简评:JavaScript 是越来越受欢迎了,很多团队都在采用这些语言工作。前端、后端、嵌入式设备等等,都可以看见它的身影。虽然我们知其然,但又知其所以然吗?
大家应该都知道 JavaScript 是单线程的,以及听过 V8 引擎的概念。
这篇文章将会介绍这些概念,并解释 JavaScript 是如何运行的。通过了解这些细节,开发者能更好地编写代码,正确利用其提供的 API。
JavaScript 引擎
比较流行的一个 JavaScript 引擎示例就是 Google 的 V8 引擎。下图是 V8 引擎在 Chrome 和 Node.js 中使用的一个简化视图: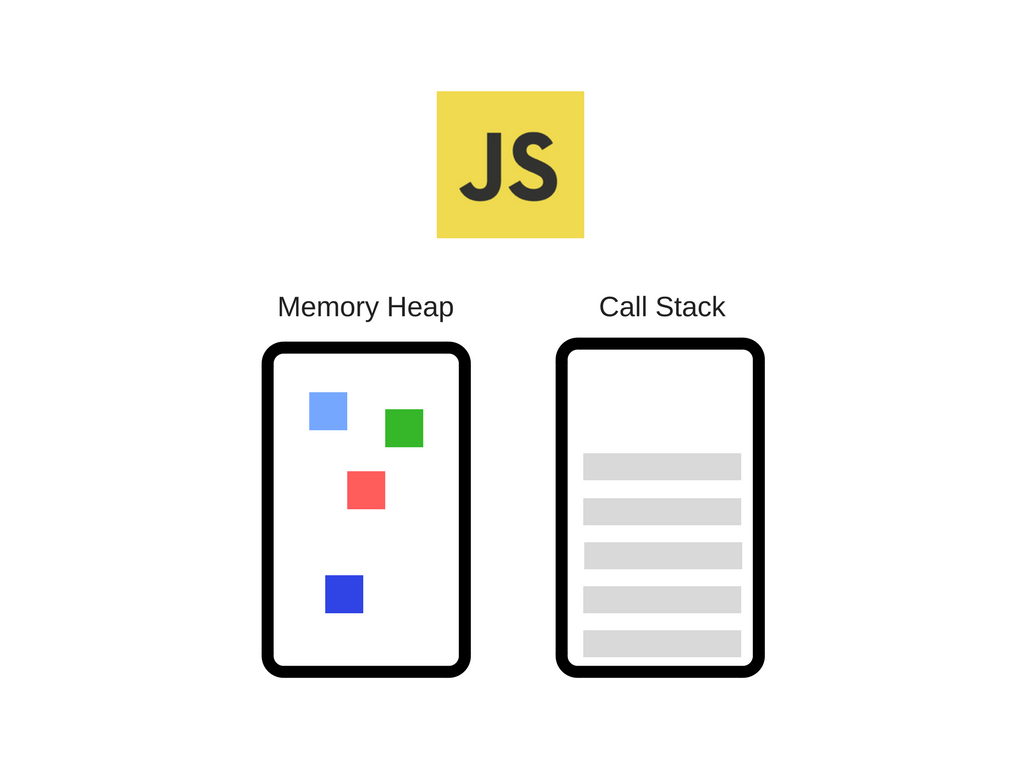
引擎主要由两个组件组成:
- 内存堆(Memory Heap ):这是内存分配的地方
- 调用堆栈(Call Stack):这是程序运行时函数的调用过程
运行
在浏览器中,例如「setTimeout」这样的 API 已经有很多开发者在用了,然后引擎并没有提供这些 API,所以它们从哪里来的呢?
