面向对象衍生
面向对象编程方法和编程语言一样在不断地演变发展。到了20世纪90年代,面向对象的方法在软件设计和分析等软件开发的上层领域中流行起来。1994年,当时主要的面向对象分析和设计方法Booth、OMT(Object Modeling Technique)以及 OOSE(Object Oriented Software Engineering)的发明人 Grady Booch、Jim Rumbaugh 和 Ivar Jacobson 合作设计了 UML(Unified Modeling Language)。UML 是用来描述通过面向对象方法设计的软件模型的图示方法,也是利用这种记法进行分析和设计的一种方法论。
UML提供了很多设计高可靠性软件的面向对象设计方法。但是,UML整体上很复杂,用到的概念很多,会让初学者觉得很难掌握。面向对象的基本概念的建立,催生了各种编程语言。
复杂性是面向对象的敌人
我们再回到面向对象的重要原则,来了解真正的面向对象编程。
软件开发的最大敌人是复杂性。人类的大脑无法做太复杂的处理,记忆力和理解力也是有限的。
计算机上运行的软件却没有这样的限制,无论多么复杂的计算机软件,无论有多少数据,无论需要多长时间,计算机都可以处理。随着越来越多的数据要用计算机来处理,对软件的要求也越来越高,软件也变得越来越复杂。
虽然计算机的性能年年在提高,但它的处理能力终究是有限的,而人类理解力的局限性给软件生产力带来的限制则更大。在计算机性能这么高的今天,人们为了找到迅速开发大规模复杂软件的方法,哪怕牺牲一些性能也在所不惜。
结构化编程
最初对这种复杂的软件开发提出挑战的是“结构化编程”。结构化编程的基本思想是有序地控制流程,即把程序的执行顺序限制为顺序、分支和循环这3种,把共通的处理归结为例程。
在结构化编程出现之前,可以用goto语句来控制程序的流程,执行流可以转移到任何地方。而结构化编程用如上文所述的3种语句控制程序的流程。这样可以降低程序流程的复杂性,此外,还引入了较为抽象的处理块(例程)的概念,也就是把基本上相同的处理抽象成例程,其中不同的地方由外部传递进来的参数来对应。
结构化编程的“限制”和“抽象化”,是人类处理复杂软件的非常有效的方法。
通过限制大大降低了程序的自由度,减少了各种组合,使得程序不至于太过复杂。但是如果由于降低了程序的自由度而导致程序的实现能力低下,那是我们所不愿意看到的。而结构化编程的顺序、分支和循环可以实现一切算法,虽然降低了程序的复杂性和灵活性,但是程序的实现能力并没有降低。
