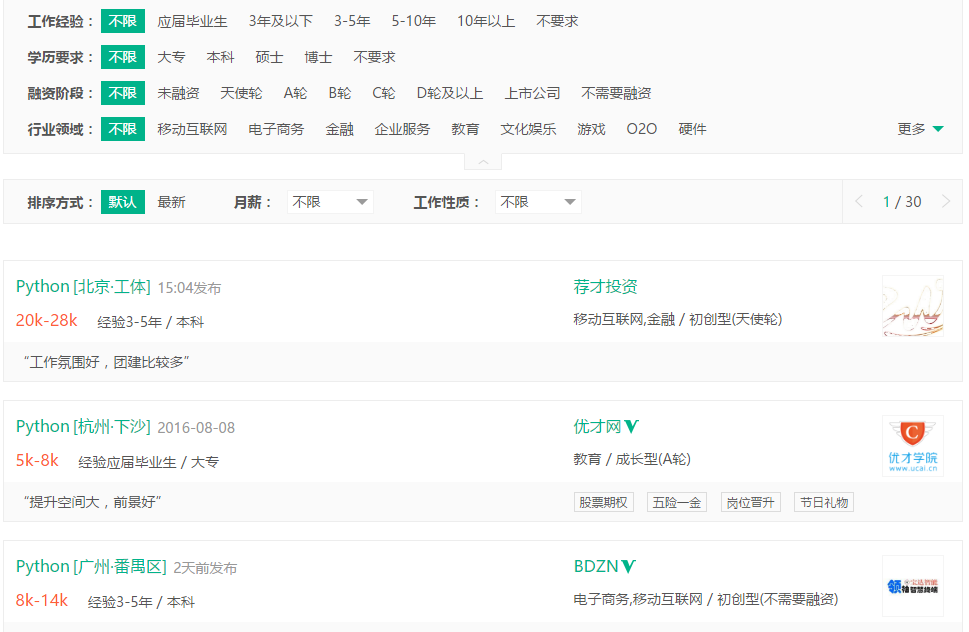
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label
页面显示如下:
在Chrome浏览器中审查元素,找到对应的链接:

然后依次针对相应的链接(比如上面显示的第一个,链接为:http://www.lagou.com/jobs/2234309.html),打开之后查看,下面是我想具体爬取的每个公司岗位相关信息:
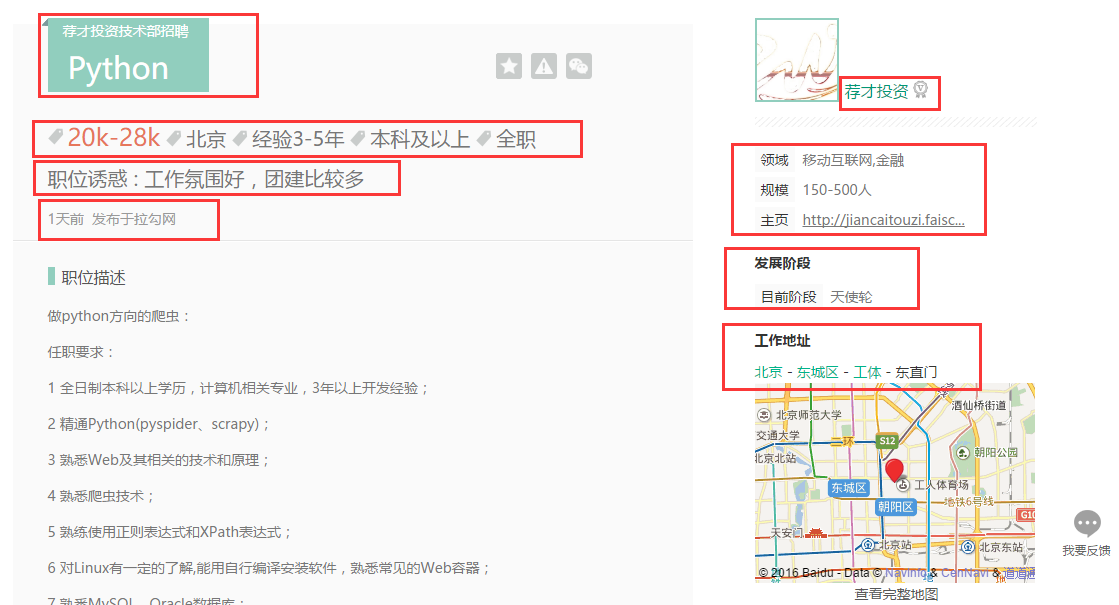
针对想要爬取的内容信息,找到html代码标签位置:
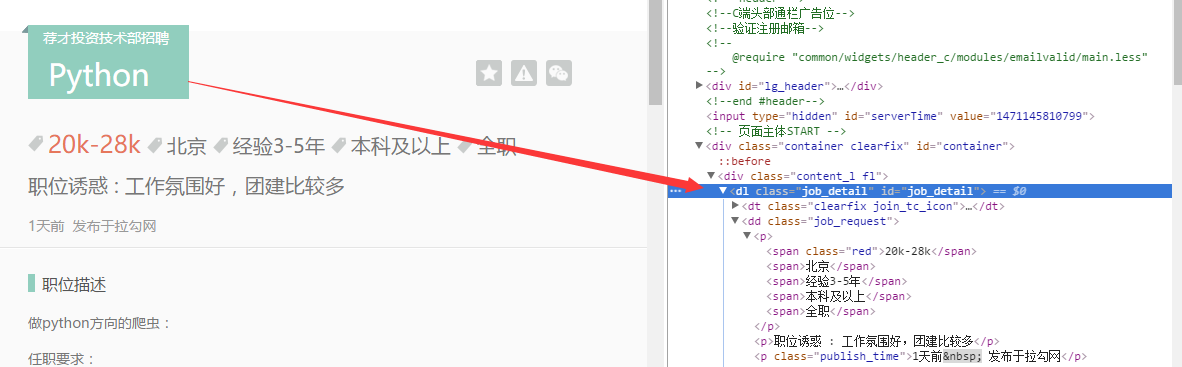
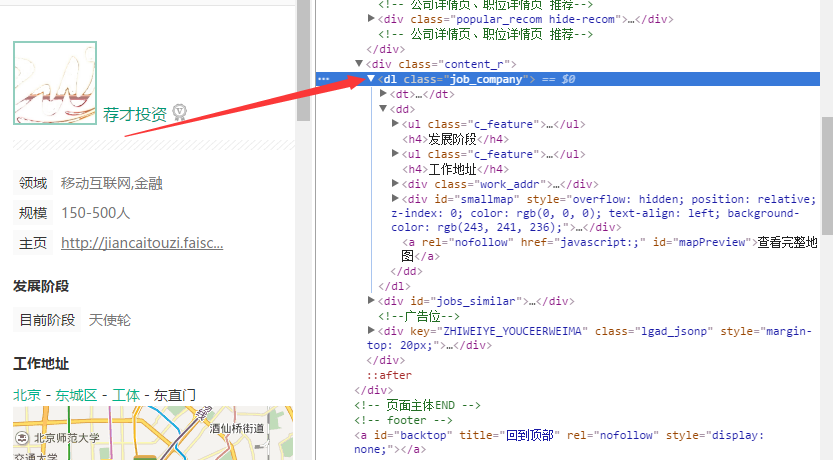
找到了相关的位置之后,就可以进行爬取的操作了。
以下是代码部分
1 # -*- coding:utf-8 -*- 2 3 import urllib 4 import urllib2 5 from bs4 import BeautifulSoup 6 import re 7 import xlwt 8 9 # initUrl = 'http://www.lagou.com/zhaopin/Python/?labelWords=label' 10 def Init(skillName): 11 totalPage = 30 12 initUrl = 'http://www.lagou.com/zhaopin/' 13 # skillName = 'Java' 14 userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36' 15 headers = {'User-Agent':userAgent} 16 17 # create excel sheet 18 workBook = xlwt.Workbook(encoding='utf-8') 19 sheetName = skillName + ' Sheet' 20 bookSheet = workBook.add_sheet(sheetName) 21 rowStart = 0 22 for page in range(totalPage): 23 page += 1 24 print '##################################################### Page ',page,'#####################################################' 25 currPage = initUrl + skillName + '/' + str(page) + '/?filterOption=3' 26 # print currUrl 27 try: 28 request = urllib2.Request(currPage,headers=headers) 29 response = urllib2.urlopen(request) 30 jobData = readPage(response) 31 # rowLength = len(jobData) 32 for i,row in enumerate(jobData): 33 for j,col in enumerate(row): 34 bookSheet.write(rowStart + i,j,col) 35 rowStart = rowStart + i +1 36 except urllib2.URLError,e: 37 if hasattr(e,"code"): 38 print e.code 39 if hasattr(e,"reason"): 40 print e.reason 41 xlsName = skillName + '.xls' 42 workBook.save(xlsName) 43 44 def readPage(response): 45 btfsp = BeautifulSoup(response.read()) 46 webLinks = btfsp.body.find_all('div',{'class':'p_top'}) 47 # webLinks = btfsp.body.find_all('a',{'class':'position_link'}) 48 # print weblinks.text 49 count = 1 50 jobData = [] 51 for link in webLinks: 52 print 'No.',count,'===========================================================================================' 53 pageUrl = link.a['href'] 54 jobList = loadPage(pageUrl) 55 # print jobList 56 jobData.append(jobList) 57 count += 1 58 return jobData 59 60 def loadPage(pageUrl): 61 currUrl = 'http:' + pageUrl 62 userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36' 63 headers = {'User-Agent':userAgent} 64 try: 65 request = urllib2.Request(currUrl,headers=headers) 66 response = urllib2.urlopen(request) 67 content = loadContent(response.read()) 