一、重新分析矩阵相乘
// Md,Nd,Pd都是Width*Width的方阵,使用的Block中线程数也是W*W __global__ void MatMulKernel(float * Md, float * Nd, float * Pd, int Width) { // 横坐标为tx的列索引 int tx = threadIdx.x; // 纵坐标为ty的行索引 int ty = threadIdx.y; float Pvalue = 0; for (int k = 0;k < Width;++k) { // 处于tx的一行 float Mdelement = Md[ty * Width + k]; // 处于ty的一列 float Ndelement = Nd[k * Width + tx]; // Width元素做累加,得到坐标ty,tx的值 Pvalue += Mdelement * Ndelement; } // 将计算得到的ty,tx的值写入相应的位置 Pd[ty * Width + tx] = Pvalue; }
上述代码实现了矩阵相乘,但是只使用了一个Block来完成,那么能够计算的矩阵大小就被Block的最大容量所限制了。我们要完成大型矩阵相乘的计算,则需要将矩阵分块来处理,也就是使用多个Block来并行完成:
// Md,Nd,Pd都是Width*Width的方阵,使用多个Block来分块计算 __global__ void MatMulKernel(float * Md, float * Nd, float * Pd, int Width) { // 索引要利用Block编号、大小以及线程编号共同决定 int tx = blockIdx.x * blockDim.x + threadIdx.x; int ty = blockIdx.y * blockDim.y + threadIdx.y; float Pvalue = 0; for (int k = 0;k < Width;++k) { // 处于tx的一行 float Mdelement = Md[ty * Width + k]; // 处于ty的一列 float Ndelement = Nd[k * Width + tx]; // Width元素做累加,得到坐标ty,tx的值 Pvalue += Mdelement * Ndelement; } // 将计算得到的ty,tx的值写入相应的位置 Pd[ty * Width + tx] = Pvalue; }
dim3 dimGrid(Width / TILE_WIDTH, Width / TILE_WIDTH);
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH);
MatMulKernel <<<dimGrid, dimBlock>>> (Md, Nd, Pd, Width);
在调用时,我们需要计算需要多少个Blocks,由于例子中使用的是方阵,所以没有区分Width和Height。
这样我们就可以使用dimGrid.x * dimGrid.y个Block来一起计算一个比较大的矩阵。
二、访存带宽受限
在上述矩阵相乘的代码中,除了我们已经解决的矩阵大小的问题,还有一个很重要的问题是访存受限的问题。
代码中的for循环中,每计算一个坐标的结果,则需要读取2 * Width次,极大的受限于访存带宽。
以G80为例子:
1.G80的峰值GFLOPS为346.5,每个浮点数为4Byte,则G80每秒能够处理的Byte数为346.5*4 = 1386GByte。
2.但G80的实际访存带宽只有86.4GB/s,那么就限制了计算速度为21.6GFLOPS,而实际代码的运行速度还更低,只有15GFLOPS
为了使GPU得运算速度尽量少的被访存带宽限制,我们要尽量减少对Global Memory的访问。如下图所示:
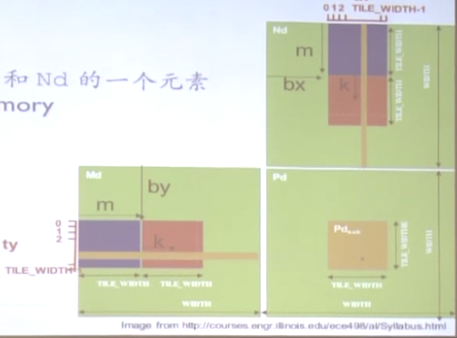
这里的Width是矩阵的总大小,TILE_WIDTH是瓦片大小。所以代码如下(代码比较绕,仔细思考):
__global__ void MatMulKernel(float * Md, float * Nd, float * Pd, int Width) { // Warp大小 const int TILE_WIDTH = 32; // 在共享存储中分配空间 __shared__ float Mds[TILE_WIDTH][TILE_WIDTH]; __shared__ float Nds[TILE_WIDTH][TILE_WIDTH]; // Block编号 int bx = blockIdx.x; int by = blockIdx.y; // Block中线程编号 int tx = threadIdx.x; int ty = threadIdx.y; // 在原数据中的某行某列 int Row = by * TILE_WIDTH + ty; int Col = bx * TILE_WIDTH + tx; float Pvalue = 0; // 为什么要循环m次,因为每一个位置的值都要计算整个列和整个行(包含m个Warp) for (int m = 0;m < Width / TILE_WIDTH;++m) { // m中的每一个Warp都要等数据拷贝完毕后才能进行计算 Mds[ty][tx] = Md[Row * Width + (m * TILE_WIDTH + tx)]; Nds[ty][tx] = Nd[(m * TILE_WIDTH + ty) * Width + Col]; // 等大家都拷贝完 __syncthreads(); // Pvalue累加了m次独立Warp互相运算的结果,得到最终一行Warp和一列Warp的运算结果 for(int k = 0;k<TILE_WIDTH;++k) Pvalue += Mds[ty][k] * Nds[k][tx]; // 等到大家都计算完,在执行下一对Warp __syncthreads(); } // 得到最终结果后,写入Pd Pd[Row*Width + Col] = Pvalue; }
上述代码在个Block计算之前,将对应的数据由各个线程自己拷贝到对应的共享存储中,相当于1:1访问。然后在计算时,直接从共享存储中访问。这里我们使用Warp的大小,例如是32,则我们对Global的访问次数就减少了32倍,所以我们需要确定Warp选用多大的数最好。
三、Warp分支发散和Warp分割
假设一个Warp是32个线程,那么我们的Block尽量设置为32的倍数。
我们可以将Warp看成一个部门的一个小组,这个小组里的人同吃同睡(执行统一指令),但存在分支发散,例如其中一半人去吃饭,另一半人在看。过一会,吃完饭后,另一半人去踢足球,这一组人在看。如下图所示:
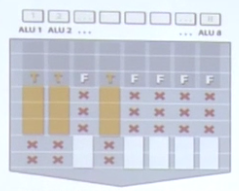
所以,在我们做分支的时候,尽量以32的倍数来分割,这样就不会出现分支发散的情况,从而提高性能。如下代码:
// 存在分支发散(假设warpSize = 32) if (threadIdx.x > 15) { // todo } // 不存在分支发散(warpSize > 1) if (threadIdx.x > warpSize - 1) { // todo }
例子,对8个数进行累加,使用8个线程,假设每两个线程是一个warp。
第一种方法,相邻两个数相加,最后得到结果:

第二种方法,每隔4个位置的数相加:
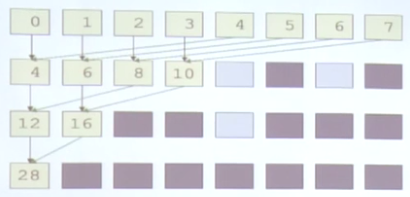
明显后者更好,可以更快的使后面的warp完成工作,从而供其他任务调度。