笔记: 2021年腾讯技术大咖直播分享-深入了解异步编程范式
重点在于范式,不会精准到语言细节
1. 异步是怎么提高效率的?
CPU实在是太快啦
原因:
- 摩尔定律失效:芯片工艺逼近物理极限,计算机性能基本到头了
- 互联网马太效应:流量向几个头部app集中,对服务器的性能要求越来越高:分布式、单机优化
优化单机,硬件提升不大,优化软件,而软件优化的重点是协调好运行速度有天壤之别的不同硬件

一个更直观的感受,假设CPU执行一条指令的时间需要1s:
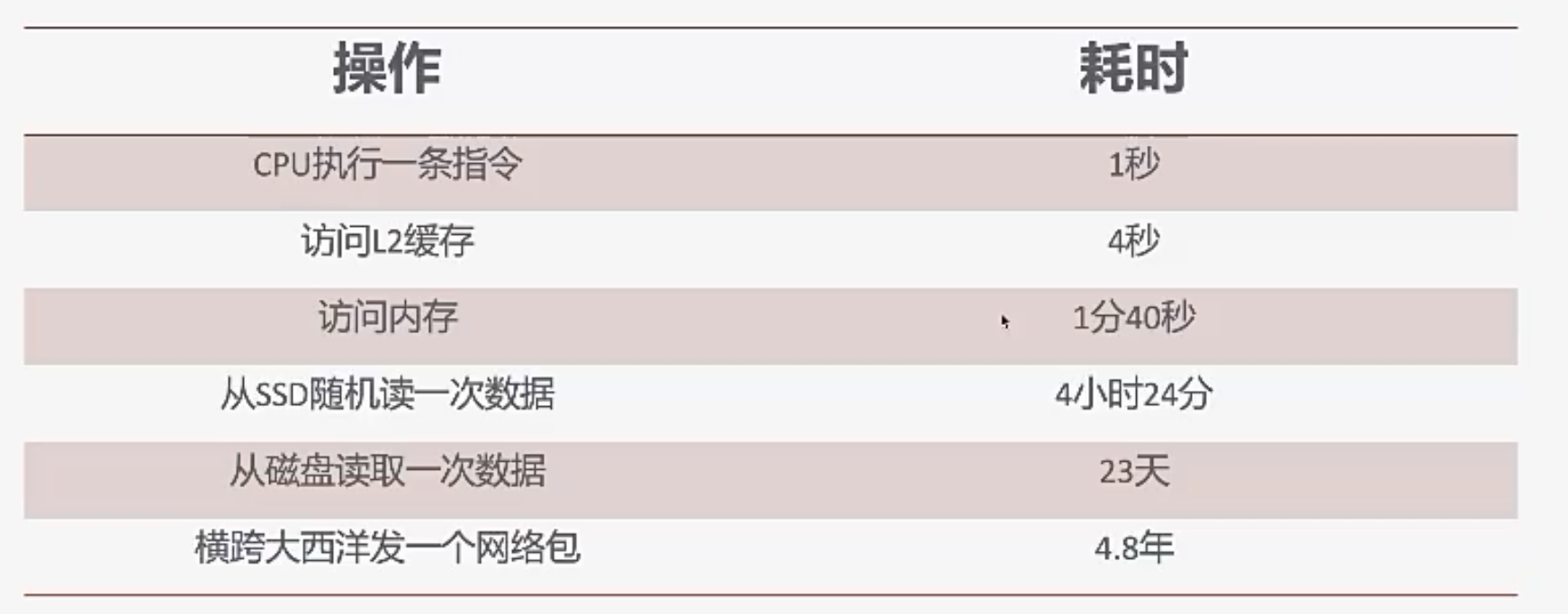
CPU实在是太快啦~~
无敌是多么寂寞
相比CPU,磁盘和网络IO就非常非常慢,导致效率低下
let x = read_file("umber.txt");
x = x+1;
print(x);
(都是伪代码,不一定能跑)
为了完成一个1ns的加法,CPU需要等待两千万ns的read_file
