https://www.cnblogs.com/sixrain/p/9138442.html
用Python如何写一个接口呢,首先得要有数据,可以用我们在网站上爬的数据,在上一篇文章中写了如何用Python爬虫,有兴趣的可以看看:
大量的数据保存到数据库比较方便。我用的pymsql,pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。但目前在python3.x中,PyMySQL取代了MySQLdb。
1.连接数据库
|
1
2
3
|
# 连接数据库,需指定charset否则可能会报错db = pymysql.connect(host="localhost", user="root", password="123", db="mysql", charset="utf8mb4")cursor = db.cursor() # 创建一个游标对象 |
2.创建数据库
|
1
2
3
4
5
6
7
8
9
10
11
|
cursor.execute("DROP TABLE IF EXISTS meizi_meizis") # 如果表存在则删除 # 创建表sql语句 createTab = """create table meizi_meizis( id int primary key auto_increment, mid varchar(10) not null, title varchar(50), picname varchar(10), page_url varchar(50), img_url varchar(50) );""" cursor.execute(createTab) # 执行创建数据表操作 |
3.爬取数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def html(self, href, title): lists = [] meiziid = href.split('/')[-1] html = self.request(href) max_span = BeautifulSoup(html.text, 'lxml').find('div', class_='pagenavi').find_all('span')[-2].get_text() for page in range(1, int(max_span) + 1): meizi = {} page_url = href + '/' + str(page) img_html = self.request(page_url) img_url = BeautifulSoup(img_html.text, 'lxml').find('div', class_='main-image').find('img')['src'] picname = img_url[-9:-4] meizi['meiziid'] = meiziid meizi['title'] = title meizi['picname'] = picname meizi['page_url'] = page_url meizi['img_url'] = img_url lists.append(meizi) # 保存到返回数组中 return lists |
4.保存到数据库
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def all_url(self, url): html = self.request(url) all_a = BeautifulSoup(html.text, 'lxml').find('div', class_='all').find_all('a') for index, a in enumerate(all_a): title = a.get_text() href = a['href'] lists = self.html(href, title) for i in lists: # print(i['meiziid'], i['title'], i['picname'], i['page_url'], i['img_url']) # 插入数据到数据库sql语句,%s用作字符串占位 sql = "INSERT INTO `meizi_meizis`(`mid`,`title`,`picname`,`page_url`,`img_url`) VALUES(%s,%s,%s,%s,%s)" try: cursor.execute(sql, (i['meiziid'], i['title'], i['picname'], i['page_url'], i['img_url'])) db.commit() print(i[0] + " is success") except: db.rollback() db.close() # 关闭数据库 |
