InnoDB是现在使用的最多的储存引擎了吧。来看看它的特点:
ACID事务
行锁
MVCC
外键
一致性非锁定读
不支持全文索引
InnoDB的体系架构
主要是由内存块组成的内存池。
内存池的主要工作
1.维护内部数据结构
2.缓存重做日志
3.缓存磁盘上的数据,数据进入内存之前就存储在这里
后台线程负责刷新内存池,保证内存池中的缓存数据是最新的。
还有,将已经修改的数据存储到磁盘中。
后台线程
默认情况下,InnoDB有7个线程:4个IO线程、1个master 线程、1个错误监控线程、一个锁监控线程。
4个IO线程分别是:
insert buffer thread
log thread
read thread
write thread
在Linux系统中,IO线程的数量是不能调整的,但是在插件版的InnoDB中,read和write线程增加到了4个,
并且配置文件中没有innodb_file_io_threads这个参数。
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
参数换成了innodb_read_io_threads和innodb_write_io_threads
mysql> show variables like 'innodb_version'G;
*************************** 1. row ***************************
Variable_name: innodb_version
Value: 5.6.36
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> show variables like 'innodb_%io_threads'G;
*************************** 1. row ***************************
Variable_name: innodb_read_io_threads
Value: 4
*************************** 2. row ***************************
Variable_name: innodb_write_io_threads
Value: 4
2 rows in set (0.00 sec)
内存
InnoDB引擎的内存由以下几部分组成:
缓冲池
mysql> show variables like 'innodb_buffer_pool_size'G;
*************************** 1. row ***************************
Variable_name: innodb_buffer_pool_size
Value: 134217728
1 row in set (0.00 sec)
重做日志缓冲池
mysql> show variables like 'innodb_log_buffer_size'G;
*************************** 1. row ***************************
Variable_name: innodb_log_buffer_size
Value: 8388608
1 row in set (0.00 sec)
额外的内存池
mysql> show variables like 'innodb_additional_mem_pool_size'G;
*************************** 1. row ***************************
Variable_name: innodb_additional_mem_pool_size
Value: 8388608
1 row in set (0.00 sec)
缓冲池占用的内存最大,用来缓存数据。
存储引擎工作方式:
将数据库文件按页(16K)读取到缓冲池中,然后按照最少使用(LRU)算法来保留缓冲池中的数据。
如果数据需要修改,优先修改缓冲池中的数据,修改后的页叫做脏页。
最后后台线程将脏页刷新到文件中。
mysql> show engine innodb statusG;
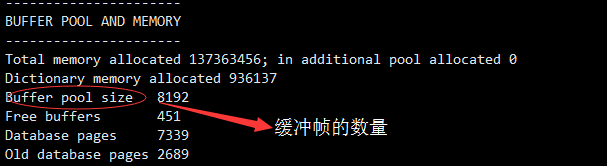
每个帧为16K,所以缓冲池大小为8192*16/1024=128M。
Free buffers 当前空闲的缓冲帧数量。
