从SpringCloud--Ribbon--源码解析--Ribbon入口实现可以看到Ribbon的总体流程,从总体流程可见,获取server是个关键点
protected Server getServer(ILoadBalancer loadBalancer, Object hint) {
if (loadBalancer == null) {
return null;
}
// Use 'default' on a null hint, or just pass it on?
return loadBalancer.chooseServer(hint != null ? hint : "default");
}
可以看到,getServer方法最终调用的是ILoadBalancer接口的chooseServer方法,IloadBalancer提供方法如下所示:
public interface ILoadBalancer {
//向负载均衡器中维护的实例列表中增加服务实例
public void addServers(List<Server> newServers);
//通过某种策略,负载均衡器维护的实力列表中获取一个实例
public Server chooseServer(Object key);
//标记服务不可用
public void markServerDown(Server server);
@Deprecated
public List<Server> getServerList(boolean availableOnly);
//获取当前正常服务的列表
public List<Server> getReachableServers();
//获取所有服务的列表
public List<Server> getAllServers();
}
方法的描述已经在上述代码中做了注释,通过查看该接口的实现类,其类关系结构如下所示:
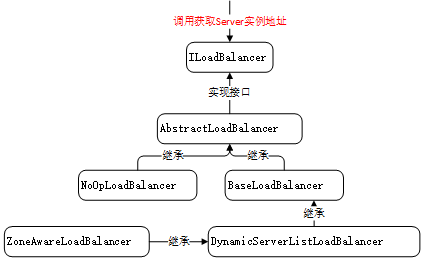
通过配置类RibbonClientConfiguration,我们发现,ZoneAwareLoadBalancer是ILoadBalancer接口的默认实现类。
@Bean
@ConditionalOnMissingBean
public ILoadBalancer ribbonLoadBalancer(IClientConfig config,
ServerList<Server> serverList, ServerListFilter<Server> serverListFilter,
IRule rule, IPing ping, ServerListUpdater serverListUpdater) {
if (this.propertiesFactory.isSet(ILoadBalancer.class, name)) {
return this.propertiesFactory.get(ILoadBalancer.class, config, name);
}
return new ZoneAwareLoadBalancer<>(config, rule, ping, serverList,
serverListFilter, serverListUpdater);
}
根据上述实现类,一个个做分析:
1、AbstractLoadBalancer
AbstractLoadBalancer类是ILoadBalancer接口的抽象实现类,在该抽象类中,定义了服务实例分组枚举类ServerGroup,包含三种不同类型(所有实例、正常服务实例、停止服务实例)
另外还提供了三个抽象方法,获取Server对象的chooseServer方法、根据服务枚举获取服务实例集合的方法getServerList方法、获取LoadBalancerStatus的getLoadBalancerStatus方法,其中LoadBalancerStatus对象主要用来存储负载均衡器种各个服务实例当前的属性和统计信息。
public abstract class AbstractLoadBalancer implements ILoadBalancer {
public enum ServerGroup{
ALL,
STATUS_UP,
STATUS_NOT_UP
}
public Server chooseServer() {
return chooseServer(null);
}
public abstract List<Server> getServerList(ServerGroup serverGroup);
public abstract LoadBalancerStats getLoadBalancerStats();
}
2、BaseLoadBalancer
BaseLoadBalancer类是Ribbon负载均衡器的基础实现类,在该类种,定义了许多关于负载均衡器的相关基础内容。
(1)定义并维护了两个存储服务实例Server对象的列表,一个用于存储所有服务清单,一个用于存储正常服务的清单。
(2)定义了用来存储负载均衡器各服务实例属性和统计信息的LoadBalanceStatus
(3)定义了检查服务实例是否正常服务的IPing对象
protected IPing ping = null;
@Monitor(name = PREFIX + "AllServerList", type = DataSourceType.INFORMATIONAL)
protected volatile List<Server> allServerList = Collections
.synchronizedList(new ArrayList<Server>());
@Monitor(name = PREFIX + "UpServerList", type = DataSourceType.INFORMATIONAL)
protected volatile List<Server> upServerList = Collections
.synchronizedList(new ArrayList<Server>());
protected LoadBalancerStats lbStats;
@Override
public List<Server> getReachableServers() {
return Collections.unmodifiableList(upServerList);
}
@Override
public List<Server> getAllServers() {
return Collections.unmodifiableList(allServerList);
}
(4)定义了检查服务实例操作的执行策咯对象IPingStrategy
private final static SerialPingStrategy DEFAULT_PING_STRATEGY = new SerialPingStrategy();
protected IRule rule = DEFAULT_RULE;
protected IPingStrategy pingStrategy = DEFAULT_PING_STRATEGY;
private static class SerialPingStrategy implements IPingStrategy {
@Override
public boolean[] pingServers(IPing ping, Server[] servers) {
int numCandidates = servers.length;
boolean[] results = new boolean[numCandidates];
logger.debug("LoadBalancer: PingTask executing [{}] servers configured", numCandidates);
for (int i = 0; i < numCandidates; i++) {
results[i] = false; /* Default answer is DEAD. */
try {
// NOTE: IFF we were doing a real ping
// assuming we had a large set of servers (say 15)
// the logic below will run them serially
// hence taking 15 times the amount of time it takes
// to ping each server
// A better method would be to put this in an executor
// pool
// But, at the time of this writing, we dont REALLY
