https://mp.weixin.qq.com/s/t93z1cIuQIxDLUhsn4eCKg
于芯片而言,功耗不仅仅是耗能问题,它会严重影响可靠性、性能及成本。而对于手持设备,功耗更是必需要严肃对待的一项性能指标,待机时间与其直接相关。所以功耗在芯片诞生过程中从算法架构到设计实现到封装测试从始至终都是被热切关怀着。老生常谈:芯片80%的功耗都取决于掌控『灵魂』的算法架构部分,『劳工』只有20%的空间可以发挥。
题外话:最多只有10%的硅农是可以掌握『灵魂』的,剩下那90%就是劳工,他们夜以继日乐此不疲地搬着砖,中间几乎没有通道,一切都取决于最初的决定。那10%都是高山仰止的,驴无法企及,所以只能浅显的论述一下劳工能做的事儿。

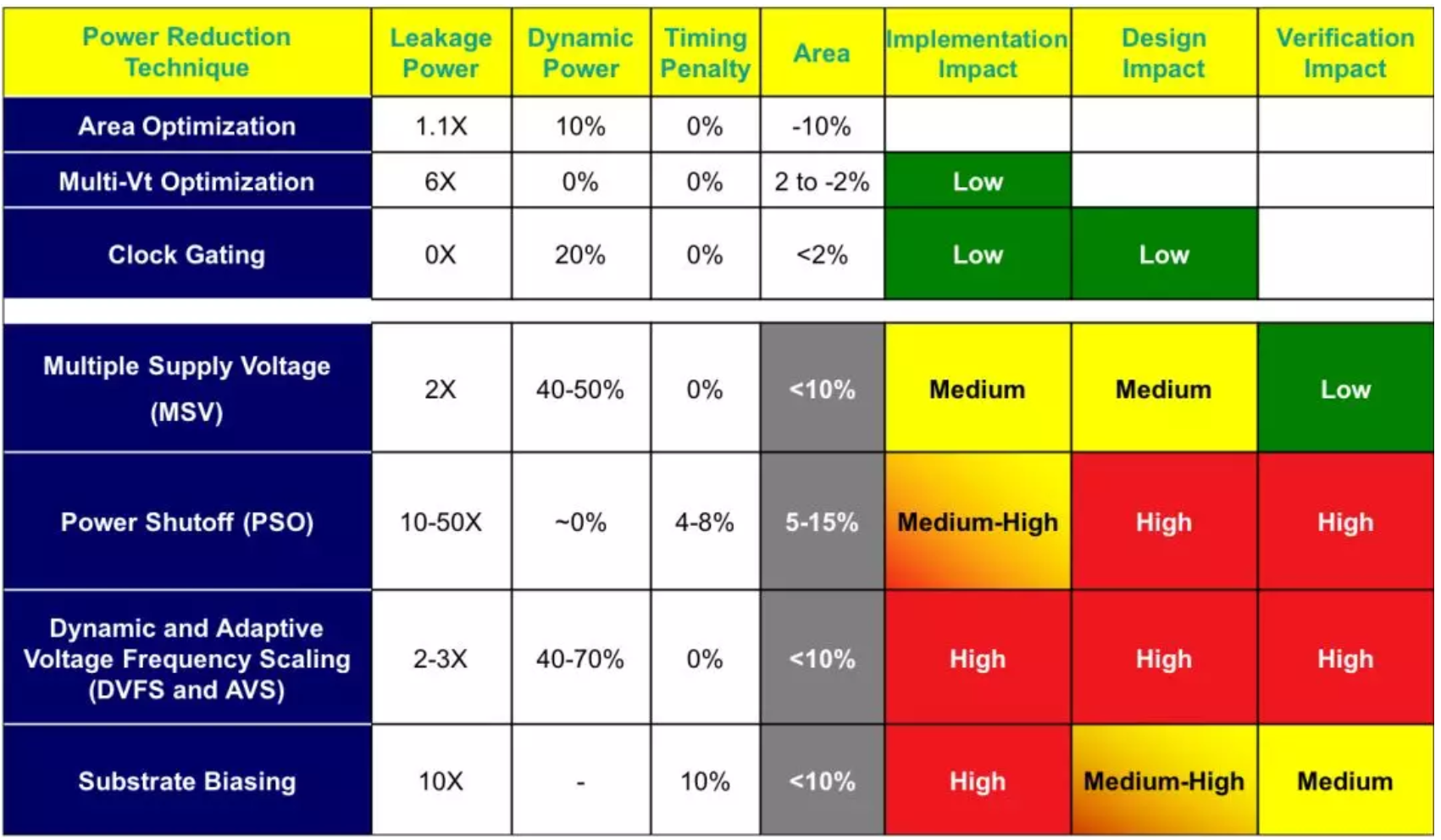
劳工们虽然触碰不到灵魂,但却不乏探索精神,他们在20%的空间内竭尽所能发挥聪明才智,探寻出了一套优化功耗的方法。下表列出了目前主流的优化功耗的方法及对设计、实现、验证各个环节的影响。论及动态功耗的优化,还是需要从动态功耗的组成及对应的计算公式入手,当工作电压和频率一定时,那优化动态功耗首要的目标就是尽量去减少toggle rate,此外对于internal power 还需要尽量减小输入pin 的transition 跟输出的load,对于负载功耗当然是尽量减小负载电容。基于此大致有如下几种优化动态功耗的方式:
-
clock gating: 到目前为止依旧是最行之有效的办法。
-
multi bit merge:需要库的支持。
-
activity driven power optimize:需要读入activty 文件
-
多电压域(MSV):需要power intent 支持。
-
动态电压频率调整(DVFS):需要power intent 支持。