抽象化的目的是我们只需要知道过程的名字,而并不需要知道过程的内部细节,因此它也被称为“黑盒化”。我们只需要知道“黑盒子”的输入和输出,而过程的细节是隐藏的。(计算器是黑盒子的一个例子。输入数字后,计算结果在液晶屏上显示出来,而内部是怎样计算的我们并不知道。也有可能是里面的小人在打算盘哦。)
例如,如果你知道了例程的输入和输出,那么即使不知道处理的内部细节也可以利用这个例程。建立一个由黑盒子组合起来的系统,复杂的结构被黑盒子隐藏起来,这样我们就可以更容易、更好地理解系统的整体结构。
如果把黑盒子内的处理也考虑上,整个系统的复杂性并没有改变。但是如果不考虑黑盒子内部的处理,系统复杂性就可以降低到人类的可控范围内。此外,黑盒子内部的处理无论怎么变化,如果输入和输出不发生变化,那么就对外部没有影响,所以这种扩展特性是我们非常希望获得的。
针对程序控制流的复杂问题,结构化编程采用了限制和抽象化的武器解决问题。结果证明,结构化程序设计是成功的,并且这种方法已经有了稳固的基础。现在几乎所有的编程语言都支持结构化编程,结构化编程已经成为了编程的基本常识。
数据抽象化
然而,程序里面不仅包括控制结构,还包括要处理的数据。结构化编程虽然降低了程序流程的复杂性,但是随着处理数据的增加,程序的复杂性也会上升。面向对象编程就是作为对抗数据复杂性的手段出现的。
世界上第一个面向对象的编程语言是Simula。随着仿真处理的数据类型越来越多,分别管理程序处理内容和处理数据对象所带来的复杂性也越来越高。为了得到正确的结果,必须保持处理和数据的一致性,这在结构化编程中是非常困难的。解决这一问题的方案就是数据抽象技术。
数据抽象是数据和处理方法的结合。对数据内容的处理和操作,必须通过事先定义好的方法来进行。数据和处理方法结合起来成为了黑盒子。
举一个栈的例子。栈是先入后出的数据存储结构。比如往快餐托盘中叠加地摞放食品。栈只有两种操作方法:入栈(push),向栈中放入数据;出栈(pop),把最后放入的数据拿出来。
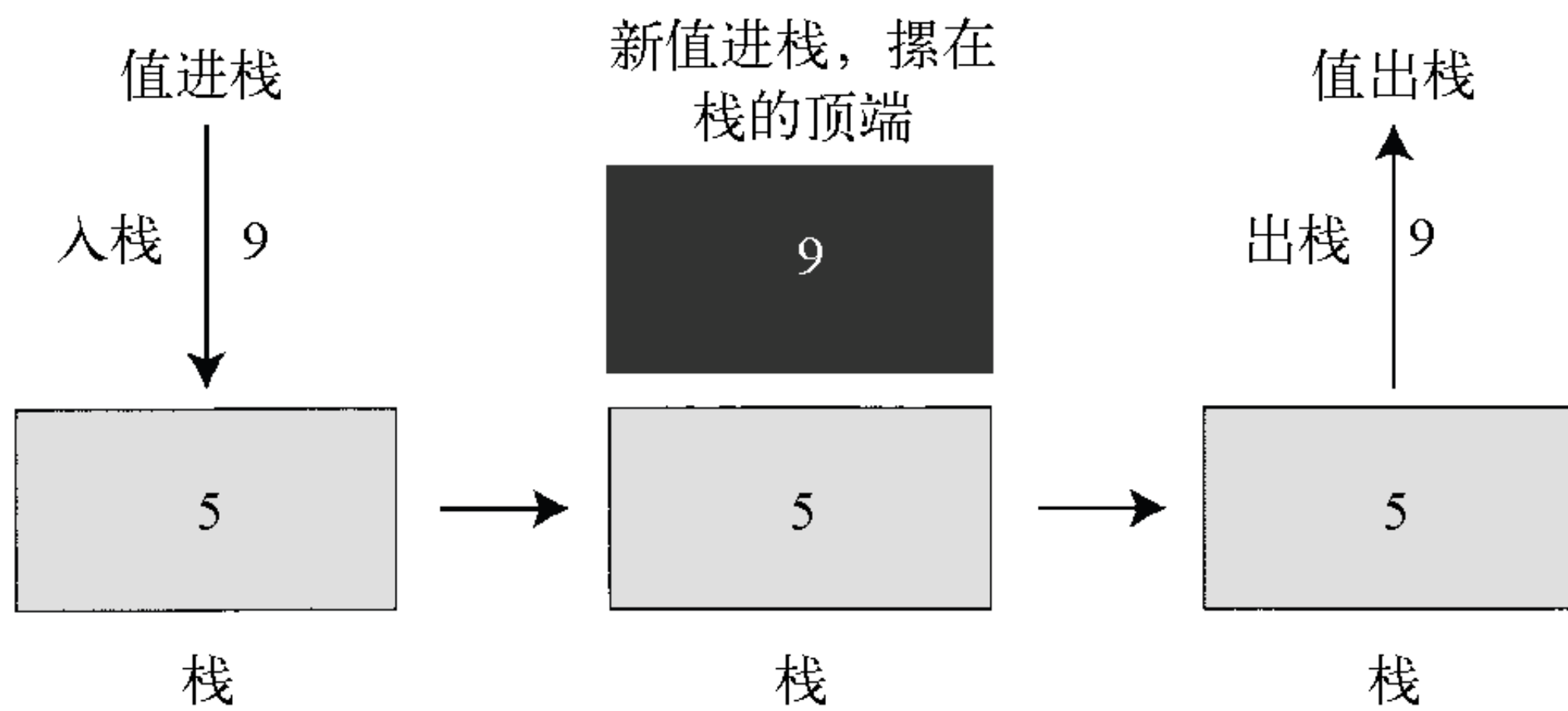
class Stack{
public:
Stack(size_t sz);
Stack(const Stack &t);
Stack& operator=(const Stack &t);
~Stack();
public:
bool isEmpty()const;
bool isFull()const;
boolean push(const Type &t);
boolean pop(Type *t);
boolean getTop(Type *t)const;
void lookAllStack()const;
private:
Type *base;
int count;
int top;
