这一节本来打算讲解HRegion的初始化过程中一些比较复杂的流程。不过,考虑前面的博文做的铺垫并不够,因此,在这一节,我还是特意来介绍HBase的CF持久化。关于这个话题的整体流程性分析在博文《HBase数据持久化之HRegion.flushcache即CF持久化》中已经介绍过,大家最好先看一下我的上篇博文,然后再看这个系列(这个系列我预计会通过三篇博文来详细讲解)。可以说,《HBase数据持久化之HRegion.flushcache即CF持久化》是CF持久化的概述,而本节是CF持久化过程中关键流程的一个详细描述。由于该系列比较复杂,因此,该系列中涉及到WAL的知识点或者其他的无关的知识点我都略过,单就介绍CF持久化的相关信息。
由于在上篇博文中,我已经将HRegion.internalPrepareFlushCache流程讲解的比较详细,因此,该系列的三篇文章都从HRegion.internalFlushCacheAndCommit讲起。
由于在博文《HBase数据持久化之HRegion.flushcache即CF持久化》中已经介绍过方法HRegion.internalFlushCacheAndCommit中的一些流程,但是某些方法讲的比较粗略。因此,我在这一节从DefaultStoreFlusher.flushSnapshot方法讲起,下一节从StoreFlusher.finalizeWriter开始讲起,第三节我将分析HStore.validateStoreFile。至于CF持久化流程中涉及到其他知识点的,我会在CF持久化系列(杂记)中一一介绍。
在这一节,我不再粘贴大量的图,尽量使用文字来进行描述,必要的时候,我会贴图来说明。虽然这样说,但是,由于该系列比较复杂,因此,在本篇博客,我可能还是会贴不少的图。
首先,让我们来到流程性的方法DefaultStoreFlusher.flushSnapshot。这里有几个关键的步骤。
1.调用内部的createScanner方法,构造了StoreScanner,这里是本节的一个重点。
2.调用HStore.createWriterInTmp方法构建了一个StoreFileWriter,该方法的流程在本节中比较复杂,但其功能可以比较简单的概括——确定CF的目录文件,并且在其目录文件上创建对应的输入流(这里我们只讨论文件系统为HDFS的情况)
3.调用内部的performFlush,将每一行信息写入到上面创建的StoreFileWriter.HFileWriterImpl.HFileBlock.Writer.userDataStream(大家这里看的可能比较懵逼,没有关系,耐心往后面看,这里是本节的重点,在这里有一个印象就好)。