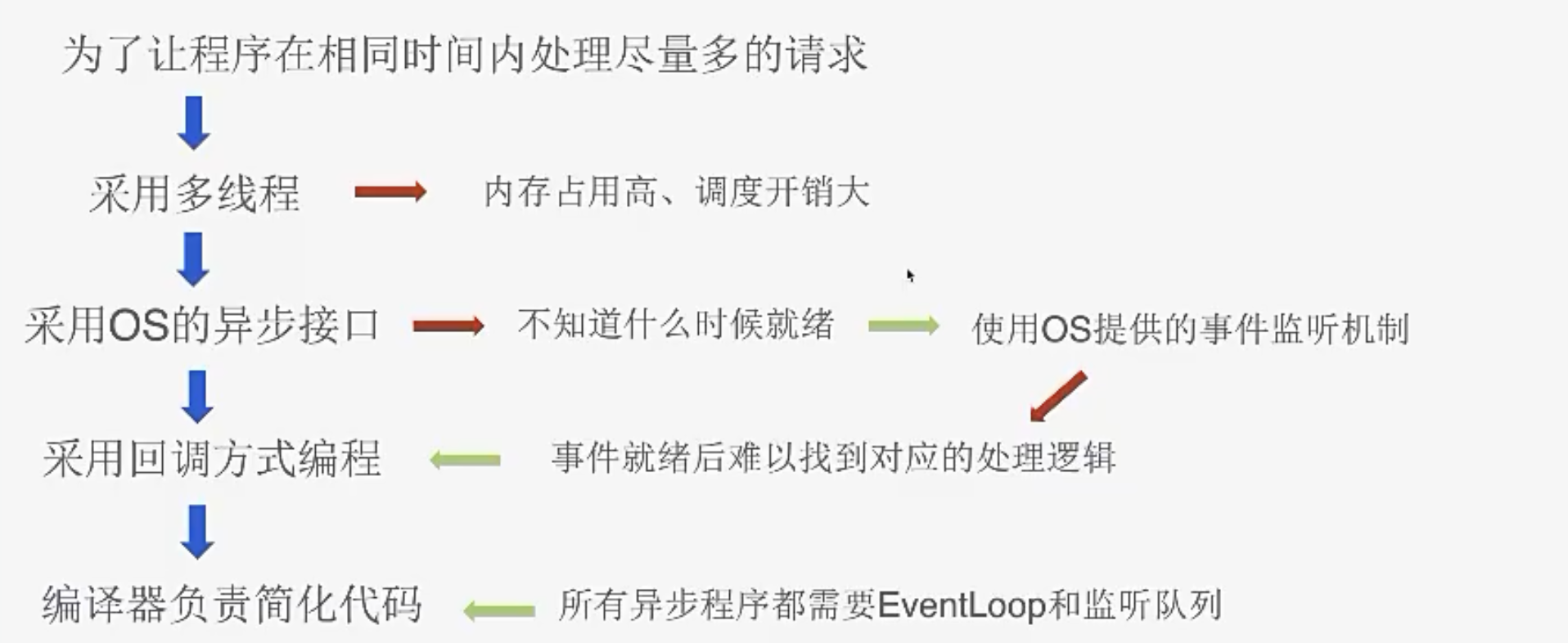
利用多线程提高CPU利用率
为了提高CPU的利用率,操作系统通常提供的多线程的解决方法
如果某个线程阻塞了,CPU会将其挂起,然后去执行其他线程
但是会遇到问题:
线程的开销很大:1个线程8M -> 1000个线程8G -> 利用率仍然不够
因此,异步到底要解决什么问题?实际上就是提升CPU利用率,在相同时间执行更多任务。
2. 回调模型的问题以及解决方案
同步方法和异步方法

左边同步的写法,read阻塞的时候操作系统会将进程挂起,然后CPU进入低功耗运行,read就绪后才接着执行
相比起来,异步看起来没有任何优势,意义在哪?
异步的价值在于,在控制权立即返回给我后,如果能做有意义的事情,异步就有价值;否则,异步就没有价值。
让任务并发执行
当有多个任务时,异步才有"操纵空间"

右边的异步代码中:jd在30秒时就会有响应,qq在50秒时响应,耗时只是两者之间的最大值
用户代码需要自己轮询就绪状态吗?
