Spark 基础入门,集群搭建以及Spark Shell
主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践。






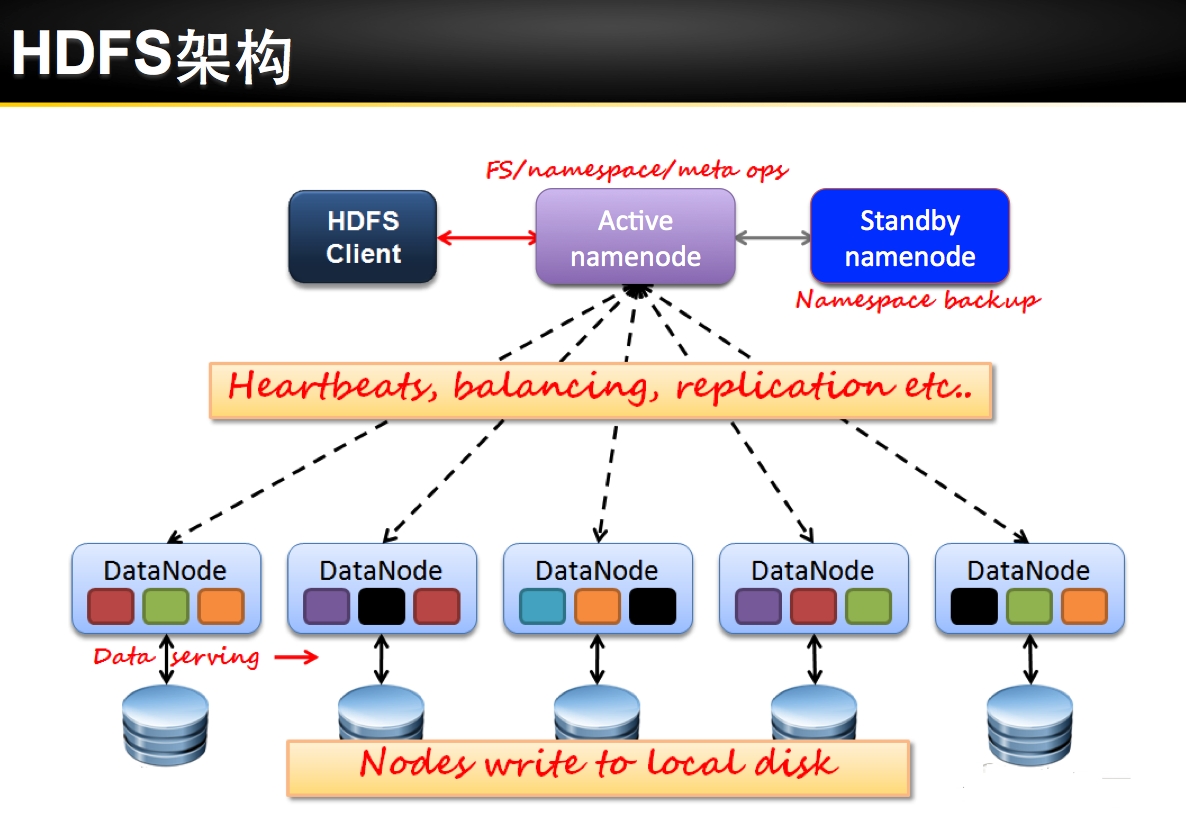

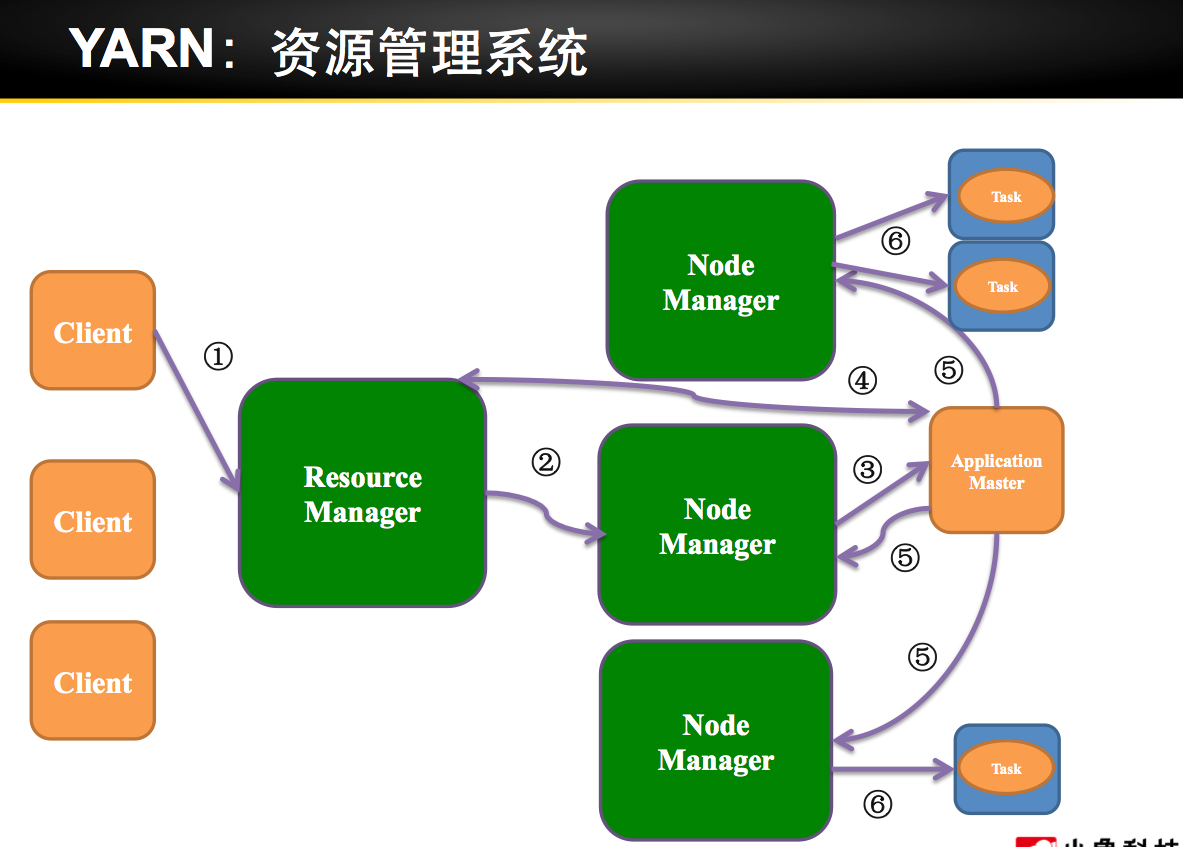







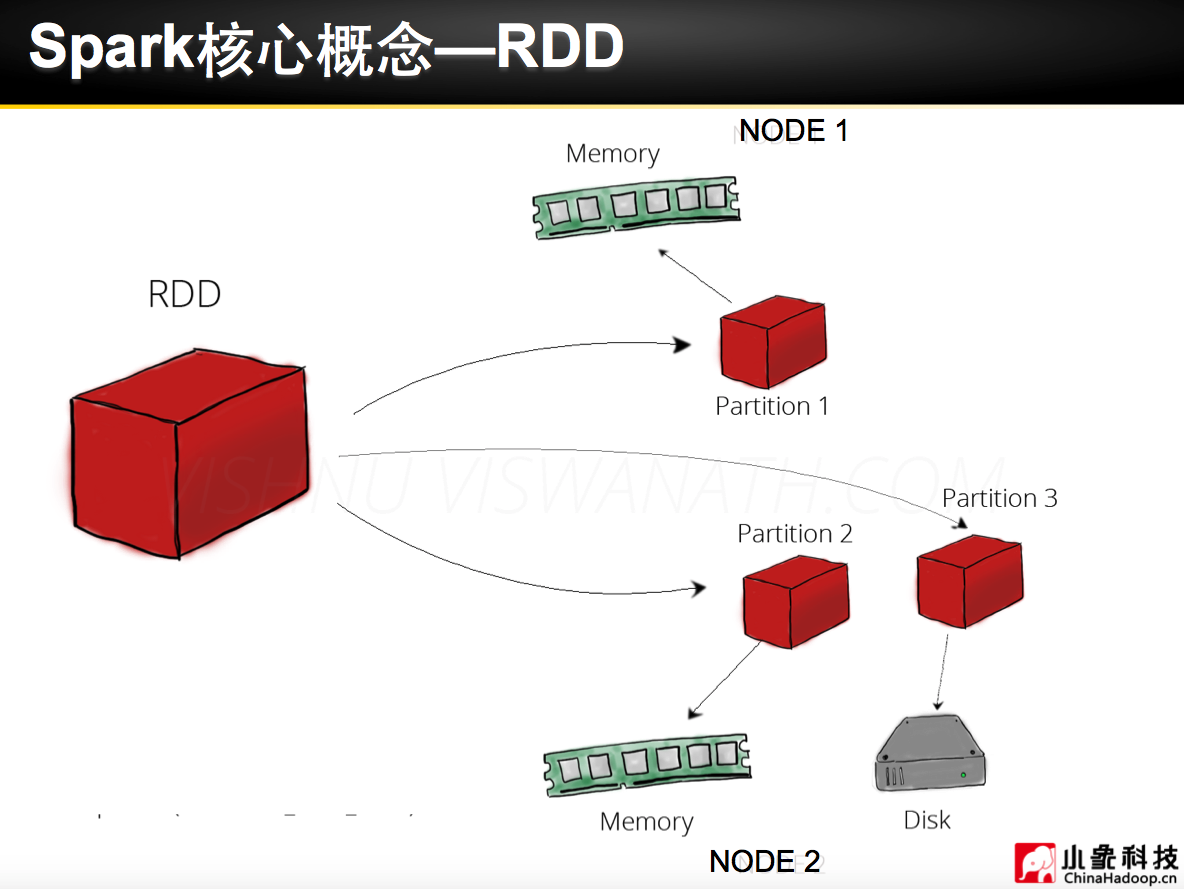