4.调用内部的finalizeWriter方法,该方法将上一步中保存的行信息写入到HFileWriterImpl.outputStream,包括布隆过滤器的值,blockIndex、File info、FixedFileTrailer中的信息。
5.将上面获取到的store.scanInfo关闭
6.将CF的目录保存到待返回的结果值中。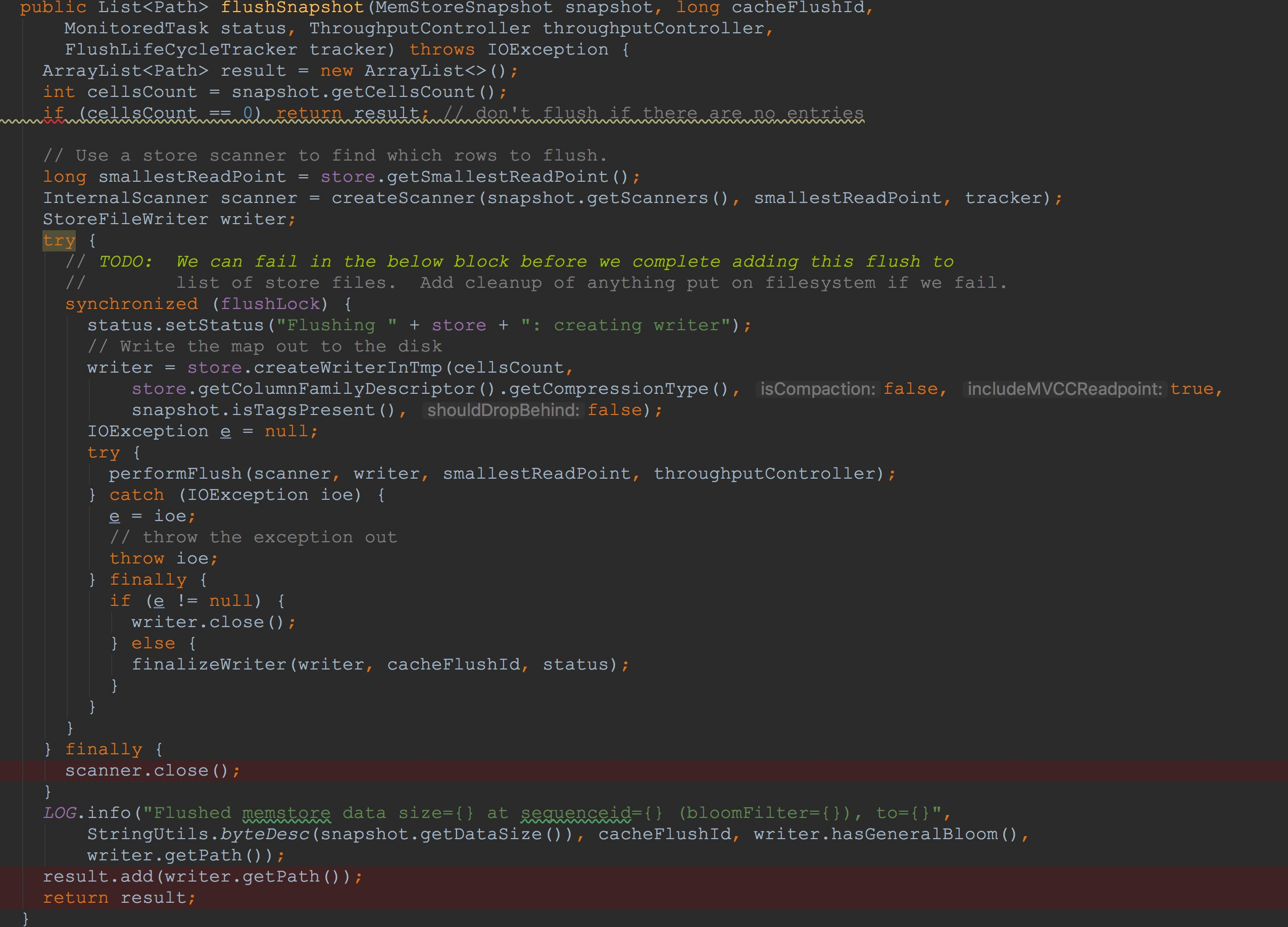
在createScanner方法内部,主要调用了StoreScanner构造方法,如下图所示。这里相对比较复杂。
1.调用了内部的另外一个构造方法,完成部分成员变量的初始化。
2.调用selectScannersFrom,会根据TLL等条件筛选出一部分scanners
3.调用seekScanners,这里将根据matcher.getStartKey()中的row与family筛选出该scanner。由于其内部使用了NavigableMap类型,以传入的matcher.getStartKey()为NavigableMap.tailMap的入参,就可以获得大于等于该值的所有cell。该方法的主要作用就是遍历入参scanners,并且初始化每个scanner中的关键性成员变量iter与current。这里的具体流程我在接下来还会着重讲解。
4.调用addCurrentScanners将入参scanners中的值都添加到其成员变量currentScanners中。
5.调用resetKVHeap初始化了成员变量heap。这里的具体流程我也会着重讲解。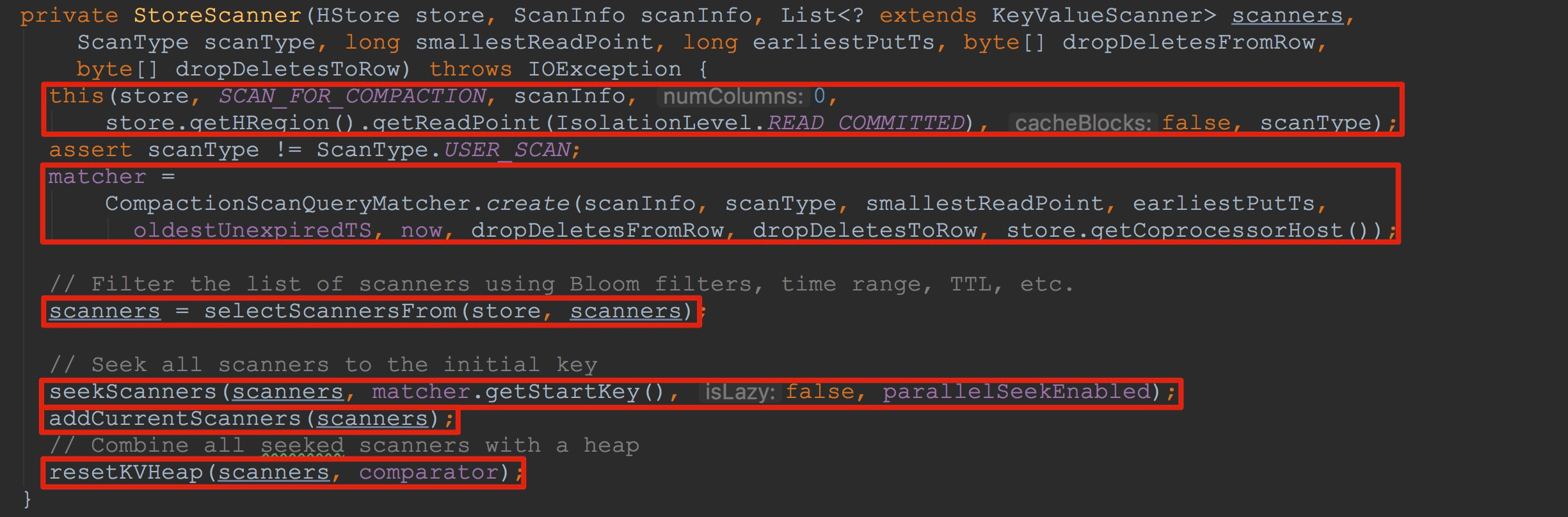
首先,让我们分析方法seekScanners。在该方法内部值得注意的方法是调用了scanner.seek(scanner类型为SegmentScanner),这里的seek方法就是用于初始化scanner的成员变量iter与current。
让我们来到SegmentScanner.seek,如下图所示,这里有两个比较重要的方法——getIterator、updateCurrent。
1.这里的getIterator方法比较琐碎,细讲吧,有种鸡肋的感觉,不细讲吧,却是一个知识点。不过,为了后面方便理解,我还是不偷懒了,为大家细细讲解一番。
2.调用updateCurrent,获得上面iter.next值,并赋给成员变量current。
这里首先介绍方法getIterator,如下图所示。这里调用了Segment.tailSet。
接下来让我们来到Segment.tailSet。如下图所示。这里调用getCellSet方法获得成员变量cellSet中的值,其cellSet类型为AtomicReference。然后调用CellSet.tailSet。
然后,我们来到CellSet.tailSet,如下图所示。这里我需要说明一点CellSet实现了接口java.util.NavigableSet,而且这里的delegatee类型为NavigableMap。也就是说,这里将delegatee中大于等于(入参inclusive为true)fromElement的值封装为NavigableSet返回,并且作为新构建的CellSet的入参。
到这里getIterator方法的流程就介绍完了。至此,我们也明白了,返回的iterator就是新构建的CellSet.iterator。
接下来,让我们来到updateCurrent。如下图所示。看到这里,我相信大家就明白许多了。没错,这里迭代iterator,将其中符合条件的值赋给了成员变量current。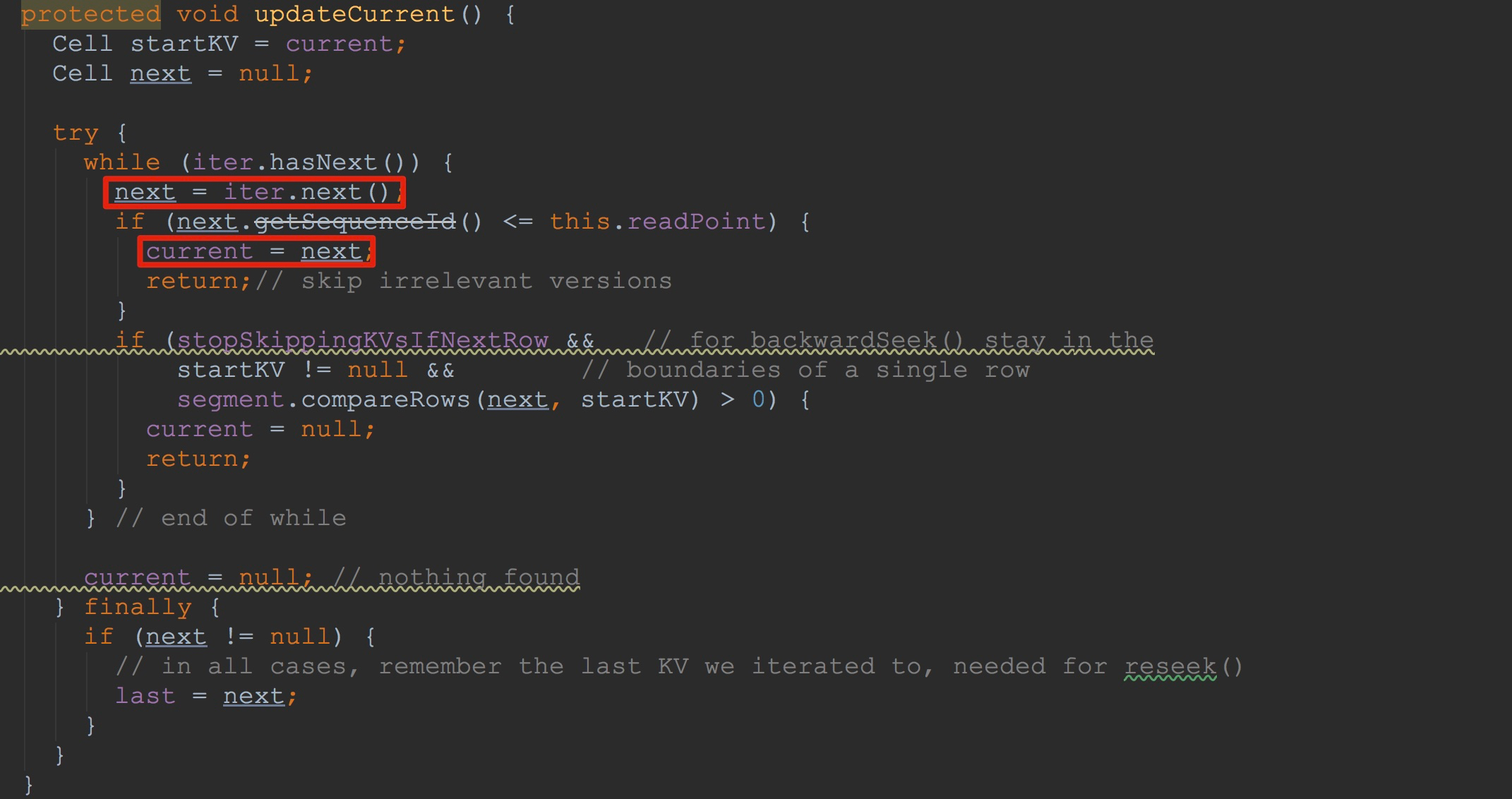
然后,调用方法resetKVHeap,将刚刚初始化好的scanners封装到KeyValueHeap中,并赋给成员变量heap。
这里,让我们简单看一下KeyValueHeap的构造函数,有利于我们在后面的理解。如下图所示,这里初始化了其成员变量heap,并且将入参中的scanners一一添加到成员变量heap中。然后调用方法pollRealKV,将其返回值用于初始化成员变量current。
在HStore.createWriterInTmp方法中主要构建了StoreFileWriter。首先,让我们来到StoreFileWriter.Builder.build方法。
1.这里首先查看CF所在的目录是否存在,如果不存在,则创建。
2.在CF所在目录下指定随机文件,该文件名通过UUID随机生成(注:这里并没有创建文件)。
3.调用StoreFileWriter的构造方法。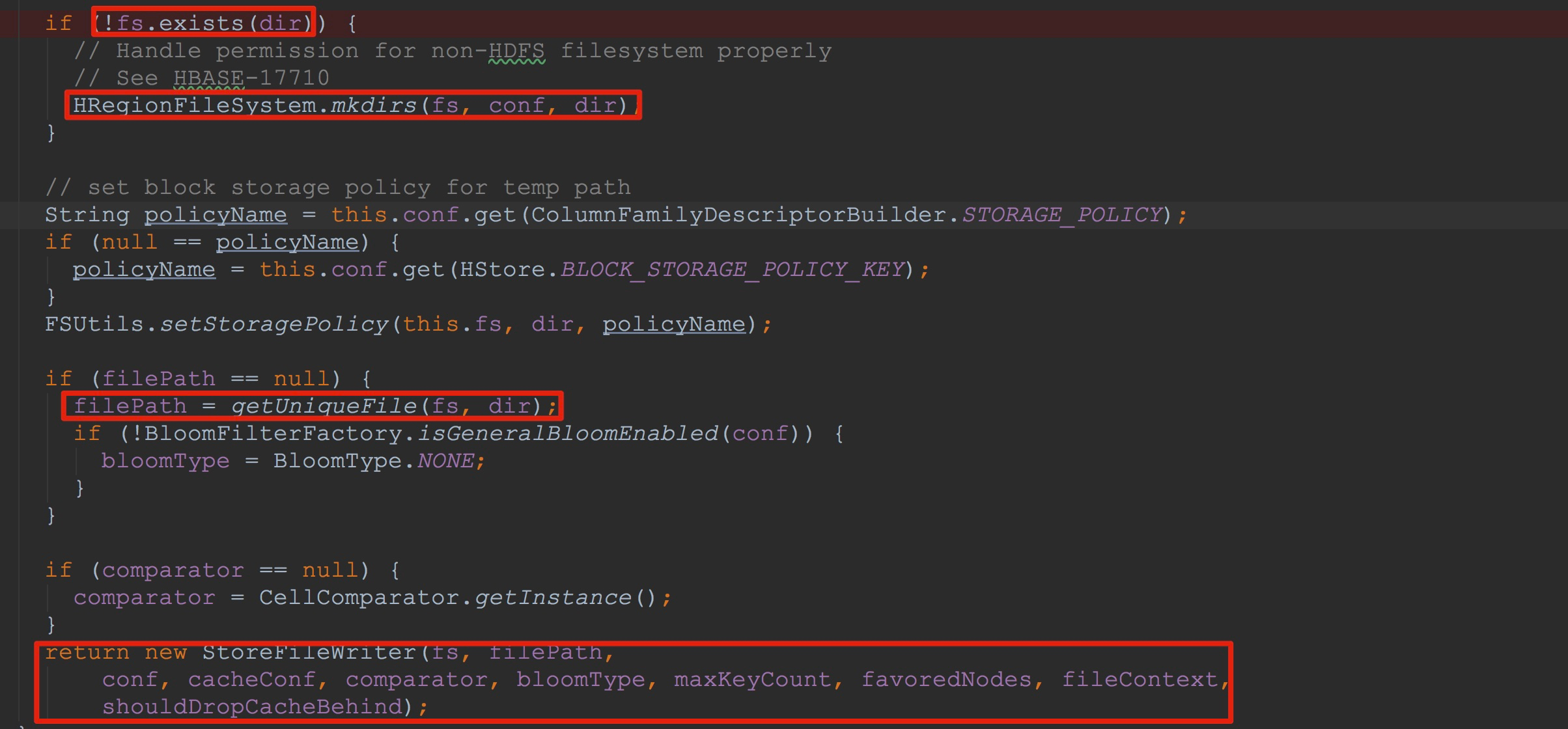
然后,来到StoreFileWriter的构造方法:
1.其内部首先通过HFile.WriterFactory创建了HFileWriterImpl。
2.调用BloomFilterFactory.createGeneralBloomAtWrite创建CompoundBloomFilterWriter,并且赋给成员变量generalBloomFilterWriter
3.这里我们分析传入的bloomType为ROW的,可以看到,其使用刚刚创建的generalBloomFilterWriter构建了RowBloomContext
4.同样,调用BloomFilterFactory.createGeneralBloomAtWrite创建CompoundBloomFilterWriter,赋给成员变量deleteFamilyBloomFilterWriter。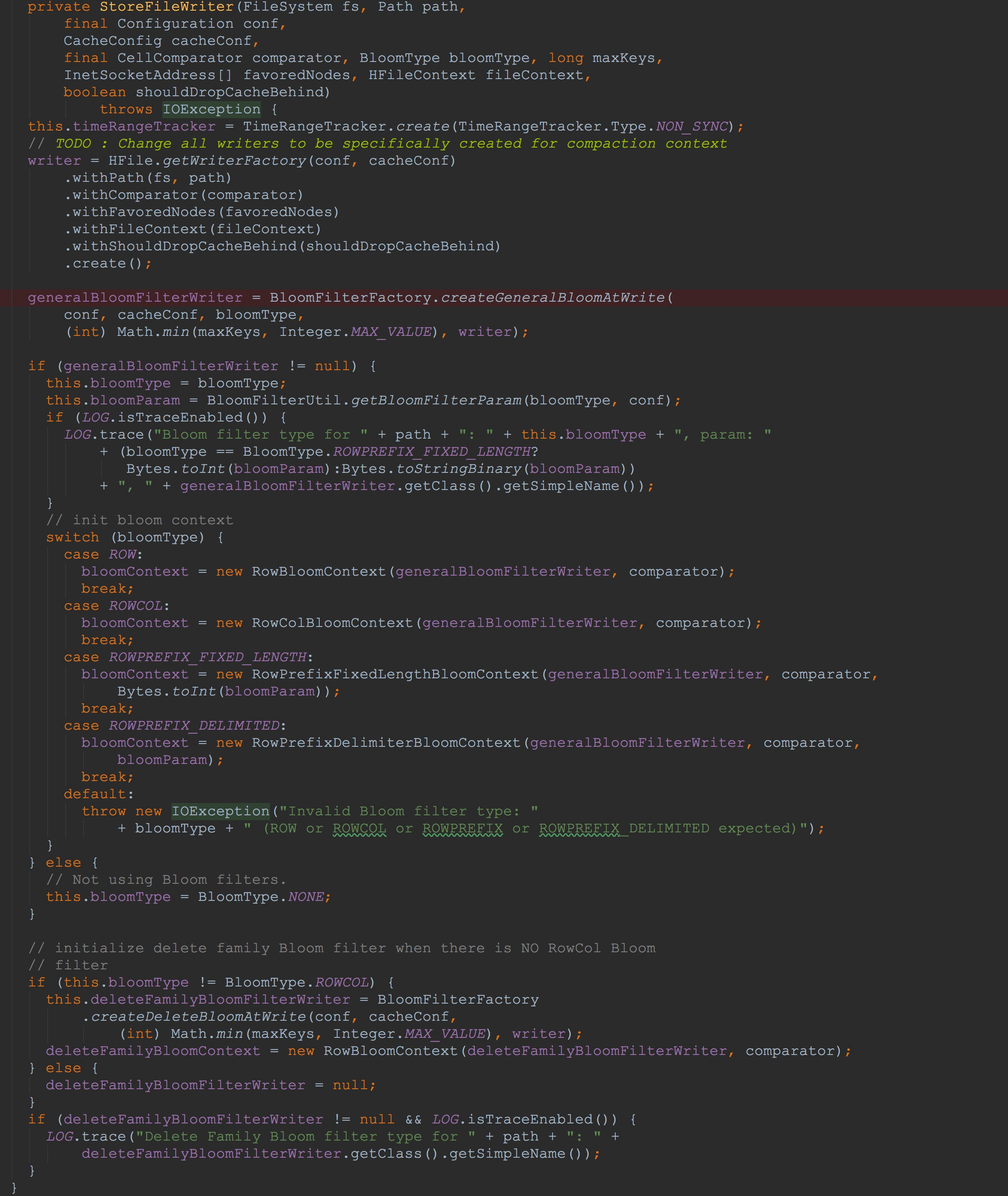
