FM的改进之一:DeepFM。
一、概述
FM模型可以通过点积和隐向量的形式学习交叉特征。由于复杂度的约束,FM通常只应用order-2的2重交叉特征。深层模型善于捕捉high-order复杂特征。所以有了FM和DNN的结合,DeepFM。
论文:https://arxiv.org/abs/1703.04247
DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order特征,DNN可以抽取high-order特征。无需Wide&Deep模型人工特征工程。
由于输入仅为原始特征,而且FM和DNN共享输入向量特征,DeepFM模型训练速度很快。
在Benchmark数据集和商业数据集上,DeepFM效果超过目前所有模型。
本质上DeepFM依然是一个wide&deep模型,wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization)。
二、DeepFM模型
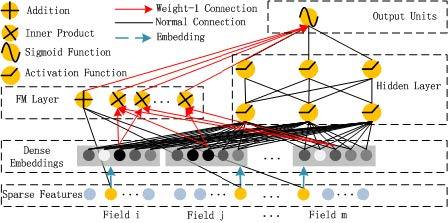
1、公式
模型输出为FM部分和DNN部分的结合
2、FM部分
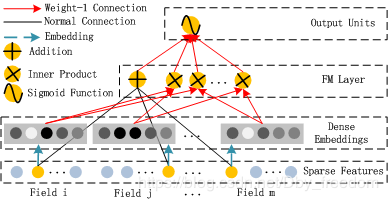
FM部分的输出由两部分组成:一个 Addition Unit,多个内积单元。
FM模型不单可以建模1阶特征,还可以通过隐向量点积的方法高效的获得2阶特征表示,即使交叉特征在数据集中非常稀疏甚至是从来没出现过。这也是FM的优势所在。
关于FM部分的理论在:从零开始的FM(1)
这里的d是输入one-hot之后的维度,我们一般称之为 feature_size。对应的是one-hot之前的特征维度,我们称之为 field_size。
虽然公式(y_{FM})是所有部分都求和,是一个标量。但是从FM模块的架构图上我们可以看到,输入到输出单元的部分并不是一个标量,应该是一个向量。
实际实现中采用的是FM化简之后的内积公式,最终的维度是:field_size + embedding_size(对应FM Layer中的神经元个数: Field数量 + 嵌入维度 = F + k,其中 F 为one-hot之前特征维度,k 为embedding的特征维度)。
1、field_size 对应的是 <W,X>。
X为原始特征one-hot编码之后的特征,我们认为X的每一列都是一个单独的维度的特征。这里我们表达的是X的1阶特征,说白了就是单独考虑X的每个特征,他们对最终预测的影响是多少。是多少那?是W!W对应的就是这些维度特征的权重。假设one-hot之后特征数量是feature_size,那么W的维度就是 (feature_size, 1)。
这里 (<W,X>) 是把X和W每一个位置对应相乘相加。由于X是one-hot之后的,所以相当于是进行了一次 Embedding!X在W上进行一次嵌入,或者说是一次选择,选择的是W的行,按什么选择那,按照X中不为0的那些特征对应的index,选择W中 row=index 的行。
所以:FM模块图中,黑线部分是一个全连接!W就是里面的权重。
如果是简单的(1,feature_size)*(feature_size,1),则结果维度为1,但其实一阶的输出维度为field_size。所以其实是特征拼接在一起,而不是加在一起。
2、embedding_size
embedding_size对应的是(sum_{j_1=1}^d sum_{j_2=j_1+1}^d<V_i,V_j>x_{j_1}x_{j_2})
FM论文中给出了化简后的公式:
这里最后的结果中是在[1,K]上的一个求和。 K就是W的列数,就是Embedding后的维度,也就是embedding_size。也就是说,在DeepFM的FM模块中,最后没有对结果从[1,K]进行求和。而是把这K个数拼接起来形成了一个K维度的向量。
其实现过程:就是从field_size个嵌入矩阵种获取每个field one-hot编码后值为1的索引对应的行向量,得到field_size个行向量,拼接成维度为(field_size,embedding_size)的二维矩阵;对该二维矩阵进行求和、平方等后续操作。
3、FM_layer
所以图中FM layer层元素维度为:field_size + embedding_size 。 整个过程需要训练的参数为:
一阶embedding矩阵 w=(feature_size ,1)。实际中,并不是一个embedding矩阵,而是有field_size个embedding矩阵,每个field生成一个数,然后得到FM_layer的前field_size个输入。
其pytorch代码如下:其中feature_sizes为DeepFM(2)中得到的feature_sizes.txt,里面包含了每个field的field_size。
fm_first_order_Linears = nn.ModuleList(
[nn.Linear(feature_size, self.embedding_size) for feature_size in self.feature_sizes[:13]])
fm_first_order_embeddings = nn.ModuleList(
[nn.Embedding(feature_size, self.embedding_size) for feature_size in self.feature_sizes[13:40]])
self.fm_first_order_models = fm_first_order_Linears.extend(fm_first_order_embeddings)
二阶交互矩阵 V = (feature_size,embedding_size),实际上也是有field_size个嵌入矩阵。
其torch代码如下:
fm_second_order_embeddings = nn.ModuleList(
[nn.Embedding(feature_size, self.embedding_size) for feature_size in self.feature_sizes[13:40]])
ps:数值特征不能进行embedding,所以在FM的二阶特征只包含类别特征的交互。这里就有一个思考:价格500和性别为女的交互,价格501和性别为女的交互,二者有何含义和不同之处
3、DNN部分
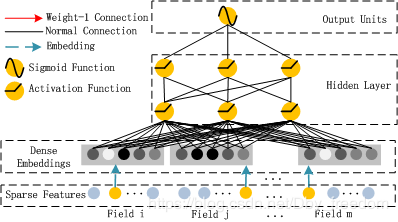
该部分和Wide&Deep模型类似,是简单的前馈网络。在输入特征部分,由于原始特征向量多是高纬度,高度稀疏,连续和类别混合的分域特征,为了更好的发挥DNN模型学习high-order特征的能力,文中设计了一套子网络结构,将原始的稀疏表示特征映射为稠密的特征向量。
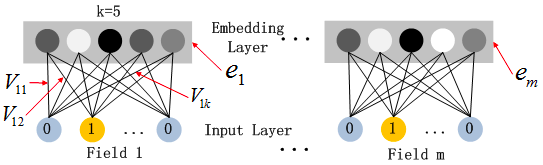
子网络设计时的两个要点:
1、不同field特征长度不同,但是子网络输出的向量需具有相同维度 embedding_size;
2、利用FM模型的隐特征向量V作为网络权重初始化来获得子网络输出向量;
这里的隐特征向量V,就是二阶交互矩阵V,一共有field_size(这里可以理解为有field_size个类别特征)个。每一个对应的输出维度为embedding_size,所有最终的dense embedding的维度为:field_size * embedding_size。
如上图假设k=5,对于输入的一条记录,同一个field只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的(V_i),((i in {1,field_size}))。文中将FM的预训练V向量作为网络权重初始化替换为直接将FM和DNN进行整体联合训练,从而实现了一个端到端的模型。
假设field_size=m,子网络的输出即为DNN模块的输入
DNN网络第l,l>=1层为:
4、FM和DNN合并
一阶、二阶、DNN的输出都为一个数,三个数求和,然后经过sigmoid激活函数
output = sigmoid(first_order_output + second_order_output + dnn_output)