// use a Real Ping (its mostly in memory eureka call)
// hence we can afford to simplify this design and run
// this
// serially
if (ping != null) {
results[i] = ping.isAlive(servers[i]);
}
} catch (Exception e) {
logger.error("Exception while pinging Server: '{}'", servers[i], e);
}
}
return results;
}
}
(5)定义了负载均衡处理的IRule对象,如果没有指定,默认使用RoundRobinRule
private final static IRule DEFAULT_RULE = new RoundRobinRule();
protected IRule rule = DEFAULT_RULE;
除此之外,在BaseLoadBalancer的构造函数种,还会启动一个用于检查Server是否健康的定时任务,该任务默认执行时间间隔为10秒
public BaseLoadBalancer(String name, IRule rule, LoadBalancerStats stats,
IPing ping, IPingStrategy pingStrategy) {
logger.debug("LoadBalancer [{}]: initialized", name);
this.name = name;
this.ping = ping;
this.pingStrategy = pingStrategy;
setRule(rule);
setupPingTask();
lbStats = stats;
init();
}
void setupPingTask() {
if (canSkipPing()) {
return;
}
if (lbTimer != null) {
lbTimer.cancel();
}
lbTimer = new ShutdownEnabledTimer("NFLoadBalancer-PingTimer-" + name,
true);
lbTimer.schedule(new PingTask(), 0, pingIntervalSeconds * 1000);
forceQuickPing();
}
除此之外,BaseLoadBalancer还实现了ILoadBalancer接口定义的一系列方法
(1)添加一个Server
@Override
public void addServers(List<Server> newServers) {
if (newServers != null && newServers.size() > 0) {
try {
ArrayList<Server> newList = new ArrayList<Server>();
newList.addAll(allServerList);
newList.addAll(newServers);
setServersList(newList);
} catch (Exception e) {
logger.error("LoadBalancer [{}]: Exception while adding Servers", name, e);
}
}
}
(2)选择一个Server
通过下述源码可以看到,最终调用的是IRule接口种的choose方法
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
(3)标记某个服务实例暂停服务
public void markServerDown(Server server) {
if (server == null || !server.isAlive()) {
return;
}
logger.error("LoadBalancer [{}]: markServerDown called on [{}]", name, server.getId());
server.setAlive(false);
// forceQuickPing();
notifyServerStatusChangeListener(singleton(server));
}
3、DynamicServerListLoadBalancer
DynamicServerListLoadBalancer继承于BaseLoadBalancer类,它是对于基础负载均衡器的扩展,实现了服务实例清单在运行期的动态更新能力;同时,它还具备了对服务实例清单的过滤功能。
通过以下源码可以看出,DynamicServerListLoadBalancer对于基础负载均衡器BaseLoadBalancer多了三个内容:ServerList、ServerListFilter、ServerListUpdater
volatile ServerList<T> serverListImpl;
volatile ServerListFilter<T> filter;
protected final ServerListUpdater.UpdateAction updateAction = new ServerListUpdater.UpdateAction() {
@Override
public void doUpdate() {
updateListOfServers();
}
};
protected volatile ServerListUpdater serverListUpdater;
public DynamicServerListLoadBalancer() {
super();
}
(1)ServerList
ServerList是一个接口,该接口种提供了两个方法:获取初始化服务实例清单方法getInitialListOfServers和获取更新服务实例清单方法getUpdatedListOfServers
查看ServerList的实现类,可以得到如下的实现和继承关系

那么,对于DynamicServerListLoadBalancer而言,使用的是哪一个呢,由于这两个方法都需要获取注册中心的服务实例,因此Ribbon肯定由访问Eureka的能力,那么可以看一下Ribbon和Eureka整合的加载类org.springframework.cloud.netflix.ribbon.eureka.EurekaRibbonClientConfiguration,可以查看ServerList的加载Bean
@Bean
@ConditionalOnMissingBean
public ServerList<?> ribbonServerList(IClientConfig config,
Provider<EurekaClient> eurekaClientProvider) {
if (this.propertiesFactory.isSet(ServerList.class, serviceId)) {
return this.propertiesFactory.get(ServerList.class, config, serviceId);
}
DiscoveryEnabledNIWSServerList discoveryServerList = new DiscoveryEnabledNIWSServerList(
config, eurekaClientProvider);
DomainExtractingServerList serverList = new DomainExtractingServerList(
discoveryServerList, config, this.approximateZoneFromHostname);
return serverList;
}
可以看到,默认使用的是DomainExtractingServerList,那么看下DomainExtractingServerList种对于ServerList种两个方法的实现
/**
* @author Dave Syer
*/
public class DomainExtractingServerList implements ServerList<DiscoveryEnabledServer> {
private ServerList<DiscoveryEnabledServer> list;
private final RibbonProperties ribbon;
private boolean approximateZoneFromHostname;
public DomainExtractingServerList(ServerList<DiscoveryEnabledServer> list,