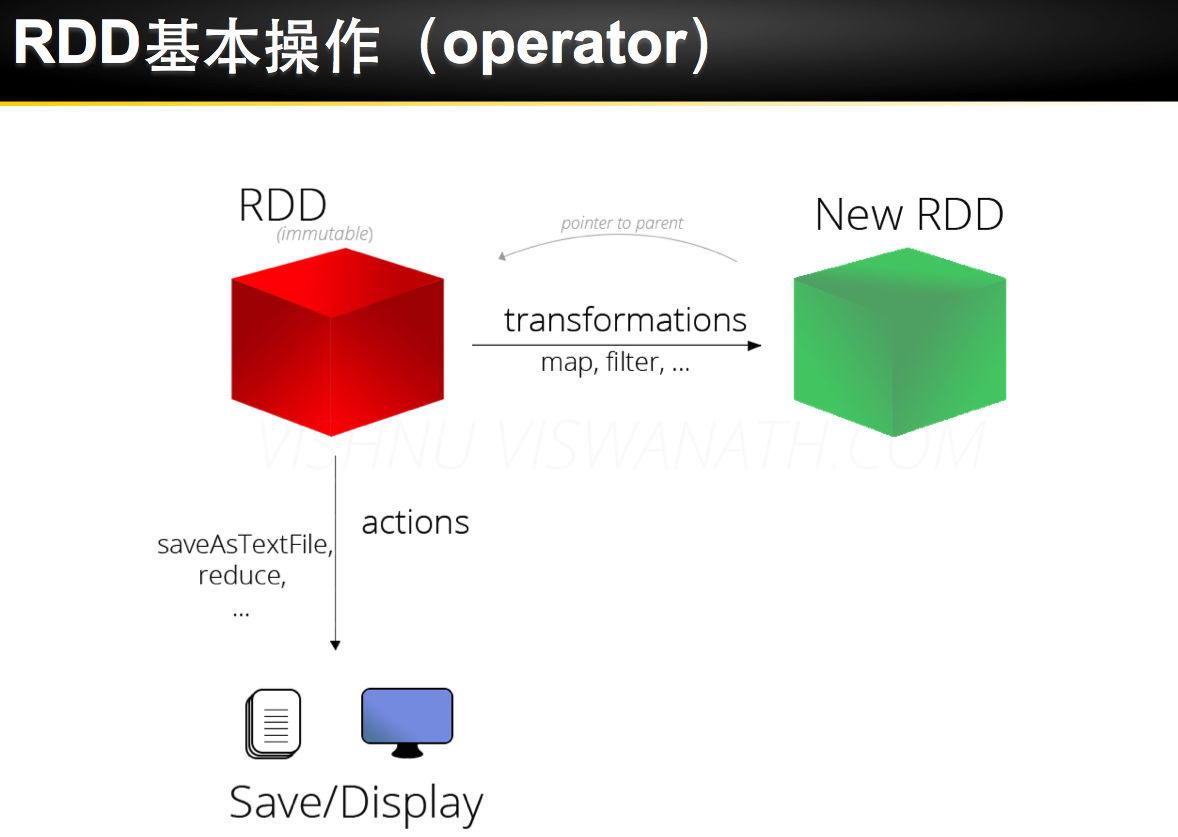

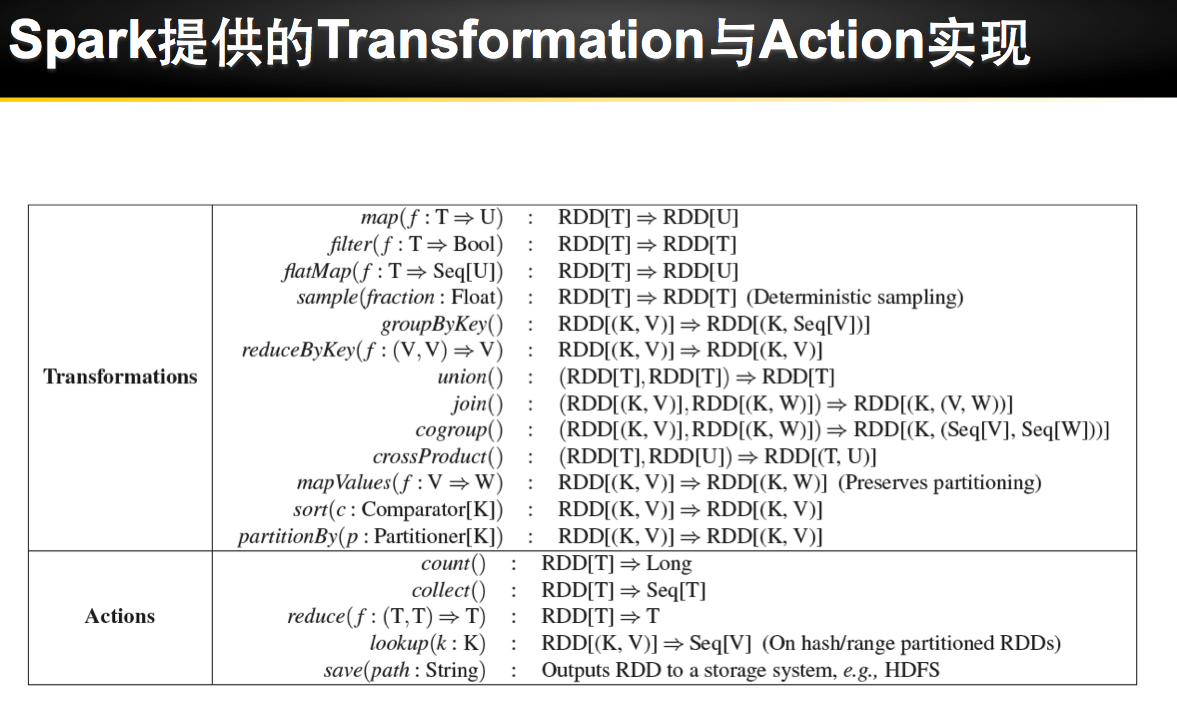






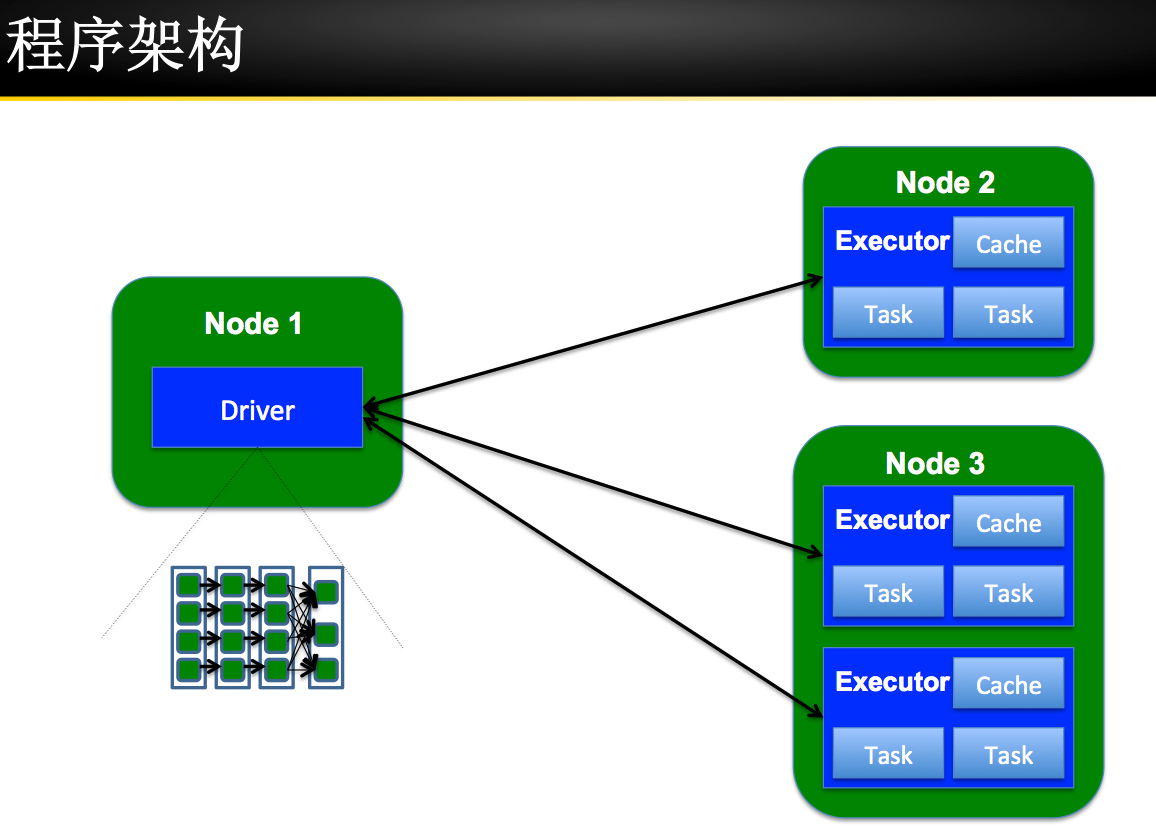