上面流程中,最主要的是创建了HFileWriterImpl。接下来让我们来到HFile.WriterFactory.create。
1.调用HFileWriterImpl.createOutputStream创建并获得文件的输出流,注意,这里的文件就是在StoreFileWriter.Builder.build中构建的文件。
在这里我们只关心文件系统为HDFS的情况。这里内部会调用FSUtils.create。如下图所示,这里通过反射方式调用了DistributedFileSystem.create方法。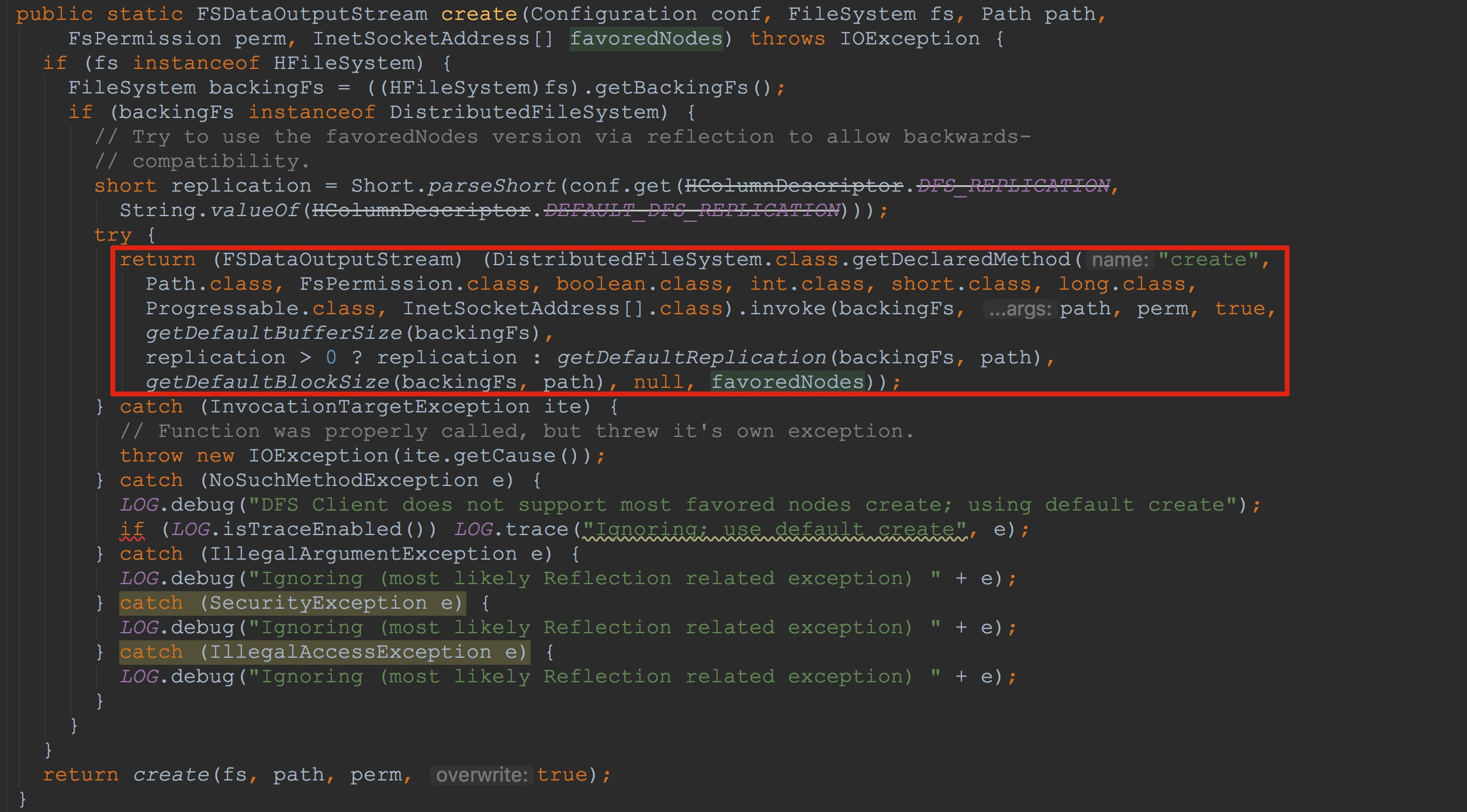
2.调用HFileWriterImpl构造方法。注意,这里将刚刚获得的输出流传入了HFileWriterImpl的构造方法中(这里是重点,我在后面将详细讲解)。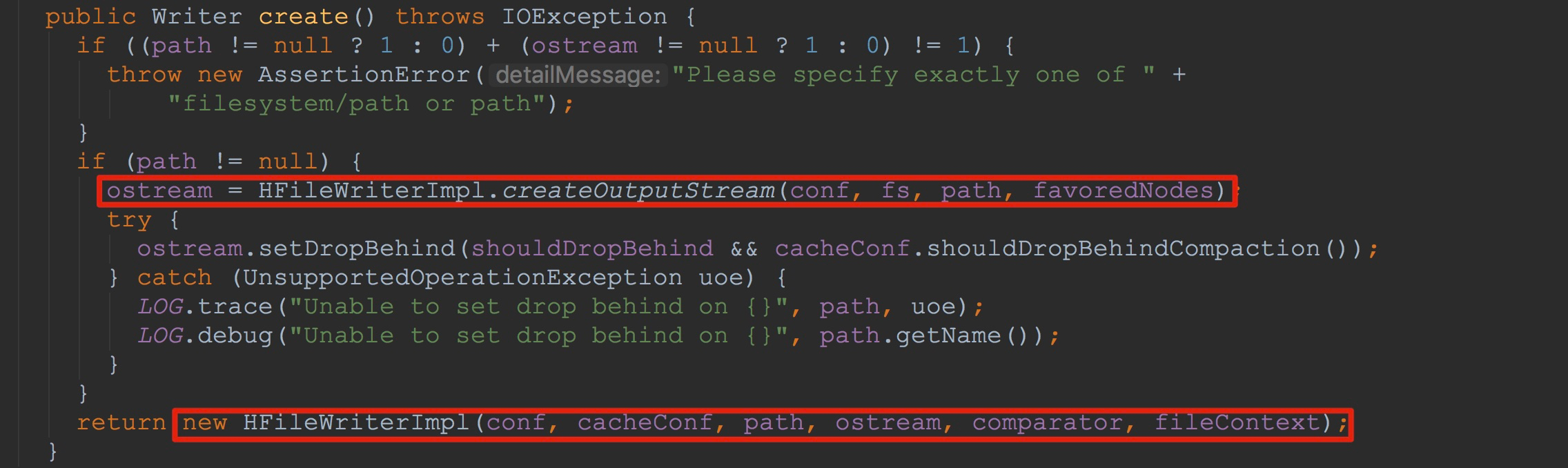
让我们来到HFileWriterImpl的构造方法中,如下图所示。
1.这里将传入的输出流赋给了成员变量outputStream
2.然后将NoOpDataBlockEncoder.INSTANCE赋给成员变量blockEncoder
3.调用了内部方法finishInit,完成了另一部分成员变量的初始化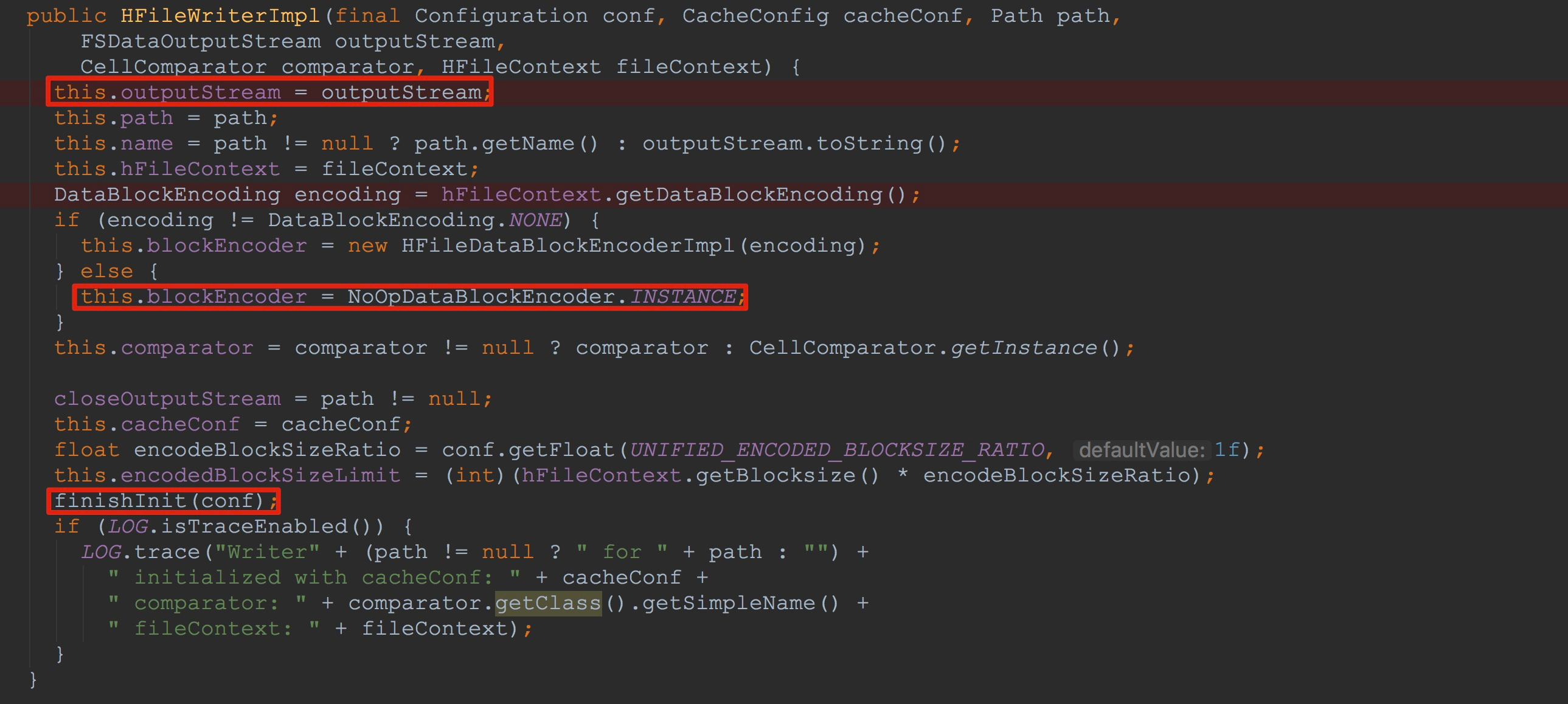
来到finishInit,如下图所示,这里连续完成了成员变量blockWriter、dataBlockIndexWriter、metaBlockIndexWriter的初始化。这里,我要着重讲一下HFileBlock.Writer构造函数。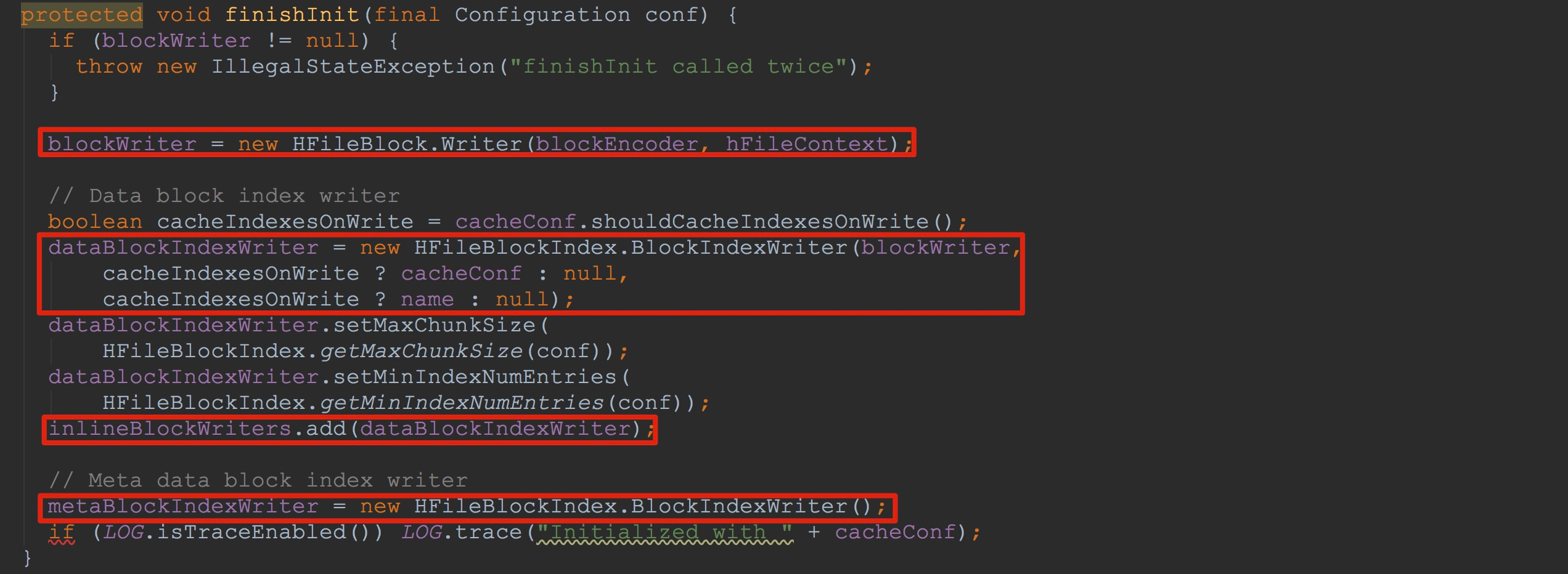
接下来让我们来到HFileBlock.Writer的构造函数。如下图所示,这里将传入的dataBlockEncoder赋给了成员变量dataBlockEncoder。另外,分别初始化了dataBlockEncodingCtx、defaultBlockEncodingCtx。由于这里的dataBlockEncoder实际类型为NoOpDataBlockEncoder,因此,这两个成员变量最后调用的方法其实是一样的,都调用了HFileBlockDefaultEncodingContext构造方法。然后初始化了成员变量baosInMemory,而这个成员变量可以说是本节的核心。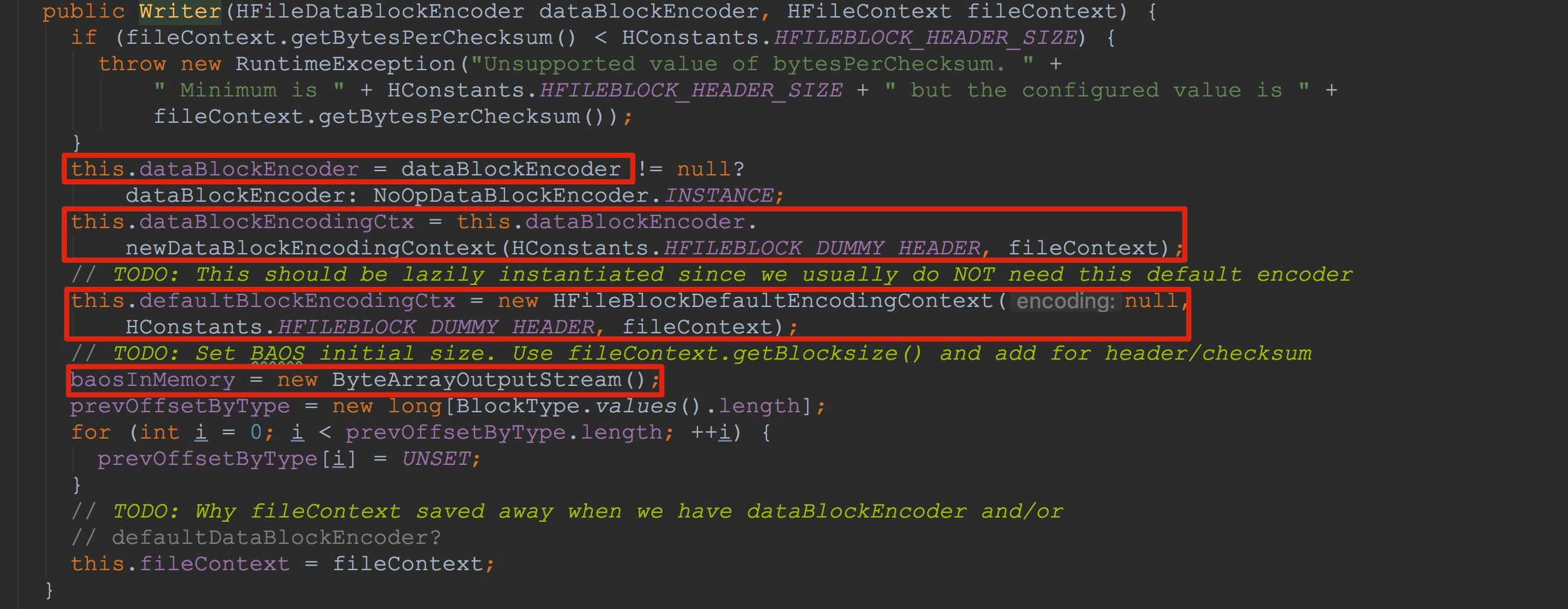
至此,我们就完成了StoreFileWriter的初始化过程。也就是本节的主线——HStore.createWriterInTmp方法调用完成。
然后,来到StoreFlusher.performFlush。
