嵌入式系统开发环境主要包括:
- 集成开发工具
- 交叉编译器
- 批处理文件
- makefile
- Link Script
- 调试工具
- 下载工具
- 其它工具(Offline Tools)
- 模拟器
- 版本控制工具
接下来分别讲解以上各个工具:
1、集成开发工具
一般CPU厂商会提供针对该CPU的集成开发环境(IDE),但在实际应用中,大多数嵌入式项目开发公司都还是会使用自己开发的环境。一是项目某些功能的特殊性要求,二是并不是所有CPU型号都有相应的IDE。
2、 Cross-Tools
Cross-Tools包含:
- Cross-Assembler
- Cross-Compiler
- Cross-Library
- Cross-Linker
- dump工具(将可执行文件转换为汇编语言代码的相关信息)
- 调试工具(GNU gdb)
以GNU Tool-Chain中的C编译器gcc为例,以下是一些编译时的选项:
- -Werror:将所有警告信息变为错误信息,一旦有警告信息产生,就不产生目标文件。
- -S : 编译时输出汇编语言代码。
- -C : 编译时仅产生目标文件
- -E : 只执行预处理,不产生目标文件
- -D : 编译时定义宏常数
- -O、-O2、-O3: 优化等级。
- -g : 编译时加入调式信息,使之可以使用GDB进行调试
以GNU Tool-Chain中的C链接器Linker为例,以下是一些选项:
- -T : 制定链接脚本文件
- -Map :连接时产生map文件,其中包含了程序中所有symbol的地址信息。
GNU tool chain可以支持许多不同的CPU,使用者可以根据需求设定配置。例如arm-elf-gcc就是会以elf格式产生ARM机器码的C编译器,而68K-coff-ld就是会以COFF格式产生68000机器码的linker。
3、Make
make是用来进行自动编译的程序工具,只要在makefile中详细叙述要用什么工具(例如cross-compiler)对哪个文件(.c、.obj、…)做何种处理(产生不优化的目标文件),make同时还会检查这些文件是否过期,如果过期会仅仅自动重新编译需要编译的(make会比较文件之间的依存关系与日期,以决定某个文件是否需要重新编译),而通常的批处理程序(例如windows下的.bat程序),在有某些文件更新后,需要重新编译所有文件。
《programming with GNU Software/GNU程序设计》
《Managing Project with make/make 项目开发工具》
以上两本书有对make使用的详细说明。
(1) makefile里的重要概念
- Target(目标):就是想要产生的文件名称。
- Dependency(依赖):定义两个文件是否存在依存关系。
- Prerequisite(必备文件):一些能建立target的文件,一个target通常由多个文件建立。
- UP to Date(新版):假设某个文件比它所依赖的文件还要新,则表示这个文件有了新版本。
makefile的基本语法:
#文件名:sample.mak
Target:Dependency list
command1
command2
要执行上述makefile的命令是:make -f sample.mak,如果没有使用-f指定makefile文件的话,make会在当前目录下寻找名为“makefile”的文件。此外如果没有指定targe的话,make会以makefile中第一个target文件名当作目标名。
(2)makefile举例
- 下例为makefile中的宏定义示例:
#File Name : DEFINE.MAK
#
#定义其它makefile中会用到的宏,思想和C语言的#define一样
#
!IFNDEF _DEFINE_MAK
_DEFINE_MAK = DEFINED
#
#定义项目相关文件所在的磁盘机编号
#
PRJ_DRIVER = Y:
#
#定义项目工具所在目录
#
PRJ_TOOLS_ROOT = $(PRJ_DRIVER)Tools
#
#定义编译器所在目录
#
GNU_CC = $(GNU33_ROOT)kcc33
GNU_LK = $(GNU33_ROOT)ld
GNU_AR = $(GNU33_ROOT)ar
#
#定义项目程序所在目录
#
SRC_ROOT = $(PRJ_DRIVER)Project2020
SRC_INC = $(SRC_ROOT)include
#
#当编译时传入-DXXX参数,其效果如同在程序中写了#define XXX
#
PRJ_CONFIG = -DPRJ_2020 -DCPU_ARM9 -DLCD_160X160
#
#定义执行C compiler时的参数
#
?CFLAGS= -c -gstabs -mlong-calls -fno-builtin -mgda=0 -mdp=1 -O3
-I$(GNU_INCLUDE)
-I$(SRC_INC)
-I$(PRJ_CONFIG)
#
#定义执行linker时的参数
#
LDFLAGS= -T main.lds -Map $(TARGET).map -N
#...
