Hadoop Distributed File System:分布式文件系统。 HDFS基于流数据模式访问和处理超大文件需求开发,具有高容错性,高可靠性,高可扩展性,多部署在低成本的硬件上。HDFS提供对应用程序数据的高吞吐量访问,便利了海量数据的处理
介绍
- 假设和目标
- 硬件故障:检测故障并从中快速恢复
- 流式数据访问
- HDFS设计用于批处理而非用户的交互使用
- 重点是数据访问的高吞吐量而非低延迟
- 大数据集
- HDFS上运行的应用程序具有大型数据集,支持大文件
- 应为单个集群中的数百个结点提供高聚合数据带宽和扩展
- 应在单个实例中支持数万个文件
- 一致性模型
- write-one-read-many
- 除了追加和截断之外,无需更改创建,写入和关闭的文件
- 支持将内容附加到文件末尾,但是无法在任意点更新
- MapReduce应用程序和Web爬虫程序完全适用于此模型
- 移动计算而非移动数据
- 好的做法是将计算迁移到更靠近数据所在的位置(HDFS提供接口)
- 应用程序在其操作的数据附近执行,效率更高
- 最大限度减小网络拥塞和提高系统吞吐量
- 跨异构硬件和软件平台的可移植性
大专栏 BeWhatevererlink" title="HDFS 架构 – 主从架构(master/slave)">HDFS 架构 – 主从架构(master/slave)
- 架构图
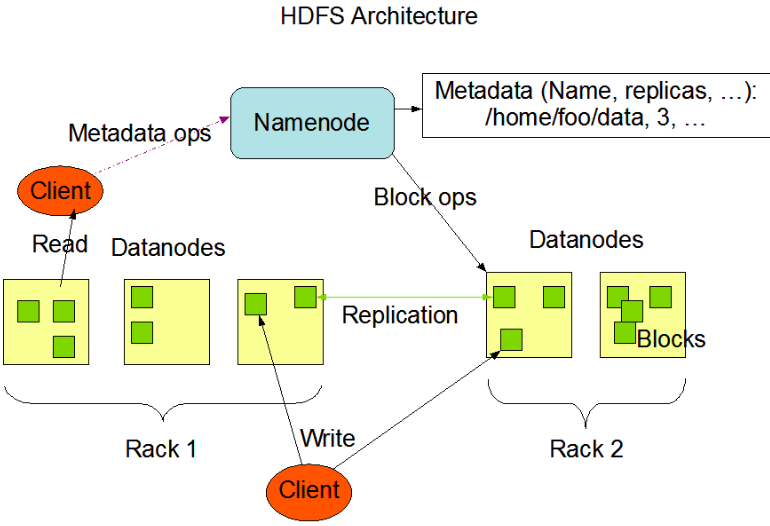
- Client
- 文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block进行存储
- 与 NameNode 交互,获取文件的位置信息
- 与 DataNode 交互,读取或者写入数据
- Client 提供命令来管理 HDFS,启动或者关闭HDFS
- Client 可以通过一些命令来访问HDFS
- NameNode(master)
- 管理系统命名空间
- 管理客户端对文件的访问(读写请求)
- 管理数据块映射信息
- 配置副本策略
- DataNode(slave)
- 确定块 – DataNode的映射
- 提供来自Client的读写请求
- 块创建/删除
- Secondary NameNode
- 当NameNode挂掉的时候,并不能马上替换 NameNode 提供服务
- 辅助 NameNode,分担其工作量
- 定期合并 fsimage和fsedits,并推送给NameNode
- 在紧急情况下,可辅助恢复 NameNode