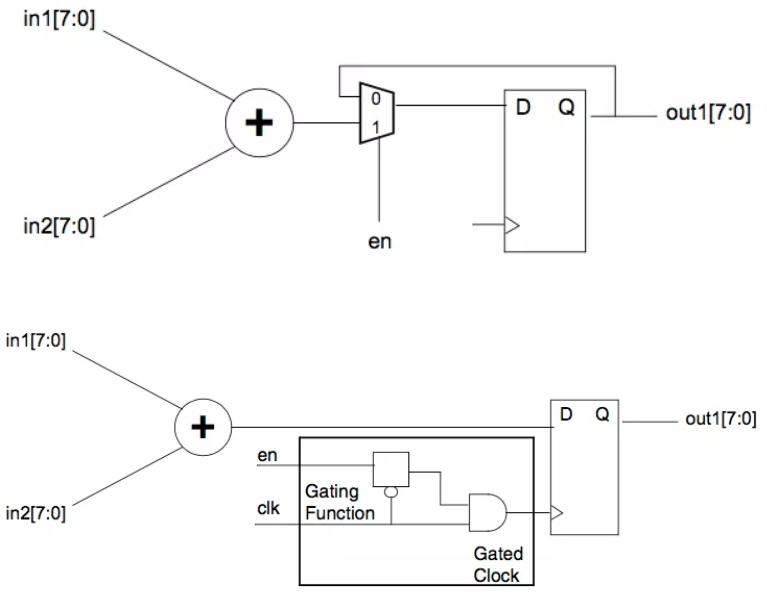
Clock gating:
clock gating就是通过减小clock tree 的toggle rate来减小动态功耗的,其原理很简单,就是将寄存器D pin上的逻辑映射到clock pin, 通过控制clock 是否翻转来确定寄存器是否锁入新的值。如下一个简单的示例,这样有if 语句的代码在RTL 中比比皆是,这样一段代码对应的电路是 MUX + DFF,MUX 的选择端即是if 语句的『判断条件』,当条件满足时,寄存器锁入新的值,否则寄存器的值不变,对于这样一个电路而言,不论『判断条件』是否满足clock每个周期都会翻转,Post-CTS 后的网标,这条clock path上不只有这组寄存器还有一串buffer/inverter, 所以clock 每翻转一次就会消耗一次功耗,如果让clock 只在需要翻转的时候才去翻转,那动态功耗自然会减少。做法非常简单成熟,成熟工艺的library 中都有glitch free的ICG cell, 综合工具会根据用户的设置自动去完成clock gating 的『映射』或『插入』。即将原始电路中D pin的MUX 映射成clock PIN 的ICG cell, MUX的选择信号即为clock gating 的使能信号。通过这种方式大概可以减少20%左右的动态功耗。

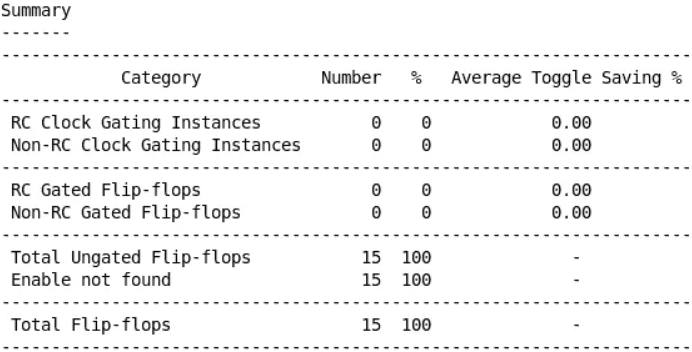
做完clock gating之后一定要用report clock_gating 检查一下插入了多少gating cell, 被gating 掉的比例有多少,及平均节省的toggle rate 是多少。
Multi bit Merge:
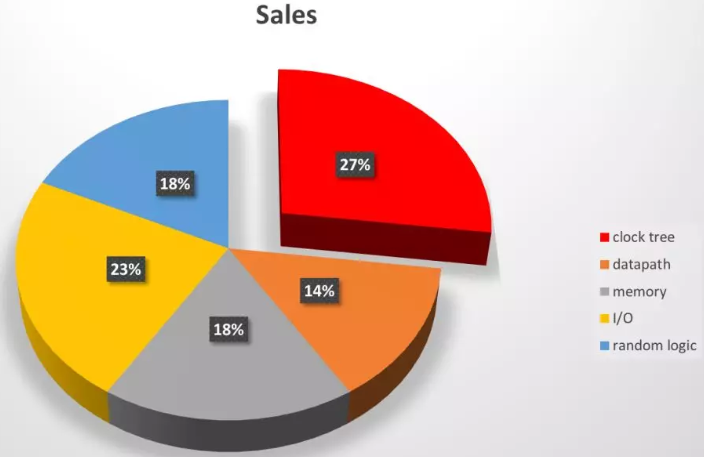
