-control头。通常定义Pragma以向后兼容基于HTTP/1.0的客户端。 -MDN
缓存校验
cache-control的验证是在浏览器本地验证的,当缓存超过了max-age设置的时间,却并不能说明这个文件已经在服务器上更新。为了应对这种情况,http 提供了一些的缓存校验方式。
304 状态码
304 Not Modified指当服务器对缓存进行校验后,发现资源没有发生更改返回的状态码,这时服务器不会返回资源,客户端收到此状态码应该从本地取缓存。
Last-Modified 和 If-Modified-Since
Last-Modified代表资源的最后修改时间(GMT 字符串),由服务器设置在响应头中。
If-Modified-Since由客户端在请求资源时设置在请求头中,值为上一次返回头上的Last-Modified。
所以这 2 个是配套使用的,如果服务器响应时设置了Last-Modified,那么下一次客户端请求时就会在响应头上设置If-Modified-Since,服务器可以通过这个时间与当前资源的最后编辑修改时间做对比(常用于静态文件),从而判断是否需要更新。
我们通过 demo 测试
1 | // 已注释其他缓存头 |
这是第一次请求,获取了Etag

这是第二次请求
需要注意的是,如果响应头没有设置cache-control或者expires,那么浏览器会把(Date - Last-Modified) / 10的时间作为缓存的有效时间,相当于设置了cache-control,在有效期内也就不会往服务端发送请求校验了。
我们去掉上面的res.setHeader('Cache-Control', 'no-cache');运行后结果如下
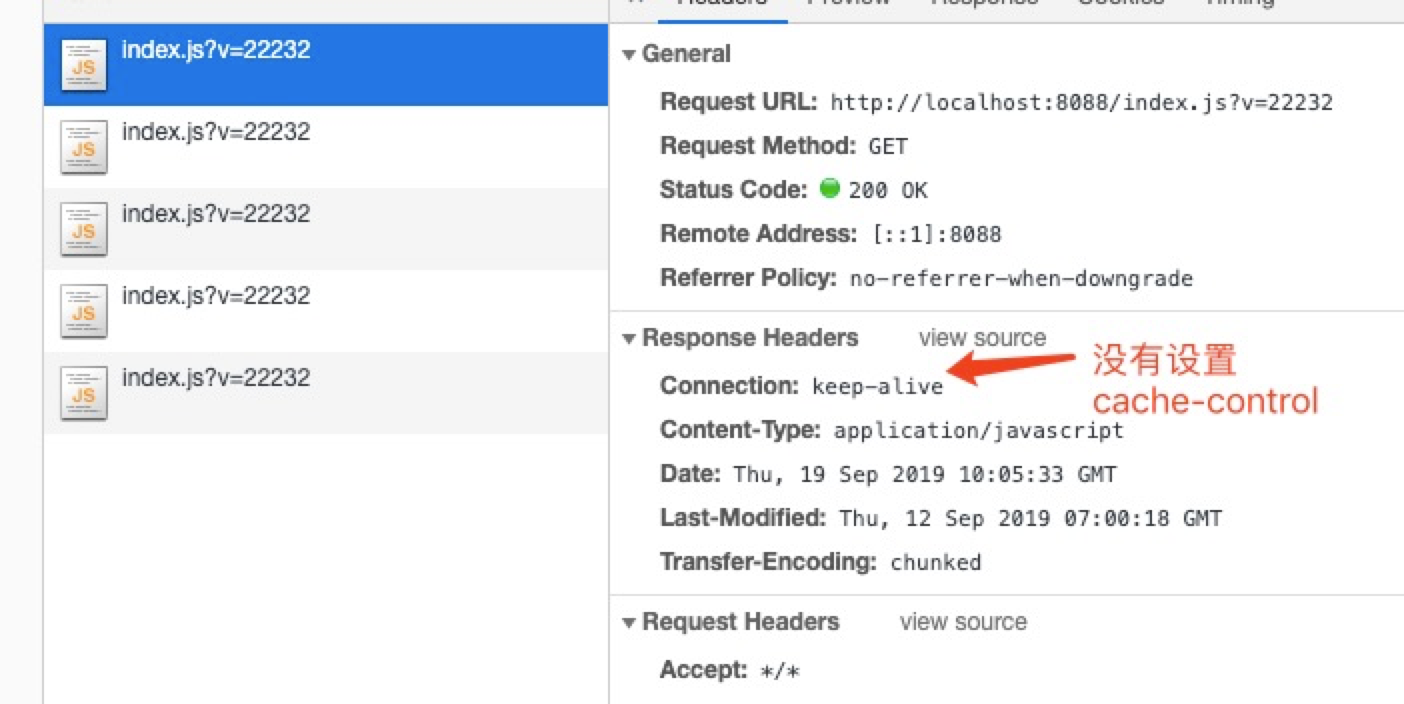
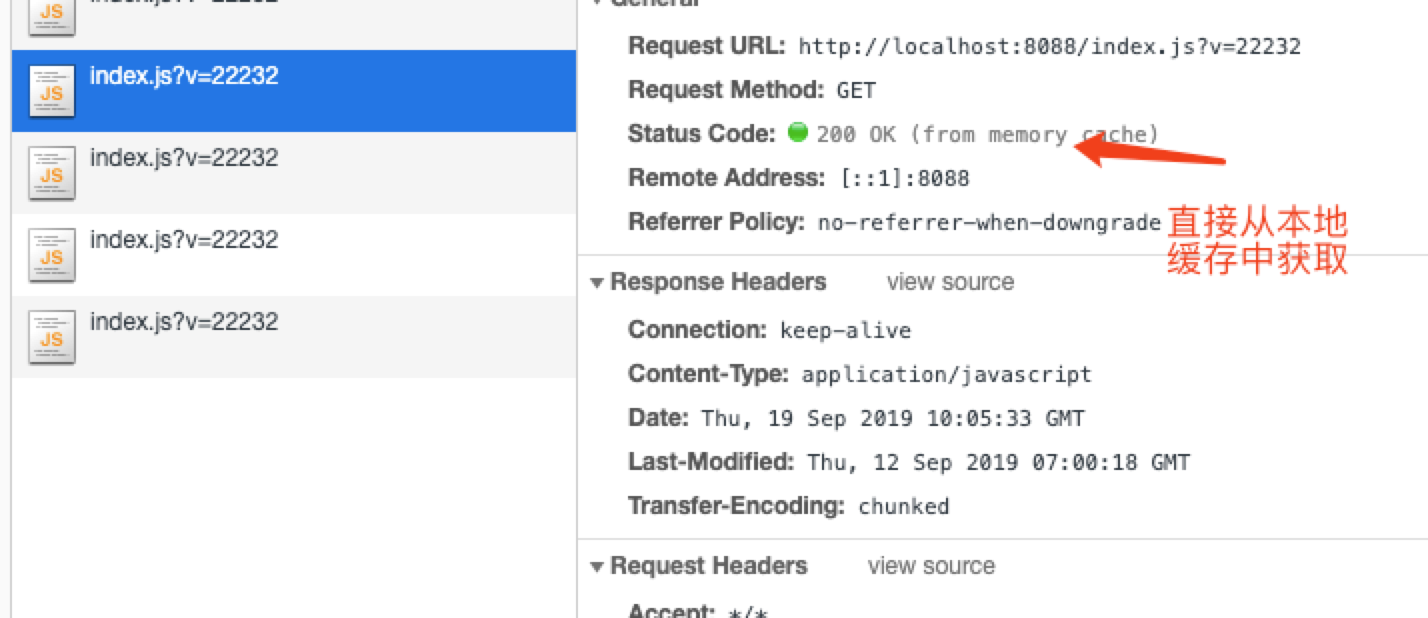
下一次请求
通过比较 Expires 的值和头里面 Date 属性的值来判断是否缓存还有效。如果 max-age 和 expires 属性都没有,找找头里的 Last-Modified 信息。如果有,缓存的寿命就等于头里面 Date 的值减去 Last-Modified 的值除以 10(注:根据 rfc2626 其实也就是乘以 10%) - MDN