68 return content 69 except urllib2.URLError,e: 70 if hasattr(e,"code"): 71 print e.code 72 if hasattr(e,"reason"): 73 print e.reason 74 75 def loadContent(pageContent): 76 # print pageContent 77 btfsp = BeautifulSoup(pageContent) 78 # job infomation 79 job_detail = btfsp.find('dl',{'id':'job_detail'}) 80 jobInfo = job_detail.h1.text 81 tempInfo = re.split(r'(?:s*)',jobInfo) # re.split is better than the Python's raw split function 82 jobTitle = tempInfo[1] 83 jobName = tempInfo[2] 84 job_request = job_detail.find('dd',{'class':'job_request'}) 85 reqList = job_request.find_all('p') 86 jobAttract = reqList[1].text 87 publishTime = reqList[2].text 88 itemLists = job_request.find_all('span') 89 salary = itemLists[0].text 90 workplace = itemLists[1].text 91 experience = itemLists[2].text 92 education = itemLists[3].text 93 worktime = itemLists[4].text 94 95 # company's infomation 96 jobCompany = btfsp.find('dl',{'class':'job_company'}) 97 # companyName = jobCompany.h2 98 companyName = re.split(r'(?:s*)',jobCompany.h2.text)[1] 99 companyInfo = jobCompany.find_all('li') 100 # workField = companyInfo[0].text.split(' ',1) 101 workField = re.split(r'(?:s*)|(?: *)',companyInfo[0].text)[2] 102 # companyScale = companyInfo[1].text 103 companyScale = re.split(r'(?:s*)|(?: *)',companyInfo[1].text)[2] 104 # homePage = companyInfo[2].text 105 homePage = re.split(r'(?:s*)|(?: *)',companyInfo[2].text)[2] 106 # currStage = companyInfo[3].text 107 currStage = re.split(r'(?:s*)|(?: *)',companyInfo[3].text)[1] 108 financeAgent = '' 109 if len(companyInfo) == 5: 110 # financeAgent = companyInfo[4].text 111 financeAgent = re.split(r'(?:s*)|(?: *)',companyInfo[4].text)[1] 112 workAddress = '' 113 if jobCompany.find('div',{'class':'work_addr'}): 114 workAddress = jobCompany.find('div',{'class':'work_addr'}) 115 workAddress = ''.join(workAddress.text.split()) # It's sooooo cool! 116 117 # workAddress = jobCompany.find('div',{'class':'work_addr'}) 118 # workAddress = ''.join(workAddress.text.split()) # It's sooooo cool! 119 120 infoList = [companyName,jobTitle,jobName,salary,workplace,experience,education,worktime,jobAttract,publishTime, 121 workField,companyScale,homePage,workAddress,currStage,financeAgent] 122 123 return infoList 124 125 def SaveToExcel(pageContent): 126 pass 127 128 if __name__ == '__main__': 129 # Init(userAgent) 130 Init('Python')
也是一边摸索一边来进行的,其中的一些代码写的不是很规范和统一。
结果显示如下:
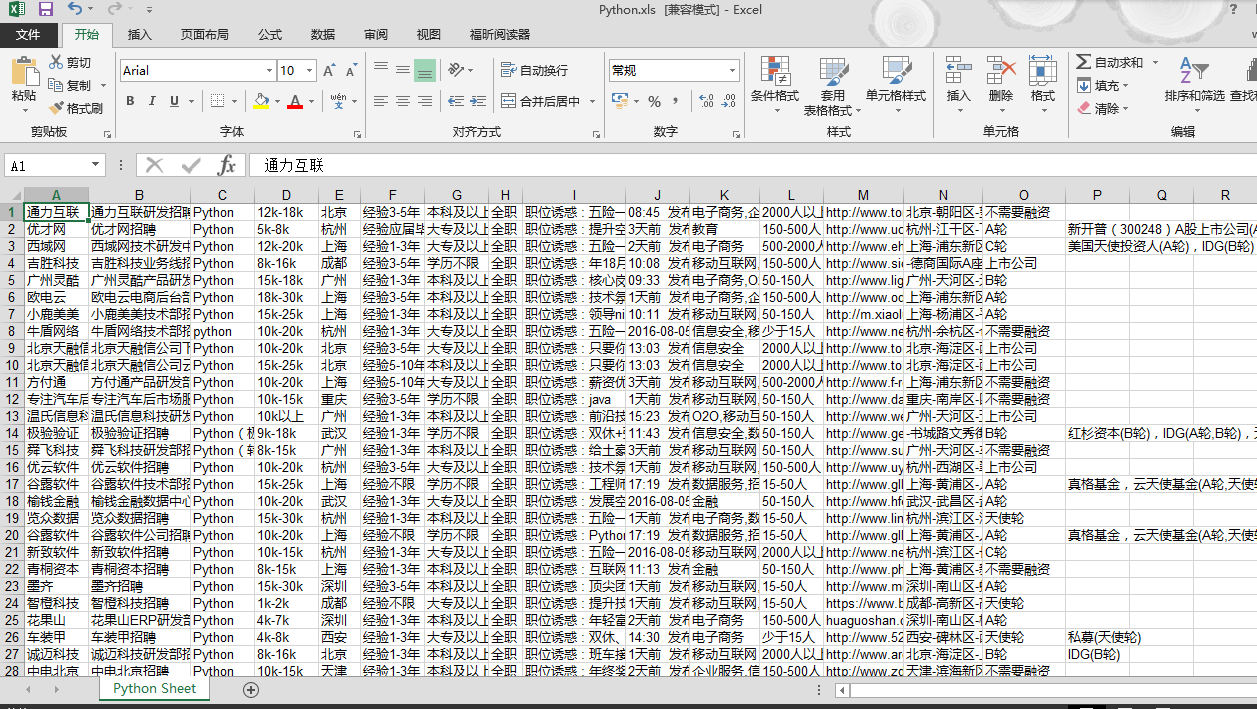
考虑打算下一步可以对相关的信息进行处理分析下,比如统计一下分布、薪资水平等之类的。
原文地址:http://www.cnblogs.com/leonwen/p/5769888.html
欢迎交流,请不要私自转载,谢谢