据统计芯片内27%的功耗都消耗在clock tree上,树大招风,它成了优化动态功耗的主要攻击目标。除了上面提及的clock gating之外,28nm之后被普遍使用的一种技术就是多比特寄存器,常见的有2/4/6/8 比特。多比特寄存器从以下几方面减小动态功耗:
-
多比特寄存器内部晶体管的共用使得同等size同样功能的多个单比特寄存器的晶体管数、面积跟内部功耗比对应的一个多比特寄存器大。
-
目前主流的多比特Scan寄存器,都会把scan chain集成在cell内部,多个比特共用一个SI跟SE,从而节省了scan Pin。
-
sink 点clock buffer 的节省,每个单比特寄存器clock pin 都可能有一个buffer,映射成多比特寄存器后,这些clock buffer就可以省掉。

怎么做:
做multibit merge必须要library 支持,Genus multibit flow 的用户接口非常简单,只要设置一个变量即可,默认Genus multibit merge 是timing driven 的,如果要追求更高的merge ratio, 可以用变量控制让工具做merge 的时候不考虑timing 。

做完multibit merge 之后可以用命令report multibit inferencing 来check merge 的ratio 及没被merge 的原因
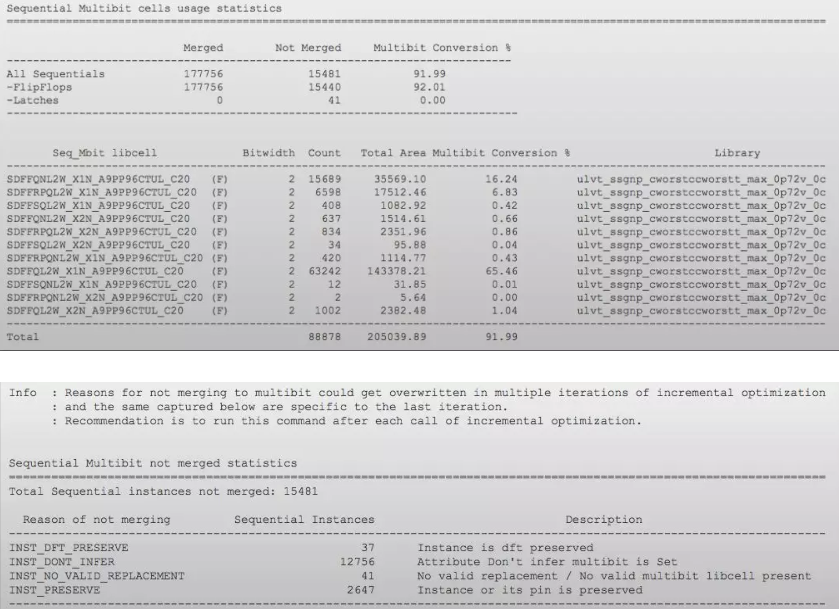
除了seq cell 可以做multibit merge,combinational cell 也可以做multibit merge 只要library 里有对应的cell 就可以做。现在常见的有multibit low power cell, 如多比特level shifter / isolation cell.