1.调用scanner.next,获取下一条行数据,并且在其方法内部调用了heap.next,更新了heap.KeyValueScanner.current的值。这里的scanner类型为StoreScanner,也正是文章一开始构造的那个StoreScanner。该方法的详细流程我还会在后面谈到。
2.接下来调用sink.append方法,将入参c中的cell信息写入到sink中。大家还记得这里的sink吗,他的实际类型是我在上面谈到的StoreFileWriter。该方法比较复杂,也是本节中的重点之一,我将在后面讲解。
3.将kvs中的值清空,以便下一次迭代。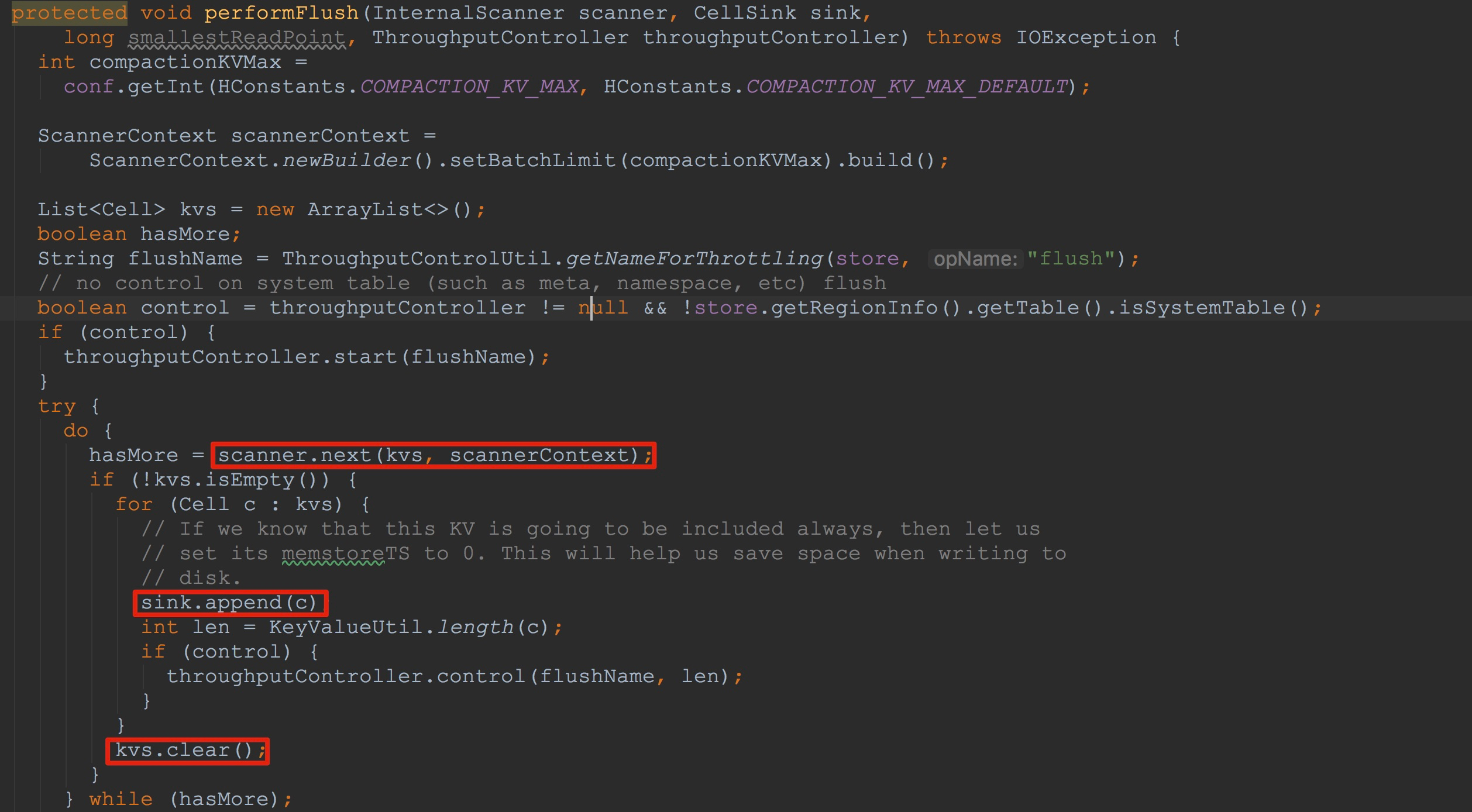
让我们首先来到scanner.next,也就是StoreScanner.next的详细流程。该方法比较长,为了避免讲解混乱,我这里就只介绍方法调用中比较重要的两个方法——heap.peek、heap.next。这里的heap类型为KeyValueHeap。因此,我们来到KeyValueHeap.peek与KeyValueHeap.next方法,如下图所示。大家可能忘记了这里的current的实际类型,我简单提醒一下,他的实际类型是文章开始谈到的SegmentScanner。
1.调用SegmentScanner.peek,获取其成员变量current的值。
2.调用SegmentScanner.next,其内部调用了方法updateCurrent(我在上面已经提到过),他的作用是更新内部成员变量current的值。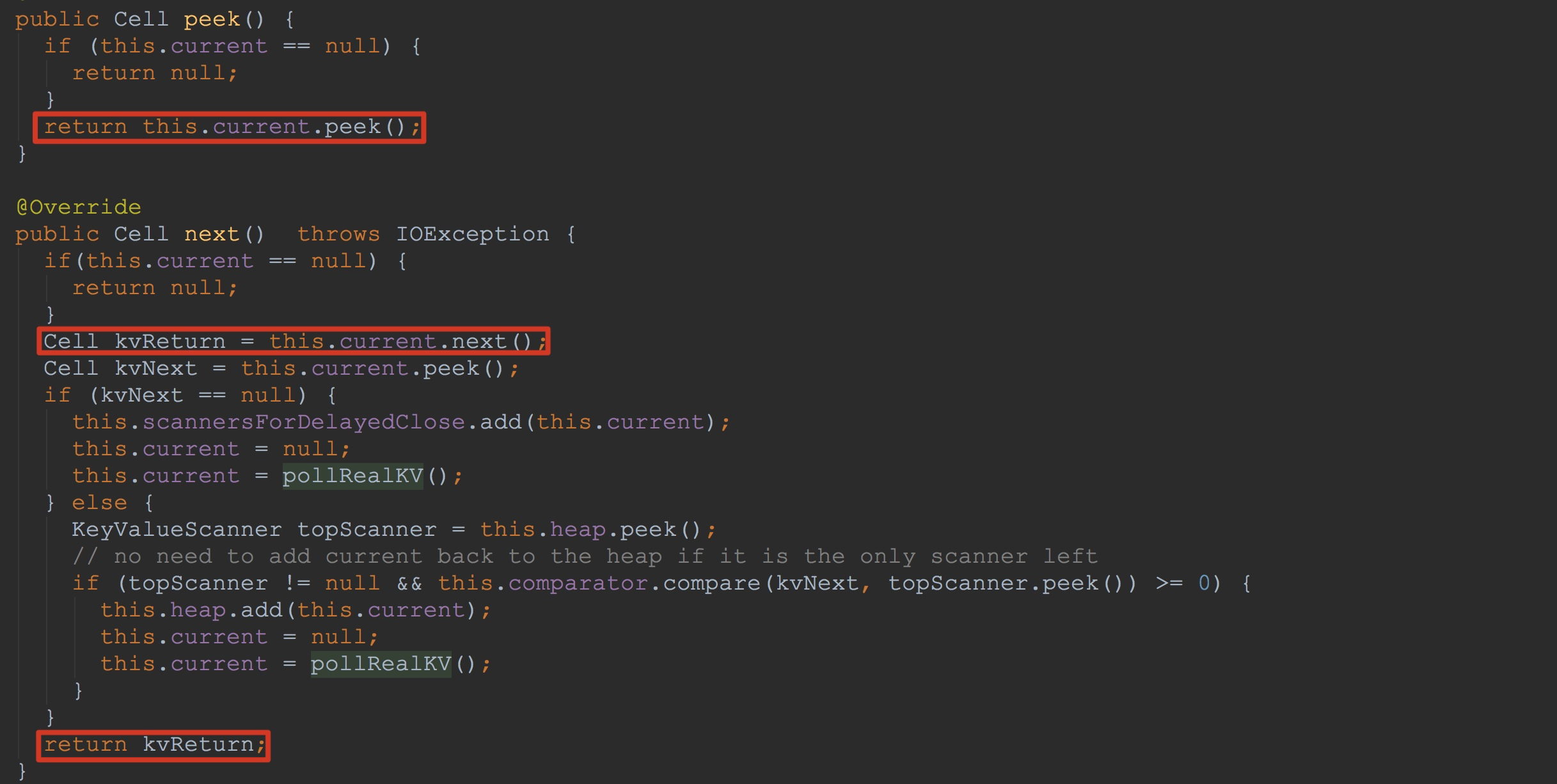
接着,让我们来到sink.append,也就是StoreFileWriter.append。该方法是本节中最为复杂的,希望大家特别留意。让我们来到其方法内部,如下图所示。
1.首先调用appendGeneralBloomfilter,其内部调用了bloomContext.writeBloom(上面分析过,这里的bloomContext类型为RowBloomContext),这里的内容我接下来会详细讲解。
2.调用writer.append。这里的调用将cell值写入到HFileBlock.Writer.userDataStream(也就是上面提到的)。至于详细的流程,我会详细讲解。
首先,让我们关注appendGeneralBloomfilter。其内部的调用比较简单,调用了bloomContext.writeBloom,这里的bloomContext类型为RowBloomContext,其内部的bloomFilterWriter类型为CompoundBloomFilterWriter。在方法bloomContext.writeBloom中调用了bloomFilterWriter.append。因此,让我们来到CompoundBloomFilterWriter.append,如下图所示。
1.这里首先调用enqueueReadyChunk,以确保成员变量chunk仍然有空间写入,如果没有,则将其封装到ReadyChunk中,然后加入到成员队列readyChunks中,并将chunk置空,以期后面的调用将其重新分配。
2.如果成员变量chunk为空,则将当前cell值copy并赋给成员变量firstKeyInChunk
3.调用allocateNewChunk,这里比较重要,后面我还是简单讲一下。
4.将入参cell加入到chunk中,需要注意的是这里的cell类型为BloomFilterChunk。关于这里的布隆过滤器的使用,我将在后面专门拿出一章来讲解。这里就不详细介绍了。
让我们来到allocateNewChunk,如下图所示。看到这里,相信大家就很清楚了。这里首先构建了BloomFilterChunk(在BloomFilterUtil.createBySize方法内),然后调用chunk.allocBloom,为chunk内部的bloom(ByteBuffer类型)分配指定的字节。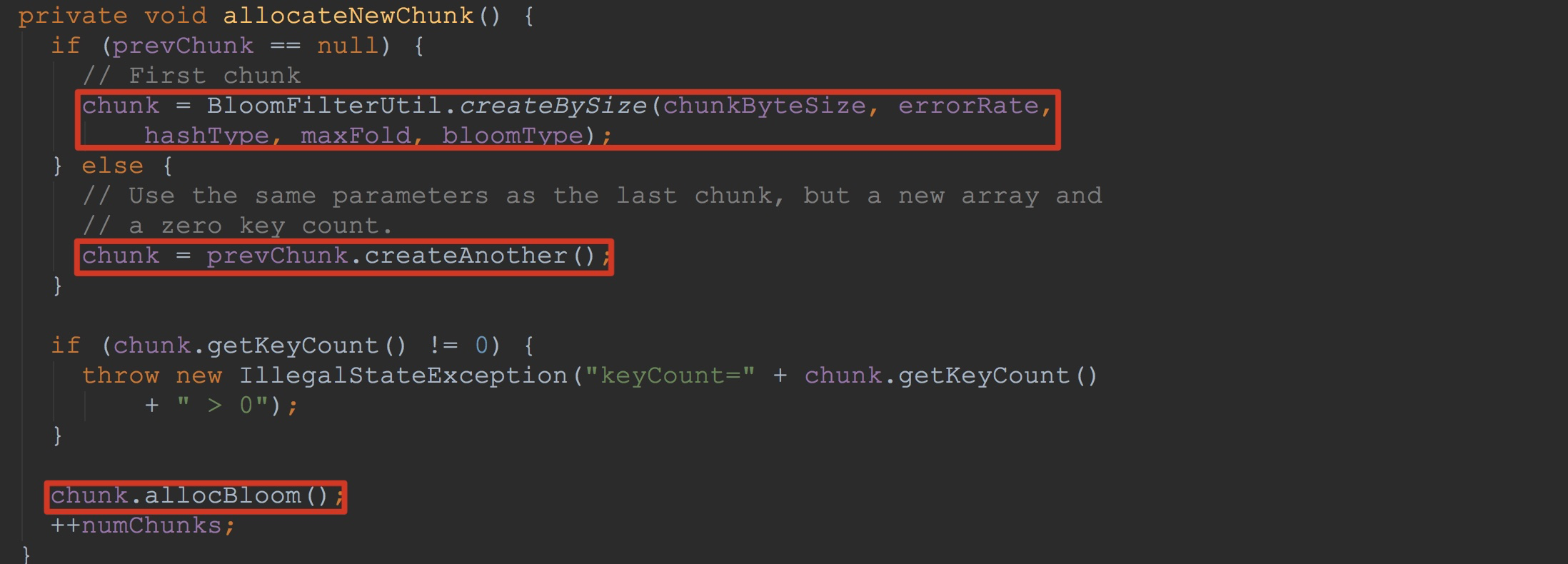
到此,大家对于其中的bloomContext.writeBloom方法应该有了一个比较明确的了解。
接下来,我来为大家详细介绍writer.append,也就是HFileWriterImpl.append。如下图所示。
1.由于这是首次写入,因此这里会调用newBlock,这里主要是后面blockWriter.write的调用做准备,具体的细节还是比较重要的,我将放在后面来讲解。
2.调用blockWriter.write方法,将cell信息写入HFileBlock.userDataStream(这里比较重要)。
3.判断是否将入参cell赋给成员变量firstCellInBlock
4.将入参cell赋给成员变量lastCell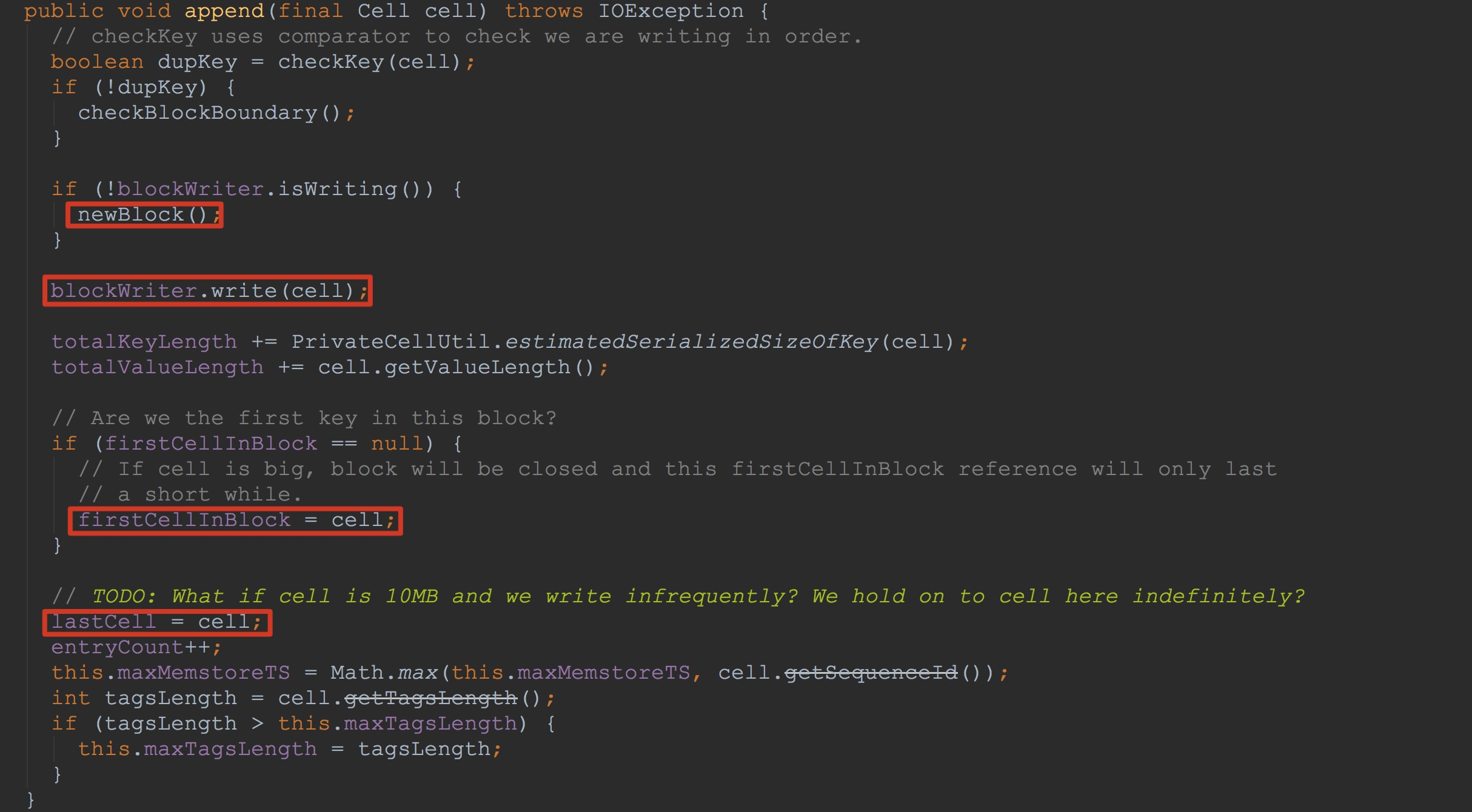
让我们首先关注方法newBlock。在其内部主要调用了blockWriter.startWriting(BlockType.DATA),这里的入参为BlockType.DATA,需要格外注意。让我们来到HFileBlock.startWriting。
1.这里的baosInMemory在Writer构造时已经实现了初始化。这里调用其reset,为下一次完整的写入做准备。
2.调用baosInMemory.write,这里已经开始写入。而HConstants.HFILEBLOCK_DUMMY_HEADER是一个空的header。在后面调用finishBlock中,会将这里的内容填充(这里的具体内容我会在后面finishBlock中分析,大家有一个概念就好)。