#...
!ENDIF
- 下例为一个较复杂的范例:
#
#在makefile中,也可以和include一样,包含其它makefile
#
!IF "$(_DEFINE_MAK)" == ""
!INCLUDE DEFINE.MAK
!ENDIF
#
#定义各模块包含的object file,每个object都是一个target
#
MODEL1_OBJS = m1_001.obj m1_002.obj m1_003.obj
MODEL2_OBJS = m2_001.obj m2_002.obj
#
# 项目中所有需要的object file
#
OBJS = $(MODEL1_OBJS) $(MODEL2_OBJS)
#
#定义会用到的库函数
#
LIBS = $(GNU_LIB)libgcc.a
#
#第一个target产生最终可执行文件main.elf,
#和main.elf有依赖关系的target有:所有的object file,main.mak,Link Script
#"$@"表示target本身,即main.elf
#
main.elf : $(OBJS) main.mak main.lds
$(GNU_LK) $(LDFLAGS) -o $@ $(OBJS) $(LIBS)
#
# $* 表示target名称去掉扩展名
# $@ 表示target本身
# $< 表示XXX.c
#
m1_001.obj : $(SRC_ROOT)m1m1_001.c $(SRC_INC)m1.h
$(GNU_CC) $@ $(CFLAGS) $*.c
m1_002.obj : $(SRC_ROOT)m1m2_001.c $(SRC_INC)m1.h
$(GNU_CC) $@ $(CFLAGS) $*.c
...
- 当需要重复处理几个扩展名一样的文件时,通常可以使用make的预设编译规则。例如当需要以同样的规则编译所有以.obj为扩展名的target时可以采用如下语句:
?.c.obj:;$(GNU_CC) $@ $(CFLAGS) $<
预设编译规则语法说明:
.c.obj:; 此行目录用来规范target为.obj文件,依赖为.c文件的预设编译规则
在设定预编译规则时依然可以使用宏
(3)非文件名称的Target
clean:
del $(OBJS)
del main.elf
del main.bin
上述makefile语句中仅有target,没有dependency,意味着该target是一定会去执行下文的del命令。一般用于重新编译所有文件前执行。
这种非文件名target也可作为其它target的dependency,用于当要make某个target时,先去执行一系列指令的效果:
build_all : clean
...
...
(4)版本控制
在系统正式发布之前,程序代码中肯定会包含许多用于调试的代码行。但实际中,由于嵌入式系统的存储资源有限,不可能将含有调试代码的程序作为最终代码烧进板子。所以在设计时,一般会设计两个版本(调试版和发行版)。当然,当程序开发完,我们不可能用手动的方式一个个去删除这些调试代码。此时可以采用C语言中条件编译的思想,见下文分析:
调试版批处理文件:make_debug.bat
REM ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
REM Make_debug.bat
REM~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
REM 设定Windows/DOS的系统环境变量
REM
set BUILD_MODE = Debug
REM make我们的程序
REM
make target
发行版批处理文件:make_release.bat
REM ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
REM Make_release.bat
REM~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
set BUILD_MODE = Release
make target
makefile:
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#makefile