像多线程或同步代码的时候,你会发现如果IO就绪了,操作系统会将线程唤醒执行。这说明操作系统一定知道某个IO操作什么时候就绪了。
假设操作系统提供就绪事件通知功能的支持,我们就能写成如下的代码:
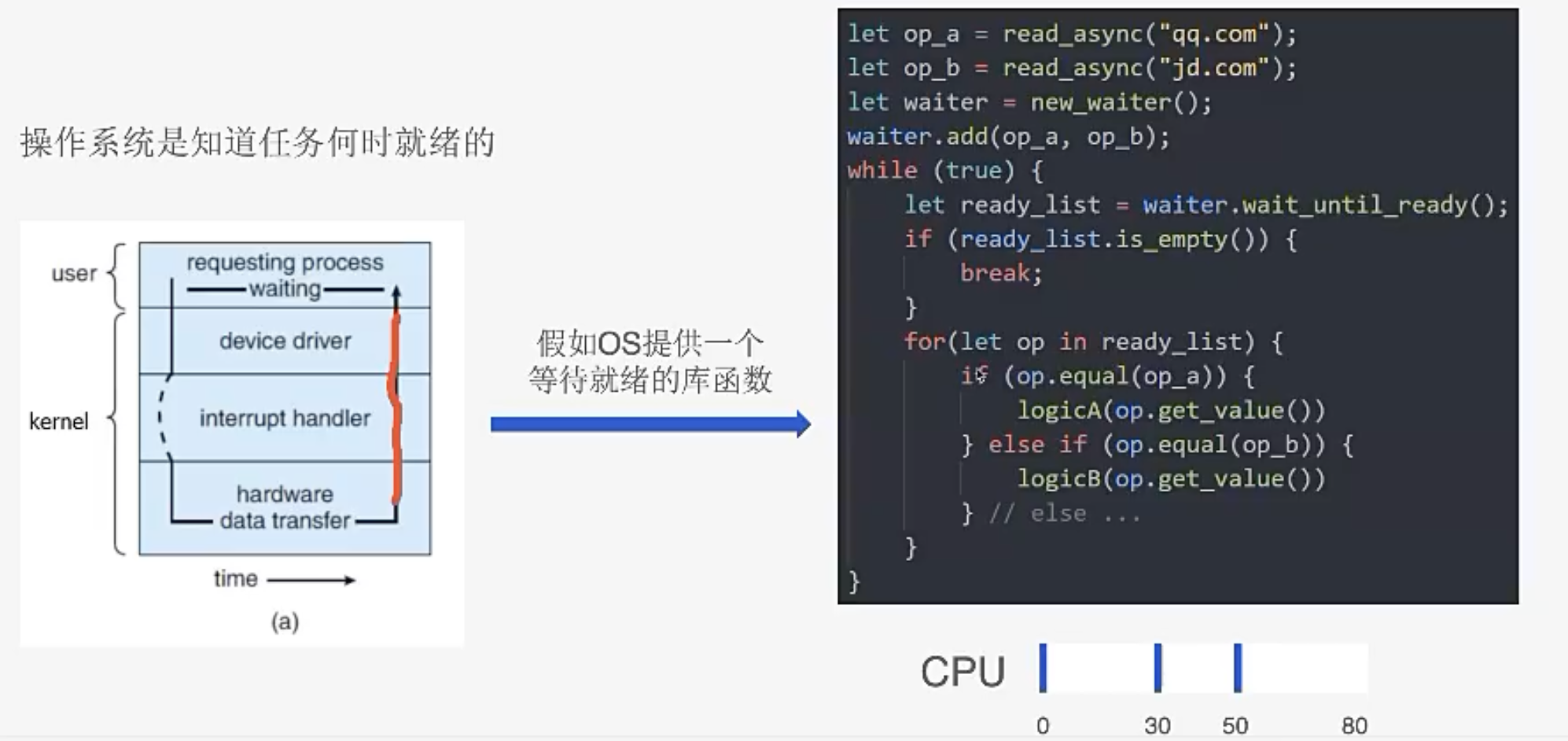
使用回调进一步简化代码
改进前,我拿到一个read_list,需要写很多if-else去处理每个类别,非常不好维护。
我们可以将代码重构,就写成回调的形式了。

这样循环就变得很简单!!
利用编译器/语言进一步简化
我们发现创建waiter以及执行eventLoop是通用的,可不可以让编译器/语言来干这件事,我们只需要注册回调。

read_async_v2 就是一个异步IO接口啦
小结
3. 回调模型的缺陷与解决方案
前面讲到,基于系统提供的一些能力,并通过编译器将一些通用的东西隐藏,能达到Javascript的编程方式,也就是异步的编程方式,基于回调的异步模型。
但是回调也有一些缺点,Callback模型的问题:回调地狱、
回调地狱
像被谁打了一拳...
