排序算法
数组 a[n]或A[n] 从小到大
一、冒泡排序
原理:重复走过要排序的数组(n-1次),依次比较相邻元素的大小,若不对就进行交换,每趟进行(n-1-j次)比较
代码如下:
For(int j=0;j<n-1;j++)
For(int i=0;i<n-1-j;i++)
If(a[i]>a[i+1])swap(a[i],a[i+1]);
二、选择排序
原理:遍历(n-1)次,每次记录最大(最小)元素的位置,在每次遍历结束时进行交换
代码如下:
For(int i=0;i<n-1;i++)
{
Min=i;
For(int j=i+1;j<n;j++)
If(a[j]<a[min])min=j;
If(min!=i) swap(a[min],a[i]);
}
三、插入排序
原理:看做是两个序列,有序和待排序序列,对于待排序序列,依次取出第一个元素,在已排序序列中从后往前扫描,找到合适的位置插入。打个比方,左手拿有序的扑克牌,右手拿随便摸的牌,将右手的牌一张张插入到左手里。
代码如下:
For(int i=1;i<n;i++)
{
Int get=a[i]; //刚开始将第一个元素当做已排序序列,第二个元素之后为待排序序列。get 获得待排序序列的第一个元素
Int j=i-1; //get的前一个元素,即有序序列的最后一个元素
While( (j>0)&&(a[j]>get) ) //当前的有序序列元素大于get,继续向左扫描
{
a[j+1]=a[j]; //把大数右移
j--; //向左扫描
}
a[j+1]=get; //插入该位置
}
四、归并排序
原理:归并排序是分治策略的应用,将一个数组二分再二分,从而可以通过将大问题分解成小问题来解决。然后递归运用归并操作,将两个有序的数组归并。
代码如下:
合并两个已排好序的数组A[left...mid]和A[mid+1...right]
void Merge(int A[], int left, int mid, int right){
int len = right - left + 1;
int *temp = new int[len]; // 辅助空间O(n)
int index = 0;
int i = left; // 前一数组的起始元素
int j = mid + 1; // 后一数组的起始元素
while (i <= mid && j <= right)
{
temp[index++] = A[i] <= A[j] ? A[i++] : A[j++]; // 带等号保证归并排序的稳定性 }
while (i <= mid)
{
temp[index++] = A[i++];
}
while (j <= right)
{
temp[index++] = A[j++];
}
for (int k = 0; k < len; k++)
{
A[left++] = temp[k];
}
}
// 递归实现的归并排序(自顶向下)
void MergeSortRecursion(int A[], int left, int right)
{
if (left == right) // 当待排序的序列长度为1时,递归开始回溯,进行merge操作
return;
int mid = (left + right) / 2;
MergeSortRecursion(A, left, mid);
MergeSortRecursion(A, mid + 1, right);
Merge(A, left, mid, right);
}
// 非递归(迭代)实现的归并排序(自底向上)
void MergeSortIteration(int A[], int len)
{
int left, mid, right;// 子数组索引,前一个为A[left...mid],后一个子数组为A[mid+1...right]
for (int i = 1; i < len; i *= 2) // 子数组的大小i初始为1,每轮翻倍 {
left = 0;
while (left + i < len) // 后一个子数组存在(需要归并) {
mid = left + i - 1;
right = mid + i < len ? mid + i : len - 1;// 后一个子数组大小可能不够 Merge(A, left, mid, right);
left = right + 1; // 前一个子数组索引向后移动 }
}
}
五、快速排序
原理:在序列中选取一个基准,其他元素比基准大的放后面,比基准小的放前面,这个过程称为分区。每个分区递归操作
代码如下:
int Partition(int A[], int left, int right) // 划分函数
{
int pivot = A[right]; // 这里每次都选择最后一个元素作为基准
int tail = left - 1; // tail为小于基准的子数组最后一个元素的索引
for (int i = left; i < right; i++) // 遍历基准以外的其他元素
{
if (A[i] <= pivot) // 把小于等于基准的元素放到前一个子数组末尾
{
Swap(A, ++tail, i);
}
}
Swap(A, tail + 1, right); // 最后把基准放到前一个子数组的后边,剩下的子数组既是大于基准的子数组
// 该操作很有可能把后面元素的稳定性打乱,所以快速排序是不稳定的排序算法
return tail + 1; // 返回基准的索引
}
void QuickSort(int A[], int left, int right)
