MP3文件信息
参考链接:https://www.jianshu.com/p/e368517ec7b9
总结:
ID3V1在MP3文件后面;
ID3V2在MP3文件前面;
现在有些文件是V1的,有些文件是V2的,
在获取信息之前要先判断,是V1,还是V2,
当然还有一些MP3是两个都不存在的,就是我们看到的未知。
一、一个MP3文件大致含有如下3个部分:
TAG_V2(ID3V2) -- TAG_V2的长度不是固定的,包含了众多关于MP3文件的信息(可选)
Frame
TAG_V1(ID3V1) -- TAG_V1的长度是固定的,128byte.期中包含MP3文件的基本信息.(可选)
二、mp3文件各可选部分的含义
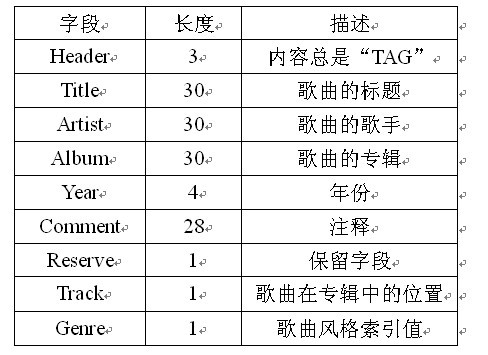
1、ID3v1
ID3V1比较简单,它是存放在MP3文件的末尾,用16进制的编辑器打开一个MP3文件,查看其末尾的128个顺序存放字节,数据结构定义如下:
char Header[3]; /*1-3 3 存放"TAG"字符,表示ID3V1.0标准,标签头必须是"TAG", 否则认为没有标签*/
char Title[30]; /*歌名: 4-33 30*/
char Artist[30]; /*作者: 34-63 30*/
char Album[30]; /*专辑名: 64-93 30*/
char Year[4]; /*年代: 94-97 4*/
char Comment[30]; /*备注: 98-127 30*/
char Genre; /*类别: 128 1 MP3*/
2、ID3V2
ID3V2到现在一共有4个版本,但流行的播放软件一般只支持第3版,既ID3v2.3。
由于ID3V1记录在MP3文件的末尾,ID3V2就只好记录在MP3文件的首部了(如果有一天发布ID3V3,真不知道该记录在哪里)。
正是由于这个原因,对ID3V2的操作比ID3V1要慢。而且ID3V2结构比ID3V1的结构要复杂得多,但比前者全面且可以伸缩和扩展。
2.1、ID3V2.3
每个ID3V2.3的标签都一个标签头和若干个标签帧或一个扩展标签头组成。
关于曲目的信息如标题、作者等都存放在不同的标签帧中,扩展标签头和标签帧并不是必要的,但每个标签至少要有一个标签帧。
标签头和标签帧一起顺序存放在MP3文件的首部。
##############################################################################
mp3 音频 音乐 tag ID3 ID3V1 ID3V2 标签 读取信息
https://blog.csdn.net/u013401219/article/details/48103315
1.mp3标签简介
我们得到一个mp3文件后,通过播放器,或是右击看其属性,我们会发现除了文件大小和名字,还会有一些其他信息。比如作者,类型,年月日,有的还有一个小图片。
这些信息都是在mp3的源文件内。源文件内除了音乐的数据,还会有一些标识性信息。在计算机的世界,几乎所有的文件都是这样,不然系统怎么直到你这一堆二进制代码是什么东西,我要对它做什么。
在mp3的数据内,有多种标签标识它的信息,最常见的就是ID3。一开始是ID3V1,这个标签在mp3的最后128个字节。前3个字节是TAG,用来标识标签的开始。在linux下,你可以用vim直接打开一个mp3文件,移到最后看一下。在windows下可以用UItraEdit。后面不同的标签会有不同的标识符,每个标识符后面就是相应的数据。ID3V1的各标识符的大小都是固定的,很好读取。不过有些限制,就是不能存中文,没有图片,表示的内容也有限。
图:ID3V1标签结构
后来ID3升级到ID3V2。ID3V2有4个版本,现在常见的应该是ID3V2.4,也就是第4个版本。ID3V2的标签在mp3的开头。前10个字节是整个标签的标签头,记录了这个标签的标识,版本,整个标签的大小。前3个是标识位,其值为ID3,表示标签存在,如果前三个字节不是ID3,那就表示没有ID3V2的标签。然后一个字节是版本号,下一个字节为副版本号,再下一个是标志位。这三个字节都没太大用。最后4个字节是标签的大小,这个挺重要。
图:ID3V2标签结构
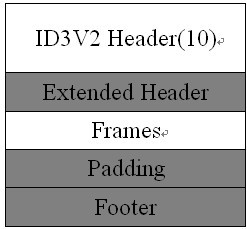
图:ID3V2头结构

说一下这四个字节是如何计算标签大小的。你最好用BYTE类型或是unsigned char类型类保存这四个字节,如果高位为1,会被认为负数。不过这里不用怕这个,因为这四个字节的每一个字节的最高位都是0,况且计算时去掉这四位。什么意思呢?就是本来是用4个字节,也就是32位的二进制数来表示标签大小,在这里把最高位都制为0,并且去掉,不加入计算。也就相当于是28位2进制数来表示标签大小。具体原因不明,反正成为了规定,就遵循吧。计算公式:
int Len = (size[0]&0x7f)*0x200000
+(size[1]&0x7f)*0x4000
+(size[2]&0x7f)*0x80
+(size[3]&0x7f);
得到的数就是标签的大小,也就是多少个字节。但是这个大小是不包括标签头的10个字节的。
读完这10个标签头的字节,再往下读10个字节就是标签帧的帧头了,和标签头的10个字节一样,它也记录了标签帧的大小,标签的内容和标志。
char FrameID[4]; /*用四个字符标识一个帧,说明其内容*/

+size[1]*0x10000
+size[2]*0x100
+size[3];
1代表字符使用UTF-16编码方式;
2代表字符使用 UTF-16BE编码方式;
3代表字符使用UTF-8编码方式。
目前只有4中编码方式,你可以计算第一个字节的大小,然后和这个表对应,就能直到使用什么编码方式保存的数据了。
如果是0或是3这两种编码方式的话,你就用一个char的数组去读这个数据,然后输出,就是你想要的内容。
如果是1或2这两种编码的话,那就要用宽字节数组去读,就是wchar_t声明的数组读取。
记住要跳过第一个字节。
3.读取图片
如果你想读取mp3里面的专辑图片的话,就要找到APIC标签,然后计算出标签大小。APIC标签的数据部分也比较特殊,首先在数据的前几个字节里面,并没有图片的数据,而是告诉你这里保存的图片数据是什么格式的,大部分都是jpeg的,因为占地小。
在数据部分前几个字节会出现一个特殊标志 image/jpeg 来标明下面的数据是jpeg格式的,如果是其他格式则为image/png image/bmp,jpeg的格式可能会有jpg peg等格式来表示。也就是image/jpg 也表示是jpeg的。