};
代码中可以直接表现push这个操作。对数据进行操作的一方,并不需要知道代码中的处理细节,而只对“要做什么”感兴趣。所以隐藏了处理细节的程序会变得更加明确,实现目的也更清晰。
不仅是操作方法容易理解,抽象数据也是能够对特定的操作产生反应的智能数据。使用抽象数据可以更好地模拟现实世界中各种活生生的实体。
有了数据抽象,程序处理的数据就不再是单纯的数值或文字这些概念性的东西,而变成了人脑容易想象的具体事物。而代码的“抽象化”则是把想象的过程“具体化”了。这种智能数据可以模拟现实世界中的实体,因而被称作“对象”,面向对象编程也由此得名。
雏形
出现在程序中的对象,通常具有相同的动作。以交通仿真程序为例,程序中有表示车和信号的对象。虽然同样的对象具有相同的性质,但是位置、颜色等状态各有不同。
从抽象的原则来说,多个相同事物出现时,应该组合在一起。这就是DRY原则(即Don't Repeat Yourself)。
我们已经看到,程序的重复是一切问题的根源。重复的程序在需要修改的时候,所涉及的范围就会更广,费用也就更高。当多个重复的地方都需要修改时,哪怕是漏掉其中之一,程序也将无法正常工作。所以重复降低了程序的可靠性。
进一步说,重复的程序是冗余的。人们解读程序、理解程序意图的成本也会增加。请记住,计算机是不管程序是否难以阅读,是否有重复的。然而,开发人员要阅读和理解大量的程序,所以程序的可读性直接关系到生产力。重复冗长的程序会降低生产力。复制和粘贴程序会导致重复,应该尽量避免。
让我们再回到对象的话题上。同样的对象大量存在的时候,为了避免重复,可以采用两种方法来管理对象。
一种是原型。用原始对象的副本来作为新的相同的对象。Self、Io等编程语言采用了原型。有名的编程语言用原型的比较少,很意外的是,JavaScript也是用的原型。
另外一种是模板。比方说我们要浇注东西的时候,往模板里注入液体材料就能浇注出相同的东西。这种模板在面向对象编程语言中称为类(class)。同样类型的对象分别属于同样的类,操作方法和属性可以共享。
跟原型不同,面向对象编程语言的类和对象有明显区别,就像做点心的模具和点心有区别一样,整数的类和1这个对象、 狗类和名字是poochy这条狗也都是有区别的。为了清晰地表明类和对象的不同,对象又常常被称作实例(instance)。叫法虽有不同,但实例和对象是一样的。
在C++面向对象编程语言中,类用关键字class来声明。
在上面的代码中,Stack就是一个类。
找出相似的部分来继承
随着软件规模的扩大,用到的类的个数也随之增加,其中也会有很多性质相似的类。这就违背了我们之前强调多次的DRY原则。程序会变得重复而且不容易理解。修改程序的代价也会变高,生产力则会降低。所以,如果有把这些相似的部分汇总到一起的方法就好了。