3.将baosInMemory封装到userDataStream,后面都会通过userDataStream将内容简介写入baosInMemory。看到这里,大家可能就会明白我在上面提到的StoreFileWriter.HFileWriterImpl.HFileBlock.Writer.userDataStream。不清楚也没有关系,后面我还会详细讲解,这里是本节的重点。
4.由于入参格式为BlockType.DATA,因此这里会调用dataBlockEncoder.startBlockEncoding。这里完成了dataBlockEncodingCtx.encoderState的初始化,为后面将cell写入userDataStream做前期准备。由于我们这里的dataBlockEncoder类型为NoOpDataBlockEncoder,因此,接下来,我们来到NoOpDataBlockEncoder.startBlockEncoding。这里需要注意的是,第一个入参为成员变量dataBlockEncodingCtx,二个入参为封装了baosInMemory的userDataStream。后面还会用到这两个变量,希望大家紧记。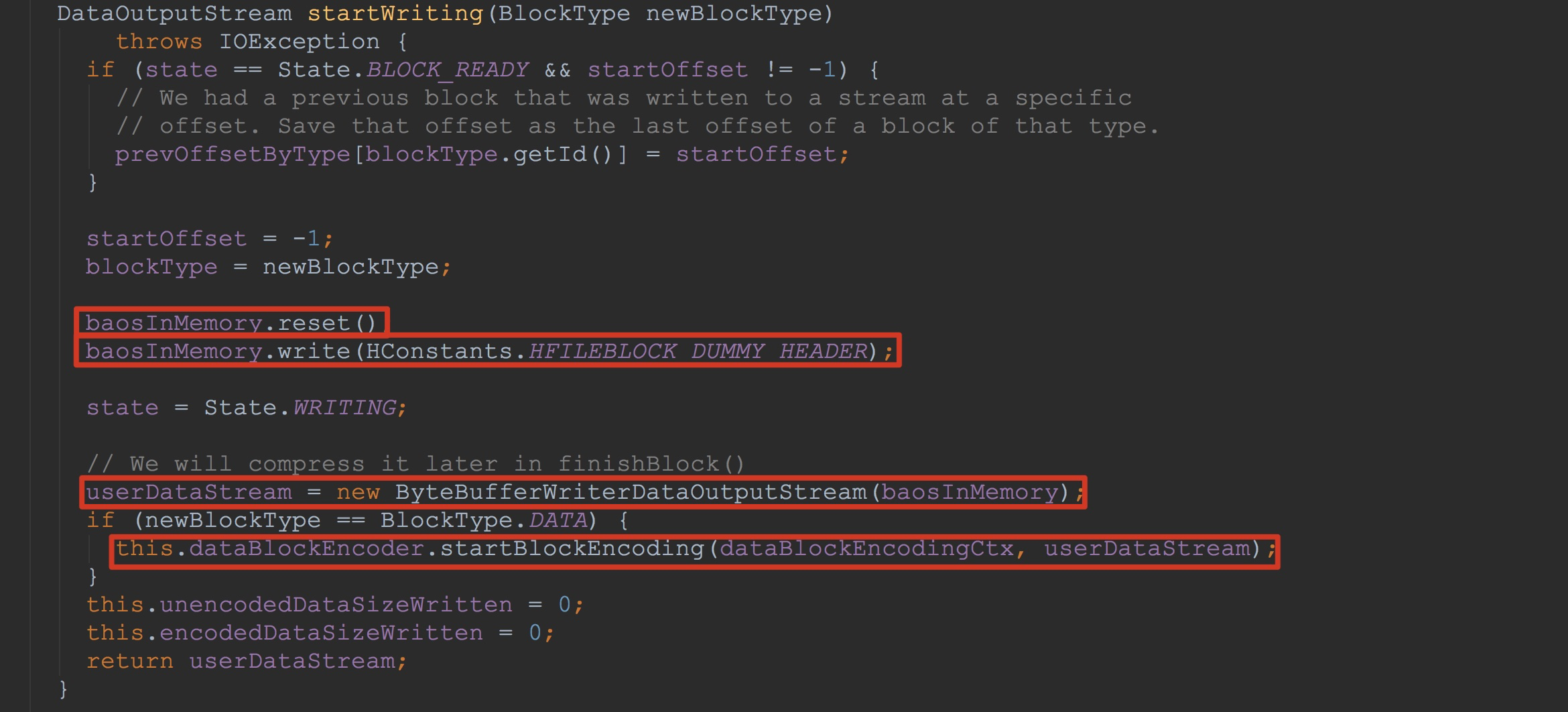
如下图所示,我们来到NoOpDataBlockEncoder.startBlockEncoding。
1.这里将入参中的out封装到新构造的encoder
2.将封装了刚刚构造的encoder封装并赋给入参blkEncodingCtx.encoderState,也就是说,这里的blkEncodingCtx.encoderState将入参中的out也封装进去了。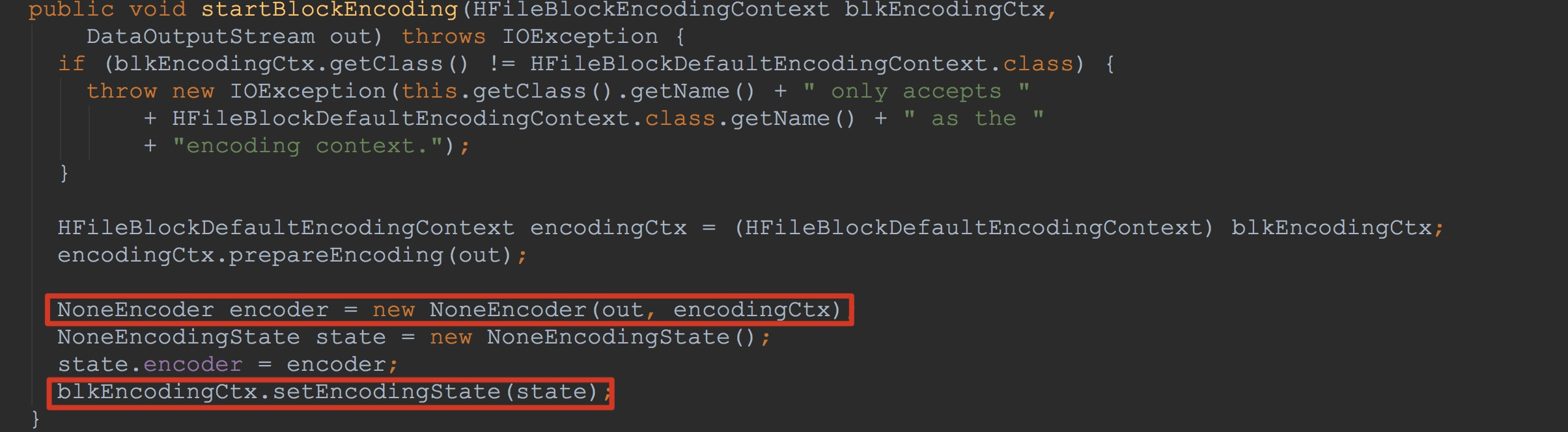
到这里,方法newBlock的调用就完成了,这里主要为后面数据的写入做了前期的准备。
接下来我们来分析blockWriter.write。
1.这里的userDataStream的就是上面刚刚构造的,其封装了baosInMemory
2.调用了dataBlockEncoder.encode,这里的第二个入参就是上面介绍的成员变量dataBlockEncodingCtx。当然,这里的dataBlockEncoder类型为NoOpDataBlockEncoder。
因此,接下来,让我们来到NoOpDataBlockEncoder.encode。如下图所示,这里获得入参的encodingCtx.encoderState。然后获取其encoder,并且调用encoder.write。
让我们来到NoneEncoder.write,如下图所示。这里我将其中的构造方法也顺带粘了过来。这里调用KeyValueUtil.oswrite。这里的out就是上面的userDataStream。