5.创建Web工程
运行我们的爬虫,很快数据库表里就有数据了。
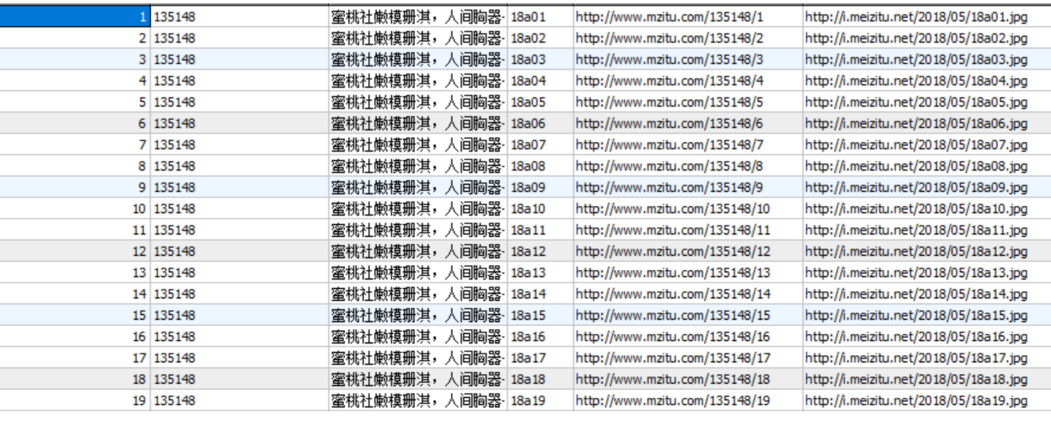
然后开始写接口。我是通过Django+rest_framework来写的。
Django 是用Python开发的一个免费开源的Web框架,可以用于快速搭建高性能,优雅的网站。Django 中提供了开发网站经常用到的模块,常见的代码都为你写好了,减少重复的代码。
Django 目录结构
网址入口,关联到对应的views.py中的一个函数(或者generic类),访问网址就对应一个函数。
处理用户发出的请求,从urls.py中对应过来, 通过渲染templates中的网页可以将显示内容,比如登陆后的用户名,用户请求的数据,输出到网页。
与数据库操作相关,存入或读取数据时用到这个,当然用不到数据库的时候 你可以不使用。
表单,用户在浏览器上输入数据提交,对数据的验证工作以及输入框的生成等工作,当然你也可以不使用。
templates 文件夹
views.py 中的函数渲染templates中的Html模板,得到动态内容的网页,当然可以用缓存来提高速度。
后台,可以用很少量的代码就拥有一个强大的后台。
Django 的设置,配置文件,比如 DEBUG 的开关,静态文件的位置等。
Django 常用操作
1)新建一个 django project
django-admin.py startproject project_name
2)新建 app
python manage.py startapp app_name
一般一个项目有多个app, 当然通用的app也可以在多个项目中使用。
还得在工程目录的settings.py文件在配置
|
1
2
3
4
5
6
7
8
9
10
11
|
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', 'meizi',] |
在app/views.py下编写代码
|
1
2
|
def index(request): return HttpResponse(u"你好") |
在工程目录urls.py配置
|
1
2
3
4
|
from learn import views as learn_viewsurlpatterns = [ url(r'^$', learn_views.index), ] |
通过python manage.py runserver启动,就会看到我们输出的“你好”了
3)创建数据库表 或 更改数据库表或字段
在app下的models.py创建表
|
1
2
3
4
5
6
7
|
class Person(models.Model): name = models.CharField(max_length=30) age = models.IntegerField() def __unicode__(self): # 在Python3中使用 def __str__(self): return self.name |
运行命令,就可以生成对应的表
|
1
2
3
4
5
|
Django 1.7.1及以上 用以下命令# 1. 创建更改的文件python manage.py makemigrations# 2. 将生成的py文件应用到数据库python manage.py migrate |
在views.py文件里就可以获取数据库的数据
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def create(request): # 新建一个对象的方法有以下几种: Person.objects.create(name='xiaoli', age=18) # p = Person(name="WZ", age=23) # p = Person(name="TWZ") # p.age = 23 # p.save() # 这种方法是防止重复很好的方法,但是速度要相对慢些,返回一个元组,第一个为Person对象, # 第二个为True或False, 新建时返回的是True, 已经存在时返回False # Person.objects.get_or_create(name="WZT", age=23) s = Person.objects.get(name='xiaoli') return HttpResponse(str(s)) |
6.写接口
接口使用rest_framework,rest_framework是一套基于Django 的 REST 框架,是一个强大灵活的构建 Web API 的工具包。
写接口三步完成:连接数据库、取数据、数据输出
1)连接数据库
在工程目录下的settings.py文件下配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
