为什么选择NIO,那么NIO相对于IO来说,有什么优势,总结来说:
- IO是面向流的,数据只能从一端读取到另一端,不能随意读写。NIO则是面向缓冲区的,进行数据的操作更方便了
- IO是阻塞的,既浪费服务器的性能,也增加了服务器的风险;而NIO是非阻塞的。
- NIO引入了IO多路复用器,效率上更高效了。
在 NIO 中有几个比较关键的概念:Channel(通道),Buffer(缓冲区),Selector(选择器)
- Channel(通道):通道,顾名思义,就是通向什么的道路,为某个提供了渠道。在传统 IO 中我们使用 Stream 来读取文件内容,因此可以将 NIO 中的 Channel 同传统 IO 中的 Stream 来类比,但是要注意,传统 IO 中,Stream 是单向的,比如 InputStream 只能进行读取操作,OutputStream 只能进行写操作。而 Channel 是双向的,既可用来进行读操作,又可用来进行写操作
- Buffer(缓冲区):是NIO中非常重要的一个东西,在NIO中所有数据的读和写都离不开 Buffer,读取的数据只能放在Buffer中,同样地,写入数据也是先写入到Buffer中
- Selector(选择器):是NIO中最关键的一个部分,Selector的作用就是用来轮询每个注册的Channel,一旦发现Channel有注册的事件发生,便获取事件然后进行处理。
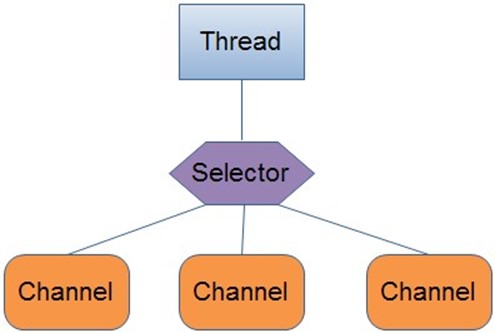
用单线程处理一个Selector,然后通过 Selector.select() 方法来获取到达事件,在获取了到达事件之后,就可以逐个地对这些事件进行响应处理
Buffer
缓冲区,实际上是一个容器,是一个连续数组。Channel提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由Buffer。具体看下面这张图就理解了:
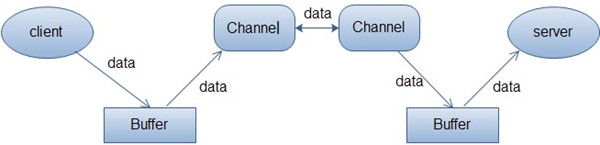
客户端发送数据时,必须先将数据存入Buffer中,然后将Buffer中的内容写入通道。服务端这边接收数据必须通过 Channel 将数据读入到 Buffer 中,然后再从 Buffer 中取出数据来处理。
Buffer 比较重要的变量如下:
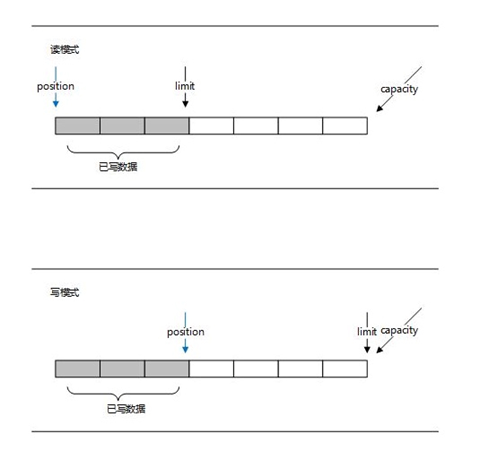
- capacity:缓冲区的 capacity 表明可以储存在缓冲区中的最大数据容量。
- limit:变量表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)
- posistion:从通道读取时,指定了下一个字节将放到数组的哪一个元素中,如果您从通道中读三个字节到缓冲区中,那么缓冲区的 position 将会设置为3,指向数组中第四个元素;写入通道时,是从缓冲区中获取数据。 position 值跟踪从缓冲区中获取了多少数据。更准确地说,它指定下一个字节来自数组的哪一个元素。因此如果从缓冲区写了5个字节到通道中,那么缓冲区的 position 将被设置为5,指向数组的第六个元素。
总结来说,NIO 的 Buffer有两种模式,读模式和写模式,默认是写模式,使用 flip() 可以切换到读模式
示例代码如下:
public static void main(String[] args) throws IOException{
//创建Buffer,分配128字节
ByteBuffer buffer=ByteBuffer.allocate(128);
System.out.println("创建Buffer,"+buffer);
//写入内容
String content="这个是内容";
buffer.put(content.getBytes());
System.out.println("写入内容,"+buffer);
//转换为读模式
buffer.flip();
System.out.println("切换为读模式,"+buffer);
//读取数据
byte[] v=new byte[buffer.remaining()];
buffer.get(v);
System.out.println("读取数据,"+buffer);
}
运行输出如下:
创建 Buffer,java.nio.HeapByteBuffer[pos=0 lim=128 cap=128]
写入内容,java.nio.HeapByteBuffer[pos=15 lim=128 cap=128]
切换为读模式,java.nio.HeapByteBuffer[pos=0 lim=15 cap=128]