实际情况是这样的: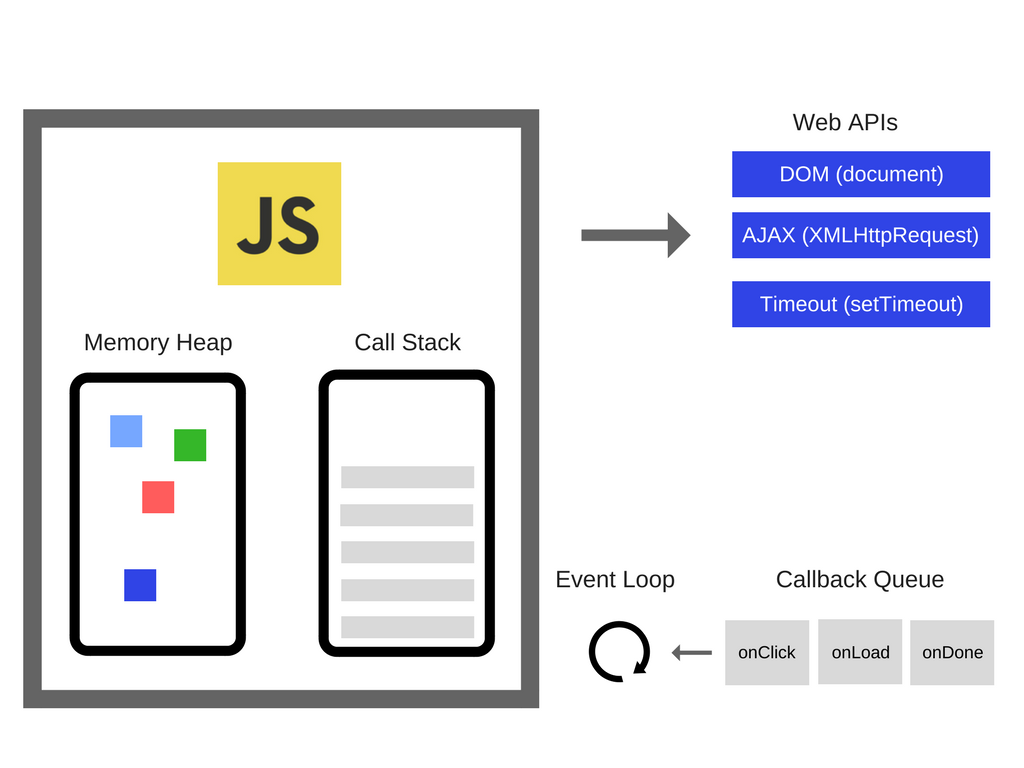
所以,除了引擎之外,还有浏览器提供的 Web API(像 DOM、AJAX、setTimeout 等等)。另外,还有事件循环(event loop)和回调队列(callback queue)。
调用堆栈(Call Stack)
JavaScript 是单线程语言,这意味着它只有一个单一的调用堆栈。因此,它每次只能做一件事。
调用堆栈是一个数据结构,按调用顺序保存所有在运行期被调用的方法。既然是个栈,那么它就满足先入后出的特性。
我们来看一个例子:
1 | function (x, y) { |
当引擎开始执行这段代码时,调用堆栈将为空。然后,就会有以下步骤:
调用堆栈中的每个条目称为堆栈帧(Stack Frame)。当异常发生时,它基本上是调用堆栈的状态。再看看下面这段代码:
1 | function foo() { |
如果这是在 Chrome 中执行(假设此代码位于一个名为 foo.js 的文件中),则会产生这种情况:
当你达到最大调用堆栈时,会容易发生这种情况,特别是在没有测试代码时随意使用递归。
看看这个示例代码:
1 | function foo() { |