IClientConfig clientConfig, boolean approximateZoneFromHostname) {
this.list = list;
this.ribbon = RibbonProperties.from(clientConfig);
this.approximateZoneFromHostname = approximateZoneFromHostname;
}
@Override
public List<DiscoveryEnabledServer> getInitialListOfServers() {
List<DiscoveryEnabledServer> servers = setZones(
this.list.getInitialListOfServers());
return servers;
}
@Override
public List<DiscoveryEnabledServer> getUpdatedListOfServers() {
List<DiscoveryEnabledServer> servers = setZones(
this.list.getUpdatedListOfServers());
return servers;
}
private List<DiscoveryEnabledServer> setZones(List<DiscoveryEnabledServer> servers) {
List<DiscoveryEnabledServer> result = new ArrayList<>();
boolean isSecure = this.ribbon.isSecure(true);
boolean shouldUseIpAddr = this.ribbon.isUseIPAddrForServer();
for (DiscoveryEnabledServer server : servers) {
result.add(new DomainExtractingServer(server, isSecure, shouldUseIpAddr,
this.approximateZoneFromHostname));
}
return result;
}
}
class DomainExtractingServer extends DiscoveryEnabledServer {
private String id;
@Override
public String getId() {
return id;
}
@Override
public void setId(String id) {
this.id = id;
}
DomainExtractingServer(DiscoveryEnabledServer server, boolean useSecurePort,
boolean useIpAddr, boolean approximateZoneFromHostname) {
// host and port are set in super()
super(server.getInstanceInfo(), useSecurePort, useIpAddr);
if (server.getInstanceInfo().getMetadata().containsKey("zone")) {
setZone(server.getInstanceInfo().getMetadata().get("zone"));
}
else if (approximateZoneFromHostname) {
setZone(ZoneUtils.extractApproximateZone(server.getHost()));
}
else {
setZone(server.getZone());
}
setId(extractId(server));
setAlive(server.isAlive());
setReadyToServe(server.isReadyToServe());
}
private String extractId(Server server) {
if (server instanceof DiscoveryEnabledServer) {
DiscoveryEnabledServer enabled = (DiscoveryEnabledServer) server;
InstanceInfo instance = enabled.getInstanceInfo();
if (instance.getMetadata().containsKey("instanceId")) {
return instance.getHostName() + ":"
+ instance.getMetadata().get("instanceId");
}
}
return super.getId();
}
}
这两个方法都是调用ServerList的对应方法,然后再调用那个setZones方法,将返回的对象转换成自定义的DomainExtractingServer对象(主要是新增了id、zone、isAliverFlag、readyToServer等属性)。
由于DomainExtractingServerList的构造函数传入的是DiscoveryEnabledNIWSServerList,因此在调用ServerList的方法时,实际调用的是实现类DiscoveryEnabledNIWSServerList,最终调用DiscoveryEnabledNIWSServerList种的obtainServersViaDiscovery来处理,在obtainServersViaDiscovery种,主要依靠从Eureka中获取的InstanceInfo对象的集合,循环集合,将InstanceInfo转换成DiscoveryEnabledServer对象返回。
@Override
public List<DiscoveryEnabledServer> getInitialListOfServers(){
return obtainServersViaDiscovery();
}
@Override
public List<DiscoveryEnabledServer> getUpdatedListOfServers(){
return obtainServersViaDiscovery();
}
private List<DiscoveryEnabledServer> obtainServersViaDiscovery() {
List<DiscoveryEnabledServer> serverList = new ArrayList<DiscoveryEnabledServer>();
if (eurekaClientProvider == null || eurekaClientProvider.get() == null) {
logger.warn("EurekaClient has not been initialized yet, returning an empty list");
return new ArrayList<DiscoveryEnabledServer>();
}
EurekaClient eurekaClient = eurekaClientProvider.get();
if (vipAddresses!=null){
for (String vipAddress : vipAddresses.split(",")) {
// if targetRegion is null, it will be interpreted as the same region of client
List<InstanceInfo> listOfInstanceInfo = eurekaClient.getInstancesByVipAddress(vipAddress, isSecure, targetRegion);
for (InstanceInfo ii : listOfInstanceInfo) {
if (ii.getStatus().equals(InstanceStatus.UP)) {
if(shouldUseOverridePort){
if(logger.isDebugEnabled()){
logger.debug("Overriding port on client name: " + clientName + " to " + overridePort);
}
// copy is necessary since the InstanceInfo builder just uses the original reference,