{
if (left >= right)
return;
int pivot_index = Partition(A, left, right); // 基准的索引
QuickSort(A, left, pivot_index - 1);
QuickSort(A, pivot_index + 1, right);
}
六、堆排序
原理:堆的第一个元素要么是最大值(大顶堆),要么是最小值(小顶堆),这样在排序的时候(假设共n个节点),直接将第一个元素和最后一个元素进行交换,然后从第一个元素开始进行向下调整至第n-1个元素。如果需要升序,就建一个大堆,需要降序,就建一个小堆。
堆排序的步骤分为三步:
1、建堆(升序建大堆,降序建小堆);
2、交换数据;
3、向下调整。
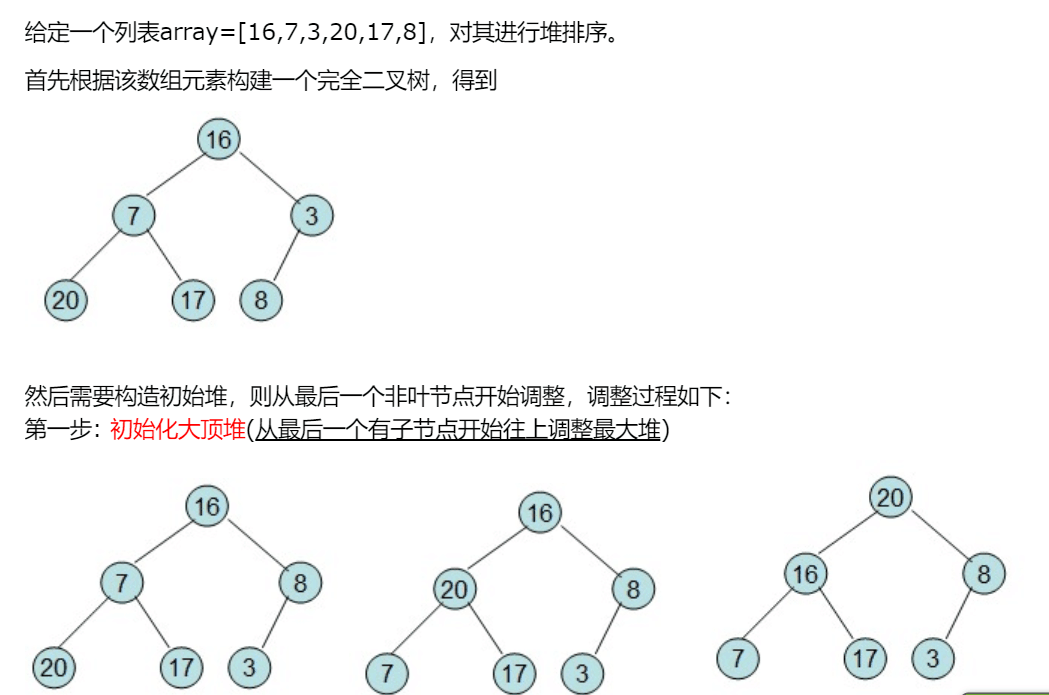



代码如下:
void Heapify(int A[], int i, int size) // 从A[i]向下进行堆调整
{
int left_child = 2 * i + 1; // 左孩子索引
int right_child = 2 * i + 2; // 右孩子索引
int max = i; // 选出当前结点与其左右孩子三者之中的最大值
if (left_child < size && A[left_child] > A[max])
max = left_child;
if (right_child < size && A[right_child] > A[max])
max = right_child;
if (max != i)
{
Swap(A, i, max); // 把当前结点和它的最大(直接)子节点进行交换
Heapify(A, max, size); // 递归调用,继续从当前结点向下进行堆调整 }
}
int BuildHeap(int A[], int n) // 建堆,时间复杂度O(n)
{
int heap_size = n;
for (int i = heap_size / 2 - 1; i >= 0; i--) // 从每一个非叶结点开始向下进行堆调整 Heapify(A, i, heap_size);
return heap_size;
}
void HeapSort(int A[], int n)
{
int heap_size = BuildHeap(A, n); // 建立一个最大堆
while (heap_size > 1) // 堆(无序区)元素个数大于1,未完成排序
{
// 将堆顶元素与堆的最后一个元素互换,并从堆中去掉最后一个元素
// 此处交换操作很有可能把后面元素的稳定性打乱,所以堆排序是不稳定的排序算法
Swap(A, 0, --heap_size);
Heapify(A, 0, heap_size); // 从新的堆顶元素开始向下进行堆调整,时间复杂度O(logn) }
}
七、计数排序
原理:找出数组中的最大最小元素,统计每个值为value的元素个数,然后按个数填充数组
代码如下:
void count_sort(int *arr, int *sorted_arr, int n)
{
int *count_arr = (int *)malloc(sizeof(int) * 100); int i; //初始化计数数组
for(i = 0; i<100; i++) count_arr[i] = 0; //统计i的次数
for(i = 0;i<n;i++) count_arr[arr[i]]++; //对所有的计数累加
for(i = 1; i<100; i++) count_arr[i] += count_arr[i-1]; //逆向遍历源数组(保证稳定性),根据计数数组中对应的值填充到先的数组中
for(i = n; i>0; i--)
{
sorted_arr[count_arr[arr[i-1]]-1] = arr[i-1];
count_arr[arr[i-1]]--;
}
free(count_arr);
}
八、基数排序
原理:基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。
代码如下:
Void RadixSort(Node L[],length,maxradix)
{
int m,n,k,lsp;
k=1;m=1;
int temp[10][length-1];
Empty(temp); //清空临时空间
while(k<maxradix) //遍历所有关键字
{
for(int i=0;i<length;i++) //分配过程
{
if(L[i]<m)
Temp[0][n]=L[i];
else
Lsp=(L[i]/m)%10; //确定关键字
Temp[lsp][n]=L[i];
n++;
}
CollectElement(L,Temp); //收集
n=0;
m=m*10;
k++;
}
}
九、桶排序
原理:桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。设置一个定量的数组当作空桶;遍历输入数据,并且把数据一个一个放到对应的桶里去;对每个不是空的桶进行排序;从不是空的桶里把排好序的数据拼接起来。

十、希尔排序
原理:希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作(且步长要小于数组长度)。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。