回调地狱的初级解决方案
回想一下,我们是什么时候引入回调的?为了绑定事件处理逻辑。
必须通过回调绑定吗?可以通过不断的.then,这就是Promise。

在read_async_v3中, next相当于一个数组,then将一个函数加入数组,run每次取一个函数执行。
Promise带来的改变

看起来,其实也并没有带来很大改变。
只是比回调好那么一点点,与同步比还是不够清晰。

Promise最大的问题是:异步任务之间共享数据困难。
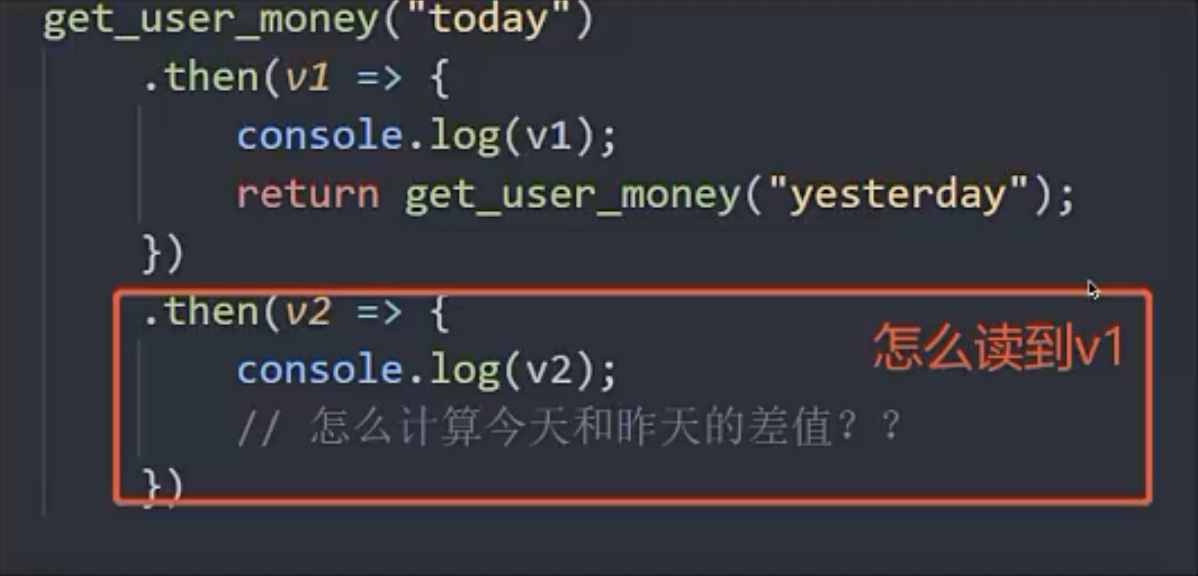
这也是async/await 与 Promise的一个区别
YY一下Promise的优化方法
既然每个异步调用后续的逻辑都需要放到then中,能不能在异步调用的函数后面加个标记(类似于Java的注解)。编译器根据标记,把被标记的代码进行等价转换。
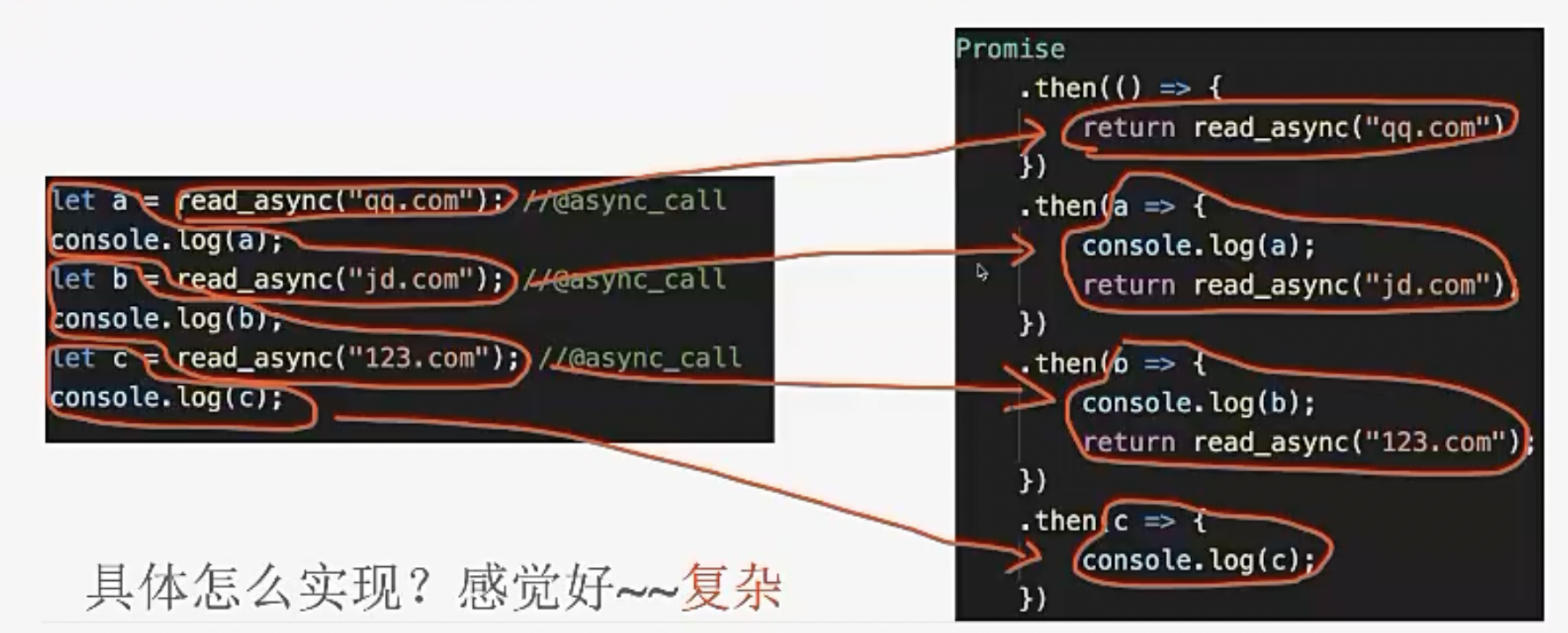
这只是一个纯编译器前端的工作,但也不是那么简单的
蓦然回首,那人却在灯火阑珊处
JS宝藏——generator

这个刚才的异步有什么关系呢?