// and we don't want to corrupt the global eureka copy of the object which may be
// used by other clients in our system
InstanceInfo copy = new InstanceInfo(ii);
if(isSecure){
ii = new InstanceInfo.Builder(copy).setSecurePort(overridePort).build();
}else{
ii = new InstanceInfo.Builder(copy).setPort(overridePort).build();
}
}
DiscoveryEnabledServer des = createServer(ii, isSecure, shouldUseIpAddr);
serverList.add(des);
}
}
if (serverList.size()>0 && prioritizeVipAddressBasedServers){
break; // if the current vipAddress has servers, we dont use subsequent vipAddress based servers
}
}
}
return serverList;
}
(2)ServerListUpdater
通过上面的源码分析,我们知道了如何从Eureka注册中心获取服务清单,那么是如何更新本地的Server列表的呢?在前面说到DynamicServerListLoadBalancer源码中可以看到如下代码
volatile ServerList<T> serverListImpl;
volatile ServerListFilter<T> filter;
protected final ServerListUpdater.UpdateAction updateAction = new ServerListUpdater.UpdateAction() {
@Override
public void doUpdate() {
updateListOfServers();
}
};
protected volatile ServerListUpdater serverListUpdater;
@VisibleForTesting
public void updateListOfServers() {
List<T> servers = new ArrayList<T>();
if (serverListImpl != null) {
servers = serverListImpl.getUpdatedListOfServers();
LOGGER.debug("List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
if (filter != null) {
servers = filter.getFilteredListOfServers(servers);
LOGGER.debug("Filtered List of Servers for {} obtained from Discovery client: {}",
getIdentifier(), servers);
}
}
updateAllServerList(servers);
}
public void enableAndInitLearnNewServersFeature() {
LOGGER.info("Using serverListUpdater {}", serverListUpdater.getClass().getSimpleName());
serverListUpdater.start(updateAction);
}
private String getIdentifier() {
return this.getClientConfig().getClientName();
}
public void stopServerListRefreshing() {
if (serverListUpdater != null) {
serverListUpdater.stop();
}
}
@Monitor(name="LastUpdated", type=DataSourceType.INFORMATIONAL)
public String getLastUpdate() {
return serverListUpdater.getLastUpdate();
}
@Monitor(name="DurationSinceLastUpdateMs", type= DataSourceType.GAUGE)
public long getDurationSinceLastUpdateMs() {
return serverListUpdater.getDurationSinceLastUpdateMs();
}
@Monitor(name="NumUpdateCyclesMissed", type=DataSourceType.GAUGE)
public int getNumberMissedCycles() {
return serverListUpdater.getNumberMissedCycles();
}
@Monitor(name="NumThreads", type=DataSourceType.GAUGE)
public int getCoreThreads() {
return serverListUpdater.getCoreThreads();
}
从上述源码中不难看出,调用了ServerListUpdater的UpdateAction接口,其接口的实现是DynamicServerListLoadBalancer内部实现的方法updateListOfServers,从该方法中,可以看到,调用了ServerList接口的获取变更服务列表的getUpdatedListOfServers方法,然后又调用了ServerListFilter接口的getFilteredListOfServers方法,获取到最终的Server列表,最后调用updateAllServerList方法更新本地服务列表。
可以看下ServerListUpdater接口的内容:
public interface ServerListUpdater {
public interface UpdateAction {
void doUpdate();
}
//启动服务更新器,传入的UpdateAction对象为更新操作的具体实现
void start(UpdateAction updateAction);
//停止服务更新器
void stop();
//获取上一次更新的时间戳
String getLastUpdate();
//获取上一次更新到当前时间的时间间隔,单为毫秒
long getDurationSinceLastUpdateMs();
//获取错过更新的周期数
int getNumberMissedCycles();
//获取核心线程数
int getCoreThreads();
}
ServerListUpdater接口的实现类有两个,EurekaNotificationServerListUpdater和PollingServerListUpdater,其中,PollingServerListUpdater更新器是ServerListUpdater接口的默认实现类,那么就说明DynamicServerListLoadBalancer默认使用定时任务的方式进行服务列表的更新;EurekaNotificationServerListUpdater更新器也可以作为DynamicServerListLoadBalancer的更新器,其实现方式是需要利用Eureka的事件监听器来驱动服务列表更新。
可以看下默认更新器的start方法
@Override
public synchronized void start(final UpdateAction updateAction) {
if (isActive.compareAndSet(false, true)) {
final Runnable wrapperRunnable = new Runnable() {
@Override
public void run() {
if (!isActive.get()) {
if (scheduledFuture != null) {
scheduledFuture.cancel(true);
}
return;
}
try {
updateAction.doUpdate();
lastUpdated = System.currentTimeMillis();
} catch (Exception e) {
