这个程序用来爬取我在博客园所有文章的标题,并用文件存起来。
from requests_html import HTMLSession base_url = 'https://www.cnblogs.com/lfri/default.html?page=' id = 1 def get_title(url): global id #在函数内部修改全局变量的值,要先用global声明全局变量。 session = HTMLSession() r = session.get(url) r.html.render(scrolldown=3, sleep=0.01) #下拉3次 titles = r.html.find('a.postTitle2') print(len(titles)) with open('titles.txt', 'a', encoding="utf-8") as f: #使用utf-8编码 for i, title in enumerate(titles): s = f'{id} [{title.text}]({title.attrs["href"]})' print(s) f.write(s + ' ') id = id + 1 if __name__ == '__main__': for x in range(20, 21): print('当前页面: '+ str(x)) get_title(base_url+str(x))
效果:
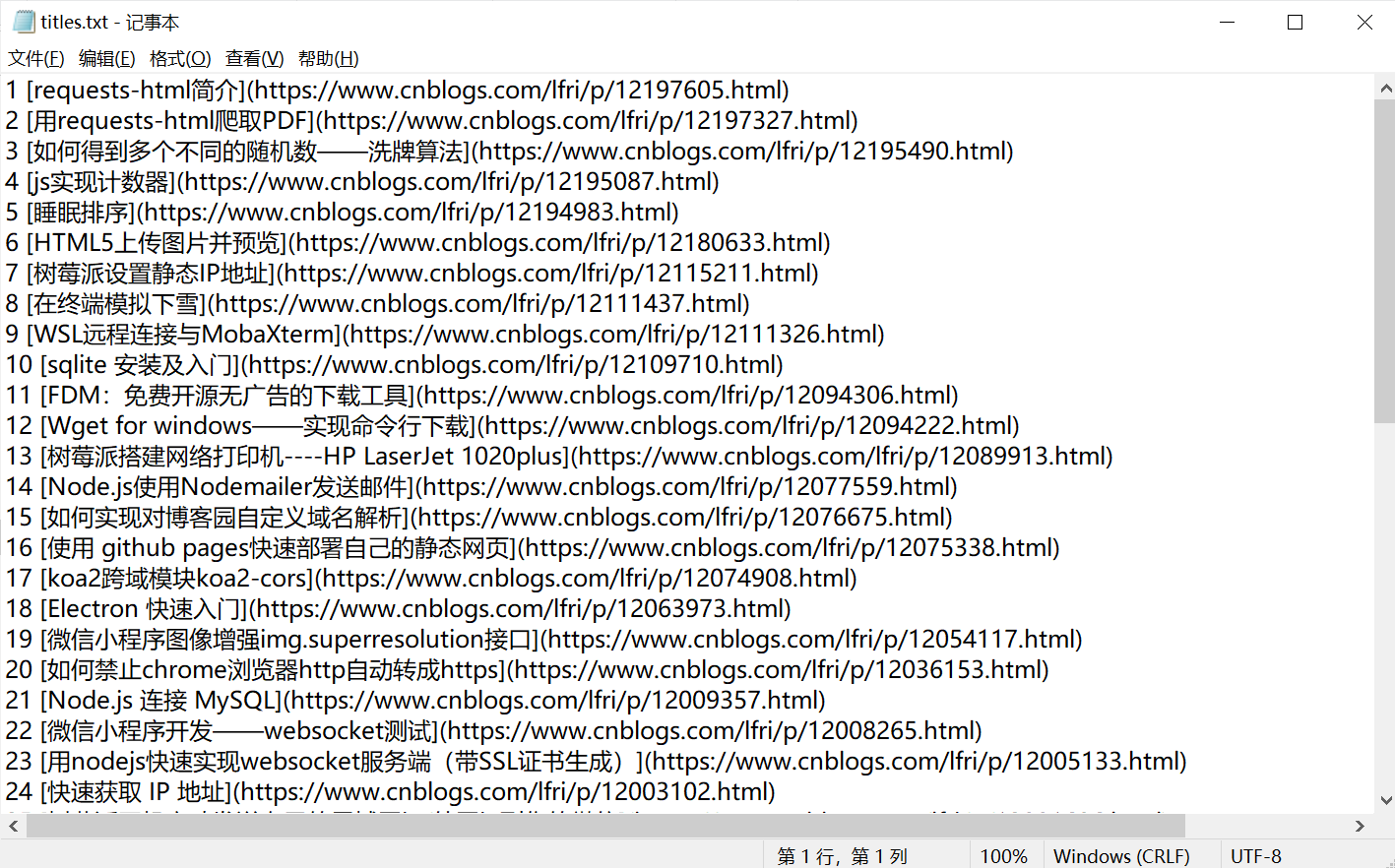
遇到的问题
1. UnicodeEncodeError: 'gbk' codec can't encode character 'xf6' in position 30: illegal multibyte sequence
解决方法:原因在于出现了gbk无法编码的字符,我有篇博客出现了“Möbius”。改成utf-8编码即可,一种方法是将encoding="utf-8"参数加到file.open()中。
2. 写入到文件中没有换行
解决方法:在字符串末尾加上 ' ' 。
参考链接: