基于numpy指南的学习
——https://docs.scipy.org/doc/numpy-1.13.0/user/quickstart.html
1、 arange、reshape函数
import numpy as np
a = np.arange(12).reshape(3, 4)
print(a)

2、ndim,shape,size,dtype,itemsize,data函数
import numpy as np
a = np.arange(12).reshape(3, 4)
#print(a)
print(a.ndim)#打印数组的维度
print(a.shape)#打印数组各个维度的长度
print(a.size)#打印数组中有几个元素
print(a.dtype)#打印数组的数据类型
print(a.itemsize)#打印数组数据类型的字节大小 int32 是4,int64是8……
print(a.data)

3、numpy中数组的创建
方式一
a = np.array([[1, 2, 3],
[4, 5, 6]], dtype = np.int64)
一定要注意维度的[]问题,同时还能再创建的时候定义数据类型有
方式二
文章一开始提及的操作
方式三
The function zeros creates an array full of zeros, the function ones creates an array full of ones, and the function empty creates an array whose initial content is random and depends on the state of the memory. By default, the dtype of the created array is float64.
如上描述的三种函数zeros,ones,empty
a = np.ones((3, 4))
print(a)
print(a.dtype)
b = np.empty((3, 4))
print(b)
print(b.dtype)
c = np.zeros((3, 4))
print(c)
print(c.dtype)

创建指定的数组,类型都是np.float64的
方式四
When arange is used with floating point arguments, it is generally not possible to predict the number of elements obtained, due to the finite floating point precision. For this reason, it is usually better to use the function linspace that receives as an argument the number of elements that we want, instead of the step:
正如所说,我们可以使用linspace来创建一个等差序列
a = np.linspace(2, 12, 6).reshape(2, 3)
print(a)
print(a.dtype)

同样的我们也能用reshape来规定它的形状,但是一定要注意元素个数与形状匹配,并且它的类型也是np.float64
4、 关于打印
the last axis is printed from left to right,
the second-to-last is printed from top to bottom,
the rest are also printed from top to bottom, with each slice separated from the next by an empty line.
最后一维是从左到右,第二维是从上到下,剩下的也是从上到下
a = np.arange(2, 14).reshape(2, 2, 3)
print(a)
print(a.dtype)

如果数据规模太过大,打印可能会缩水
a = np.arange(10000).reshape(100, 100)
print(a)

If an array is too large to be printed, NumPy automatically skips the central part of the array and only prints the corners:
正如这句话说的只能打印四个角,中间的都被隐藏了
想要完全打印也是可以的
加上这条np.set_printoptions(threshold=np.nan),但是我一使用这条就报错不知道怎么回事
5、基本操作
+、-、*、/、(,等**
a = np.arange(12).reshape(3, 4)
b = np.arange(12, 24).reshape(3, 4)
print(a)
print("")
print(b)
print("")
print(a + b)
print("")
print(a - b)
print("")
print(a * b)
print("")
print(a / b)

矩阵乘法dot函数
np.dot(a, b), a.dot(b)都是同一个结果
a = np.arange(12).reshape(3, 4)
b = np.arange(12, 24).reshape(4, 3)
print(a)
print("")
print(b)
print("")
print(a.dot(b))

3.31
同样的numpy提供了许多一元操作
a = np.arange(12).reshape(3, 4)
print(a.sum())
print(a.sum(axis = 1))
print(a.sum(axis = 0))
print(a.min())
print(a.min(axis = 1))
print(a.min(axis = 0))
print(a.max())
print(a.max(axis = 1))
print(a.min(axis = 0))
这些操作可以对应于所有的元素,也可以指定特定的轴,对于二维的axis = 0对应的是列,1对应的是行。

NumPy provides familiar mathematical functions such as sin, cos, and exp等
同时还有一些熟悉的数学函数,这里列出其中一个的用法
a = np.ones((2, 3))
b = np.arange(6).reshape(2, 3)
print(b * np.exp(a))

索引切片迭代
Indexing, Slicing and Iterating
一维数组的索引切片迭代就像python内置的列表一样,这里就不用实例来说明了
这里又介绍了一种新的数组生成方式
def f(x, y):
return x + y
a = np.fromfunction(f, (4, 5))
print(a)
这里的x,y分别对应的是其数组下标,也就是索引值,当然其也可以指定dtype类型

多维切片
这里还是用上面的数组
多维切片有两个参数,一个是行,另一个是列
例如
a.[:,:]就是打印出一整个数组
a.[:3,:]就是打印出第0,1,2行的
a.[:3,:4]就是打印前三行的前三列,估计看到这都知道这二维的切片是怎么回事了吧

索引操作,这个跟c语言的字符数组操作一模一样
同时索引切片还支持负数的操作,就跟python内置的列表操作一样。
print(a[0])