logger.warn("Failed one update cycle", e);
}
}
};
scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay(
wrapperRunnable,
initialDelayMs,
refreshIntervalMs,
TimeUnit.MILLISECONDS
);
} else {
logger.info("Already active, no-op");
}
}
通过上述源码可以看出,创建了一个延时定时执行的线程池,具体执行方法是updateAction.doUpdate();,也就是在DynamicServerListLoadBalancer中实现的doUpdate方法,上面已经说过。同时通过源码可以看到创建线程池时,initialDelayMs默认取值为1000,refreshIntervalMs默认取直为30*1000,说明,更新实例在初始化后延迟一秒开始执行,并且以每30秒执行一次的周期执行。
(3)ServerListFilter
在上一步中提到,现调用ServerListUpdater的getUpdatedListOfServers方法,然后又调用了ServerListFilter接口的getFilteredListOfServers方法,获取到最终的Server列表;ServerListFilter接口只有一个方法getFilteredListOfServers,用于过滤Server列表。
通过源码可以查看ServerListFilter接口的实现类及类继承关系
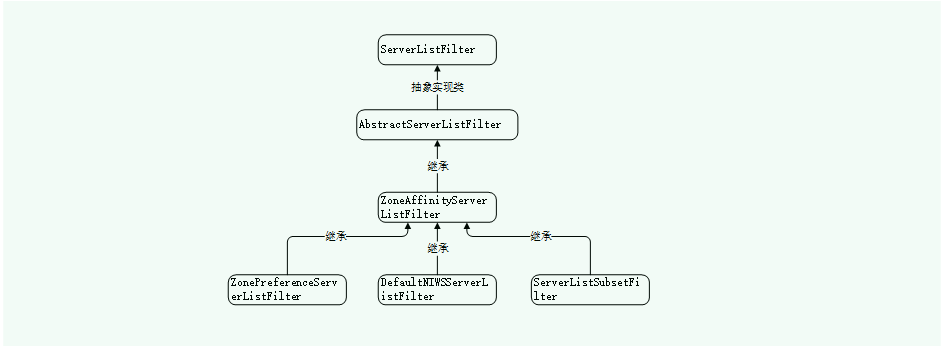
这些实现类中,除了ZonePreferenceServerListFilter的实现是SpringCloud Ribbon对于Netflix Ribbon的扩展实现外,其余的都是Netflix Ribbon中的原生实现。
a、AbstractServerListFilter
AbstractServerListFilter是一个抽象的过滤器,在这里就做了一件事,定义了过滤时需要的一个重要的LoadBalancerStatus对象(在之前已经说过,该对象存储了用于负载均衡器的一些属性和统计信息)
public abstract class AbstractServerListFilter<T extends Server> implements ServerListFilter<T> {
private volatile LoadBalancerStats stats;
public void setLoadBalancerStats(LoadBalancerStats stats) {
this.stats = stats;
}
public LoadBalancerStats getLoadBalancerStats() {
return stats;
}
}
b、ZoneAffinityServerListFilter
@Override
public List<T> getFilteredListOfServers(List<T> servers) {
if (zone != null && (zoneAffinity || zoneExclusive) && servers !=null && servers.size() > 0){
List<T> filteredServers = Lists.newArrayList(Iterables.filter(
servers, this.zoneAffinityPredicate.getServerOnlyPredicate()));
if (shouldEnableZoneAffinity(filteredServers)) {
return filteredServers;
} else if (zoneAffinity) {
overrideCounter.increment();
}
}
return servers;
}
private boolean shouldEnableZoneAffinity(List<T> filtered) {
if (!zoneAffinity && !zoneExclusive) {
return false;
}
if (zoneExclusive) {
return true;
}
LoadBalancerStats stats = getLoadBalancerStats();
if (stats == null) {
return zoneAffinity;
} else {
logger.debug("Determining if zone affinity should be enabled with given server list: {}", filtered);
ZoneSnapshot snapshot = stats.getZoneSnapshot(filtered);
double loadPerServer = snapshot.getLoadPerServer();
int instanceCount = snapshot.getInstanceCount();
int circuitBreakerTrippedCount = snapshot.getCircuitTrippedCount();
if (((double) circuitBreakerTrippedCount) / instanceCount >= blackOutServerPercentageThreshold.get()
|| loadPerServer >= activeReqeustsPerServerThreshold.get()
|| (instanceCount - circuitBreakerTrippedCount) < availableServersThreshold.get()) {
logger.debug("zoneAffinity is overriden. blackOutServerPercentage: {}, activeReqeustsPerServer: {}, availableServers: {}",
new Object[] {(double) circuitBreakerTrippedCount / instanceCount, loadPerServer, instanceCount - circuitBreakerTrippedCount});
return false;
} else {
return true;
}
}
}
通过实现接口的getFilteredListOfServers方法,可以看到,先使用Iterables.filter(servers, this.zoneAffinityPredicate.getServerOnlyPredicate())来进行服务实例和消费者的Zone进行比较,获得比较成功的Server集合,然后再调用shouldEnableZoneAffinity方法判断是否要启用“区域感知”的功能,如果开启,则直接返回过滤后的Server集合,否则返回全量Server集合。
在shouldEnableZoneAffinity方法中,使用了LoadBalancerStatus的getLoadPerServer方法来获取同区域实例的基础指标(包含实力数量、断路器断开数、活动请求数、实例平均负载等)根据一些列的算法与设置的阈值进行对比,如果满足条件,则不开启区域感知。这一实现主要为了解决如果集群出现区域故障时,仍可使用使用其他区域的实例进行正常的服务,从而达到集群的高可用。对源码中是否开启区域感知的条件解释如下:
circuitBreakerTrippedCount) / instanceCount >= blackOutServerPercentageThreshold.get():故障实例百分比(断路器断开数/实例数量),默认阈值0.8
loadPerServer >= activeReqeustsPerServerThreshold.get():实例平均负载,默认阈值0.6
(instanceCount - circuitBreakerTrippedCount) < availableServersThreshold.get():可用实例数(实例数量-断路器断开数),默认阈值2
c、DefaultNIWSServerListFilter
该过滤器完全继承自ZoneAffinityServerListFilter,没有任何自己的代码,是默认的NIWS(Netflix Internal Web Service)过滤器
d、ServerListSubsetFilter