Database pages 已经使用的缓冲帧
Modified db pages 脏页的数量
从上面的数据可以看出,缓冲池还剩下5.5%左右可以使用。数据库压力比较大。
Per second averages calculated from the last 30 seconds
该命令显示的是过去30秒的状态,并非最新的状态。
数据页的类型
索引页
数据页
undo页
插入缓冲(insert buffer)
自适应哈希索引(adaptive hash index)
InnoDB存储的锁信息(lock info)
数据字典信息(data dictionary)
等
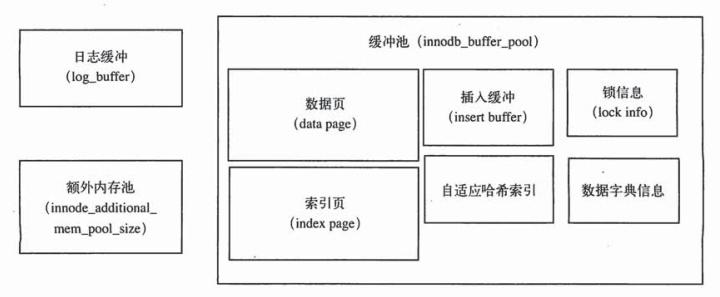
日志缓冲将日志文件先放入缓冲区,然后刷新到重做日志。一般每秒就会将重做日志缓冲刷新到日志文件,日志缓冲的值不需要设置很大,大于每秒的事务量即可。
InnoDB引擎管理内存的方式叫做内存堆(heap)
在对某些数据结构本身进行内存分配时,首先从额外内存池分配,不够用就从缓冲池分配。
InnoDB实例的缓冲池中,缓冲帧对应的缓冲控制对象所需的内存也是从额外内存池分配的,
所以当缓冲池很大时,额外内存池的大小也要增加。
master thread
InnoDB引擎的主要工作都是在master thread由完成的。
master thread线程的优先级最高,通过分析其源代码可以知道,其内部由几个循环构成:
主循环(loop)
后台循环
暂停循环
刷新循环
master thread基本就是在这几个循环之间来回切换。
主循环(loop)
大部分操作都在此循环中完成,分为2大部分:每秒钟的操作和每10秒的操作

从代码中可以看出,是可能有延迟的。
每一秒的操作包括:
重做日志缓冲刷新到磁盘,即使这个事务还没有提交(总是)。
合并插入缓冲(可能)。
最多刷新100个InnoDB缓冲池中的脏页到磁盘(可能)。
如果当前没有用户活动,切换到后台循环(可能)。
即使事务没有提交,重做日志缓冲每秒也会被刷新到磁盘中的重做日志文件,这也是为什么再大的事务提交的时间也很快。
合并插入缓冲并不是每秒都发生。InnoDB引擎会判断一秒内发生的IO次数是够小于5次,如果小于5次,InnoDB认为IO压力很小,
就会执行插入缓冲合并。
同样,最多刷新100个脏页也不是一定发生。InnoDB会判断当前缓冲区脏页的比例是否超过了配置文件中innodb_max_dirty_pages_pct
参数(默认90%),如果超过了该值,就会刷新100个脏页到磁盘中。
接着来看每10秒的操作:
刷新100个脏页到磁盘(可能)。
合并至多5个插入缓冲(总是)。
将日志缓冲刷新到磁盘(总是)。
删除无效的重做页(总是)。
刷新100个或者10个脏页到磁盘(总是)。
产生一个检查点(总是)。
以上过程中,InnoDB首先会判断过去10秒内,IO操作是否超过200次,
如果没有,将会把100个脏页刷新到磁盘。
之后,会合并插入缓冲。
之后,会将日志缓冲刷新到磁盘。
然后,删除无用的Undo页。
在执行update或者delete操作时,因为一致性读的关系,这些行的版本信息会被保留,
在进行Undo时,会去判断这些被删除的行是否可以删除
如果可以,立即删除。通过源代码可以知道,最多一次删除20个Undo页
然后,InnoDB回去判断缓冲池中脏页的比例,如果大于70%,则刷新100个脏页,否则,刷新10个脏页
最后,InnoDB会产生一个检查点,在此刻,InnoDB会将最老日志序列号(oldest LSN)的页写入磁盘。
接着来看后台循环
如果数据库没有活动,数据库空闲或者数据库关闭时,就会切换到这个模式。
这个循环会执行的操作:
删除无用的Undo页(总是)。
合并20个插入缓冲(总是)。
跳回到主循环 (总是)。
不断刷新100个页,知道符号条件(可能,跳转到flush loop中完成)
如果刷新循环没有什么活动,会切换到暂停循环,将master thread挂起。
如果启用了InnoDB引擎,却没有任何基于InnoDB的表,就是处于这个状态。
master thread的潜在问题
从上面的知识可以知道,源代码对IO做了限制。每秒最大刷新100个脏页或者刷新20个插入缓冲。
这个可能在某些程序中会导致master thread忙不过来
所以在InnoDB Plugin版本中加入了innodb_io_capacity参数,
用来表示磁盘IO吞吐量