继承就是这种方法。具体说来,继承就是在保持既有类的性质的基础上而生成新类的方法。原来的类称为父类,新生成的类称为子类。子类继承父类所有的方法,如果需要也可以增加新的方法。子类也可以根据需要重写从父类继承的方法。
// 基类
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// 派生类
class Rectangle: public Shape
{
public:
int getArea()
{
return (width * height);
}
};
从自顶向下的方法来看,通过扩展一个类来生成新的类也是很自然的。
但是,从用自底向上的方法提取共通部分的角度来看,一个子类只能有一个父类的限制是太严格了。其实,在C++、Lisp等编程语言中,一个子类可以有多个父类,这称为“多重继承”。
多重继承的缺点
上一节讲解了面向对象编程的三大原则(多态性、数据抽象和继承)中的继承。如前所述,人们一次能够把握并记忆的概念是有限的,为解决这一问题,就需要用到抽出类中相似部分的方法(继承)。继承是随着程序的结构化和抽象化自然进化而来的一种方式。
但最后一句话严格来说并不完全正确。结构化和抽象化,意味着把共通部分提取出来生成父类的自底向上的方法。如果继承是这样诞生的话,那么最初,有多个父类的多重继承就会成为主流。
但实际上,最初引入继承的Simula编程语言,只提供单一继承。同样,在随后的很多面向对象编程语言中也都是这样的。因此我认为,继承的原本目的实际上是逐步细化。
为什么需要多重继承
单一继承只能有一个父类。有时候,大家会觉得这样的制约过于严格了。在现实中,一个公司职员同时也可能是一位父亲,一个程序员同时也可能是一位作家。
正如上一节中说明的,如果把继承作为抽离出程序的共通部分的一个抽象化手段来考虑,那么从一个类中抽象化(抽出)的部分只能有一,这个假定会给编程 带来很大的限制。因此,多重继承的思想就这样产生了。单一继承和多重继承的区别仅仅是父类的数量不同。多重继承完全是单一继承的超集,可以简单地看做是单 一继承的一个自然延伸。
可以使用多重继承的编程语言,不受单一继承的不自然的限制。例如,只提供单一继承的 Smalltalk 语言,它的类库因为单一继承而显得很不自然。
多重继承和单一继承不可分离
经过对多重继承和单一继承这样一比较,单一继承的特点就很明显了。
继承关系单纯
单一继承的继承关系是单纯的树结构,这样有利有弊。类之间的关系单纯就不会发生混乱,实现起来也比较简单。但是,如刚才的Smalltalk的Stream一样,不能通过继承关系来共享程序代码,导致了最后要复制程序。
