转载地址:https://www.cnblogs.com/len0031/p/12108737.html
java代码
1 import org.apache.logging.log4j.LogManager; 2 import org.apache.logging.log4j.Logger; 3 import org.apache.poi.hwpf.HWPFDocument; 4 import org.apache.poi.hwpf.converter.PicturesManager; 5 import org.apache.poi.hwpf.converter.WordToHtmlConverter; 6 import org.apache.poi.hwpf.usermodel.PictureType; 7 import org.apache.poi.xwpf.converter.core.BasicURIResolver; 8 import org.apache.poi.xwpf.converter.core.FileImageExtractor; 9 import org.apache.poi.xwpf.converter.xhtml.XHTMLConverter; 10 import org.apache.poi.xwpf.converter.xhtml.XHTMLOptions; 11 import org.apache.poi.xwpf.usermodel.XWPFDocument; 12 import org.springframework.stereotype.Controller; 13 import org.springframework.web.bind.annotation.RequestMapping; 14 import org.w3c.dom.Document; 15 import javax.xml.parsers.DocumentBuilderFactory; 16 import javax.xml.parsers.ParserConfigurationException; 17 import javax.xml.transform.OutputKeys; 18 import javax.xml.transform.Transformer; 19 import javax.xml.transform.TransformerException; 20 import javax.xml.transform.TransformerFactory; 21 import javax.xml.transform.dom.DOMSource; 22 import javax.xml.transform.stream.StreamResult; 23 import java.io.*; 24 @Controller 25 @RequestMapping("/manual/") 26 public class ManualController { 27 28 private static final Logger logger = LogManager.getLogger(ManualController.class); 29 30 /** 31 * 将word2003转换为html文件 32 * 33 * @param wordPath word文件路径 34 * @param wordName word文件名称无后缀 35 * @param suffix word文件后缀 36 * @param htmlPath html存储地址 37 * @throws IOException 38 * @throws TransformerException 39 * @throws ParserConfigurationException 40 */ 41 public static String Word2003ToHtml(String wordPath, String wordName, String suffix, String htmlPath) 42 throws IOException, TransformerException, ParserConfigurationException { 43 String htmlName = wordName + ".html"; 44 final String imagePath = htmlPath + "image" + File.separator; 45 // 判断html文件是否存在 46 File htmlFile = new File(htmlPath + htmlName); 47 if (htmlFile.exists()) { 48 return htmlFile.getAbsolutePath(); 49 } 50 // 原word文档 51 final String file = wordPath + File.separator + wordName + suffix; 52 InputStream input = new FileInputStream(new File(file)); 53 HWPFDocument wordDocument = new HWPFDocument(input); 54 WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter( 55 DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument()); 56 // 设置图片存放的位置 57 wordToHtmlConverter.setPicturesManager(new PicturesManager() { 58 public String savePicture(byte[] content, PictureType pictureType, String suggestedName, float widthInches, 59 float heightInches) { 60 File imgPath = new File(imagePath); 61 if (!imgPath.exists()) {// 图片目录不存在则创建 62 imgPath.mkdirs(); 63 } 64 File file = new File(imagePath + suggestedName); 65 try { 66 OutputStream os = new FileOutputStream(file); 67 os.write(content); 68 os.close(); 69 } catch (FileNotFoundException e) { 70 e.printStackTrace(); 71 } catch (IOException e) { 72 e.printStackTrace(); 73 } 74 // 图片在html文件上的路径 相对路径 75 return "image/" + suggestedName; 76 } 77 }); 78 // 解析word文档 79 wordToHtmlConverter.processDocument(wordDocument); 80 Document htmlDocument = wordToHtmlConverter.getDocument(); 81 // 生成html文件上级文件夹 82 File folder = new