mysql> show variables like 'innodb_io%'G;
*************************** 1. row ***************************
Variable_name: innodb_io_capacity
Value: 200
规则如下:
在合并插入缓冲时,数量为该值的5%
在刷新脏页时,数量为该值
如果使用了SSD和进行了Raid操作,可以将该值设置的高点。
另一个问题是参数innodb_max_dirty_pages_pct,在mysql5.1(包括此版本),默认值为90%,
意味着脏页占缓冲池的90%,这个太大了!在InnoDB Plugin版本,该值被调整为了75%,
所以可以兼顾脏页刷新频率和磁盘IO。
InnoDB Plugin的另一个参数是innodb_adaptive_flushing(自适应的刷新),该值影响每秒脏页的数量
mysql> show variables like 'innodb_adaptive_%'G;
*************************** 1. row ***************************
Variable_name: innodb_adaptive_flushing
Value: ON
这个参数会导致,当脏页在缓冲池的比例小于innodb_max_dirty_pages_pct时,也会刷新一定数量的脏页。
所以,最好使用InnoDB Plugin版本,对数据库的性能会有提升。
关键特性
InnoDB的关键特性还包括插入缓冲,2次写,自适应哈希索引。
插入缓冲
我们知道,主键是行的唯一标识符,在表中,行的插入顺序是按照主键递增的
插入缓冲的使用要满足2个条件
索引是辅助索引
索引不是唯一的
2次写
这个可以保证数据的可靠性。
架构
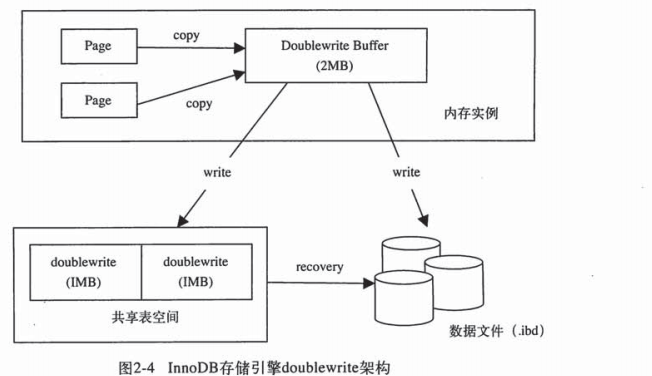
当脏页刷新时,并不是直接将其写入磁盘,而是先将其写入内存中的doublewrite buffer。
每次写入1M到共享表空间的磁盘中。这样如果数据库崩溃了,可以在共享表空间找到页的副本,
在应用重做日志来恢复。
自适应哈希索引
哈希是一种快速的查找方法。
常用语join操作
InnoDB引擎会监控表上的索引查找,如果观察到建立哈希索引会带来速度的提升,
就会建立哈希索引,这就是自适应哈希索引。
启动自适应哈希索引,可以带来读写性能2倍的提高;
可以带来辅助索引性能5倍的提高;
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276707, node heap has 402 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
默认开启
*************************** 3. row ***************************
Variable_name: innodb_adaptive_hash_index
Value: ON
启动、关闭和恢复
innodb_fast_shutdown参数影响InnoDB引擎的行为,默认为1
mysql> show variables like 'innodb_fast_shutdown'G; *************************** 1. row *************************** Variable_name: innodb_fast_shutdown Value: 1 1 row in set (0.00 sec)
0 表示关闭数据库时,需要完成所有的full purge和merge insert buffer操作
如果在升级InnoDB Plugin,可以将该值设置为0
2 表示不完成full purge和merge insert buffer操作,也不将缓冲池中的数据脏页写会磁盘,而是写在日志。
innodb_force_recovery参数影响引擎的恢复情况,默认值为0
mysql> show variables like 'innodb_force_recovery'G; *************************** 1. row *************************** Variable_name: innodb_force_recovery Value: 0 1 row in set (0.00 sec)