DATABASES = { # 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # } 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'mysql', 'USER': 'root', 'HOST': '127.0.0.1', 'PASSWORD': '123', 'PORT': 3306, # show variables like 'character_set_database'; # 修改字段字符编码 # alter table spiders_weibo modify text longtext charset utf8mb4 collate utf8mb4_unicode_ci; 'OPTIONS': {'charset': 'utf8mb4'}, }} |
2)取数据
既然要取数据,那model肯定得和数据库的一致,我发现一个快捷的方式可以把数据库中的表生成对应的model,在项目目录下执行命令
|
1
|
python manage.py inspectdb |
可以看到下图
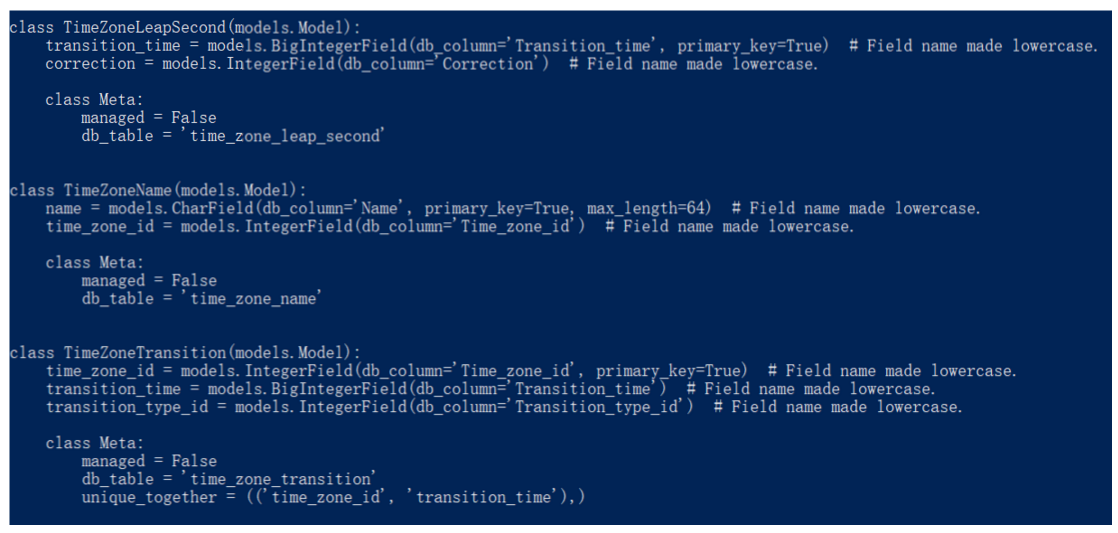
取我们表的model拷贝到app下的models.py里
|
1
2
3
4
5
6
7
8
9
10
|
class Meizis(models.Model): mid = models.CharField(max_length=10) title = models.CharField(max_length=50, blank=True, null=True) picname = models.CharField(max_length=10, blank=True, null=True) page_url = models.CharField(max_length=50, blank=True, null=True) img_url = models.CharField(max_length=50, blank=True, null=True) class Meta: managed = False db_table = 'meizi_meizis' |
创建一个序列化Serializer类
提供序列化和反序列化的途径,使之可以转化为,某种表现形式如json。我们可以借助serializer来实现,类似于Django表单(form)的运作方式。在app目录下,创建文件serializers.py。
|
1
2
3
4
5
6
7
|
class MeiziSerializer(serializers.ModelSerializer): # ModelSerializer和Django中ModelForm功能相似 # Serializer和Django中Form功能相似 class Meta: model = Meizis # 和"__all__"等价 fields = ('mid', 'title', 'picname', 'page_url', 'img_url') |
这样在views.py就可以来获取数据库的数据了
|
1
2
3
|
meizis = Meizis.objects.all()serializer = MeiziSerializer(meizis, many=True)return Response(serializer.data) |
3) 数据输出客户端或前端
REST框架提供了两种编写API视图的封装。
- @api_view装饰器,基于方法的视图。
- 继承APIView类,基于类的视图。
request.data会自行处理输入的json请求
使用格式后缀明确的指向指定的格式,需要添加一个format关键字参数
http http://127.0.0.1:8000/getlist.json # JSON 后缀
http://127.0.0.1:8000/getlist.api # 可视化 API 后缀
http://127.0.0.1:8000/getlist/ code="print 123"post
使用格式后缀明确的指向指定的格式,需要添加一个format关键字参数
http http://127.0.0.1:8000/getlist.json # JSON 后缀
http://127.0.0.1:8000/getlist.api # 可视化 API 后缀
http://127.0.0.1:8000/getlist/ code="print 123"post