Activity driven power optimize:
在综合或PR的时候带着真实的activity 文件(仿真波形),做动态功耗优化。通常工具会通过以下几种手段优化动态功耗:
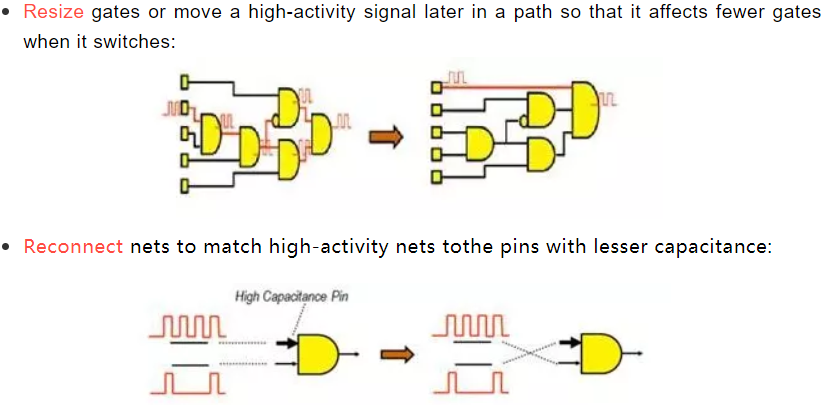
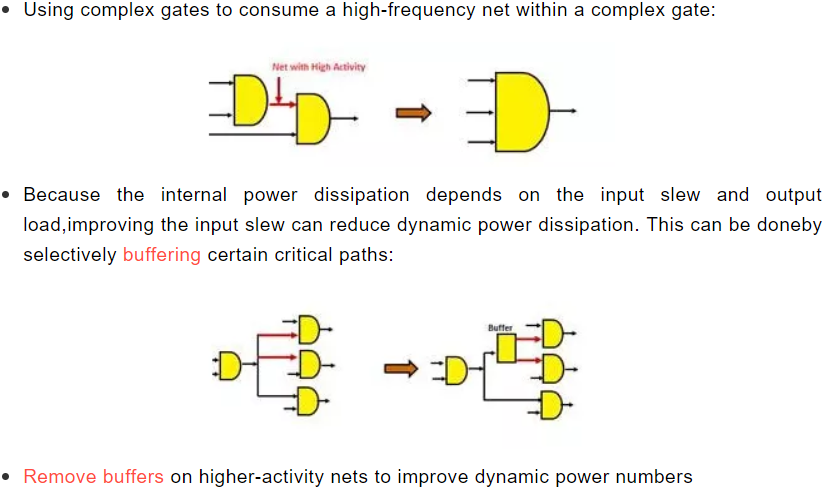
怎么做:
如下是Genus activity driven synthesis 的流程,相对于其它流程,只需要在elaborate 后读入activity 文件即可,需要特别注意的是反标率。

MSV跟DVFS:
多电压域(MSV)跟动态电压频率调整(DVFS)都需要library 跟power intent 支持。至于电压域的划分,涉及到整个芯片的电源管理,当然由系统架构的人确定,劳工只要根据划分好的power domain 及定义好的工作状态,完成UPF 的描述,在综合或PR时插入相应的低功耗 cell 并将对应的power 线连好即可。关于低功耗的部分,如1801 coding, CLP check 等后续会单独陈诉。