Etag
由于 GMT 的精确度只能达到秒级,在同一秒内的修改会导致校验通过。所以如果我们想要获取文件的精确到字节的修改,就需要借助Etag了。
Etag是资源的标记符字符串,可以通过任意的算法生成的不限长度字符串,比如 hash,修改的时间戳,版本号都可以。如果想要精确校验,需要当修改资源的某个字节时,算法能保证生成和之前不同的值。
与Last-Modified类似,客户端在请求时会将上一次资源的Etag值通过If-None-Match头(如果有的话)发送给服务端,服务端通过与重新计算的Etag值做对比,如果相同返回 304,不同返回新的资源。当然如果有变化返回都必须设置新的Etag头部作为下一次请求的值。
经测试,如果即使后续的响应不设置 Etag,只要客户端缓存版本存在 Etag,也会发送
If-None-Match
我们通过 demo 进行测试
1 | // 已注释其他缓存头 |
这是第一次请求,响应设置了Etag

这是第二次请求,请求设置了If-None-Match,响应了 304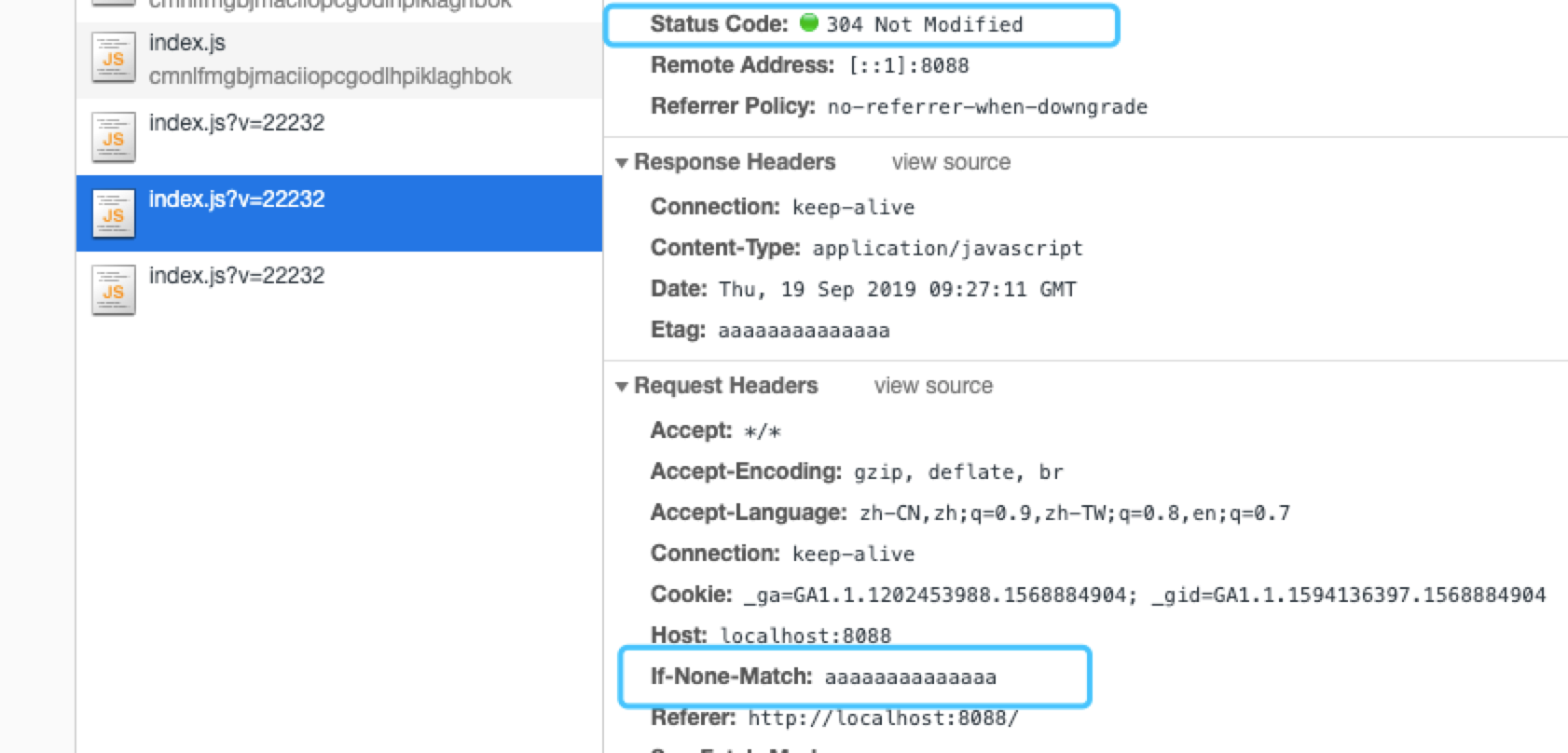
Vary
Vary是一个响应的头部,他的值是请求头的一个名称,用来作为下一次浏览器判断是否使用当前缓存的依据。
例如,某个资源的响应设置了Vary: User-Agent,当下一次发起请求时,如果当前的请求头的User-Agent和上一次缓存资源请求的User-Agent不同,则不会取这一次的缓存。
那这个有什么用处呢?我们都知道资源是通过 url 地址进行标记的,但是客户端的形态是多样的,有移动端,桌面端,手机端等。如果我们需要在同一个 url 针对不同设备返回不同数据,在使用如 CDN 之类的缓存服务器时,如果不设置Vary头的,缓存服务器会将不会按客户端类似区分,这样可能会导致缓存服务器发送给客户端的缓存不正确。
同时设置Vary头也可以帮助搜索引擎更好的缓存不同类似客户端的页面。
测试
我们可以通过 Chrome 调试工具的Toggle Device功能进行测试。