把generator和异步结合起来
假如read_async 返回的是一个Promise,就可以给它绑定一个回调。
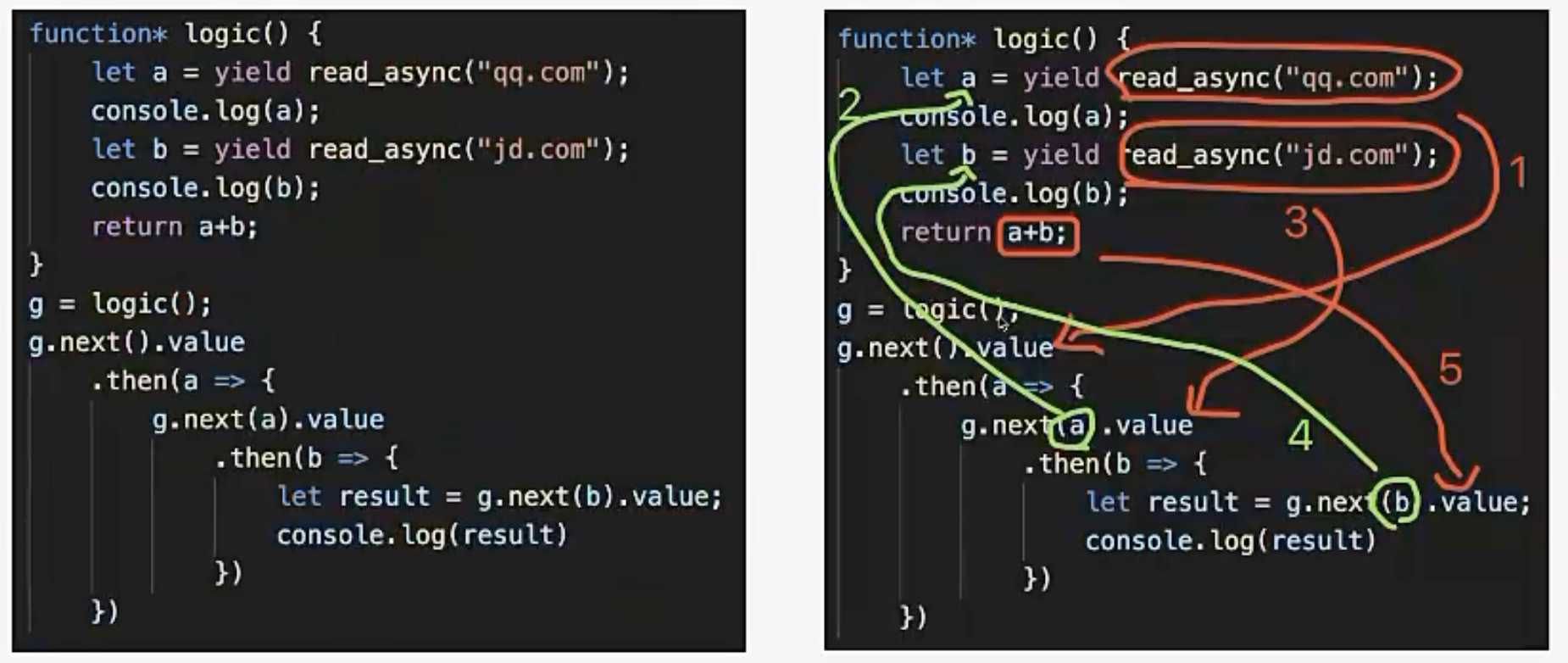
可以发现,上面这个logic代码和我们同步的代码基本一样,除了加了一个yield关键字。但是还有一个问题,为了执行logic,我需要不断调用next。
其实这是一个递归,完全可以执行一个excute将下面那部分包装一下:

Then里面递归调用了Then,这样将所有的逻辑执行完。
这样不仅代码进一步简化,还弥补了Promise的缺点。运用executeor来执行generator:
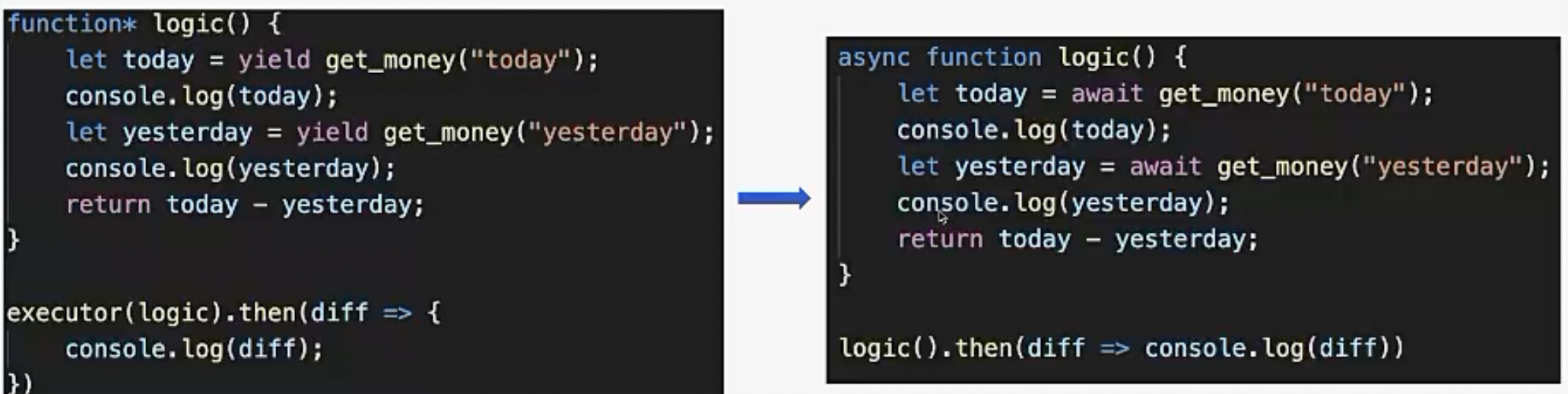
到目前为止,不借助操作系统的黑科技,通过一系列的包装,我们基本实现了同步写法。这就是大家目前用的async await。
async await和generator的区别
-generator不是专门为async await专门设计的,它是迭代器