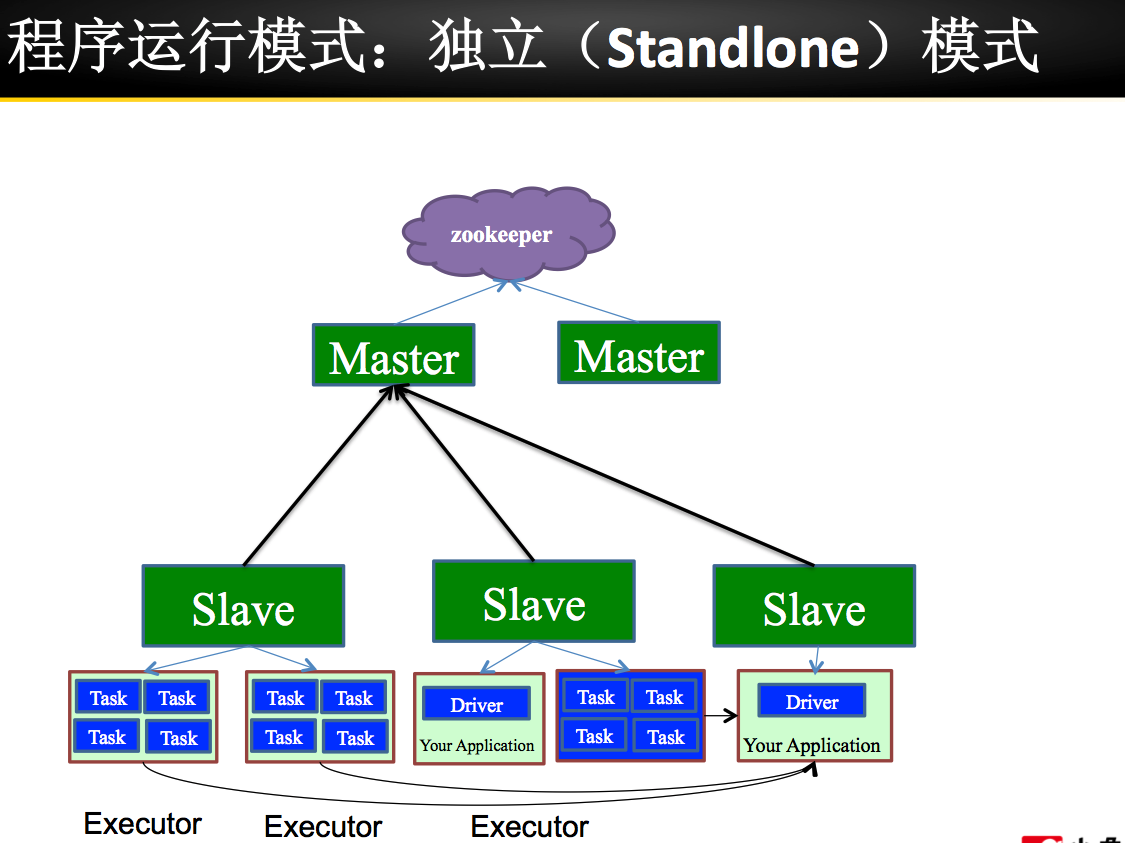
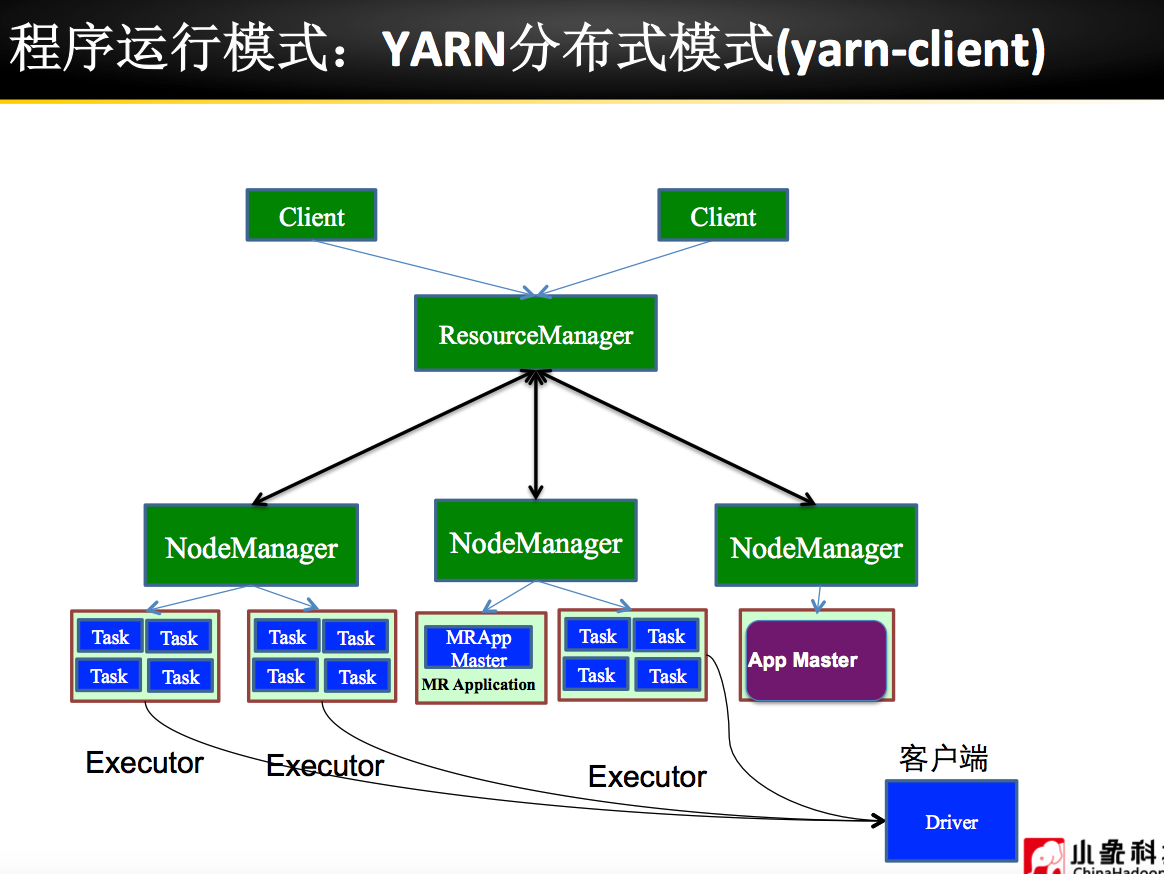
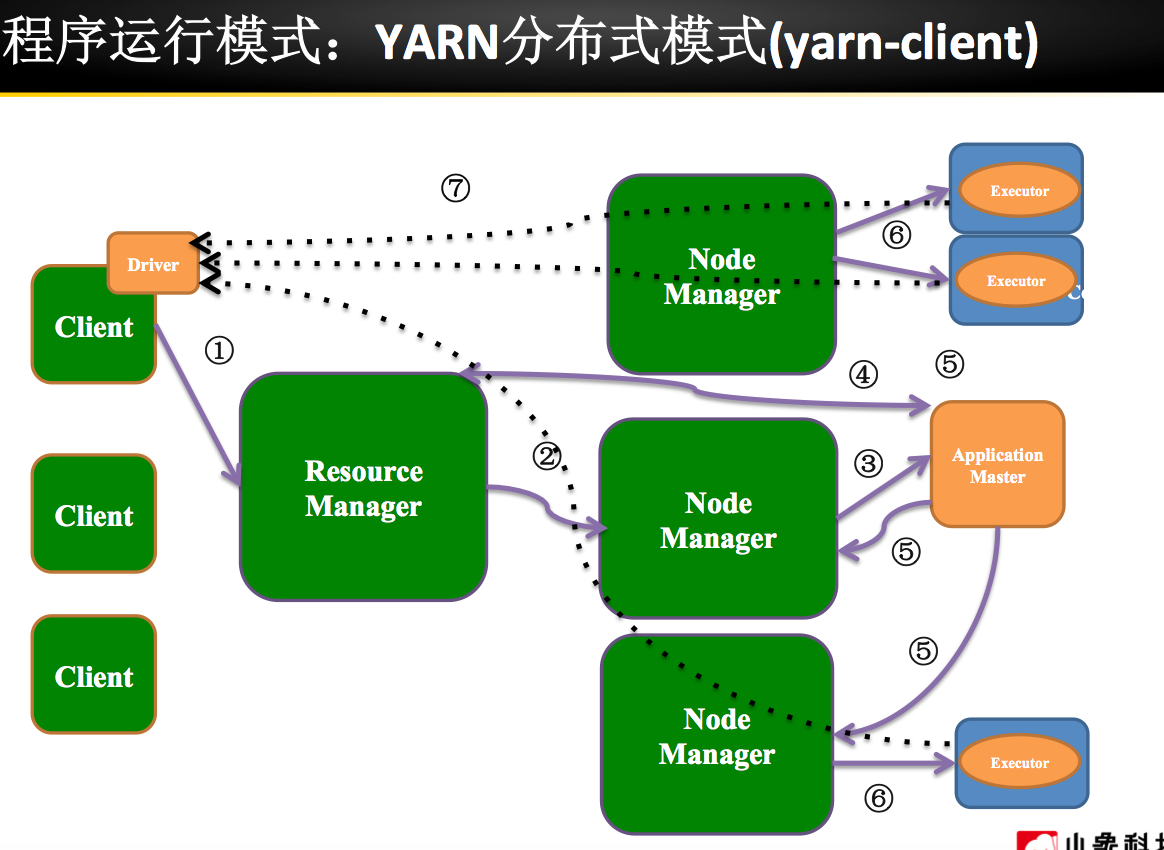