代码执行时,首先调用函数「foo」。然而,这是递归函数,调用自身的同时又没有设置终止条件,所以每一次执行,相同的函数都会被添加进堆栈中,看起来就是这样: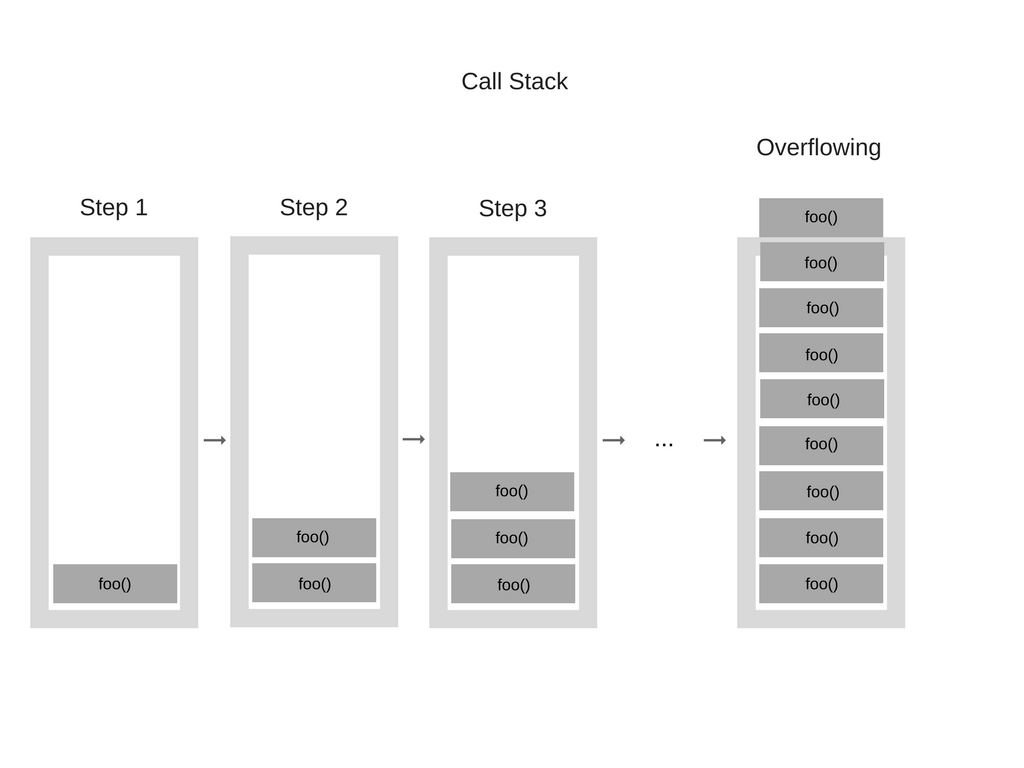
某些时候,调用堆栈中的函数调用次数超过了调用堆栈的实际大小,那么浏览器就会抛出一个错误,看起来像这样:
单线程上编写代码相对多线程来说会简单得多,你不必考虑死锁这样的复杂场景。但单线程也有许多限制,由于 JavaScript 有调用堆栈,当执行代码需要耗费大量时间时是怎样的呢?
并发和事件循环
当你在调用堆栈中进行函数调用,有时候需要大量时间才能进行处理。例如在浏览器中使用JavaScript 进行一些复杂的图像转换。在这个过程中又发生了什么?
这个问题的产生是因为,虽然调用堆栈具有执行的功能,但浏览器本身是无法渲染也不能运行其他任何代码,它被卡住了。当你想执行一套流畅的 UI 时,就会产生这样的问题。大多数浏览器通过抛出异常处理错误,询问用户是否要终止网页: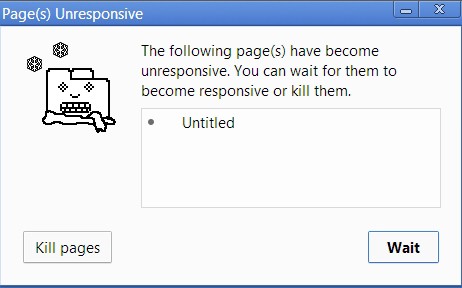
这个用户体验很糟糕。那么如何解决呢?答案是异步回调(asynchronous callbacks)。这是后话,下次再讲。
翻译和参考 https://blog.sessionstack.com/how-does-javascript-actually-work-part-1-b0bacc073cf