该过滤器继承自ZoneAffinityServerListFilter类,查看其实现ServerListFilter方法getFilteredListOfServers,它适用于拥有大规模服务集群的系统因为它可以产生一个“区域感知”结果的子集列表,同时它还能够通过比较服务实例的通信失败数量和并发连接数来判断该服务是否健康来选择性地从服务实例列表中剔除那些不够健康的实例。可以看到,该过滤器的实现主要分为三步:
先调用父类ZoneAffinityServerListFilter的getFilteredListOfServers获取服务实例清单
从当前消费者消费者维护的实例中剔除那些相对不够健康的实例
不健康实例标准:
服务的并发数超过客户端配置的值(默认配置值为0)
服务实例的失败数超过客户端的配置值(默认配置值为0)
上述两笔剔除完毕后,剔除比例如果小于10%(默认值),则将剩余的实例按照健康状态排序,从最不健康的开始剔除,知道满足剔除10%
完成剔除后,清单已经少了至少10%的服务实例,最后通过随机的方式从候选清单中选一批实例加入到清单中,以保证服务实例子集和与原来的数量一致(默认20个)
@Override
public List<T> getFilteredListOfServers(List<T> servers) {
List<T> zoneAffinityFiltered = super.getFilteredListOfServers(servers);
Set<T> candidates = Sets.newHashSet(zoneAffinityFiltered);
Set<T> newSubSet = Sets.newHashSet(currentSubset);
LoadBalancerStats lbStats = getLoadBalancerStats();
for (T server: currentSubset) {
// this server is either down or out of service
if (!candidates.contains(server)) {
newSubSet.remove(server);
} else {
ServerStats stats = lbStats.getSingleServerStat(server);
// remove the servers that do not meet health criteria
if (stats.getActiveRequestsCount() > eliminationConnectionCountThreshold.get()
|| stats.getFailureCount() > eliminationFailureCountThreshold.get()) {
newSubSet.remove(server);
// also remove from the general pool to avoid selecting them again
candidates.remove(server);
}
}
}
int targetedListSize = sizeProp.get();
int numEliminated = currentSubset.size() - newSubSet.size();
int minElimination = (int) (targetedListSize * eliminationPercent.get());
int numToForceEliminate = 0;
if (targetedListSize < newSubSet.size()) {
// size is shrinking
numToForceEliminate = newSubSet.size() - targetedListSize;
} else if (minElimination > numEliminated) {
numToForceEliminate = minElimination - numEliminated;
}
if (numToForceEliminate > newSubSet.size()) {
numToForceEliminate = newSubSet.size();
}
if (numToForceEliminate > 0) {
List<T> sortedSubSet = Lists.newArrayList(newSubSet);
Collections.sort(sortedSubSet, this);
List<T> forceEliminated = sortedSubSet.subList(0, numToForceEliminate);
newSubSet.removeAll(forceEliminated);
candidates.removeAll(forceEliminated);
}
// after forced elimination or elimination of unhealthy instances,
// the size of the set may be less than the targeted size,
// then we just randomly add servers from the big pool
if (newSubSet.size() < targetedListSize) {
int numToChoose = targetedListSize - newSubSet.size();
candidates.removeAll(newSubSet);
if (numToChoose > candidates.size()) {
// Not enough healthy instances to choose, fallback to use the
// total server pool
candidates = Sets.newHashSet(zoneAffinityFiltered);
candidates.removeAll(newSubSet);
}
List<T> chosen = randomChoose(Lists.newArrayList(candidates), numToChoose);
for (T server: chosen) {
newSubSet.add(server);
}
}
currentSubset = newSubSet;
return Lists.newArrayList(newSubSet);
}
e、ZonePreferenceServerListFilter
SpringCloud整合时新增的过滤器,该过滤器继承自ZoneAffinityServerListFilter,若使用SpringCloud整合Eureka和Ribbon,该过滤器是默认过滤器,它实现了通过配置或者Eureka实例元数据区域(Zone)来过滤出同区域服务实例。
如下面源码所示,首先使用ZoneAffinityServerListFilter获取所有服务实例,然后使用消费者预设立的Zone进行过滤,如果过滤为空,就直接返回父类获取的实例集合(所有实例),如果不为空,就返回过滤后的实例集合。
@Override
public List<Server> getFilteredListOfServers(List<Server> servers) {
List<Server> output = super.getFilteredListOfServers(servers);
if (this.zone != null && output.size() == servers.size()) {
List<Server> local = new ArrayList<>();
for (Server server : output) {
if (this.zone.equalsIgnoreCase(server.getZone())) {
local.add(server);
}
}
if (!local.isEmpty()) {
return local;
}
}
return output;
}
4、ZoneAwareLoadBalancer
ZoneAwareLoadBalancer负载均衡是对DynamicServerListLoadBalancer负载均衡器的扩展。在DynamicServerListLoadBalancer负载均衡器中,并没有重写选择具体服务实例的chooseServer方法,所以它会采用BaseLoadBalancer中实现的算法,使用RoundRobinRule规则,轮询选择调用的实例。该规则没有区域的概念,他会把所有的实例看成一个Zone,这样就会周期性的跨域访问。由于跨域访问会产生更高的延迟,这些实例主要是防止区域性故障而实现高可用目的使用的,而不应该是常规访问,所以在多区域部署的情况下一定有性能问题,那么ZoneAwareLoadBalancer是如何避免这个问题呢?
首先,在ZoneAwareLoadBalancer负载均衡器中并没有重写setServerList方法,说明实现服务实例清单更新主逻辑没有变化,但是我们发现他重写了父类的setServerListForZones方法,先看父类该方法的调用链,可见在setServerList方法中,最后调用了setServerListForZones方法,父类中的setServerListForZones是将一个key为Zone,value为Server集合的map存入了LoadBalancerStatus中。
@Override
public void setServersList(List lsrv) {
super.setServersList(lsrv);
List<T> serverList = (List<T>) lsrv;
Map<String, List<Server>> serversInZones = new HashMap<String, List<Server>>();
for (Server server : serverList) {
// make sure ServerStats is created to avoid creating them on hot
// path
getLoadBalancerStats().getSingleServerStat(server);
String zone = server.getZone();
if (zone != null) {
zone = zone.toLowerCase();
List<Server> servers = serversInZones.get(zone);
if (servers == null) {
servers = new ArrayList<Server>();
serversInZones.put(zone, servers);
}
servers.add(server);
}
}
setServerListForZones(serversInZones);
}
protected void setServerListForZones(
Map<String, List<Server>> zoneServersMap) {
LOGGER.debug("Setting server list for zones: {}", zoneServersMap);
getLoadBalancerStats().updateZoneServerMapping(zoneServersMap);
}
那么在ZoneAwareLoadBalancer负载均衡器中,对于setServerListForZones方法的重写源码如下面所示:
@Override
protected void setServerListForZones(Map<String, List<Server>> zoneServersMap) {
super.setServerListForZones(zoneServersMap);
if (balancers == null) {
balancers = new ConcurrentHashMap<String, BaseLoadBalancer>();
}
for (Map.Entry<String, List<Server>> entry: zoneServersMap.entrySet()) {
String zone = entry.getKey().toLowerCase();
getLoadBalancer(zone).setServersList(entry.getValue());
}
// check if there is any zone that no longer has a server
// and set the list to empty so that the zone related metrics does not
// contain stale data
for (Map.Entry<String, BaseLoadBalancer> existingLBEntry: balancers.entrySet()) {
if (!zoneServersMap.keySet().contains(existingLBEntry.getKey())) {
existingLBEntry.getValue().setServersList(Collections.emptyList());
}
}
}
@VisibleForTesting
BaseLoadBalancer getLoadBalancer(String zone) {
zone = zone.toLowerCase();
BaseLoadBalancer loadBalancer = balancers.get(zone);
if (loadBalancer == null) {
// We need to create rule object for load balancer for each zone
IRule rule = cloneRule(this.getRule());
loadBalancer = new BaseLoadBalancer(this.getName() + "_" + zone, rule, this.getLoadBalancerStats());
BaseLoadBalancer prev = balancers.putIfAbsent(zone, loadBalancer);
if (prev != null) {
loadBalancer = prev;
}
}
return loadBalancer;
}
private IRule cloneRule(IRule toClone) {
IRule rule;
if (toClone == null) {
rule = new AvailabilityFilteringRule();
} else {
String ruleClass = toClone.getClass().getName();
try {
rule = (IRule) ClientFactory.instantiateInstanceWithClientConfig(ruleClass, this.getClientConfig());
} catch (Exception e) {
throw new RuntimeException("Unexpected exception creating rule for ZoneAwareLoadBalancer", e);
}
}
return rule;
}
从上述源码可以看出,在该实现类中创建了一个ConcurrentHashMap类型的balancers对象,它用来存储每个Zone区域对应的负载均衡器,而具体的创建负载均衡器则是调用getLoadBalancer方法来创建的,在该方法中,同时会创建其Rule规则,如果没有,则默认创建使用AvailabilityFilteringRule。在创建完LoadBalancer后,立马调用setServerList方法为其设置对应Zone区域的实例清单,第二个循环是Zone区域清单的检查,看看是否有Zone区域下已经没有实例,是的话,将Zone区域中对应的实例列表清空。
在了解了该负载均衡是如何扩展服务实例清单的实现后,接下来可以看下它是如何挑选服务实例的,那么就要看chooseServer方法:
@Override
public Server chooseServer(Object key) {
if (!ENABLED.get() || getLoadBalancerStats().getAvailableZones().size() <= 1) {
logger.debug("Zone aware logic disabled or there is only one zone");
return super.chooseServer(key);
}
Server server = null;
try {
LoadBalancerStats lbStats = getLoadBalancerStats();
