写这篇文章,起源于要写一个脚本批量把CSV文件(文件采用GBK或utf-8编码)写入到sqlite数据库里。
Python版本:2.7.9
sqlite3模块提供了con = sqlite3.connect("D:\text_factory.db3") 这样的方法来创建数据库(当文件不存在时,新建库),数据库默认编码为UTF-8,支持使用特殊sql语句设置编码
PRAGMA encoding = "UTF-8";
PRAGMA encoding = "UTF-16";
PRAGMA encoding = "UTF-16le";
PRAGMA encoding = "UTF-16be";
但设置编码必须在main库之前,否则无法更改。 https://www.sqlite.org/pragma.html#pragma_encoding
认识text_factory属性,大家应该都是通过以下错误知晓的:
sqlite3.ProgrammingError: You must not use 8-bit bytestrings unless you use a text_factory that can interpret 8-bit bytestrings (like text_factory = str). It is highly recommended that you instead just switch your application to Unicode strings.
大意是推荐你把字符串入库之前转成unicode string,你要用bytestring字节型字符串(如ascii ,gbk,utf-8),需要加一条语句text_factory = str。
Python拥有两种字符串类型。标准字符串是单字节字符序列,允许包含二进制数据和嵌入的null字符。 Unicode 字符串是双字节字符序列,一个字符使用两个字节来保存,因此可以有最多65536种不同的unicode字符。尽管最新的Unicode标准支持最多100万个不同的字符,Python现在尚未支持这个最新的标准。
默认text_factory = unicode,原以为这unicode、str是函数指针,但貌似不是,是<type 'unicode'>和<type 'str'>
下面写了一段测试验证代码:
1 # -*- coding: utf-8 -*- 2 import sqlite3 3 ''' 4 GBK UNIC UTF-8 5 B8A3 798F E7 A6 8F 福 6 D6DD 5DDE E5 B7 9E 州 7 ''' 8 9 con = sqlite3.connect(":memory:") 10 # con = sqlite3.connect("D:\text_factory1.db3") 11 # con.executescript('PRAGMA encoding = "UTF-16";') 12 cur = con.cursor() 13 14 a_text = "Fu Zhou" 15 gb_text = "xB8xA3xD6xDD" 16 utf8_text = "xE7xA6x8FxE5xB7x9E" 17 unicode_text= u"u798Fu5DDE" 18 19 print 'Part 1: con.text_factory=str' 20 con.text_factory = str 21 print type(con.text_factory) 22 cur.execute("CREATE TABLE table1 (city);") 23 cur.execute("INSERT INTO table1 (city) VALUES (?);",(a_text,)) 24 cur.execute("INSERT INTO table1 (city) VALUES (?);",(gb_text,)) 25 cur.execute("INSERT INTO table1 (city) VALUES (?);",(utf8_text,)) 26 cur.execute("INSERT INTO table1 (city) VALUES (?);",(unicode_text,)) 27 cur.execute("select city from table1") 28 res = cur.fetchall() 29 print "-- result: %s"%(res) 30 31 print 'Part 2: con.text_factory=unicode' 32 con.text_factory = unicode 33 print type(con.text_factory) 34 cur.execute("CREATE TABLE table2 (city);") 35 cur.execute("INSERT INTO table2 (city) VALUES (?);",(a_text,)) 36 # cur.execute("INSERT INTO table2 (city) VALUES (?);",(gb_text,)) 37 # cur.execute("INSERT INTO table2 (city) VALUES (?);",(utf8_text,)) 38 cur.execute("INSERT INTO table2 (city) VALUES (?);",(unicode_text,)) 39 cur.execute("select city from table2") 40 res = cur.fetchall() 41 print "-- result: %s"%(res) 42 43 print 'Part 3: OptimizedUnicode' 44 con.text_factory = str 45 cur.execute("CREATE TABLE table3 (city);") 46 cur.execute("INSERT INTO table3 (city) VALUES (?);",(a_text,)) 47 #cur.execute("INSERT INTO table3 (city) VALUES (?);",(gb_text,)) 48 cur.execute("INSERT INTO table3 (city) VALUES (?);",(utf8_text,)) 49 cur.execute("INSERT INTO table3 (city) VALUES (?);",(unicode_text,)) 50 con.text_factory = sqlite3.OptimizedUnicode 51 print type(con.text_factory) 52 cur.execute("select city from table3") 53 res = cur.fetchall() 54 print "-- result: %s"%(res) 55 56 print 'Part 4: custom fuction' 57 con.text_factory = lambda x: unicode(x, "gbk", "ignore") 58 print type(con.text_factory) 59 cur.execute("CREATE TABLE table4 (city);") 60 cur.execute("INSERT INTO table4 (city) VALUES (?);",(a_text,)) 61 cur.execute("INSERT INTO table4 (city) VALUES (?);",(gb_text,)) 62 cur.execute("INSERT INTO table4 (city) VALUES (?);",(utf8_text,)) 63 cur.execute("INSERT INTO table4 (city) VALUES (?);",(unicode_text,)) 64 cur.execute("select city from table4") 65 res = cur.fetchall() 66 print "-- result: %s"%(res)
打印结果:
Part 1: con.text_factory=str
<type 'type'>
-- result: [('Fu Zhou',), ('xb8xa3xd6xdd',), ('xe7xa6x8fxe5xb7x9e',), ('xe7xa6x8fxe5xb7x9e',)]
Part 2: con.text_factory=unicode
<type 'type'>
-- result: [(u'Fu Zhou',), (u'u798fu5dde',)]
Part 3: OptimizedUnicode
<type 'type'>
-- result: [('Fu Zhou',), (u'u798fu5dde',), (u'u798fu5dde',)]
Part 4: custom fuction
<type 'function'>
-- result: [(u'Fu Zhou',), (u'u798fu5dde',), (u'u7ec2u5fd3u7a9e',), (u'u7ec2u5fd3u7a9e',)]
Part 1:unicode被转换成了utf-8,utf-8和GBK被透传,写入数据库,GBK字符串被取出显示时,需要用类似'gbk chars'.decode("cp936").encode("utf_8")的语句进行解析print
Part 2:默认设置,注释的掉都会产生以上的经典错误,输入范围被限定在unicode对象或纯ascii码
Part 3:自动优化,ascii为str对象,非ascii转为unicode对象
Part 4:GBK被正确转换,utf-8和unicode在存入数据库时,都被转为了默认编码utf-8存储,既'xe7xa6x8fxe5xb7x9e',
In[16]: unicode('xe7xa6x8fxe5xb7x9e','gbk')
Out[16]: u'u7ec2u5fd3u7a9e'
就得到了以上结果。
接着,用软件查看数据库里是如何存放的。
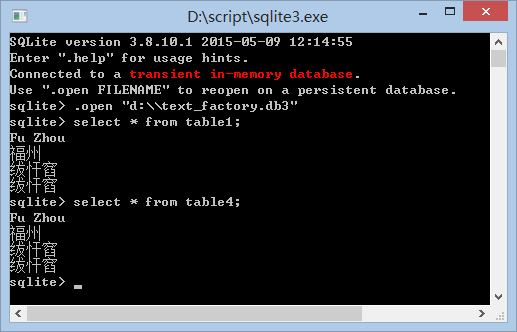
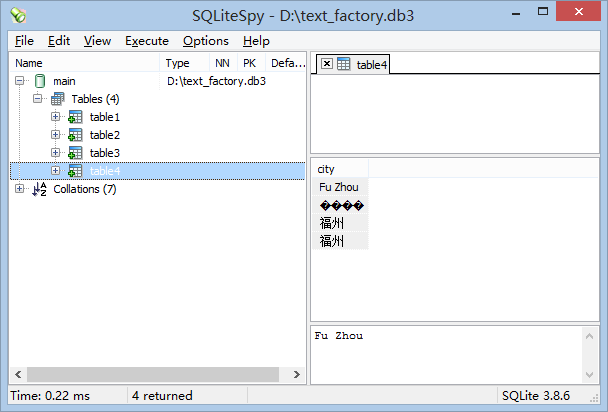
分别用官方的sqlite3.exe和SqliteSpy查看,sqlite3.exe因为用命令行界面,命令行用的是GBK显示;SqliteSpy则是用UTF显示,所以GBK显示乱码。这就再次印证了GBK被允许存放入数据库的时候,存放的是raw数据,并不会强制转为数据库的默认编码utf-8保存。
Connection.text_factory使用此属性来控制我们可以从TEXT类型得到什么对象(我:这也印证写入数据库的时候,需要自己编码,不能依靠这个)。默认情况下,这个属性被设置为Unicode,sqlite3模块将会为TEXT返回Unicode对象。若你想返回bytestring对象,可以将它设置为str。
因为效率的原因,还有一个只针对非ASCII数据,返回Unicode对象,其它数据则全部返回bytestring对象的方法。要激活它,将此属性设置为sqlite3.OptimizedUnicode。
你也可以将它设置为任意的其它callabel,接收一个bytestirng类型的参数,并返回结果对象。《摘自http://www.360doc.com/content/11/1102/10/4910_161017252.shtml》
以上一段话是官方文档的中文版关于text_factory描述的节选。
综上,我谈谈我的看法*和使用建议:
1)sqlite3模块执行insert时,写入的是raw数据,写入前会根据text_factory属性进行类型判断,默认判断写入的是否为unicode对象;
2)使用fetchall()从数据库读出时,会根据text_factory属性进行转化。
3)输入字符串是GBK编码的bytestring,decode转为unicode写入;或加text_factory=str直接写入,读出时仍为GBK,前提需要数据库编码为utf-8,注意用sqlitespy查看是乱码。
4)输入字符串是Utf-8编码的bytestring,可以设置text_factory=str直接写入直接读出,sqlitespy查看正常显示。
5)如果不是什么高性能场景,入库前转成unicode,性能开销也很小,测试数据找不到了,像我这样话一整天研究这一行代码,不如让机器每次多跑零点几秒。。
*(因为没有查看sqlite3模块的源代码,所以只是猜测)
另外,附上数据库设置为UTF-16编码时,产生的结果,更乱,不推荐。
Part 1: con.text_factory=str
<type 'type'>
-- result: [('Fu Zhou',), ('xc2xb8xc2xa3xefxbfxbdxefxbfxbd',), ('xe7xa6x8fxe5xb7x9e',), ('xe7xa6x8fxe5xb7x9e',)]
Part 2: con.text_factory=unicode
<type 'type'>
-- result: [(u'Fu Zhou',), (u'u798fu5dde',)]
Part 3: OptimizedUnicode
<type 'type'>
-- result: [('Fu Zhou',), (u'u798fu5dde',), (u'u798fu5dde',)]
Part 4: custom fuction
<type 'function'>
-- result: [(u'Fu Zhou',), (u'u8d42u62e2u951fu65a4u62f7',), (u'u7ec2u5fd3u7a9e',), (u'u7ec2u5fd3u7a9e',)]