读取数据,java.nio.HeapByteBuffer[pos=15 lim=15 cap=128]
访问方法
ByteBuffer 类中有四个 get() 方法:
- byte get();
- ByteBuffer get( byte dst[] );
- ByteBuffer get( byte dst[], int offset, int length );
- byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回 ByteBuffer 的方法只是返回调用它们的缓冲区的 this 值。
此外,我们认为前三个 get() 方法是相对的,而最后一个方法是绝对的。 相对意味着 get() 操作服从 limit 和 position 值,更明确地说,字节是从当前 position 读取的,而 position 在 get 之后会增加。另一方面,一个 绝对方法会忽略 limit 和 position 值,也不会影响它们。事实上,它完全绕过了缓冲区的统计方法。
上面列出的方法对应于 ByteBuffer 类。其他类有等价的 get() 方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
ByteBuffer 类中有五个 put() 方法:
- ByteBuffer put( byte b );
- ByteBuffer put( byte src[] );
- ByteBuffer put( byte src[], int offset, int length );
- ByteBuffer put( ByteBuffer src );
- ByteBuffer put( int index, byte b );
第一个方法 写入(put) 单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源 ByteBuffer 写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回 ByteBuffer 的方法只是返回调用它们的缓冲区的 this 值。
与 get() 方法一样,我们将把 put() 方法划分为 相对 或者 绝对 的。前四个方法是相对的,而第五个方法是绝对的。
上面显示的方法对应于 ByteBuffer 类。其他类有等价的 put() 方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型
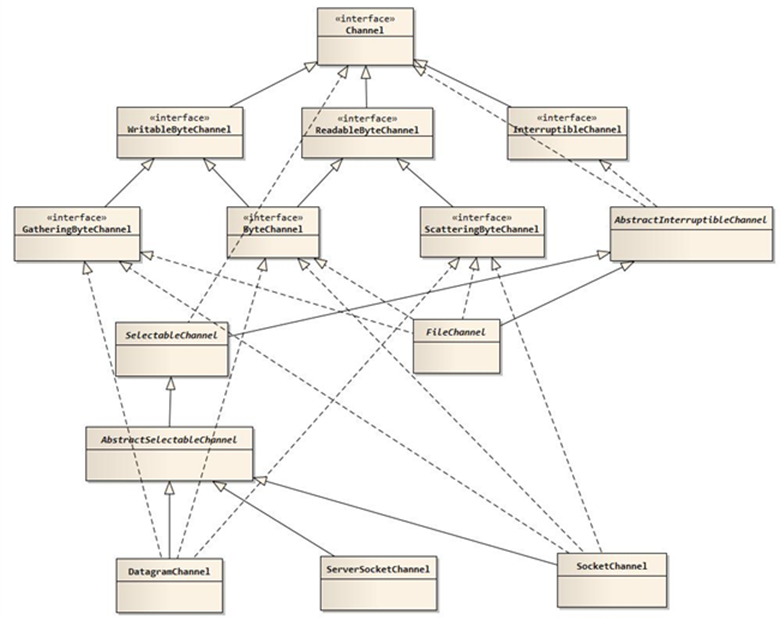
Channel
Channel 和传统 IO 中的 Stream 很相似。虽然很相似,但是有很大的区别,主要区别为通道是双向的,通过一个Channel既可以进行读,也可以进行写,常用的通道如下:
- FileChannel:可以从文件读或者向文件写入数据
- SocketChanel:以TCP来向网络连接的两端读写数据
- ServerSocketChannel:能够监听客户端发起的TCP连接,并为每个TCP连接创建一个新的SocketChannel来进行数据读写
- DatagramChannel:以UDP协议来向网络连接的两端读写数据
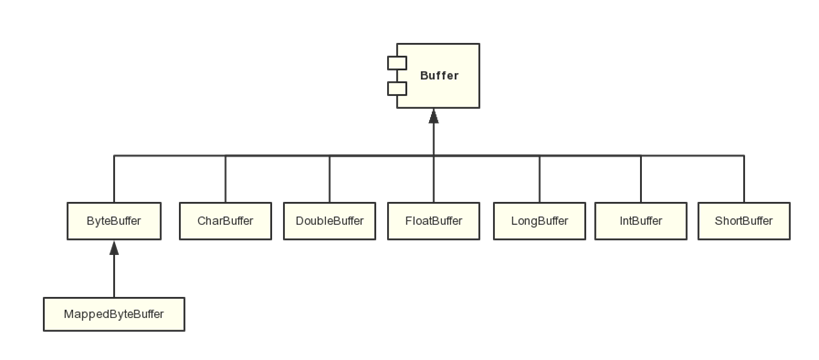
NIO 提供了多种通道对象,而所有的通道对象都实现了Channel 接口,他们之间的继承关系如下图:
我们将从一个文件中读取一些数据。如果使用原来的 I/O,那么我们只需创建一个 FileInputStream 并从它那里读取。在 NIO 中,情况稍有不同,我们首先从 FileInputStream 获取一个 Channel 对象,然后使用这个通道来读取数据。
在 NIO 系统中,任何时候执行一个读操作,都是从通道中读取,但是不是直接从通道读取。因为所有数据最终都驻留在缓冲区中,所以您是从通道读到缓冲区中。因此读取文件涉及三个步骤:
从 FileInputStream 获取 Channel
FileInputStream fin=new FileInputStream("readandshow.txt");
FileChannel fc=fin.getChannel();
创建 Buffer
ByteBuffer buffer=ByteBuffer.allocate(1024);
将数据从 Channel 读到 Buffer 中
fc.read(buffer);
写入文件和读取类似,首先需要从 FileOutputStream 获取一个通道
FileOutputStream fout=new FileOutputStream("writesomebytes.txt");
FileChannel fc=fout.getChannel();