然后开始读取图片数据,在image/jpeg这个标志后面就保存了图片的数据,不过并不是image/jpeg结束后第一个字节就是图片数据,在这里image/jpeg出现的位置和图片的数据开始的位置都是不固定的,就是在它们前后可能都有一些空字节,所以要判断一下。
我们查询jpeg的图片格式可以知道当连着的两个字节是16进制0xFFD8时,就表示图片的数据开始的位置,所以你要从这里开始读,包括0xFFd8也要读进去,也就是FF是第一个字节,D8是第二个字节,然后往下读,直到读到连续两个字节是0xFFD9,这就表示图片数据读完了,记住也要把这两个结束字符读进去。
前面我们已经计算出这个APIC的大小,你可以用这个大小减去不是图片数据的字节数,从0xFFD8开始读剩下的字节数就可以了。
我们把读到的数据放到数组里,然后写到一个空文件里,就是一幅jpeg的图片了
4.图片转换
得到jpeg图片后,如果我们想转换成其它图片,那么就需要进行图片转码了。jpeg图像之所以很小,是因为里面进行了多次压缩。先要把计算机上常用的RGB图像源数据转换成YCrCb,然后进行DCT变换,重排DCT结果,量化,这样就会是图像数组的左上角是相似的数字,剩下的大部分是0。然后是RLE编码,huffman编码。最后编出来一堆你不认识的值,加上各种段,标志,保存成jpeg。所以如果我们想转换成其它图片的话,就要反着来一边。这个工作比较麻烦,也比较复杂。所以我们可以用第三方的库来实现。我这里用的是jpeglib。
然后下载jpegsr8d.zip包。虽然它写着是for windows的,其实里面是一个linux下的工程,你需要的东西必须编译一下,才能生成。
在包的里面有一个install.txt的文档,里面告诉你在不同的环境下如何编译,我截取一段在windows下用vs2010编译的部分:
Microsoft Windows, Microsoft Visual C++ 2010 Developer Studio (v10):
We include makefiles that should work as project files in Visual Studio
2010 or later. There is a library makefile that builds the IJG library
as a static Win32 library, and application makefiles that build the sample
applications as Win32 console applications. (Even if you only want the
library, we recommend building the applications so that you can run the
self-test.)
To use:
1. Open the command prompt, change to the main directory and execute the
command line
NMAKE /f makefile.vc setup-v10
This will move jconfig.vc to jconfig.h and makefiles to project files.
(Note that the renaming is critical!)
2. Open the solution file jpeg.sln, build the library project.
(If you are using Visual Studio more recent than 2010 (v10), you'll
probably get a message saying that the project files are being updated.)
3. Open the solution file apps.sln, build the application projects.
4. To perform the self-test, execute the command line
NMAKE /f makefile.vc test-build
5. Move the application .exe files from `app`Release to an
appropriate location on your path.
Note:
There seems to be an optimization bug in the compiler which causes the
self-test to fail with the color quantization option.
We have disabled optimization for the file jquant2.c in the library
project file which causes the self-test to pass properly.
也就是先执行NMAKE /f makefile.vc setup-v10,然后用vs打开jpeg.sln工程,编译一下,然后打开apps.sln工程,里面有好几个工程,每一个都编译一遍,这时候你得到这四个文件:jconfig.h jmorecfg.h jpeg.lib jpeglib.h,把它们放到你的工程目录下,然后在程序开始包含头文件的时候包含进去就可以了。然后上网搜一下copy 粘贴最多的那片文章,把里面代码稍微改一下就可以用了。后面的命令是测试用的,不用管。
如何执行NMAKE /f makefile.vc setup-v10?先打开开始菜单,找到visual studio2010的文件夹,找到visual studio tools,然后在里面打开x64 cross tools command,进入到makefile.vc目录下,也就是你解压的目录下,执行就可以了。在这个command下切换目录是,先输入文件所在盘符名,比如C:,回车,然后cd 加文件名进入即可。
这个第三方库帮我们把jpeg的解码都做了,我们获得其中的图像数据RGB,然后上网查一下bmp的格式,然后把那篇拷贝粘贴最多的程序,改一下把数据写进去就可以了。
bmp格式很简单,只有两个头标签,然后是把RGB数据写到标签后面就行了,没有压缩,所以比jpeg大十几倍或几十倍。