generator+支持promise的executor刚好达到async await的效果,所以async await的底层选择使用generator来实现generator对于实现async await来说是非必需的,因为ES6中才开始支持generator,在ES5中要实现async await来变成了怎么实现generator- 实现
generator就需要涉及到语法分析语义分析,然后利用状态机进行代码装换(这也是babel的工作)
JS async await 模型的优缺点
优势:
- 代码直观,符合人的思维顺序
- 在IO密集型的情况下能高效利用CPU
劣势:
- 需要区分异步操作和同步操作,手动标注await
- 所有逻辑跑在单线程下,无法利用多核
- 如果代码有阻塞操作,整个服务都会受影响
- 如果有CPU计算密集的任务会拖累整个系统的吞吐
例如在Nodejs下,只有单线程,并发能力起不来,因为只要在代码中加一些计算任务就会把整个线程卡住。
但是像在Redis中,它也是单线程+异步事件, 整个主逻辑单线程就够了,发现某些任务可能卡住主逻辑, 也会开单独的线程去执行
4. Go语言怎么用同步逻辑描述异步行为
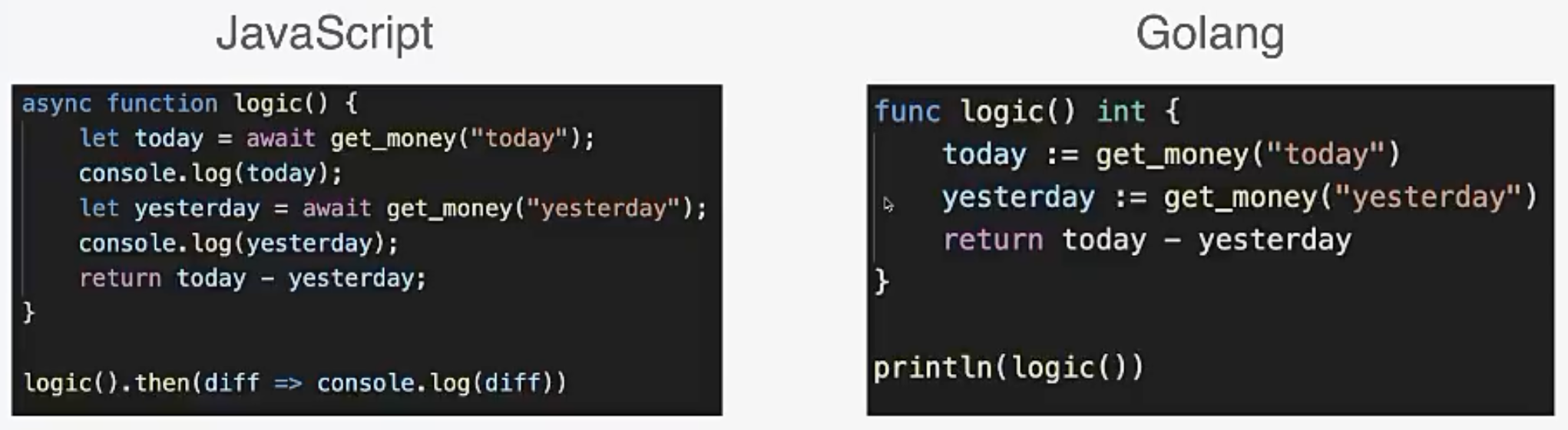
Go代码和async await代码对比
Go甚至不需要async await标记!!