更高维度的切片
c = np.array( [[[ 0, 1, 2],
[ 10, 12, 13]],
[[100,101,102],
[110,112,113]]])
print(c[1,])
print(c[1,...])
print(c[...,0])
这里是通过加,…的方式来达到目的,c[1,] 和c[1,…]的行为是一样的,
但是c[…,0]能达到目的,c[,0]却会报错,所以最好还是加上”…”

迭代
基于二维的迭代。
a = np.arange(12).reshape(3, 4)
for i in a:
print(i)
for i in a.flat:
print(i)
我们可以看到默认的迭代对象是以行为单位,
通过flat可以迭代出数组内的所有元素。
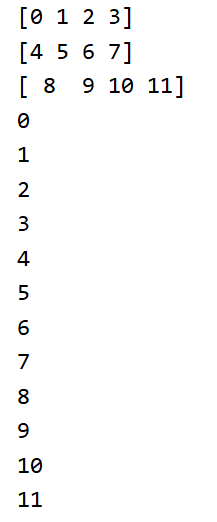
基于三维的迭代
迭代的基本单位是二维的。
从这里我们不难得到其迭代单位是它的降维。
a = np.arange(12).reshape(2, 2, 3)
for i in a:
print(i)
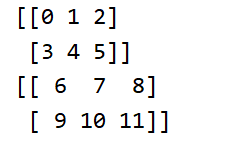
数组的形状Shape
这里再说一个reshape函数,可以在创建数组的时候固定形状,也可以在创建后固定形状。
a = np.arange(12)
b = np.arange(12).reshape((3, 4))
print(b)
print(a)
a = a.reshape((3, 4))
print(a)

合并不同的矩阵Stacking together different arrays¶
a = np.arange(4).reshape(2, 2)
b = np.arange(4, 8).reshape(2, 2)
print(a)
print(b)
print(np.vstack((a, b)))#里面一定是元组组成的变量
print(np.hstack((a, b)))
在二维数组中
vstack 进行水平方向的叠加还有个np.column_stack和它的效果一样
hstack 进行竖直方向上的叠加,同样的有np.row_stack

数组的分块
Splitting one array into several smaller ones
和上面的stack刚好相反,split也有hsplit 和vsplit、
Hsplit用法及效果
a = np.arange(12).reshape((2, 6))
x, y, z = np.hsplit(a, 3)
print(a)
print(x)
print(y)
print(z)

Vsplit用法及效果
a = np.arange(12).reshape((2, 6))
x, y = np.vsplit(a, 2)
print(a)
print(x)
print(y)
通过这两个例子我们可以看出,数组在进行分解后维度依然还是遵守原样。

数组的拷贝
Copies and Views
浅度拷贝
>>> a = np.arange(12)
>>> b = a # no new object is created
>>> b is a # a and b are two names for the same ndarray object
True
>>> b.shape = 3,4 # changes the shape of a
>>> a.shape
(3, 4)
这里直接引用网站上的说明, = 号并不是赋值,而是把两个变量直接指向同一个地址,其中一个元素发生变化,也就是这个地址中的元素发生变化,另一个变量也会跟着发生变化。
a = np.arange(6).reshape((2, 3))
b = a
b[0][0] = 15
print(a)
print(b)

这些东西我暂时没怎么搞懂,先挂上吧,等以后用上的时候再来叙述
View or Shallow Copy
Different array objects can share the same data. The view method creates a new array object that looks at the same data.
>>> c = a.view()
>>> c is a
False
>>> c.base is a # c is a view of the data owned by a
True
>>> c.flags.owndata
False
>>>
>>> c.shape = 2,6 # a's shape doesn't change
>>> a.shape
(3, 4)
>>> c[0,4] = 1234 # a's data changes
>>> a
array([[ 0, 1, 2, 3],
[1234, 5, 6, 7],
[ 8, 9, 10, 11]])
Slicing an array returns a view of it:
>>> s = a[ : , 1:3] # spaces added for clarity; could also be written "s = a[:,1:3]"
>>> s[:] = 10 # s[:] is a view of s. Note the difference between s=10 and s[:]=10
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
深度拷贝
这个就比较简单了,意思就是使这两个变量不关联,主要就是一个函数np.copy
a = np.arange(6)
b = a.copy()
c = np.copy(a)
print(b)
print(c)
一张基本函数的概要图

花式索引和索引的技巧
Fancy indexing and index tricks
用array数组来索引
a = np.arange(12) ** 2
b = np.array([1, 2, 3])#一维
print(a[b])
b = np.array([[2, 3], [4, 5]])#二维
print(a[b])

索引值改变数组
a = np.arange(12) ** 2
b = np.array([1, 2, 3])#生成一维
a[b] = 0
print(a)

用bool数组来索引
a = np.arange(6).reshape(2, 3)
b = np.array([
[False, True, False],
[False, False, True],
], dtype = bool)
print(a[b])

a = np.arange(6).reshape(2, 3)
b = a > 2
print(b)
print(a[b])

Bool数组的高阶索引
这里就和之前提到的多维数组索引的操作差不多
a = np.arange(6).reshape(2, 3)
b = np.array([False, True], dtype = bool)
print(a[b,])