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#
!IF "$(BUILD_MODE)" == "Debug"
# 如果BUILD_MODE等于“Debug”,则设定编译时期的参数CFLAGS_DEBUG = __DEBUG_VERSION
# 反之,则设定编译时期的参数为空
#
CFLAGS_DEBUG = -D__DEBUG_VERSION
!ENDIF
target:
gcc $(CFLAGS_DEBUG) xxx.c
#-D参数用来在编译时期设定宏变量“__DEBUG_VERSION”
4、Link Script
制作可执行文件的流程中,要先把所有的程序文件编译成目标文件,接下来就是通过链接器linker将所有的目标文件与库文件链接为可执行文件。而具体如何链接,连接到哪个地址就是通过扩展名为.ld的连接脚本文件来指定了。
有操作系统的情况下,不同的程序有自己的地址空间,而且相互之间互不干涉。这种程序都在RAM(内存)中执行,所有程序只要从同一个起始地址连接在一起就好。但嵌入式程序很多时候是没有操作系统的,系统和程序通常在在同一个地址空间,且往往连硬盘都没有,程序只能在ROM或flash中执行。但数据则只能被寻址在RAM中,所以连接时要告诉linker,程序段要被寻址到哪里(ROM的起始地址),数据段要被寻址到哪里(RAM的起始地址)。
(1)程序区段的结构
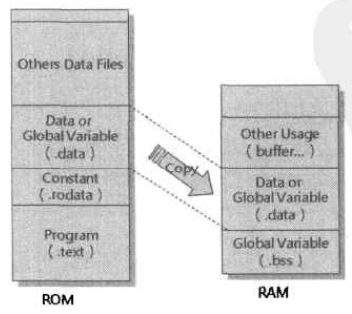
- text段:即代码段,执行期间text段的内容不会改变,其可以直接在ROM里执行,无须载入到内存。
- Read-only-data(rodata)段:定义为const的变量,以及字符串都会归类到rodata段。,其也是直接在ROM里执行。
- Data段 :有初值的全局变量放在这个段。在连接时期,这些初值必须加入到可执行文件中,但要被寻址到RAM的地址;在执行时期,这些变量被存储在ROM中,但必须被载入到RAM中才能使用,因为他们的值是可变的。所以,data段会被加入ROM,但却要寻址到RAM中。
- bss段:没有初值的全局变量会被归类到bss段。因为无初值,所以不必加入到程序中,只要在连接时将其寻址到RAM即可。执行时期也没有载入的问题,但机器RESET后,由系统主动将整个bss段清零。
(2)link script 的内容
执行时期存储器的使用状况:
- LMA(Load Memory Address)与VMA(Virtual Memory Address)
数据会被放置在ROM,但执行时必须载入到RAM,则在ROM中(最终存储的地址)的地址称为LMA,而在RAM中(执行时期)的地址就是VMA。
试着写一下具有如下连接要求的link script:
- 系统中有一块ROM,它的起始地址是0xC00000,另有一块RAM,起始地址为0.
- 可执行文件包含text、rodata、data段,其中text段和rodata段在ROM里执行即可,所以被寻址到0xC00000,而rodata跟在text后面。
- bss段因为没有初值,所以不会占据可执行空间或ROM空间,它会被寻址到RAM的起始地址0.
- data段比较复杂,它的内容也必须包含在可执行文件内,在执行时期它必须被载入到RAM里。所以data的VMA在RAM中,跟在bss段之后,而LVA则跟在rodata段后面。
扩展:当希望某段程序以更快的速度执行,则只需要将其LMA在ROM里,VMA则寻址到RAM中,在执行前将其从ROM中载入到RAM里。
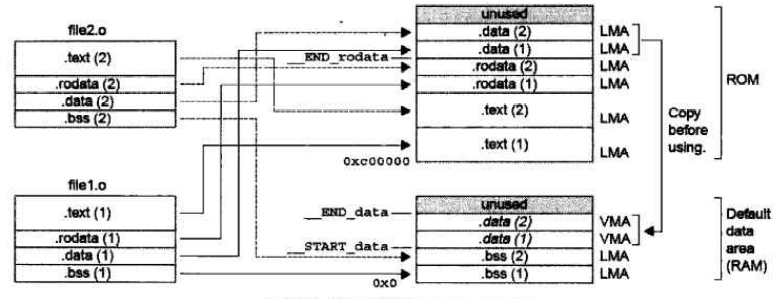
/*********************************************************
Link Script sample
存储器地址配置:ROM起始地址(0xC00000),RAM起始地址(0)
输出ARM9机器码,可执行文件格式为elf32
**********************************************************/
OUTPUT_FORMAT("elf32-arm9")
OUTPUT_ARCH(arm9)
SEARCH_DIR(.);
SECTIONS
