author:lihaiping1603@aliyun.com
date:2019-12-20
如何生成dump core文件?
当我们在linux下将ffmpeg编译好之后,进入运行调试阶段,突然ffmpeg就cash了,提示出现了一个莫名其妙的"segment fault(段错误)"。然后我们想找出他崩溃时候出现的堆栈信息,这时候我们想到了dump core文件,但ls一看,当前目录下是空的,并没有任何的core文件生成,这时候如何是好呢?
一般来说程序cash了,都会生成一个core文件的,但为什么生成不了呢?是不是被系统限制了啥?网上一查,果然如此。我们要判断是不是系统限制,可以通过命令 ulimit -a 查看当前系统core文件的大小限制。
例如:
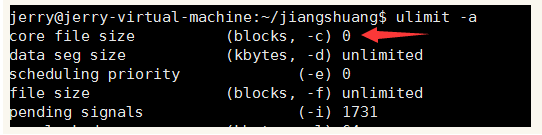

这种情况,说明core文件被限制,因为他限制生成core文件的大小为0,那也就是生成不了core文件。
如何解除这种限制呢?办法是通过ulimit -a unlimited 来解除,运行这条命令以后,我们再ulimit -a查看一下:


这个时候,我们再运行ffmpeg,如果崩溃的话,就会在当前命令生成相应的core文件了。
通过gdb和core查看堆栈信息,堆栈信息中全是??,并不能找到代码对应的堆栈函数信息
通过上一步,我们能生成cash当时的core文件了,但当gdb 该core文件的时候,堆栈信息却是一堆??,这个是什么原因导致的?我们如何解决这个问题?
这个问题的主要原因是因为我们的ffmpeg在编译的时候没有开启调试选项信息,如果我们需要生成的core文件能有效的话,我们需要在编译ffmpeg的时候,不能去掉strip符号信息,而ffmpeg默认是去掉strip符号 信息的,所以我们编译配置的时候,需要加上./configure --enable-debug --disable-optimizations --disable-asm --disable-stripping 。
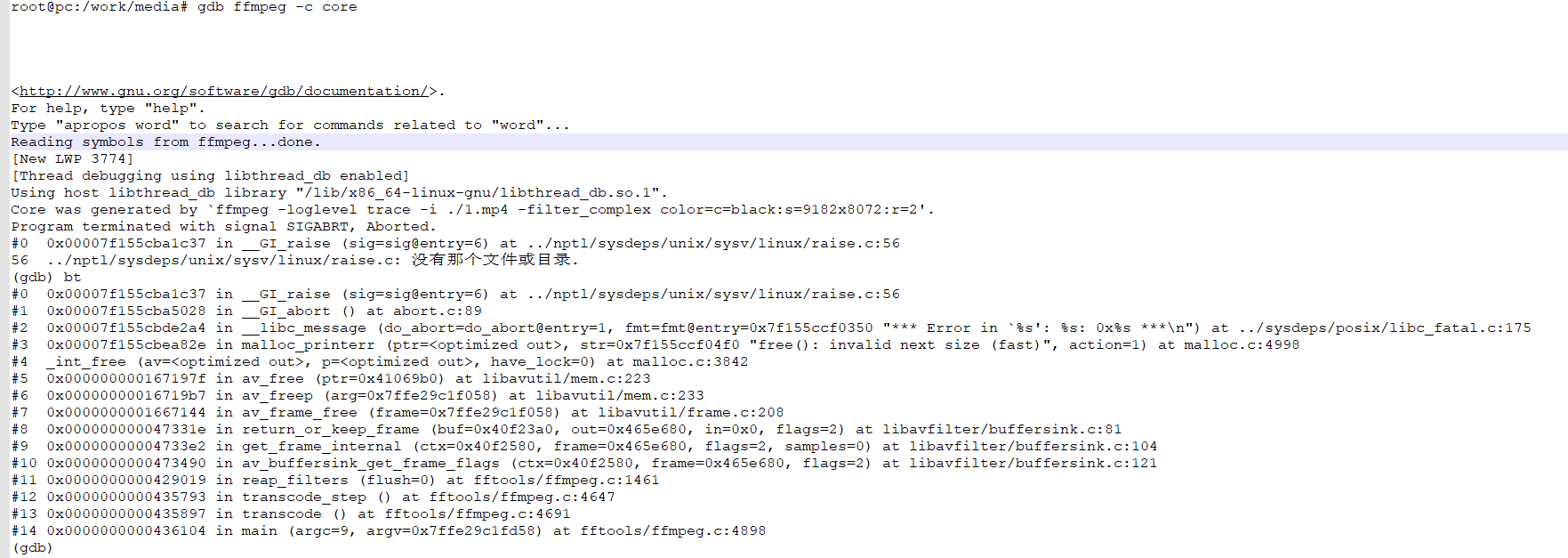
这时候生成的core文件堆栈信息就能显示相关详细函数了。
例如:

ffmpeg filter中,关于frame的释放出现的一个bug
最近在开发filter的时候,出现了一个frame释放的bug,其实这个是一个个人人为造成的bug,但还是在这里记录一下。
在filter中,我们经常从prev filter拿到帧数据以后,可能在current filter中直接对帧数据进行修改,也可能需要对这个帧数据需要进行先拷贝,然后再修改的过程(可参考writing_filter.txt或者我翻译的writing_filter_zh.md )。
而我在自己开发的这个filter中,我是先从缓冲器中获取到一个src frame之后,先对他进行一个scale,然后scale以后,我就把src frame给free了,因为我觉得这个frame,我后续用不到了,所以选择释放掉,防止内存释放,但就因为我这个释放,导致ffmpeg在用到这个filter的时候,就崩溃了,你说尴尬不,一开始我还莫名其妙。
后面再阅读了一次writing_filter.txt中的内容,我就知道我犯了啥错误,我这个地方从缓冲器中获取到的frame,不应该由我释放,因为他被其他地方引用了,所以这里有两个方式,
1,修改之前先拷贝一次,然后去scale
2,不拷贝,那也就不用释放
这个过程可以多参考几个源码中的filter写法。
一般来说,如果我们获取到的这个frame,先抛弃掉我们自己的处理过程(假如我们啥都不做的话),如果这个frame是直接被传递到next filter当中的话,那么我们就需要对这个frame释放,我们有它的所有管理权限,例如crop中的frame。如果不是直接被传递到next filter的话,那我们就需要更加谨慎处理了,需要判断我们可以释放the frame,例如overlay滤镜当中的do blend函数,通过ff_framesync_dualinput_get_writable 函数获取到的mainpic 和second 两个frame,因为mainpic ,我们是直接后续会传递给next filter的,所以我们在当前filter中进行释放,他是没有问题的,但second 这个frame,我们是不能进行释放的,他被缓存了,所以如果选择释放的话,就会出现崩溃cash的可能。
diff 生成补丁文件
在开发一个filter之后,我们需要通过diff 命令:diff -Naru file_old file_new > differences.patch
来生成补丁文件,后续再其他的场景下,我们直接用这个补丁文件,进行打补丁就OK,防止人为的二次修改导致出现的bug。
转载请注明出处:https://www.cnblogs.com/lihaiping/p/12072323.html