Spark 安装部署


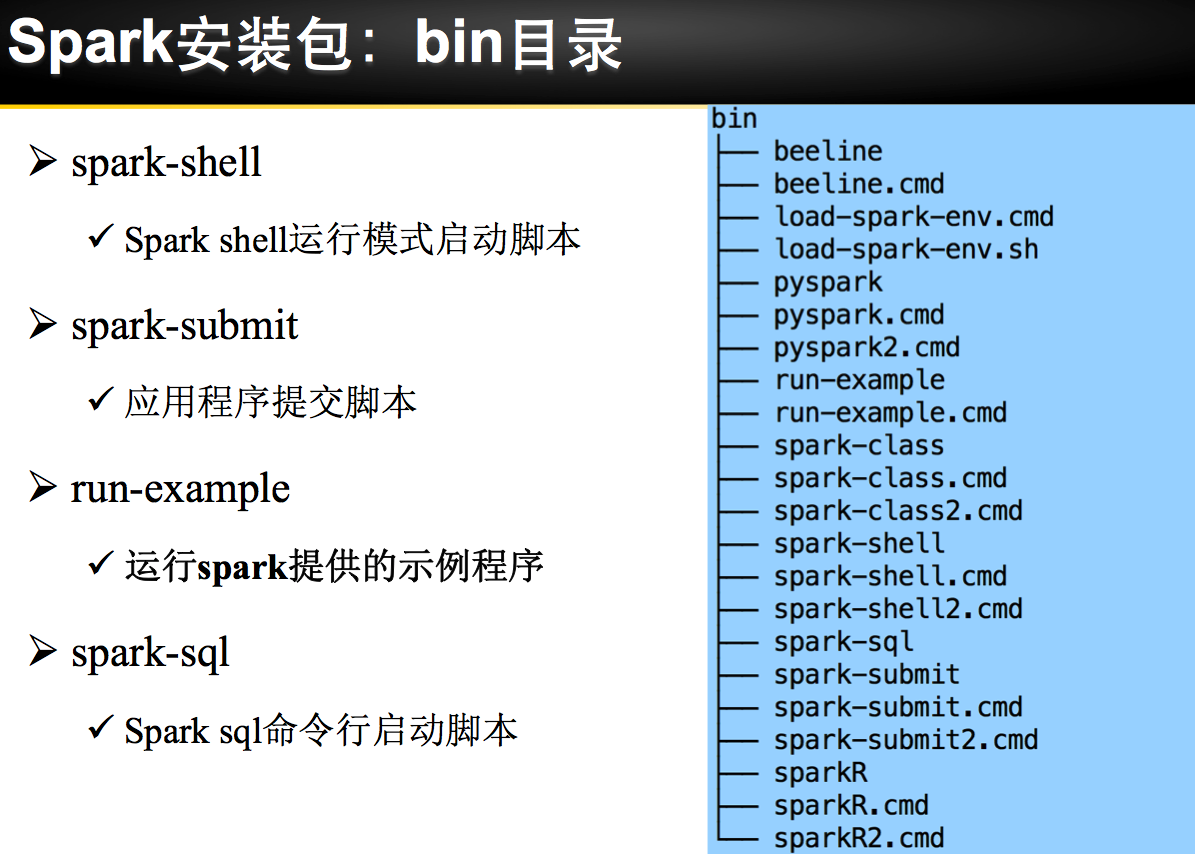
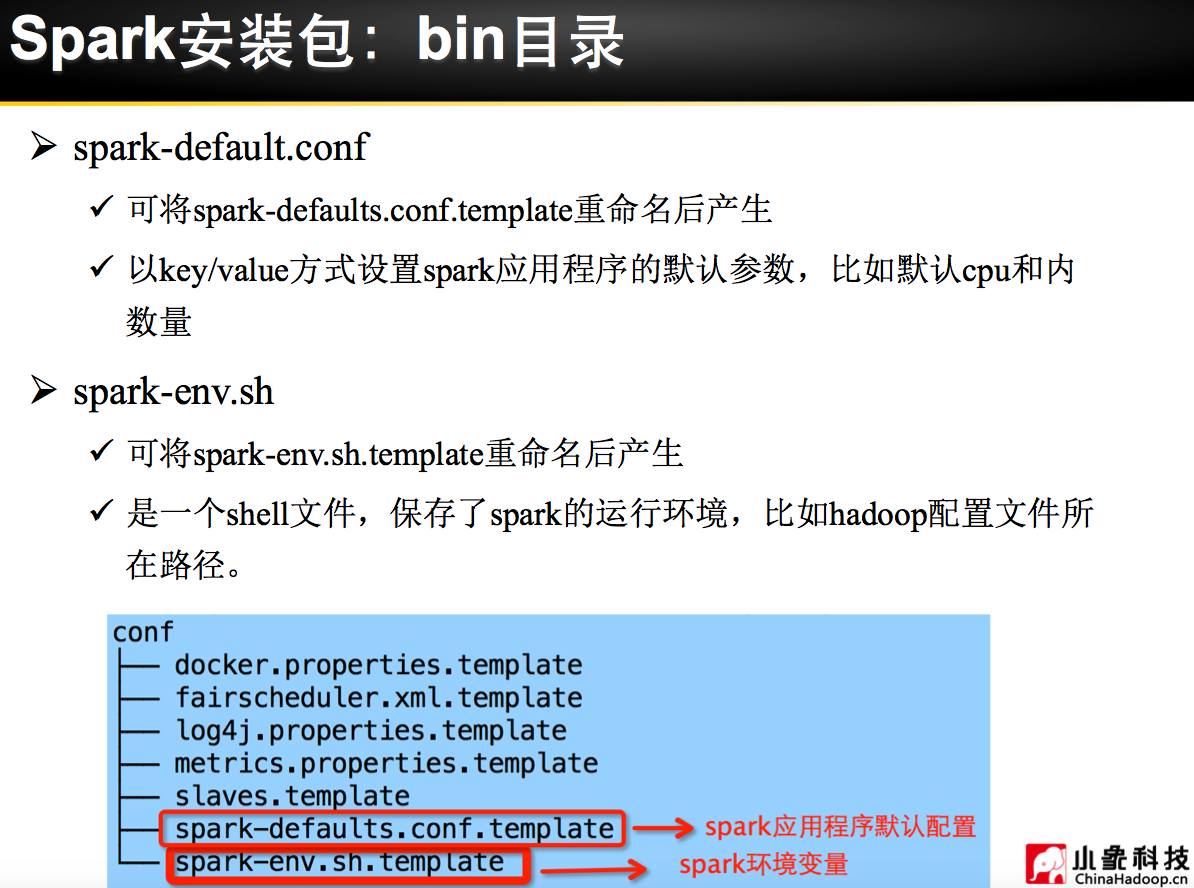