{
/*****************************************
定义text段,起始地址(VMA)从0xC00000开始,
若没有指定LMA,表示LMA起始地址同VMA。
*****************************************/
.text 0xC00000:
{
/* 定义变量__START_text,句号.表示当前的VMA,即0xC00000 */
__START_text = . ;
/* *(.text)表示将当前目录中所有的.text段加入到这个段*/
*(.text);
/* 定义变量__END_text,目前VMA应该是0xC00000加上所有.text段的size总和 */
__END_text = . ;
}
/*****************************************
定义rodata段,起始地址(VMA)从__END_text开始(跟在text段之后),
若没有指定LMA,表示LMA起始地址同VMA。
*****************************************/
.rodata __END_text :
{
__START_rodata = . ;
*(.rodata);
__END_rodata = . ;
}
/*****************************************
定义bss段,起始地址(VMA)从0开始,
若没有指定LMA,表示LMA起始地址同VMA。
*****************************************/
.bss 0x00000000:
{
__START_bss = .;
*(.bss);
__END_bss = .;
}
/* 定义可在程序中使用的变量__SIZE_BSS,表示bss段的大小。*/
__SIZE_BSS = __END_bss - __START_bss;
/*****************************************
定义data段,其LMA应该在ROM,而VMA在RAM。
所以,VMA跟在bss段后面,LMA跟在rodata段之后
*****************************************/
.data __END_bss : AT(__END_rodata)
{
__START_data = .;
*(.data);
__END_data = .;
}
/*定义变量__START_data_LMA,表示data段的起始地址*/
__START_DATA_LMA = LOADADDR(.data);
/* 定义可在程序中使用的变量__SIZE_DATA,表示data段的大小。*/
__SIZE_DATA = __END_data - __START_data;
/***********************************************
speed_up模块的VMA和LMA都是跟在data段之后,
它会被加到可执行文件中,但执行时要载入到RAM才能执行
**************************************************/
.text_speed_up __END_data : AT(__START_data_LMA + SIZEOF(.data))
{
__START_text_speed_up = .;
speed_up_main.o(.text);
speed_up_main.o(.rodata);
speed_up_main.o(.data);
__END_text_speed_up = .;
/* 为便于说明,假设该模块没有bss段*/
}
__START_text_speed_up_LMA = LOADADDR(.text_speed_up);
__SIZE_TEXT_SPEED_UP = __END_text_speed_up - __START_text_speed_up;
}
将某个程序模块(speed_up)传输到速度较快的存储器上执行的代码如下:
extern unsigned char * __START_text_speed_up;
extern unsigned char * __START_text_speed_up_LMA;
