Context-Aware Network Embedding for Relation Modeling
论文:http://www.aclweb.org/anthology/P17-1158
创新点:
- 考虑属性连边关系
- 引入卷积神经网络
- 结构信息借助深层网络表示,将不同节点间关联信息融入CNN中
- 基于TensorFlow 架构实现CNN
基于上下文感知网络嵌入的关系建模
本文主要针对目前存在的 NE 方法对于每个顶点仅有一个简单 embedding,没有考虑到网络节点根据不同的交互对象会展现出不同交互特性的缺陷,提出了上下文敏感的网络表示(CANE)。
- 首先通过 cnn 得到网络顶点的一个 embedding(context-free embedding)
- 之后通过计算该节点与相邻节点的 mutual attention(在 pooling 层引入一个相关程度矩阵),得到顶点针对该相邻节点的 context-aware embedding
- 最终顶点的 embedding 表示由这两个 embedding 结合得到
上下文感知的网络嵌入框架:
无上下文嵌入: 与不同邻居交互时,嵌入保持不变
上下文感知嵌入:面对不同邻居时动态
network embedding(网络嵌入方法)
学习网络中节点的低维潜在表示,学到的特征用来:用作基于图的各种任务特征:分类,聚类,链路预测
出现背景:信息网络可能包含数十亿个节点和边缘,因此在整个网络上执行复杂的推理过程可能会非常棘手
中心思想:找到一种映射函数,该函数将网络中的每个节点转换为低维度的潜在表示
总结
任务
给定:节点描述信息,及其交互信息
目标:使用低维有效的向量表示节点信息
背景
1. 与不同邻居交互时,展示不同的方面(如研究人员以不同研究主题与合作伙伴合作,用户分享不同兴趣给不同邻居,网页链接到不同页面用于不同目的)
2. 现有 NE 方法:
(1)与不同邻居交互时,不能灵活处理侧重点转换
(2) 限制顶点间的交互关系:如AB分享不同兴趣,但却彼此相近,因为由中间人联系
1. 概述
现有方法:无上下文嵌入,与其他顶点交互时忽略不同角色
提出:上下文相关的网络嵌入(CANE)
通过相互关注机制学习顶点的上下文感知嵌入
CANE:应用在基于文本的信息网络
利用节点丰富的外部信息:文本、标签、其他元数据
此处上下文关系更重要
当节点 u和v 交互时,相互关联的文本信息分别来自 Su 和 Sv ,对于每个顶点,可使用神经网络构建基于文本的无上下文嵌入
引入相互注意方案,将u和v间的相互关注建立在神经模型中(引导神经模型)
实验结果:
适合涉及顶点间复杂交互的情况
应用方面:链路预测、顶点分类
2. 相关概念
信息网络 G = (V, E, T)
1. V 顶点集合
2. E《 V*V 边集合
3. T 顶点的文本信息
4. eu,v 顶点(u,v)间的关系 w 为权重 (Wu,v !== Wv,u)
5. 顶点文本嘻嘻被表示为单词序列 Sv = (w1, w2, ...,wnv)
6. NRL 根据顶点结构和相关信息学习一个低维矩阵v 进行表示
3. 模型构建
充分利用网络结构和文本信息,提出两类顶点嵌入:
- 基于结构的嵌入 Vs
- 基于文本的嵌入 Vt
(无感知/上下文感知,决定V是否为上下文感知)