创建一个缓冲区并在其中放入一些数据
byte[] message="message".getBytes();
ByteBuffer buffer=ByteBuffer.allocate(1024);
for(byte aMessage:message){
buffer.put(aMessage);
}
buffer.flip();
最后一步是写入缓冲区中
fc.write(buffer);
Selector
Selector 类是 NIO 的核心类,Selector 能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。与Selector 有关的一个关键类是 SelectionKey,一个 SelectionKey 表示一个到达的事件,这2个类构成了服务端处理业务的关键逻辑。
我们创建一个服务器套接字程序,需要做的第一件事就是创建一个 Selector 对象
//创建S elector
Selector selector=Selector.open();
为了接收连接,我们需要一个 ServerSocketChannel,事实上,我们要监听的每一个端口都需要有一个 ServerSocketChannel ,如下所示
//创建ServerSocketChannel并设置非阻塞,绑定到端口
ServerSocketChannel serverSocketChannel=ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
ServerSocket serverSocket=serverSocketChannel.socket();
InetSocketAddress inetSocketAddress=new InetSocketAddress(9990);
serverSocket.bind(inetSocketAddress);
打开的 ServerSocketChannels 注册到 Selector上,为此我们使用 ServerSocketChannel.register() 方法
//注册事件OP_ACCEPT表示监听accept事件,也就是在新的连接建立时所发生的事件,
//其返回的SelectionKey用于后续的取消注册
SelectionKey selectionKey=serverSocketChannel.register(selector,SelectionKey.OP_ACCEPT);
我们调用 Selector 的 select() 方法,这个方法会阻塞,直到至少有一个已注册的事件发生,当一个或者更多的事件发生时, select() 方法将返回所发生的事件的数量。
//阻塞,直到有注册的事件发生,返回发生事件的数量
int num=selector.select();
接下来,我们调用 Selector 的 selectedKeys() 方法,它返回发生了事件的 SelectionKey 对象的一个 集合 。
//返回发生事件的SelectionKey集合
SetselectedKeys=selector.selectedKeys();
我们通过迭代 SelectionKeys 并依次处理每个 SelectionKey 来处理事件,对于每一个 SelectionKey,您必须确定发生的是什么 I/O 事件,以及这个事件影响哪些 I/O 对象,在处理完成后,需要迭代器中移除,防止多次处理。
//迭代集合依次处理
Iterator it=selectedKeys.iterator();
while(it.hasNext()){
SelectionKeykey=(SelectionKey)it.next();
// 针对事件类型进行处理
if((key.readyOps()&SelectionKey.OP_ACCEPT)==SelectionKey.OP_ACCEPT){
// 服务器套接字有传入连接在等待,操作accept接受连接
ServerSocketChannel ssc=(ServerSocketChannel)key.channel();
SocketChannel sc=ssc.accept();
// 配置为非阻塞
sc.configureBlocking(false);
// 注册事件OP_READ表示监听读取
SelectionKey newKey=sc.register(selector,SelectionKey.OP_READ);
}
if((key.readyOps()&SelectionKey.OP_READ)==SelectionKey.OP_READ){
// 处理接收数据事件
}
//处理完成后,从集合中移除
it.remove();
}