File(htmlPath); 83 if (!folder.exists()) { 84 folder.mkdirs(); 85 } 86 OutputStream outStream = new FileOutputStream(htmlFile); 87 DOMSource domSource = new DOMSource(htmlDocument); 88 StreamResult streamResult = new StreamResult(outStream); 89 TransformerFactory factory = TransformerFactory.newInstance(); 90 Transformer serializer = factory.newTransformer(); 91 serializer.setOutputProperty(OutputKeys.ENCODING, "utf-8"); 92 serializer.setOutputProperty(OutputKeys.INDENT, "yes"); 93 serializer.setOutputProperty(OutputKeys.METHOD, "html"); 94 serializer.transform(domSource, streamResult); 95 return htmlFile.getAbsolutePath(); 96 } 97 /** 98 * 99 * 2007版本word转换成html 100 * 101 * @param wordPath word文件路径 102 * @param wordName word文件名称无后缀 103 * @param suffix word文件后缀 104 * @param htmlPath html存储地址 105 * @return 106 * @throws IOException 107 */ 108 public static String Word2007ToHtml(String wordPath, String wordName, String suffix, String htmlPath) 109 throws IOException { 110 String htmlName = wordName + ".html"; 111 String imagePath = htmlPath + "image" + File.separator; 112 // 判断html文件是否存在 113 File htmlFile = new File(htmlPath + htmlName); 114 if (htmlFile.exists()) { 115 return htmlFile.getAbsolutePath(); 116 } 117 // word文件 118 File wordFile = new File(wordPath + File.separator + wordName + suffix); 119 // 1) 加载word文档生成 XWPFDocument对象 120 InputStream in = new FileInputStream(wordFile); 121 XWPFDocument document = new XWPFDocument(in); 122 // 2) 解析 XHTML配置 (这里设置IURIResolver来设置图片存放的目录) 123 File imgFolder = new File(imagePath); 124 XHTMLOptions options = XHTMLOptions.create(); 125 options.setExtractor(new FileImageExtractor(imgFolder)); 126 // html中图片的路径 相对路径 127 options.URIResolver(new BasicURIResolver("image")); 128 options.setIgnoreStylesIfUnused(false); 129 options.setFragment(true); 130 // 3) 将 XWPFDocument转换成XHTML 131 // 生成html文件上级文件夹 132 File folder = new File(htmlPath); 133 if (!folder.exists()) { 134 folder.mkdirs(); 135 } 136 OutputStream out = new FileOutputStream(htmlFile); 137 XHTMLConverter.getInstance().convert(document, out, options); 138 return htmlFile.getAbsolutePath(); 139 } 140 141 public static void main(String[] args) { 142 try { 143 Word2007ToHtml("D:\Ning\word2html\", "33", ".docx", "D://Ning//word2html/"); 144 } catch (Exception e) { 145 e.printStackTrace(); 146 } 147 } 148 }
xml
1 <dependency> 2 <groupId>org.apache.poi</groupId> 3 <artifactId>poi-scratchpad</artifactId> 4 <version>3.14</version> 5 </dependency> 6 <dependency> 7 <groupId>org.apache.poi</groupId> 8 <artifactId>poi-ooxml</artifactId> 9 <version>3.14</version> 10 </dependency> 11 <dependency> 12 <groupId>fr.opensagres.xdocreport</groupId> 13 <artifactId>xdocreport</artifactId> 14 <version>1.0.6</version> 15 </dependency> 16 <dependency> 17 <groupId>org.apache.poi</groupId> 18 <artifactId>poi-ooxml-schemas</artifactId> 19 <version>3.14</version> 20 </dependency> 21 <dependency> 22 <groupId>org.apache.poi</groupId> 23 <artifactId>ooxml-schemas</artifactId> 24 <version>1.3</version> 25 </dependency> 26 <dependency> 27 <groupId>org.jsoup</groupId> 28 <artifactId>jsoup</artifactId> 29 <version>1.11.3</version> 30 </dependency>
需要自己新建一个测试docx文件
找到生成文件路径

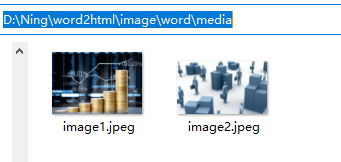
生成的图片位置
打开生成的html文档(图片地址为生成的文件夹图片路径)