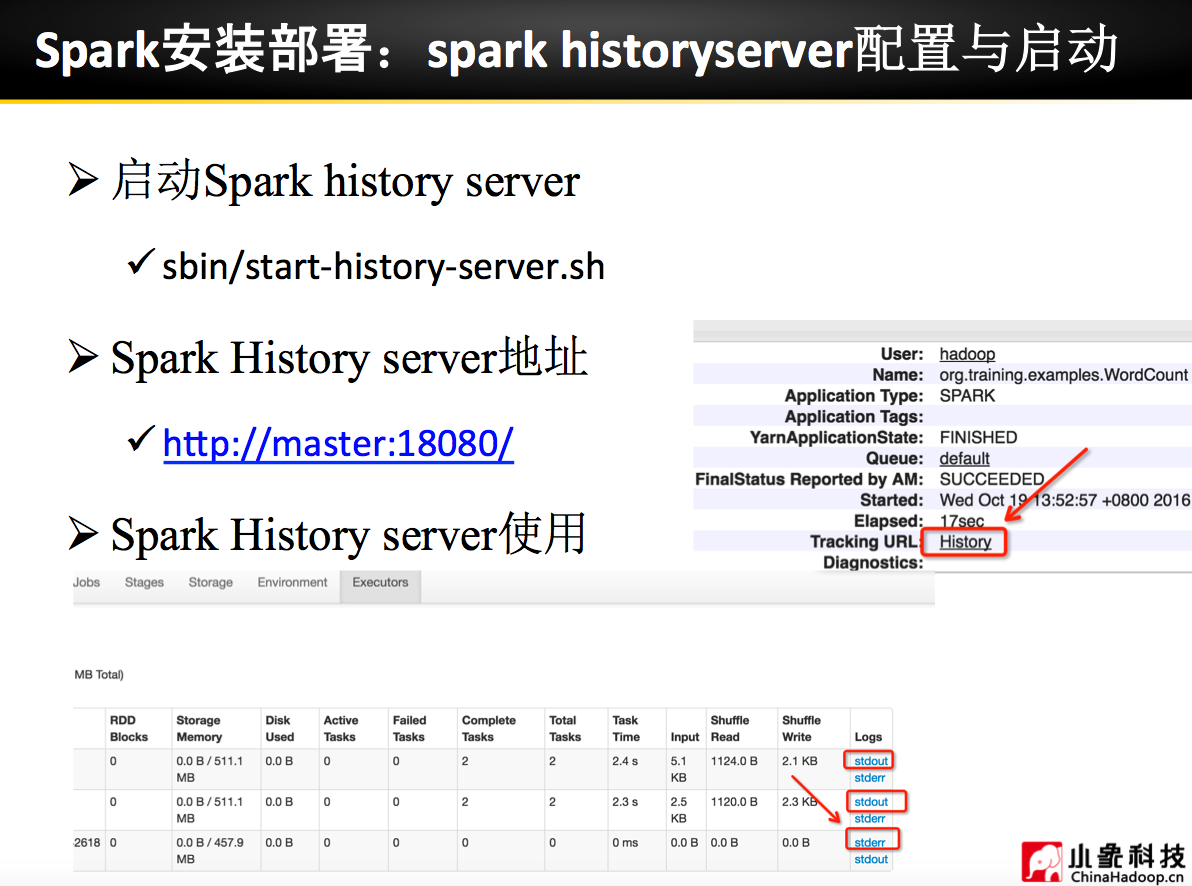



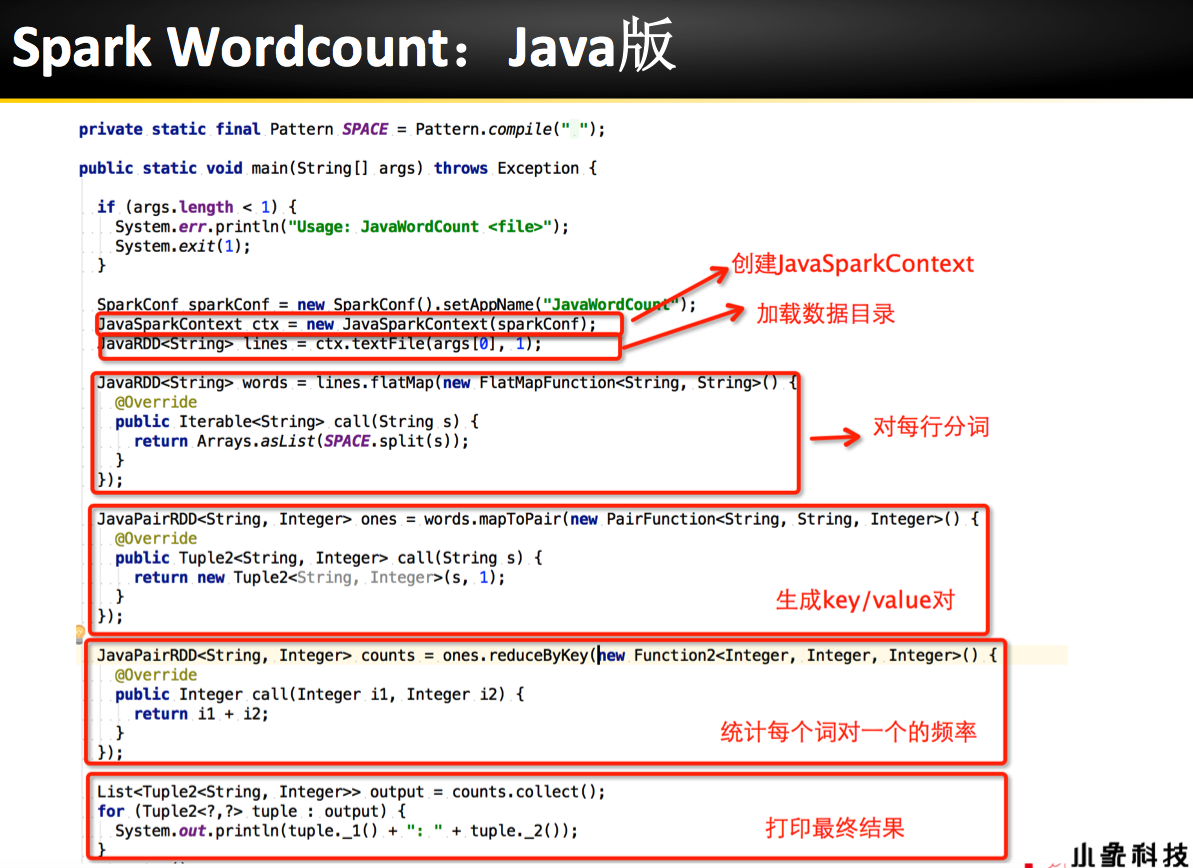





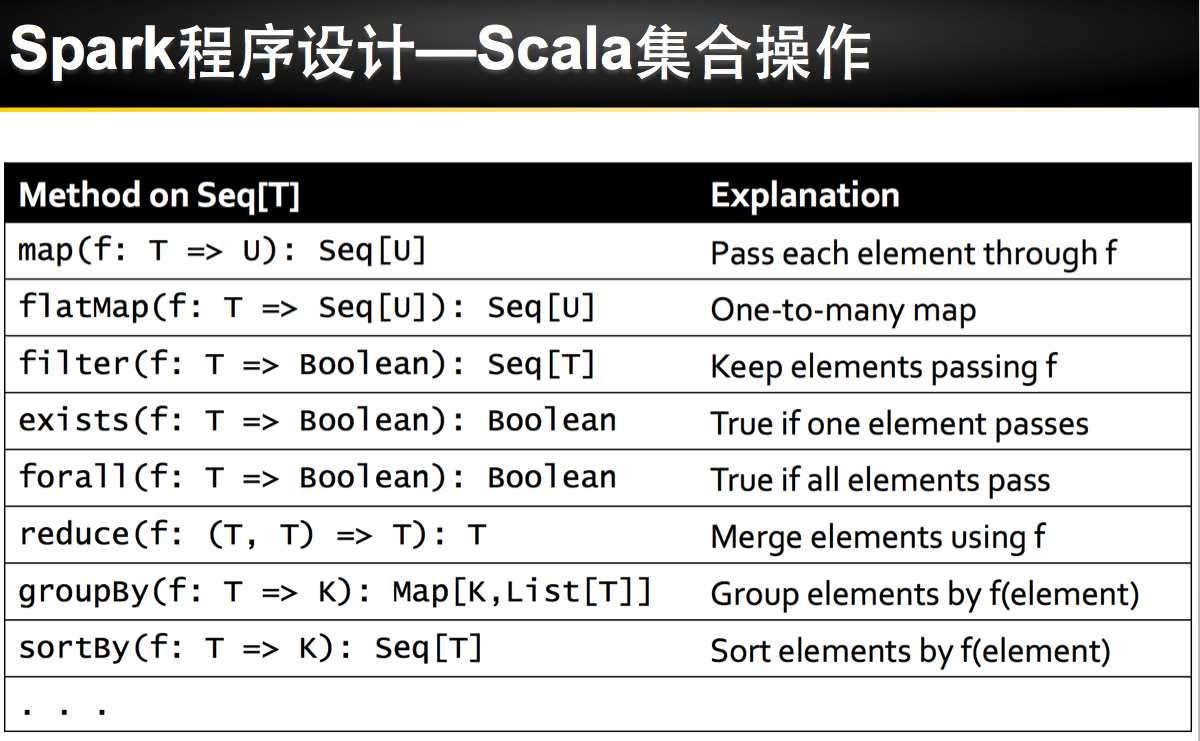

理论已经了解的差不多了,接下来是实际动手实验:
练习1 利用Spark Shell(本机模式) 完成WordCount
spark-shell 进行Spark-shell本机模式

第一步:通过文件方式导入数据
scala> val rdd1 = sc.textFile("file:///tmp/wordcount.txt")
rdd1: org.apache.spark.rdd.RDD[String] = file:///tmp/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> rdd1.count
res1: Long = 3

第二步:利用flatmap(_.split(" ")) 进行分词操作
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:26
scala> rdd2.count
res2: Long = 8
scala> rdd2.take
take takeAsync takeOrdered takeSample
scala> rdd2.take(8)
res3: Array[String] = Array(hello, world, spark, world, hello, spark, hadoop, great)
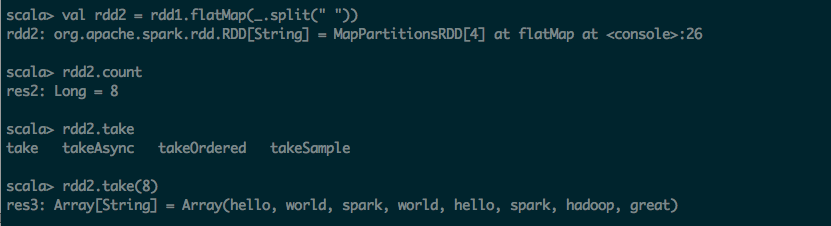
第三步:利用map 转化为KV的形式
scala> val kvrdd1 = rdd2.map(x => (x,1))
kvrdd1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:28
scala> kvrdd1.count
res4: Long = 8
scala> kvrdd1.take(8)
res5: Array[(String, Int)] = Array((hello,1), (world,1), (spark,1), (world,1), (hello,1), (spark,1), (hadoop,1), (great,1))

第四步:把KV的map进行ReduceByKey操作
scala> val resultRdd1 = kvrdd1.reduceByKey(_+_)
resultRdd1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at <console>:30
scala> resultRdd1.count
res6: Long = 5
scala> resultRdd1.take(5)
res7: Array[(String, Int)] = Array((hello,2), (world,2), (spark,2), (hadoop,1), (great,1))

第五步:将结果保持到文件之中
scala> resultRdd1.saveAsTextFile("file:///tmp/output1")

练习2 利用Spark Shell(Yarn Client模式) 完成WordCount
spark-shell --master yarn-client 启动Spark-shell Yarn Client模式