Map<String, ZoneSnapshot> zoneSnapshot = ZoneAvoidanceRule.createSnapshot(lbStats);
logger.debug("Zone snapshots: {}", zoneSnapshot);
if (triggeringLoad == null) {
triggeringLoad = DynamicPropertyFactory.getInstance().getDoubleProperty(
"ZoneAwareNIWSDiscoveryLoadBalancer." + this.getName() + ".triggeringLoadPerServerThreshold", 0.2d);
}
if (triggeringBlackoutPercentage == null) {
triggeringBlackoutPercentage = DynamicPropertyFactory.getInstance().getDoubleProperty(
"ZoneAwareNIWSDiscoveryLoadBalancer." + this.getName() + ".avoidZoneWithBlackoutPercetage", 0.99999d);
}
Set<String> availableZones = ZoneAvoidanceRule.getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get());
logger.debug("Available zones: {}", availableZones);
if (availableZones != null && availableZones.size() < zoneSnapshot.keySet().size()) {
String zone = ZoneAvoidanceRule.randomChooseZone(zoneSnapshot, availableZones);
logger.debug("Zone chosen: {}", zone);
if (zone != null) {
BaseLoadBalancer zoneLoadBalancer = getLoadBalancer(zone);
server = zoneLoadBalancer.chooseServer(key);
}
}
} catch (Exception e) {
logger.error("Error choosing server using zone aware logic for load balancer={}", name, e);
}
if (server != null) {
return server;
} else {
logger.debug("Zone avoidance logic is not invoked.");
return super.chooseServer(key);
}
}
从上述源码中可以看到,首先会判断如果当前负载均衡器中维护的Zone区域小于1(getLoadBalancerStats().getAvailableZones().size() <= 1),则不执行选择策略,直接使用父类的实现。
如果当前负载均衡器中维护的Zone区域大于1,首先调用ZoneAvoidanceRule.createSnapshot(lbStats);方法获取Zone对应快照的map集合,然后调用ZoneAvoidanceRule.getAvailableZones来获取可用的Zone集合。当获取的可用Zone集合不为空且数量小于总的Zone数量时,调用ZoneAvoidanceRule.randomChooseZone随机获取一个Zone区域;在确定了Zone区域后,则调用getLoadBalancer来获取该区域对应的负载均衡器(同时会获得负载均衡策略Rule),最终调用负载均衡器的chooseServer方法来挑选实例。
这里单独说一下调用ZoneAvoidanceRule.getAvailableZones来获取可用的Zone集合
public static Set<String> getAvailableZones(
Map<String, ZoneSnapshot> snapshot, double triggeringLoad,
double triggeringBlackoutPercentage) {
if (snapshot.isEmpty()) {
return null;
}
Set<String> availableZones = new HashSet<String>(snapshot.keySet());
if (availableZones.size() == 1) {
return availableZones;
}
Set<String> worstZones = new HashSet<String>();
double maxLoadPerServer = 0;
boolean limitedZoneAvailability = false;
for (Map.Entry<String, ZoneSnapshot> zoneEntry : snapshot.entrySet()) {
String zone = zoneEntry.getKey();
ZoneSnapshot zoneSnapshot = zoneEntry.getValue();
int instanceCount = zoneSnapshot.getInstanceCount();
if (instanceCount == 0) {
availableZones.remove(zone);
limitedZoneAvailability = true;
} else {
double loadPerServer = zoneSnapshot.getLoadPerServer();
if (((double) zoneSnapshot.getCircuitTrippedCount())
/ instanceCount >= triggeringBlackoutPercentage
|| loadPerServer < 0) {
availableZones.remove(zone);
limitedZoneAvailability = true;
} else {
if (Math.abs(loadPerServer - maxLoadPerServer) < 0.000001d) {
// they are the same considering double calculation
// round error
worstZones.add(zone);
} else if (loadPerServer > maxLoadPerServer) {
maxLoadPerServer = loadPerServer;
worstZones.clear();
worstZones.add(zone);
}
}
}
}
if (maxLoadPerServer < triggeringLoad && !limitedZoneAvailability) {
// zone override is not needed here
return availableZones;
}
String zoneToAvoid = randomChooseZone(snapshot, worstZones);
if (zoneToAvoid != null) {
availableZones.remove(zoneToAvoid);
}
return availableZones;
}
通过上述源码可以看到,首先,会剔除以下Zone区域:所属实例为0的Zone区域、Zone区域内平均负载为0的Zone区域、故障率大于等于阈值(断路器断开时/实例数)(默认值0.99999)
然后根据Zone区域的实例平均负载计算出最差的Zone区域(实例平均负载最高的Zone区域)
如果上述过程中没有剔除的Zone,同时实例最大平均负载小于阈值(默认20%),就直接返回所有Zone区域为可用区域,否则,从最坏的Zone区域中随机选择一个,将它从Zzone区域中剔除。