Go是怎么做到让看起来同步的代码异步执行的呢?
Go是怎么骗你的?
Go不提供同步的api就完事了,将可能会阻塞的api都改成成异步的。因为你写的Go语言,你用的函数都是Go标准库暴露出来的函数,因此都能异步执行。

先将fd设置成非阻塞,并添加到监听事件中,然后返回到scheduler,scheduler执行了大量的程序,直到read读好了才恢复刚才的协程,读取数据再返回数据。
Go底层的实现大概就是这么一个流程,我之前的一个项目uthread主要也是做这件事情。
Go为什么可以做到这个呢?
首先,用户都是使用标准库API进行各种IO操作,而这个API都是Go改造过的
其次,这个异步操作都是IO,IO本质上都可以用read/write来抽象
最后,Go底层实现了协程切换和运行时调度器,Runtime会对异步IO调用进行协程切换。
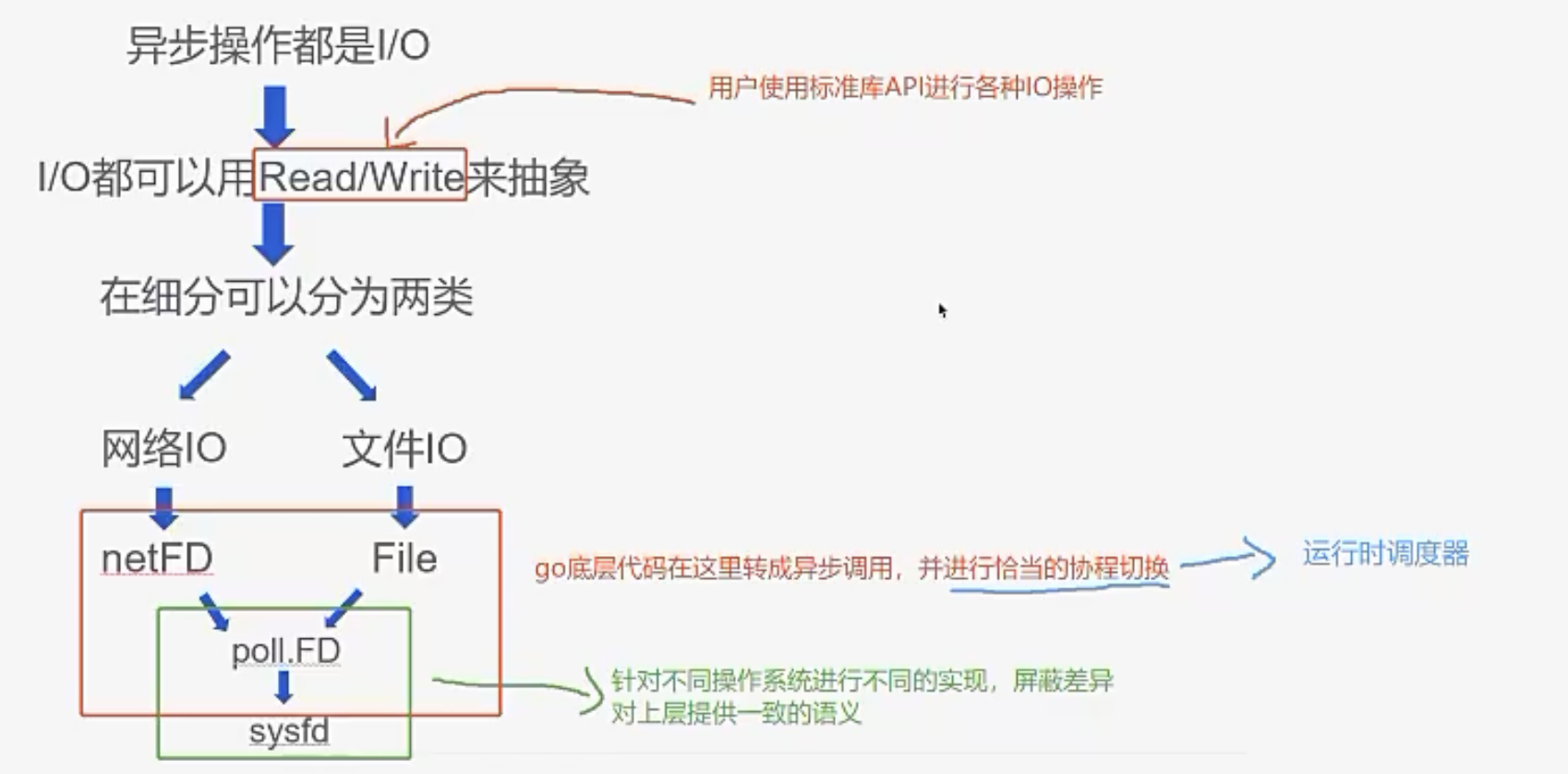
很像一个骗术,同步的调用底层被转成异步,只是能在适当时候返回。Go的开发者好像不用管同步异步,而实际上,你只要是用标准库的IO接口,都是异步的。
Go提供的同步抽象和async await哪个好?