extern int __SIZE_TEXT_SPEED_UP;
void copy_data_section(void)
{
//一个字节一个字节的传输(性能较差)
int i;
unsigned char *dest = __START_text_speed_up;
unsigned char *src = __START_text_speed_up_LMA;
for(i=0; i<__SIZE_TEXT_SPEED_UP; i++)
dest[i] = src[i]
}
为bss段赋予0的代码为:
extern unsigned char * __START_bss;
extern int __SIZE_BSS;
void clear_bss_section(void)
{
int i;
unsigned char * dest = __START_bss;
for(i=0; i<__SIZE_BSS;i++)
dest[i] = 0;
}
(3)Map File或符号表(Symbol Table)
连接后除了产生可执行文件外,通常还要求产生map文件(GNU linker ‘ld’ 的-m参数),其用于记录项目中每一个Symbol(程序中所有函数、库函数、全局变量及链接器自动产生的各个区段起始和结束地址的变量)的LMA与VMA的对应关系。通过该map文件可以得到如下信息:
- 程序各区段的寻址是否正确;
- 程序各区段的大小;即ROM和RAM的使用量;
- 程序中各符号的地址;
- 各个符号在存储器中的顺序关系
- 各个程序文件的存储用量
当连接完毕,下载可执行文件到实际存储器中前,一般需要查看map文件,以确定各区段的起始地址和大小符合自己的设想。下图是一个map文件的部分截图:

5、ROM Maker
可执行文件的格式多样(ELF、COFF、HEX、S-Record、EXE等),但最终要烧到板子ROM里的是二进制文件,所以当得到可执行文件后,还需要通过ROM Maker将其转化为纯二进制文件才能执行烧录。当然,因为嵌入式系统通常没有硬盘,所以除了可执行二进制文件之外的文件也必须同时和他们一起转换成一个总的单一的二进制文件(Image File),这个过程称为make ROM。具体流程见下图:
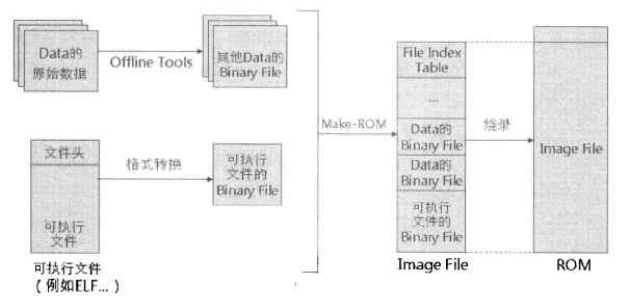
这里说的除了二进制可执行文件之外的一起加入到Image File的文件常见的有图片(JPG文件等),常见的作法是通过将该图片文件按字节转化为常量C数组,并给予一个名称,在程序中就可以通过直接操作存储器来使用这些数据,从而避免使用文件系统,但扩展性不强,更新麻烦。所以当这些图片文件有很多时,还是建议使用文件系统来管理较为方便。
实际上,我们一般会开发一个工具,把某目录下的所有文件一一转化为C array的程序,同时会产生一个.h头文件,其中包含所有代表数据挖掘的C array声明与每一个数组的大小,使用时只要include这个.h文件就可以使用这些array。
- 文件系统映像
实际上文件系统就是一种访问数据的接口而已,它是一套实现了数据的存储、分级组织、访问和获取等操作的抽象数据类型。文件系统存储在哪、用什么样的格式都有可能,如果系统对文件没有写入需求,文件系统照样可以存储在ROM中。
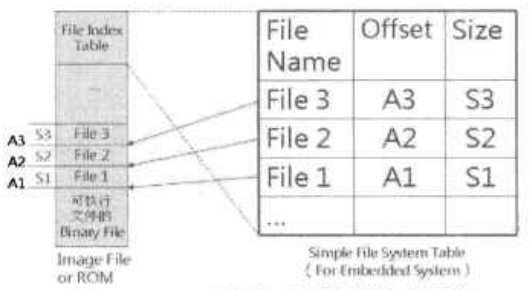
在嵌入式系统中,如果没有写入数据的需求,我一般会采用一个索引表格,记录文件名及其在存储器中的文件首地址和文件大小。为了查找方便,该索引表格一般位于最高地址处。
6、Offline Tools
用于开发阶段且必须自己开发并执行于PC上的工具叫做offline tools。这些工具可分为6大类:
-
程序产生器(Program General)
- 系统配置设定工具:一个运行于PC上,用于选择系统配置(某些功能开关、LCD分辨率等),并自动产生.h文件或make-file。
- Resource Manager:要加到系统中的字符串、图形或数据文件为resource。例如用于UI界面的小图形文件必须转为C array并加到程序中,其它程序则通过resource ID对应到该array。该工具可以使我们仅通过编辑资源文件名,即可自动转出包含所有resource ID定义的.h文件,以及包含这些resource内容的C array的.c文件。
-
Data Maker:一般嵌入式系统无法使用诸如mySQL这种数据库,必须根据应用的特性自行设计。
- File System:严格来说文件系统也是数据库,只是它的单元是文件而非记录。
- Database:所谓的database基本上会包含数据文件与多个层级的索引表(index table)。在CPU算力有限二点前提下,数据库格式与压缩算法的设计尤为重要。
- 产品内置的文件:例如一些MP3内置音乐或电子书内置书籍等不可被用户删除的文件必须与用户可编辑的文件区分开,而这就涉及多个文件存储区域或多个文件系统。
- 产品信息或预设出厂设定:对于一些经常变动的信息(厂商、日期等),我们会倾向于不要写死在程序里,而是将这些信息存储在file或Database中,让系统在运行时取得其中的信息即可。
-
Image Maker:它的功能就是制作要最后烧入存储器中的image。该映像中不仅包含程序,可能还包含产品信息、FIle System image、Database等。
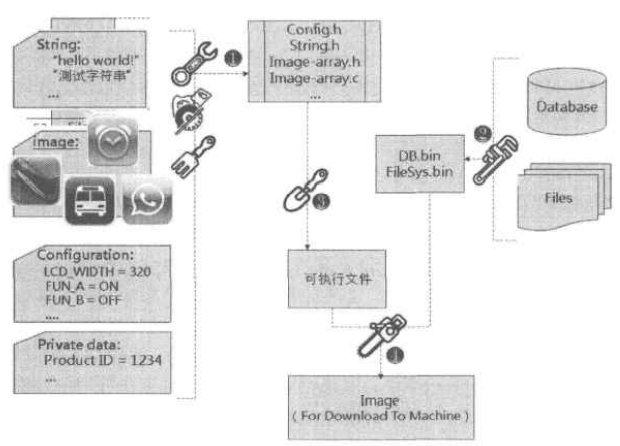
- 下载工具:除了用烧录器写image进存储器外,还需要提供局部下载的下载工具,因为有时候仅仅是更新部分程序或文件系统里的某些文件。
- 量产工具:厂商有些信息(厂商名、批号、日期等)只有在烧录前才可决定,此时需要提供一个工具给厂商,将这些信息写入image特定位置后才进行存储器烧录。
- 模拟器
- 其它工具
7、下载与执行
严格来说,所谓的ROM是无法烧录的。在量产前,要委托专业的Mask-ROM制造商根据我们提供的image File进行一次性烧录。在开发阶段,我们要选用其它可重复读写的替代品,通常如NOR-flash、EPROM或EEPROM等。而要将数据写入一般有以下几个做法:
- 先利用ICE下载到RAM执行并测试。
- 烧录器:要先把存储器的Chip放在烧录器的socket上,然后利用PC操作厂商提供的烧录程序,选择image file并执行烧录即可。(开发阶段板子的存储器先设计成通过socket与板子连接,我们只要把烧好的IC放在socket上夹好即可)
- ROM-Emulator:该工具就是模拟EPROM/EEPROM,它的一端接到板子的socket上,另一端接到PC上。通过厂商提供的程序,可以将image file下载到ROM模拟器的存储器内,机器连接着模拟器就如同接着一颗真正的ROM一样。
- Update程序:在实际板子可以通过某种方式(USB、RS232、网线)与PC连接并传输数据的话,我们可以开发一个update程序模块用于接收PC端的image file内容并将其写入NOR flash中,如此一来就完成了更新机器上程序版本的功能。
8、版本控制
无论是嵌入式系统或一般软件项目,只要涉及多人协作开发,就一定要做版本控制。当软件开发达到某个里程碑或有重大突破时,管理者可以为当前版本取一个名字,我们称之为Lable或tag,以后任何人都可以从版本控制服务器下载某lable时间点的所有程序。
的烧录程序,选择image file并执行烧录即可。(开发阶段板子的存储器先设计成通过socket与板子连接,我们只要把烧好的IC放在socket上夹好即可)
- ROM-Emulator:该工具就是模拟EPROM/EEPROM,它的一端接到板子的socket上,另一端接到PC上。通过厂商提供的程序,可以将image file下载到ROM模拟器的存储器内,机器连接着模拟器就如同接着一颗真正的ROM一样。
- Update程序:在实际板子可以通过某种方式(USB、RS232、网线)与PC连接并传输数据的话,我们可以开发一个update程序模块用于接收PC端的image file内容并将其写入NOR flash中,如此一来就完成了更新机器上程序版本的功能。
8、版本控制
无论是嵌入式系统或一般软件项目,只要涉及多人协作开发,就一定要做版本控制。当软件开发达到某个里程碑或有重大突破时,管理者可以为当前版本取一个名字,我们称之为Lable或tag,以后任何人都可以从版本控制服务器下载某lable时间点的所有程序。
当系统需要开发一个新功能时,可以建立一个分支(branch),并在该分支上进行开发。成功后在与主分支(master)进行合并。