修改代码设置响应的Vary为用户代理字符串(User-Agent),并设置缓存有效期为 1000 秒。
1 | /** Vary */ |
选择设备为 iphone,第一次请求如下。
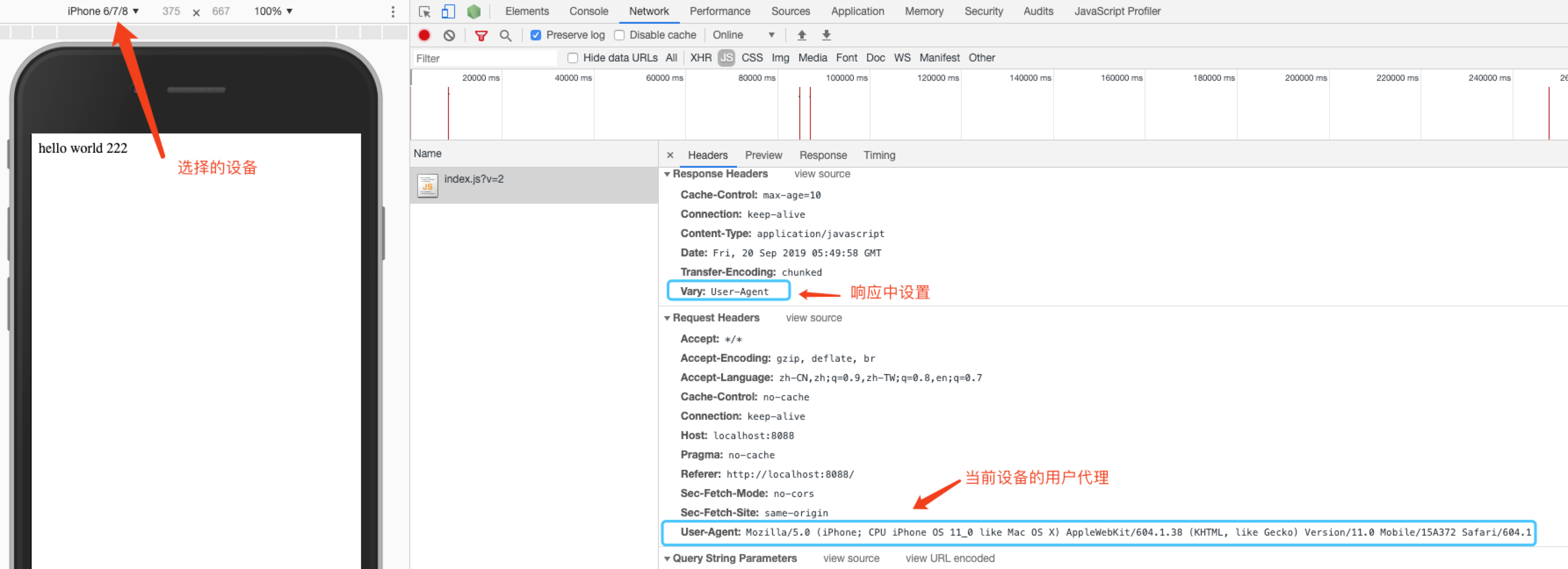
如果我们不切换设备,继续下一次请求,max-age设置的时间未过期,所以取了缓存。

现在我们将设备切换成 ipad,再次请求。由于设备变化导致user-agent变化,浏览器并没有从缓存获取资源,即使现在还远远没到过期时间。
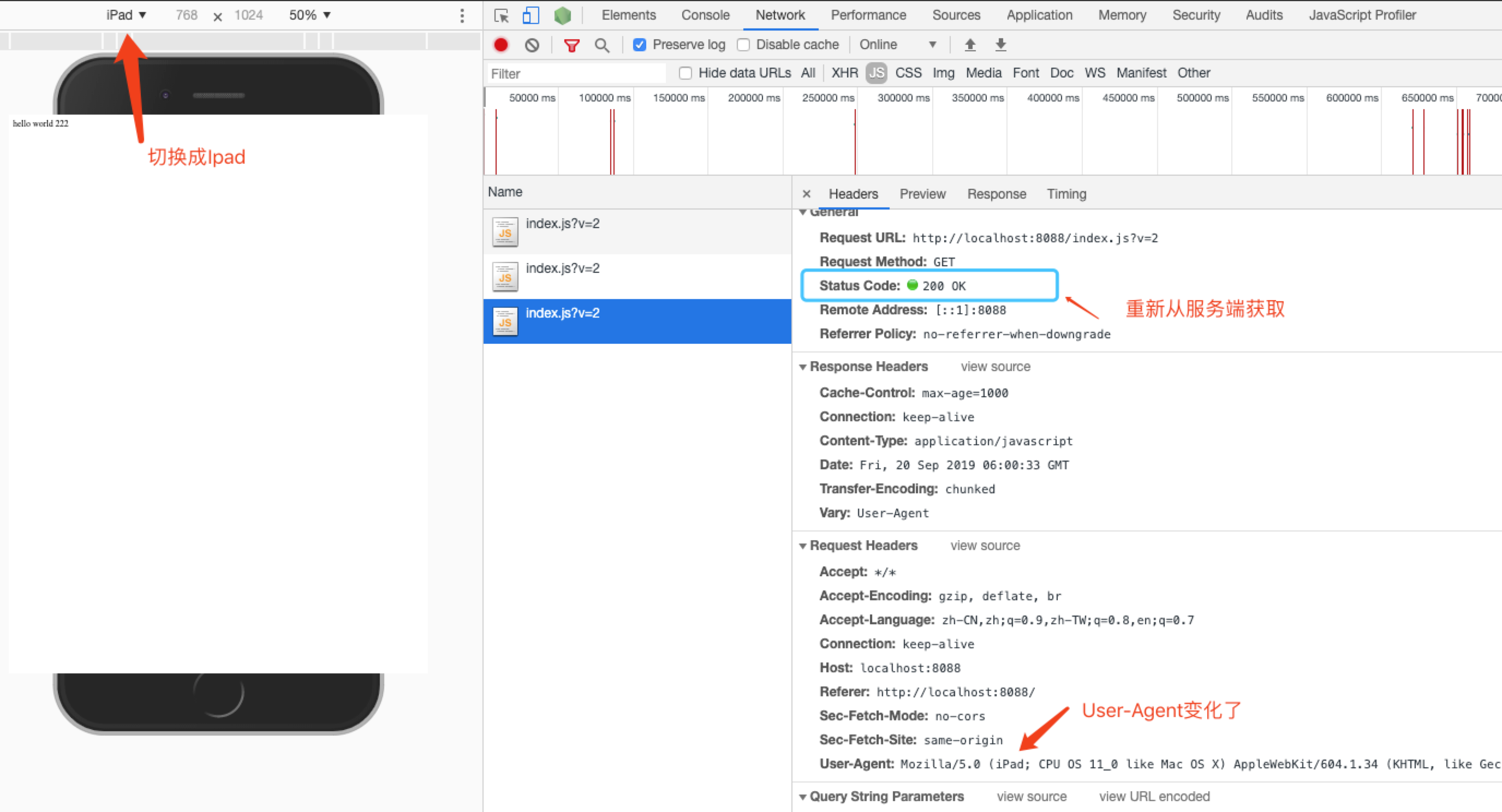
如果 Vary 设置成 *,代理服务器将永远不会缓存,相当于设置 max-age: private。
优先级策略
上面介绍了一堆缓存的控制的方法,但它们并不是各自为政的,如果同时使用,得有个优先级才行。
缓存控制的优先级为
1 | Expires < Cache-Control < Pragma |
当需要缓存需要验证时,校验方式的优先级取决于代码的执行顺序。