小筆記. Tensorflow 裡實作的 GRU 跟 Colah’s blog 描述的 GRU 有些不太一樣. 所以做了一下 TF 的 GRU 結構. 圖比較醜, 我盡力了… XD
TF 的 GRU 結構
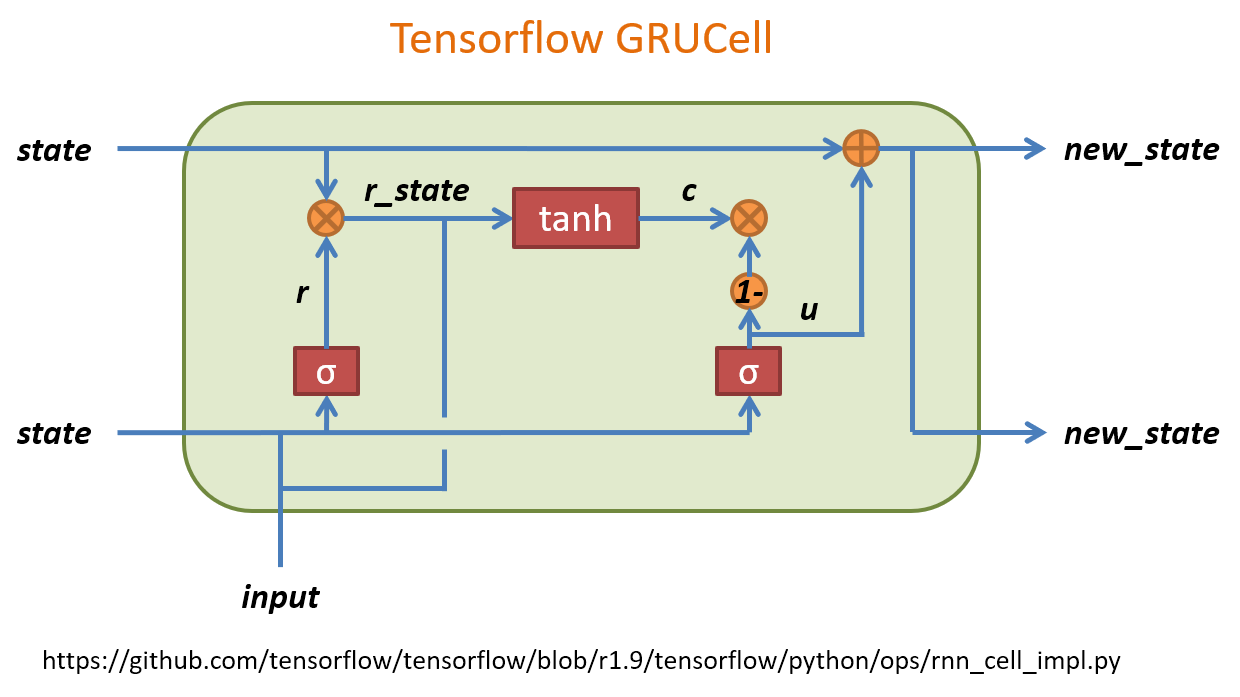
u 可以想成是原來 LSTM 的 forget gate, 而 c 表示要在 memory cell 中需要記住的內容. 這個要記住的內容簡單講是用一個 gate (r) 來控制之前的 state 有多少比例保留, concate input 後做 activation transform 後得到. 可以對照下面 tf source codes.
TF Source Codes
rnn_cell_impl.py
1 2 3 4 5 6 7 8 9
| def (self, inputs, state): """Gated recurrent unit (GRU) with nunits cells.""" gate_inputs = math_ops.matmul( array_ops.concat([inputs, state], 1), self._gate_kernel) gate_inputs = nn_ops.bias_add(gate_inputs, self._gate_bias) value = math_ops.sigmoid(gate_inputs) r, u = array_ops.split(value=value, num_or_size_splits=2, axis=1) r_state = r * state candidate = math_ops.matmul( array_ops.concat([inputs, r_state], 1), self._candidate_kernel) candidate = nn_ops.bias_add(candidate, self._candidate_bias) c = self._activation(candidate) new_h = u * state + (1 - u) * c return new_h, new_h
|