连接两者:V = Vs * Vt
CANE :旨在最大化边的总体目标函数(基于结构的目标、基于文本的目标)
每个边L(e) 包含两部分
Ls(e) ,Lt(e) 分别为基于结构、基于文本的目标函数
3.1. 基于结构的目标函数
旨在使用基于结构的嵌入来测量有向边的对数似然(无向边可认为是具有相反方向相等权重的两个有向边)
根据 LINE 方法,定义v 基于 u 的条件概率
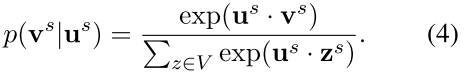
3.2. 基于文本的目标函数(无感知/上下文感知,决定V是否为上下文感知)
从关联顶点的文本信息中获取
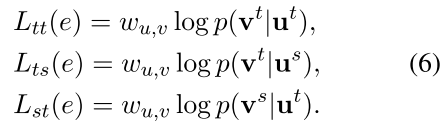
上面的条件概率将两种顶点嵌入映射到相同的表示空间,考虑其各自特点,不设置完全相同,使用softmax 函数计算概率(如eq4)
4. CNN 在表示学习的转化应用
4.1. 无上下文文本嵌入
将节点的单词序列作为输入,CNN 通过三层获得基于文本的嵌入
1. Looking-up
S = (w1, w2,...,)
将所有text 构成词汇表,对应于每个节点,有则为1,没有为0,获取嵌入序列 S
d 为单词嵌入的维度
2. convolution
卷积层提取输入嵌入序列 S 的局部特征
方式:矩阵点乘:卷积核为行向量,一行一行扫描
使用卷积矩阵在长度为l 的滑动窗口执行卷积运算
Si:i+l-1 表示第 i 个窗口内的字嵌入,b 为偏移向量
d 为卷积核数量(l * d`)对应于滑动窗口大小为l 个词向量大小
3. max-pooling
在{x0, x1...} 运行最大池化和非线性转换,每个卷积核得到特征值为
(Vt 与它与之交互的其他顶点无关,故命名为无上下文的文本嵌入)
此处得到顶点 text 的d 维表示
4. Content-aware-CNN
用CNN 对顶点的文本信息进行编码得到基于文本的嵌入
这里并未实现节点间content-aware ,只是用CNN做的一个 text 向量表示
采用相互关注机制获取上下文感知的文本嵌入,使池化层得知顶点间文本嵌入的影响
过程如下图:

looking-up 和convolution 阶段相似
池化前,引入注意力矩阵 A ,非线性变化后得到相互关系矩阵F,行平均池化得到 U 的表示,列平均池化得到 V的表示
引入softmax 归一化
嵌入生成过程:
1. 给定边:eu,v 对应于文本序列 Su Sv
2. 通过卷积层得到矩阵P Q
(m 和 n 代表 S 的长度)
3. 通过引入注意矩阵 A ,计算相关性矩阵 F
(F 中元素Fi,j 表示两个隐藏矢量P Q间的相关分数)
4. 沿着F的行和列进行池化操作,生成重要性向量, 行池,列池,采用平均池操作,获得重要性向量 gp 和 gq
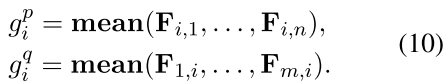
5. 使用softmax 函数转换重要性载体 gp gq 为 ap aq,ap的第i个元素

6. u 和 v 的上下文感知文本嵌入计算为
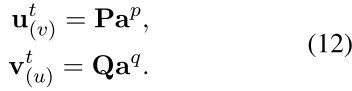
7. 因此:给定边(u,v),可获得结合结构嵌入和上下文感知的文本嵌入
4.2. CANE 优化
由 eq 3 和 eq6 可知,CANE 旨在最大化u v 间的几个条件概率 
使用softmax 优化条件概率计算花销太大,通过最大化条件概率密度,使用负抽样,转化目标函数为
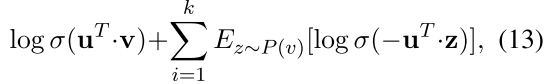
k 为负样本数量
0 sigmoid 函数
顶点分布:
dv 为 d 的出度
使用 Adam 优化转化后的目标函数
5. 实验
dataset :
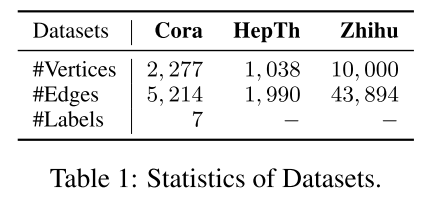
- Cora:引文网络
- 含有text 信息
- 有分类信息
- 存在标签信息缺失
- HepTh
- arxiv 的引文网络
实验:
1. 三个数据集上进行链路预测
2. Cora 上进行节点分类
6. baseline
仅考虑结构:
- MMB(Mixed Membership Stochastic Blockmodel)
- 关系数据的传统图形模型,允许每个顶点形成边缘时随机选择不同“主题”
- DeepWalk
- 通过网络随机游走并使用Skip-Gram 模型学习顶点嵌入
- LINE
- 使用一阶和二阶邻域学习大规模网络中的顶点嵌入
- Node2vec
- 基于DeepWalk 的偏向随机游走算法,可有效检索邻域架构
结构和文本:
- Naive Combination
- 简单将基于结构的嵌入于基于CNN 的嵌入连接表示顶点
- TADW
- 采用矩阵分解合并顶点文本特征进行网络嵌入
- CENE
- 通过将文本内容视为特殊顶点利用结构和文本信息,并优化异构链接的概率
7. 评估指标和实验设置
- 链路预测
- 采用标准的评估矩阵 AUC,表示随机未观察到的链接中的顶点比随机不存在的链接中的顶点更相似的概率
- 顶点分类
- L2 正则化逻辑回归(L2R-LR) 训练分类器,并评估各种方法的分类准确性
实验设置
所有方法设置嵌入维度为200
- LINE
- 负样本数量 5
- 分别学习100 维一阶和二阶嵌入,连接形成200 维嵌入
- node2vec
- 采用网格搜索选择最佳执行的超参数进行训练
- CANE
- 应用网格搜索设置CANE中的超参数
- 将负样本数k 设置为 1,加快训练过程
- 用三个版本CANE 验证
- text-only
- CANE without attention
- CANE
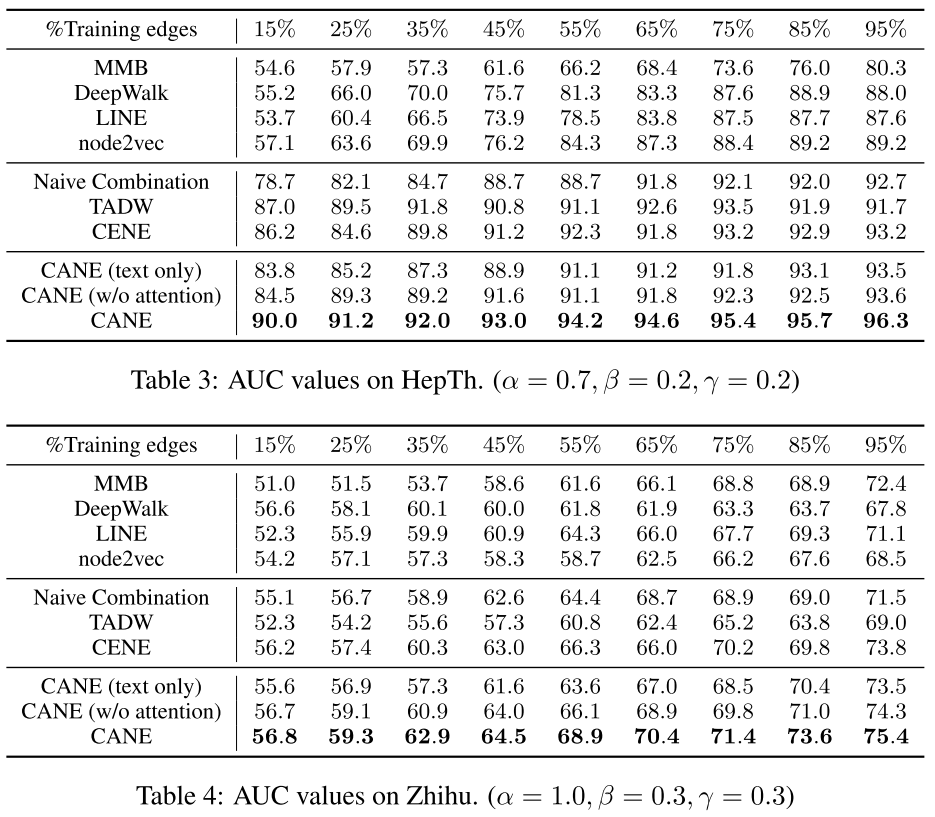
8. 结果显示
链路预测
顶点分类
网络分析任务(顶点分类、聚类)需要全局嵌入,而不是每个顶点的上下文感知嵌入
通过简单平均所有上下文感知嵌入生成顶点u 的全局嵌入(N为顶点数)

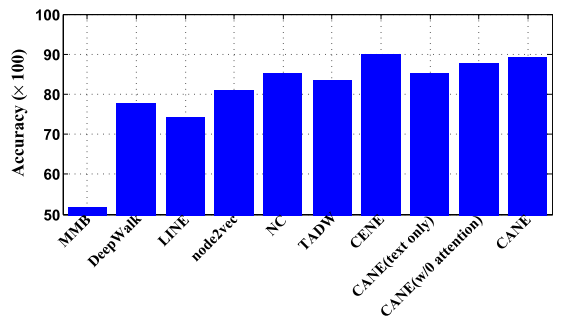
- 通过平均操作转换为高质量的无上下文嵌入
9. 可改进/受限
- 本文考虑的 context 是针对一条边所连接的节点文本信息,
- 可将节点 context 认为是该节点连接的边及其邻居节点信息
- 节点表示可能方案:将抽取到的selective attention 找到和该节点连接重要的边,再使用mutual attention 对节点的text 和 边邻域节点的text 进行融合表示