前言:前面几篇介绍了线性表的顺序和链式存储结构,其中链式存储结构为单向链表(即一个方向的有限长度、不循环的链表),对于单链表,由于每个节点只存储了向后的指针,到了尾部标识就停止了向后链的操作。也就是说只能向后走,如果走过了,就回不去了,还得重头开始遍历,所以就衍生出了循环链表
一、简介
定义:将单链表中中断结点的指针端有空指针改为指向头结点,就使整个单链表形成一个环,这种头尾详解的单链表称为单循环链表,简称循环链表;
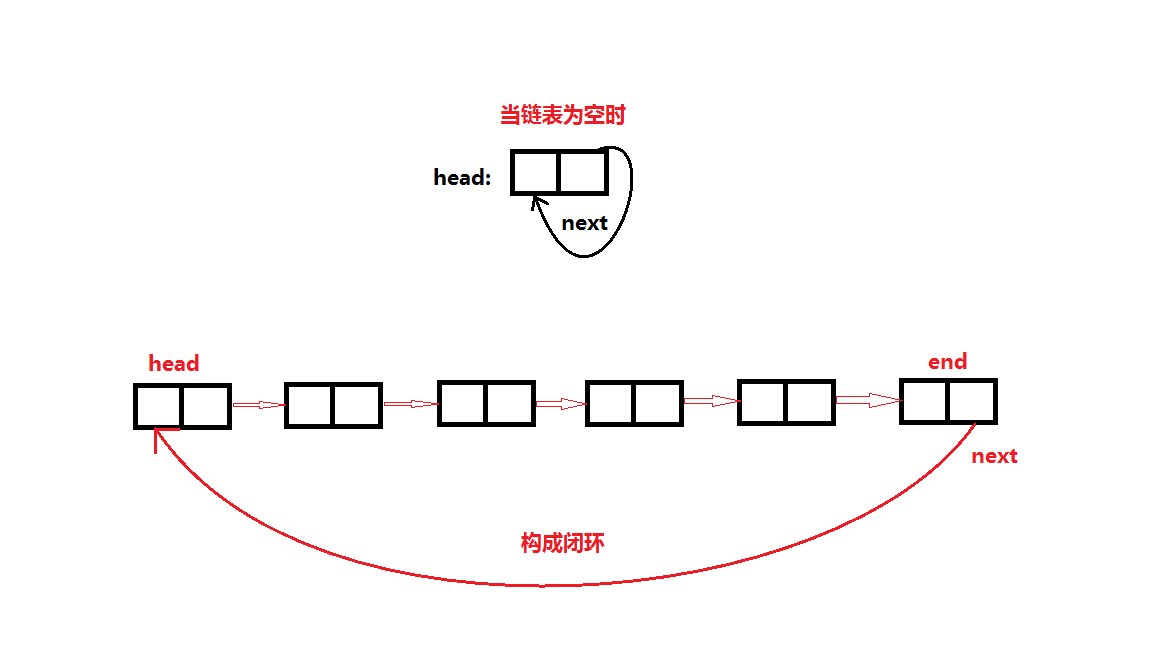

特性:
- 若链表为空,则头结点的next结点还是指向其本身,即head.next=head;
- 尾节点的next指针指向head结点,即头尾相连;
- 判断是否遍历了完,直接判断next==head即可;
- 由单链表变化的循环也成为单向循环链表;
- 循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活;
二、单向循环链表的实现
循环链表是在单链表(线性单链表)的基础上,将尾节点的next指向了head,所以基本的结构是类似的,所以下面,直接贴代码了;


public class LoopChain<T> { //尾结点直接引用 private Node<T> tail; //链长度 private Integer size; //初始化 LoopChain() { tail = new Node<T>(); tail.setNext(tail); } public Node<T> remove(Integer index) throws Exception { //获取该位置的上一个节点 Node<T> s = getNode(index - 1); //获取该位置节点的下一个节点 Node<T> next = getNode(index).getNext(); //将本节点的next节点放在本节点的前一个节点的next节点位置 s.setNext(next.getNext()); return next; } public void add(T t,Integer index) throws Exception { //获取该位置的上一个节点 Node<T> s = getNode(index - 1); //创建新节点 Node<T> p = new Node<>(); p.setObject(t); //将本节点的next节点放入新节点的next节点 p.setNext(s.getNext()); //将新节点放入本节点的next节点位置 s.setNext(p); } public T get(Integer index) throws Exception { return (T)getNode(index).getObject(); } private Node<T> getNode(Integer index) throws Exception { if (index > size || index < 0) throw new Exception("index outof length"); //取头节点 Node<T> p = tail.next; for (int i = 0; i < index; i++) p = p.getNext(); return p; } class Node<T> { private Object object; private Node next; public Object getObject() { return object; } public void setObject(Object object) { this.object = object; } public Node getNext() { return next; } public void setNext(Node next) { this.next = next; } } }
获取元素:
public T get(Integer index) throws Exception { return (T)getNode(index).getObject(); } private Node<T> getNode(Integer index) throws Exception { if (index > size || index < 0) throw new Exception("index outof length"); //取头节点 Node<T> p = tail.next; for (int i = 0; i < index; i++) p = p.getNext(); return p; }
插入元素:
public void add(T t,Integer index) throws Exception { //获取该位置的上一个节点 Node<T> s = getNode(index - 1); //创建新节点 Node<T> p = new Node<>(); //将本节点的next节点放入新节点的next节点 p.setNext(s.getNext()); //将新节点放入本节点的next节点位置 s.setNext(p); }
移除元素:
public Node<T> remove(Integer index) throws Exception { //获取该位置的上一个节点 Node<T> s = getNode(index - 1); //获取该位置节点的下一个节点 Node<T> next = getNode(index).getNext(); //将本节点的next节点放在本节点的前一个节点的next节点位置 s.setNext(next.getNext()); return next; }
在之前学习单链表的时候,我们使用头结点来代表一个链表,可以用O(1)的时间访问第一个节点,但是在访问尾节点时,需要使用O(n)的时间,而循环链表则不同,完全可以使用O(1)的时间来访问第一个节点和尾节点。
三、问题
判断单链表中是否有环?
思考:有环的定义是,链表的尾节点指向了链表中的某个节点;
那么怎么判断是否有环的存在呢?
1、使用p、q两个指针,p总是向前走,但q每次都从头开始走,对于每个节点,p走的步数是否与q走的步数一致,若不一致则说明存在环;
若链表长度为3,当p走完一圈后,会出现p的步数为4,而q的步数为1,不相等,则存在环。
2、使用p、q两个指针,p每次向前走一步,q每次向前走两步,若在某个时候p==q,则存在环;
使用了快慢原理来进行判断是否存在环。
注意:
①循环链表中没有NULL指针。涉及遍历操作时,其终止条件就不再是像非循环链表那样判别p或p->next是否为空,而是判别它们是否等于某一指定指针,如头指针或尾指针等。
②在单链表中,从一已知结点出发,只能访问到该结点及其后续结点,无法找到该结点之前的其它结点。而在单循环链表中,从任一结点出发都可访问到表中所有结点,这一优点使某些运算在单循环链表上易于实现。
本系列参考书籍:
《写给大家看的算法书》
《图灵程序设计丛书 算法 第4版》