对需要指定算式和变量类型的Java这样的静态编程语言来说,单一继承还有一个缺点,我们将在后面说明。
多重继承的特点正好相反。多重继承有以下两个优点:
· 很自然地做到了单一继承的扩展;
· 可以继承多个类的功能。
单一继承可以实现的功能,多重继承都可以实现。但是,类之间的关系会变得复杂。这是多重继承的一个缺点。
goto语句和多重继承比较相似
前面我们讲到了结构化编程,说明了与其用goto语句在程序中跳来跳去,还不如用分支或者循环来控制程序的流程。分支和循环可以用goto语句来实现,单纯的分支和循环组合起来不能直接实现的控制也可以用goto语句来实现。goto语句具有更强的控制力。goto语句的控制能力虽然很强,但是我们也不推荐使用。因为用goto语句的程序不是一目了然的,结构不容易理解。这样的流程复杂的程序被称为“意大利面条程序”。
多重继承也存在同样的问题。多重继承是单一继承的扩展,单一继承可以实现的功能它都可以实现。用单一继承不能实现的功能,多重继承也可以实现。
但是,如果允许从多个类继承,类的关系就会变得复杂。哪个类继承了哪个类的功能就不容易理解,出现问题时,是哪个类导致的问题也不容易判明。
这样混合起来发展的继承称为“意大利面条继承”。当然也不能说所有的多重继承都是意大利面条继承,但是使用时格外小心是必要的。多重继承会导致下列3个问题。
· 结构复杂化
如果是单一继承,一个类的父类是什么,父类的父类又是什么,都很明确,因为只有单一的继承关系。然而如果是多重继承的话,一个类有多个父类,这些父类又有自己的父类,那么类之间的关系就很复杂了。
· 优先顺序模糊
具有复杂的父类的类,它们的优先关系一下子很难辨认清楚。D 继承父类方法的顺序是 D、B、A、C、Object 还是 D、B、C、A、Object,或者是其他的顺序,很不明确。确定不了究竟是哪一个。相比之下,单一继承中类的优先顺序是明确了然的。
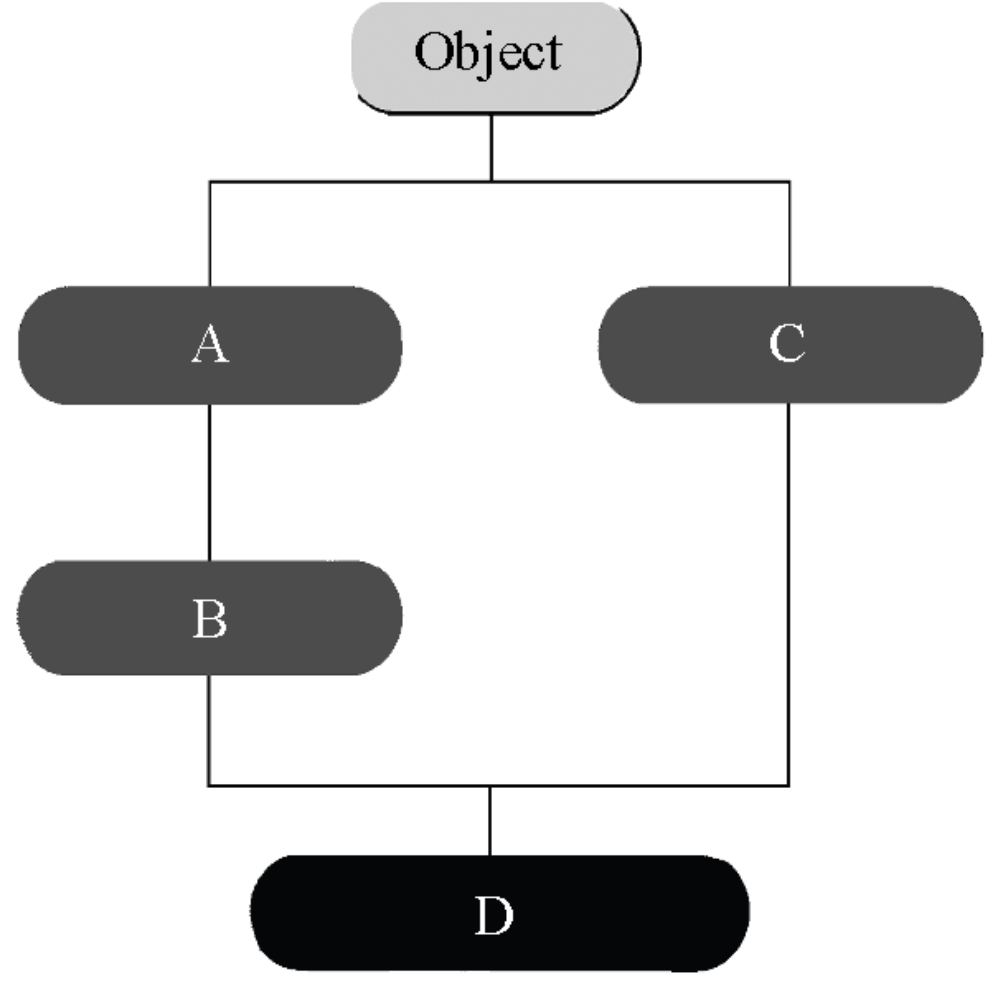
· 功能冲突
因为多重继承有多个父类,所以当不同父类中有相同的方法时就会产生冲突。比如在上图中,当类 B 和类 C 有相同的方法时,D 继承的是哪个方法就不明确了,因为存在两种可能性。
后面作者还写了很多关于多重继承,来排除大家对于多重继承的误解,并说到了Java中的接口来实现多重继承,我大致看了下,都写得相当有水平,我就不再赘述了。
参考文献:
松本幸弘的程序世界
C++面向对象入门
http://learn.jser.com/cplusplus/cpp-inheritance.html