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@api_view(['GET', 'POST'])def getlist(request, format=None): if request.method == 'GET': meizis = Meizis.objects.all() serializer = MeiziSerializer(meizis, many=True) return Response(serializer.data) elif request.method == 'POST': serializer = MeiziSerializer(data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST) |
4)分页
最后别忘了在urls.py配置URL,通过浏览器就可以看到json数据了。



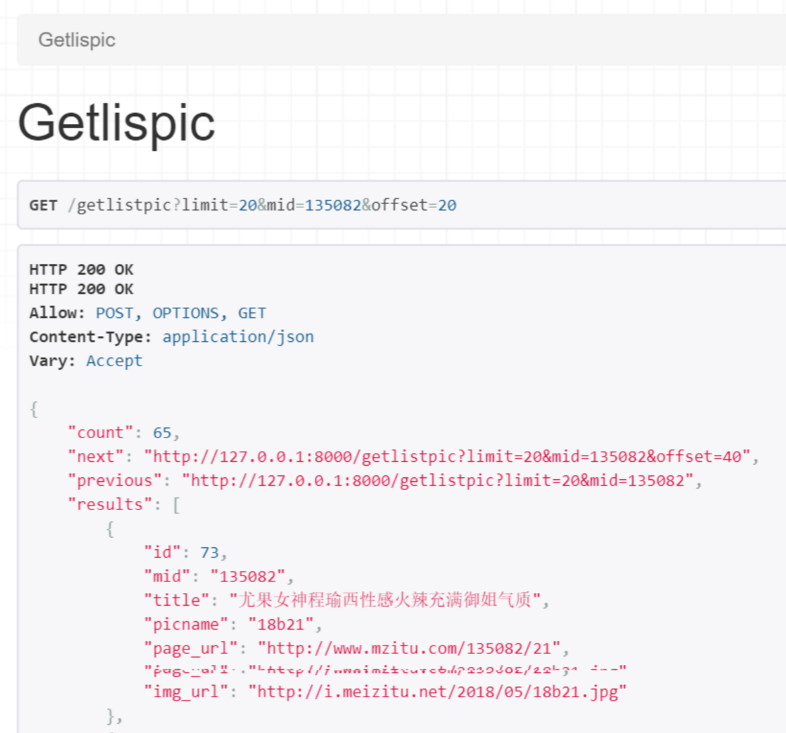
当然app也是可以调用我们的接口的

还有个问题
我们的数据有好几千条,一块返回来很不合理,所以需要分页,当然rest_framework框架提供了这个功能,post请求不支持,需要自己查数据库或者切片来进行返回。来看看rest_framework是如何来分页的。在models.py里创建一个类
|
1
2
3
4
5
6
7
8
9
|
class StandardResultSetPagination(LimitOffsetPagination): # 默认每页显示的条数 default_limit = 20 # url 中传入的显示数据条数的参数 limit_query_param = 'limit' # url中传入的数据位置的参数 offset_query_param = 'offset' # 最大每页显示条数 max_limit = None |
在serializers.py创建俩个类,为什么是俩个?因为我们有俩个接口,一个明细,一个列表,而列表是不需要把字段的所有数据都返回的
|
1
2
3
4
5
6
7
8
9
10
|
class ListSerialize(serializers.ModelSerializer): class Meta: model = Meizis fields = ('mid', 'title')class ListPicSerialize(serializers.ModelSerializer): class Meta: model = Meizis fields = "__all__" |
在views.py里编写
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
@api_view(['GET'])def getlist(request, format=None): if request.method == 'GET': meizis = Meizis.objects.values('mid','title').distinct() # http: // 127.0.0.1:8000 / getlist?limit = 20 # http: // 127.0.0.1:8000 / getlist?limit = 20 & offset = 20 # http: // 127.0.0.1:8000 / getlist?limit = 20 & offset = 40 # 根据url参数 获取分页数据 obj = StandardResultSetPagination() page_list = obj.paginate_queryset(meizis, request) # 对数据序列化 普通序列化 显示的只是数据 ser = ListSerialize(instance=page_list, many=True) # 多个many=True # instance:把对象序列化 response = obj.get_paginated_response(ser.data) return response@api_view(['GET', 'POST'])def getlispic(request, format=None): if request.method == 'GET': mid = request.GET['mid'] if mid is not None: # get是用来获取一个对象的,如果需要获取满足条件的一些数据,就要用到filter meizis = Meizis.objects.filter(mid=mid) obj = StandardResultSetPagination() page_list = obj.paginate_queryset(meizis, request) ser = ListPicSerialize(instance=page_list, many=True) response = obj.get_paginated_response(ser.data) return response else: return Response(str('请传mid')) |
到这里就完成了接口的编写,都是对框架的简单使用,希望对大家有帮助。
GitHub地址,欢迎star