- MapReduce:进行批处理(离线计算)基于磁盘。
- Spark:基于内存(性能高一个层次)。
- Hive:数据仓库,可以使用sql语句,Hive把sql语句转换成MapReduce作业,批量数据处理。
- Pig:流数据处理,提供类似sql的查询语句PigLatin。
- Oozie:作业流调度系统。
- Zookeeper:分布式协调服务,分布式锁集群管理。
- Hbase:分布式数据库。
- Flume:日志收集。
- Sqoop:数据导入导出,数据从关系型数据库中导入Hadoop。
- Ambari:安装部署工具。
一、MapReduce两大核心组件
- JobTracker
- JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。
- 主要功能:
- 作业控制:在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
- 资源管理。
- TaskTracker
- TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;另一方面,
将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。 - 主要功能:
- 汇报心跳:Tracker周期性将所有节点上各种信息通过心跳机制汇报给JobTracker。这些信息包括两部分:
- 机器级别信息:节点健康情况、资源使用情况等。
- 任务级别信息:任务执行进度、任务运行状态等。
- TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;另一方面,
二、HDFS的局限性
- 不适合低延迟数据访问。
- 无法高效储存大量小文件。
- 不支持多用户写入及任意修改文件。
三、HDFS两大组件
- 名称节点:负责提取索引,目录功能,保存元数据。
- FsImage:保存系统文件树。
- EditLog:记录对数据进行的诸如创建,删除,重命名等操作。
- 数据节点:负责存储实际数据。
四、HDFS读取数据

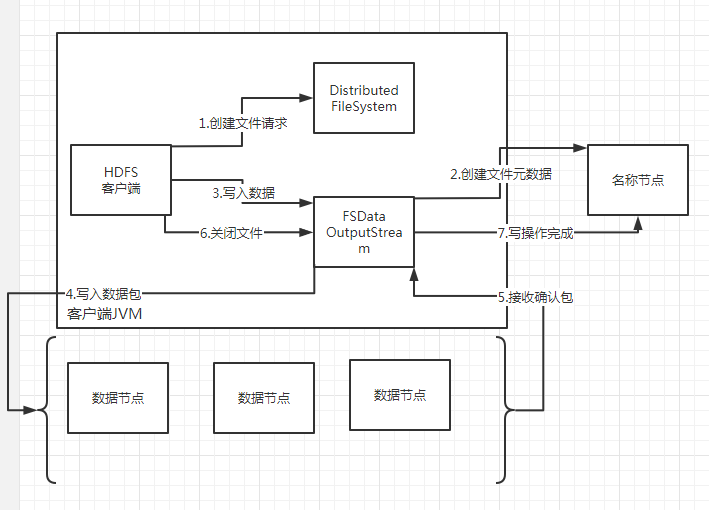
五、HDFS写数据