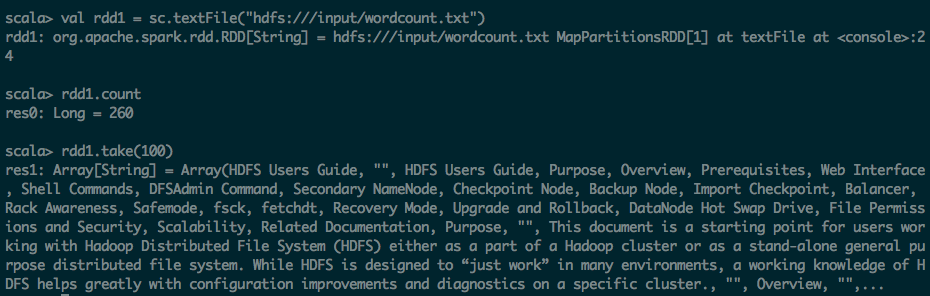
第一步:通过文件方式导入数据
scala> val rdd1 = sc.textFile("hdfs:///input/wordcount.txt")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs:///input/wordcount.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> rdd1.count
res0: Long = 260
scala> rdd1.take(100)
res1: Array[String] = Array(HDFS Users Guide, "", HDFS Users Guide, Purpose, Overview, Prerequisites, Web Interface, Shell Commands, DFSAdmin Command, Secondary NameNode, Checkpoint Node, Backup Node, Import Checkpoint, Balancer, Rack Awareness, Safemode, fsck, fetchdt, Recovery Mode, Upgrade and Rollback, DataNode Hot Swap Drive, File Permissions and Security, Scalability, Related Documentation, Purpose, "", This document is a starting point for users working with Hadoop Distributed File System (HDFS) either as a part of a Hadoop cluster or as a stand-alone general purpose distributed file system. While HDFS is designed to “just work” in many environments, a working knowledge of HDFS helps greatly with configuration improvements and diagnostics on a specific cluster., "", Overview, "",...
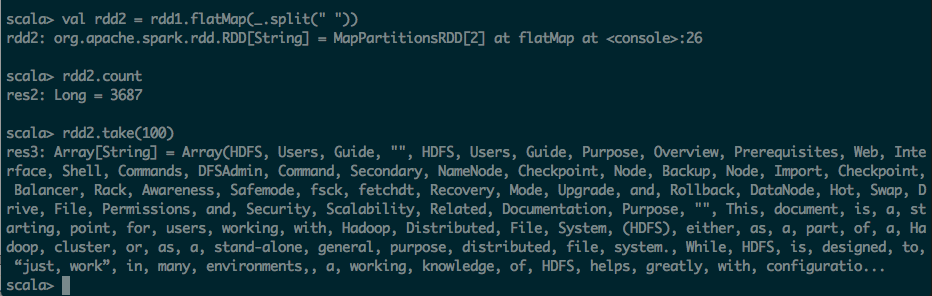
第二步:利用flatmap(_.split(" ")) 进行分词操作
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:26
scala> rdd2.count
res2: Long = 3687
scala> rdd2.take(100)
res3: Array[String] = Array(HDFS, Users, Guide, "", HDFS, Users, Guide, Purpose, Overview, Prerequisites, Web, Interface, Shell, Commands, DFSAdmin, Command, Secondary, NameNode, Checkpoint, Node, Backup, Node, Import, Checkpoint, Balancer, Rack, Awareness, Safemode, fsck, fetchdt, Recovery, Mode, Upgrade, and, Rollback, DataNode, Hot, Swap, Drive, File, Permissions, and, Security, Scalability, Related, Documentation, Purpose, "", This, document, is, a, starting, point, for, users, working, with, Hadoop, Distributed, File, System, (HDFS), either, as, a, part, of, a, Hadoop, cluster, or, as, a, stand-alone, general, purpose, distributed, file, system., While, HDFS, is, designed, to, “just, work”, in, many, environments,, a, working, knowledge, of, HDFS, helps, greatly, with, configuratio...
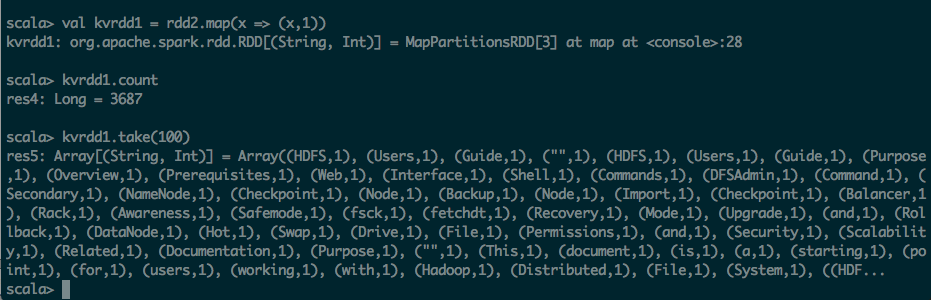
第三步:利用map 转化为KV的形式
scala> val kvrdd1 = rdd2.map(x => (x,1))
kvrdd1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:28
scala> kvrdd1.count
res4: Long = 3687
scala> kvrdd1.take(100)
res5: Array[(String, Int)] = Array((HDFS,1), (Users,1), (Guide,1), ("",1), (HDFS,1), (Users,1), (Guide,1), (Purpose,1), (Overview,1), (Prerequisites,1), (Web,1), (Interface,1), (Shell,1), (Commands,1), (DFSAdmin,1), (Command,1), (Secondary,1), (NameNode,1), (Checkpoint,1), (Node,1), (Backup,1), (Node,1), (Import,1), (Checkpoint,1), (Balancer,1), (Rack,1), (Awareness,1), (Safemode,1), (fsck,1), (fetchdt,1), (Recovery,1), (Mode,1), (Upgrade,1), (and,1), (Rollback,1), (DataNode,1), (Hot,1), (Swap,1), (Drive,1), (File,1), (Permissions,1), (and,1), (Security,1), (Scalability,1), (Related,1), (Documentation,1), (Purpose,1), ("",1), (This,1), (document,1), (is,1), (a,1), (starting,1), (point,1), (for,1), (users,1), (working,1), (with,1), (Hadoop,1), (Distributed,1), (File,1), (System,1), ((HDF...
第四步:把KV的map进行ReduceByKey操作
scala> var resultRdd1 = kvrdd1.reduce
reduce reduceByKey reduceByKeyLocally
scala> var resultRdd1 = kvrdd1.reduceByKey
reduceByKey reduceByKeyLocally
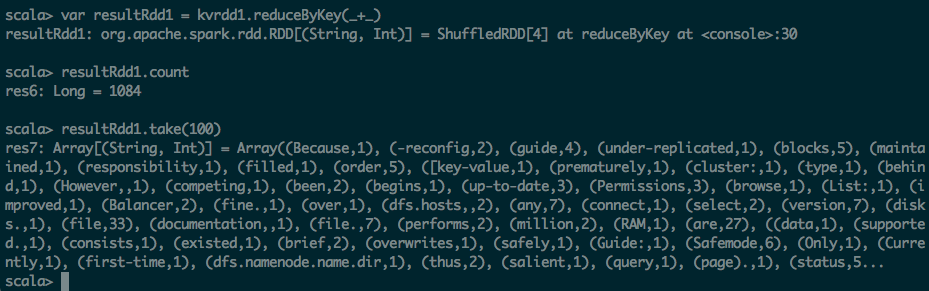
scala> var resultRdd1 = kvrdd1.reduceByKey(_+_)
resultRdd1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:30
scala> resultRdd1.count
res6: Long = 1084
scala> resultRdd1.take(100)
res7: Array[(String, Int)] = Array((Because,1), (-reconfig,2), (guide,4), (under-replicated,1), (blocks,5), (maintained,1), (responsibility,1), (filled,1), (order,5), ([key-value,1), (prematurely,1), (cluster:,1), (type,1), (behind,1), (However,,1), (competing,1), (been,2), (begins,1), (up-to-date,3), (Permissions,3), (browse,1), (List:,1), (improved,1), (Balancer,2), (fine.,1), (over,1), (dfs.hosts,,2), (any,7), (connect,1), (select,2), (version,7), (disks.,1), (file,33), (documentation,,1), (file.,7), (performs,2), (million,2), (RAM,1), (are,27), ((data,1), (supported.,1), (consists,1), (existed,1), (brief,2), (overwrites,1), (safely,1), (Guide:,1), (Safemode,6), (Only,1), (Currently,1), (first-time,1), (dfs.namenode.name.dir,1), (thus,2), (salient,1), (query,1), (page).,1), (status,5...
第五步:将结果保持到HDFS文件之中
scala> resultRdd1.saveAsTextFile("hdfs:///output/wordcount1")

localhost:tmp jonsonli$ hadoop fs -ls /output/wordcount1
17/05/13 17:49:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
-rw-r--r-- 1 jonsonli supergroup 0 2017-05-13 17:47 /output/wordcount1/_SUCCESS
-rw-r--r-- 1 jonsonli supergroup 6562 2017-05-13 17:47 /output/wordcount1/part-00000
-rw-r--r-- 1 jonsonli supergroup 6946 2017-05-13 17:47 /output/wordcount1/part-00001