Redis数据结构系列:
Redis 没有直接使用 C 语言传统的字符串表示(以空字符结尾的字符数组,以下简称 C 字符串), 而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型, 并将 SDS 用作 Redis 的默认字符串表示;
在 Redis 里面, C 字符串只会作为字符串字面量(string literal), 用在一些无须对字符串值进行修改的地方, 比如打印日志;
当 Redis 需要的不仅仅是一个字符串字面量, 而是一个可以被修改的字符串值时, Redis 就会使用 SDS 来表示字符串值: 比如在 Redis 的数据库里面, 包含字符串值的键值对在底层都是由 SDS 实现的。
在sds.h/sdshdr下定义了SDS的结构
struct sdshdr { // 记录 buf 数组中已使用字节的数量 // 等于 SDS 所保存字符串的长度 int len; // 记录 buf 数组中未使用字节的数量 int free; // 字节数组,用于保存字符串 char buf[]; };
属性说明
free属性的值为0, 表示这个 SDS 没有分配任何未使用空间。len属性的值为5, 表示这个 SDS 保存了一个五字节长的字符串。buf属性是一个char类型的数组, 数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符, 而最后一个字节则保存了空字符'\0';

C语言字符串有以下几个问题:
- 计算字符串的长度时间复杂度为O(n);
- 每一次删除和增加字符串的长度,都需要重新分配空间;
- 缓存区异常;
- 类似ASCII码,字符串中不能出现空白符。否则认为是字符串的结尾;
redids改进:
- redis的结构中存储了字符串的长度,所以获取字符串的长度的时间复杂的为O(1)
- 由于redis分配的空间不是按照需要的分配,一般会有多余的空间(空间预分配)。所以字符串长度增加时,剩余的空间足够,就可以避免重新分配空间。减少字符的长度时也不是直接删除多余的内容。而是设置已使用空间的长度,隐藏删除内容(惰性释放)。
- redis会先检查总的空间大小,满足才会分配,避免缓存区溢出;
- 采用二进制存储,不存在空白符的干扰
实际在数据存储过程中,字符串对象根据保存值的类型、长度不同,可以分为三种存储结构:
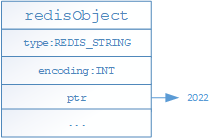
- Int:如果存储的是整数值(可以用long表示),则底层通过如下结构进行存储,其中type代表当前对象为STRING对象,encoding表示当前对象的编码格式,ptr的属性保存是真实的值;
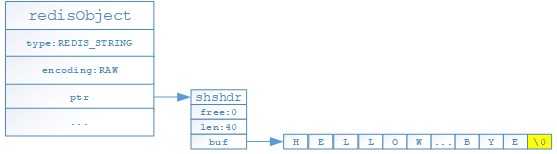
- raw:如果存储的是字符串且字符串长度超过39字节,则底层通过如下结构进行存储,其中type代表当前对象为STRING对象,encoding表示当前对象的编码格式,ptr为指针指向一个SDS(shshdr:简单动态字符串对象)来保存具体的值;

- embstr:如果存储的是字符串且字符串长度未超过39字节,则底层通过embstr结构进行存储(需要一块连续的内存空间)
embstr和Raw对比:
- embstr和raw都使用redisObject结构和sdshdr结构来表示字符串对象,但是raw会分别两次创建redisObject结构与sdshdr结构,内存不一定是连续的,而embstr直接创建一块连续的内存;
- embstr需要一块连续的内存空间,因此其效率上比raw方式要高
- emstr在内存分配以及内存释放时只需要一次接口,而raw方式需要两次(因为存在redisObject和shshdr两个对象)