在KeyValueUtil.oswrite完成了将cell中内容写入到out的功能。其流程还是一个知识点,我这里还是讲解一番。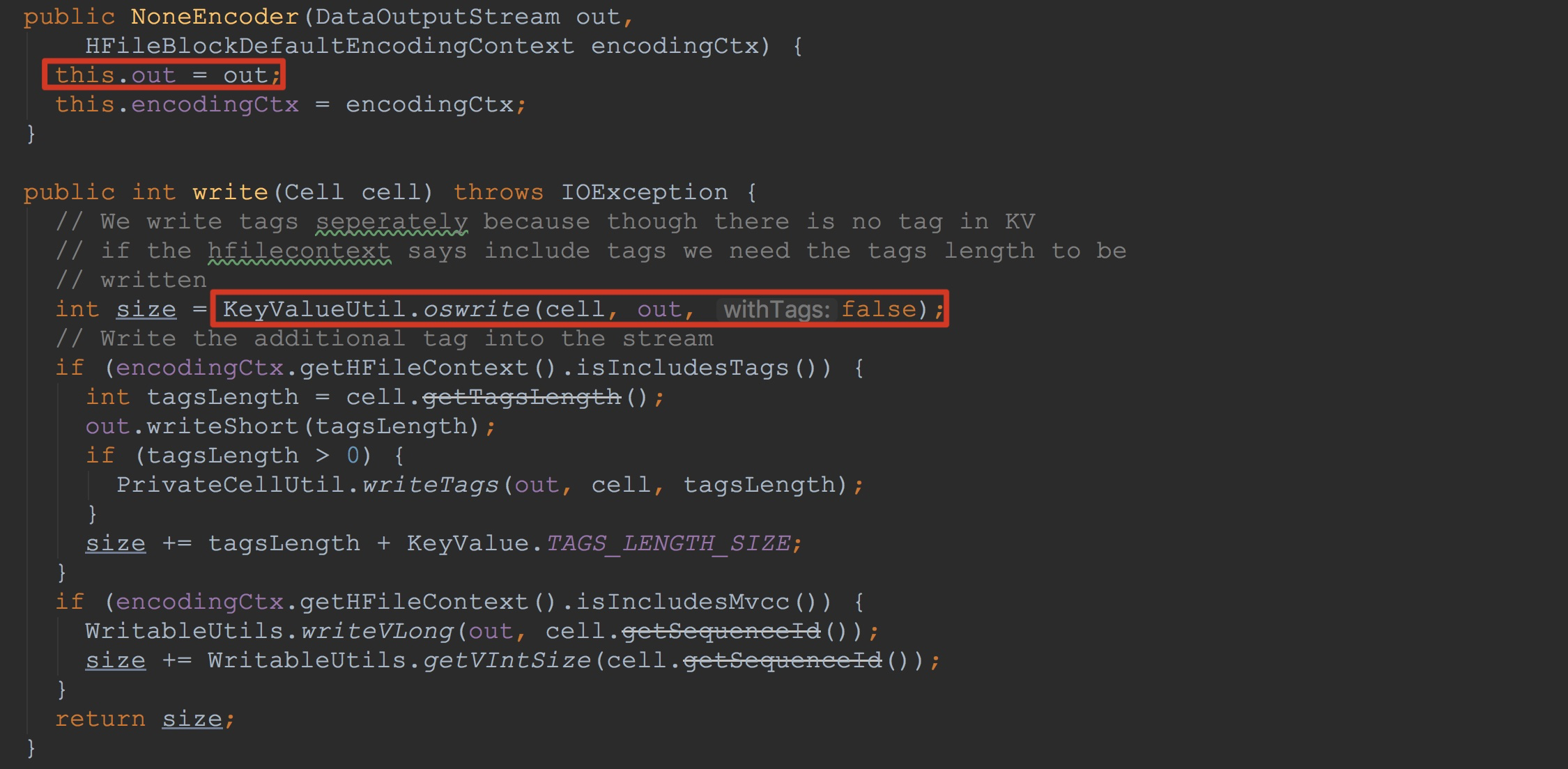
我这里只介绍入参cell类型为NoTagByteBufferChunkKeyValue。在KeyValueUtil.oswrite方法中,由于NoTagByteBufferChunkKeyValue实现了ExtendedCell接口。
因此,在KeyValueUtil.oswrite方法中,仅仅调用了((ExtendedCell)cell).write(out, withTags)方法。如下图所示,这里调用了ByteBufferUtils.copyBufferToStream(该方法会多次调用)。
接下来让我们来到ByteBufferUtils.copyBufferToStream。这里的入参out类型为ByteBufferWriterDataOutputStream,其实现了ByteBufferWriter接口。因此,这里调用了ByteBufferWriterDataOutputStream.write方法。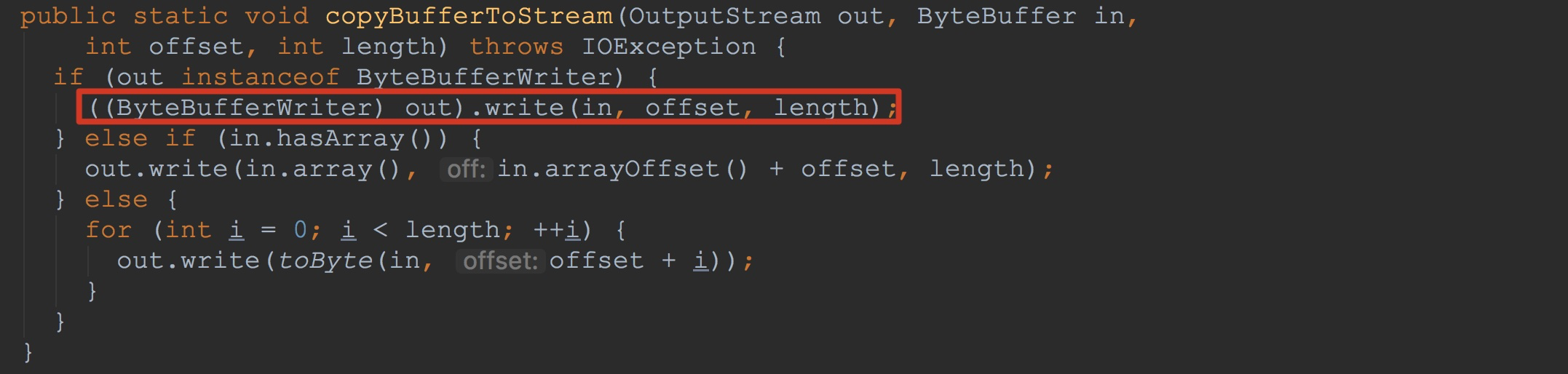
让我们来到ByteBufferWriterDataOutputStream.write。如下图所示,这里又调用了上面的方法ByteBufferUtils.copyBufferToStream,不过这里的out类型与上面的out的类型不同了,这里的out类型为ByteArrayOutputStream。也就是上面提到的userDataStream封装的baosInMemory。也就是说,这里然后调用了ByteArrayOutputStream.write。让我们进一步分析。
来到ByteArrayOutputStream.write。
1.这里检查成员变量buf是否足以容纳extra长度的字节,如果不满足,则从新分配、拷贝,如果已经满足,则不再进行任何操作。这里的详细逻辑我就不详述了。
2.调用ByteBufferUtils.copyFromBufferToArray将入参b中的内容拷贝到成员变量buf中。
到此,我们就分析完了blockWriter.write的详细流程。
也就是说,这里就将cell中的内容写到了HFileBlock.userDataStream,也就是HFileBlock.baosInMemory中。从整体流程上来讲,我们就完成了StoreFlusher.performFlush。
本节就分析到这里。下一节我将从StoreFlusher.finalizeWriter开始分析。