其实前面讲async await的时候都没有说协程这个概念,业界通常将Go的这个协程称为有栈协程,将Rust/JS中的async await称为无栈协程。
其实这只是一种语义上的概念,肯定都是有栈的,函数执行肯定有栈。这个有栈/无栈是指我们是否抽象出协程概念,是否需要对协程保存相应的寄存器和栈。想async await根本没有保存寄存器,它就是全局的,绑上正确的回调函数,等着EventLoop调用,没有真正意义上的协程概念。
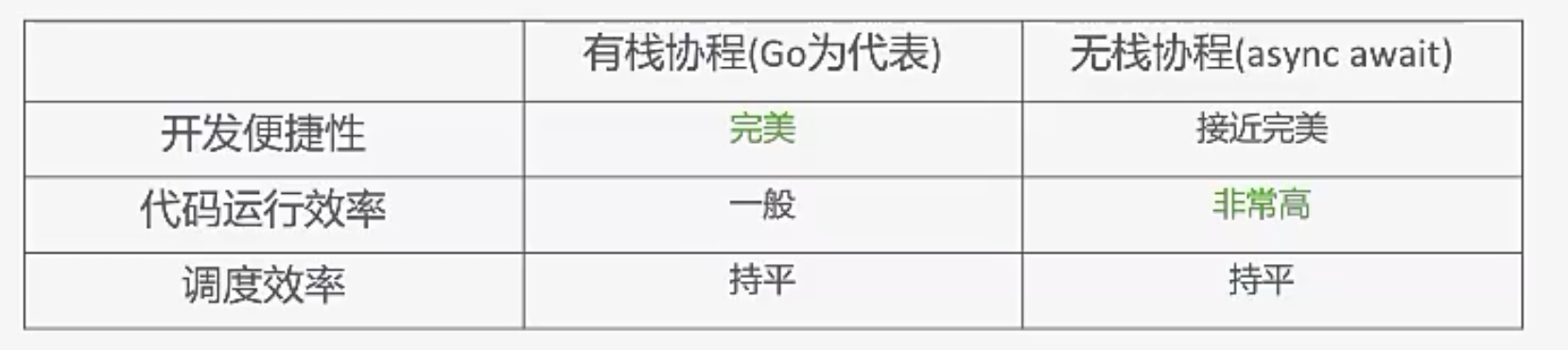
Go底层切换时需要保存当前上下文,切出来,再切回来,这些都是有开销的。Go其实就是将EventLoop封装到了Runtime。所以运行效率上不会比async await有什么优势。但这些复杂的东西不用我们写,Go程序员可以用同步方式写异步代码,这也是Go流行起来的一大原因吧
学习建议
本文简单地介绍了编程范式, 不是深入语言、深入操作系统去聊技术细节。主要讲怎么把异步的代码写地越来越符合人类的思维模式,从原始的异步轮询到EventLoop,不断优化转化,让编译器优化,甚至有栈协程让它更加接近完美。
最后,一些学习的建议:
- 先看目录索引,把握主干脉络
- 不要一开始就陷入各种细节
- 学习某种技术背后的目的,而不是为了学而学
- 不要来就看源码,先想想如果是我,要怎么实现
- 时常总结,通过思维导图帮助自己梳理自己的知识体系
- 现在会什么不重要,重要的是快速学习的能力