- embstr为只读对象,任何对embstr编码对象的修改都会导致对象的编码格式变为raw
- int/embstr编码格式的字符串对象在满足一定条件后会自动转为raw编码格式
部分源码:
在redis源码中3.0、3.2以及4.0中,代码创建的逻辑是与REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39进行比较,如果小于39的话创建的是embstr,否则位raw。
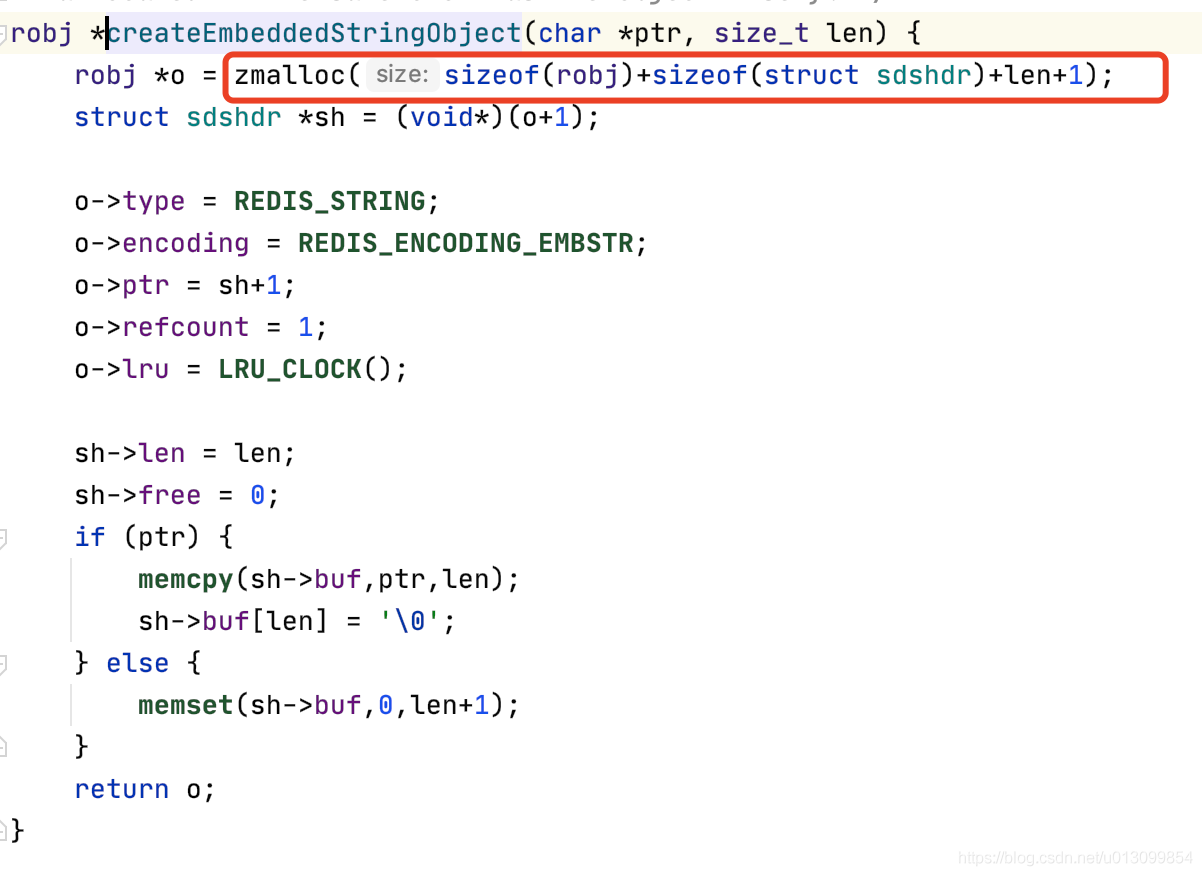
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39 robj *createStringObject(char *ptr, size_t len) { if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) return createEmbeddedStringObject(ptr,len); else return createRawStringObject(ptr,len); } //创建embstr robj *createEmbeddedStringObject(char *ptr, size_t len) { robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1); struct sdshdr *sh = (void*)(o+1); o->type = REDIS_STRING; o->encoding = REDIS_ENCODING_EMBSTR; o->ptr = sh+1; o->refcount = 1; o->lru = LRU_CLOCK(); sh->len = len; sh->free = 0; if (ptr) { memcpy(sh->buf,ptr,len); sh->buf[len] = '\0'; } else { memset(sh->buf,0,len+1); } return o; } //创建raw robj *createObject(int type, void *ptr) { robj *o = zmalloc(sizeof(*o)); o->type = type; o->encoding = REDIS_ENCODING_RAW; o->ptr = ptr; o->refcount = 1; /* Set the LRU to the current lruclock (minutes resolution). */ o->lru = LRU_CLOCK(); return o; }
redis使用jemalloc内存分配器。这个比glibc的malloc要好不少,还省内存。在这里可以简单理解,jemalloc会分配8,16,32,64等字节的内存。所以embstr最小分配64字节。其中16个字节值得是redisObject所占的字节数
typedef struct redisObject { unsigned type:4;//对象类型(4位=0.5字节) unsigned encoding:4;//编码(4位=0.5字节) unsigned lru:LRU_BITS;//记录对象最后一次被应用程序访问的时间(24位=3字节) int refcount;//引用计数。等于0时表示可以被垃圾回收(32位=4字节) void *ptr;//指向底层实际的数据存储结构,如:SDS等(8字节) } robj;
其中sdshr中len与free这两个变量所占用8个字节,/0占用一个字节,buff最多占用,64-8-16-1=39剩下的39个字节,这个默认39就是这样来的,在5.0及后续版本中临界值改为了44;。
参考链接: