redis 中 set 和 hset 有什么不同,什么时候使用 hset 什么时候使用set?
redis 中存数据时,到底什么时候用 hset 相比于 set 存数据时又有什么不一样?
set 就是普通的已key-value 方式存储数据,可以设置过期时间。时间复杂度为 O(1),没多执行一个 set 在redis 中就会多一个 key ,
hset 则是以hash 散列表的形式存储。超时时间只能设置在 大 key 上,单个 filed 则不可以设置超时 时间复杂度我百度了很多文章都说是 O(1) 但是我下面给出的参考文章说时间上的时间复杂度其实是 O(N) N 值是单个hash 上的 filed 个数,所以 hash 上单个不适合存储大量的 filed 并且如果 filed 多了比较消耗cpu,但同时以 散列表存储则比较节省内存。
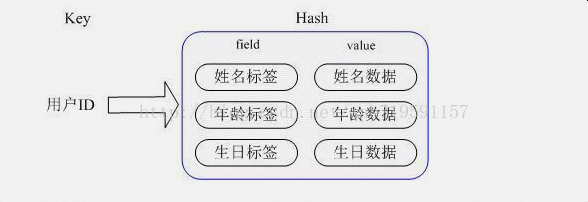
所以在实际的使用过程中应该使用 set 存储单个大文本非结构化数据 hset 则存储结构化数据,一个 hash 存储一条数据,一个 filed 则存储 一条数据中的一个属性,value 则是属性对应的值。
例如 数据库中有一张表 user 包含 id,name,age,sex 4个属性,并且有400w条数据,
id,name,age,sex
1、1,张三,16,1
2、2,李四,22,1
3、3,王五,28,0
4、4,赵六,32,1
...
如果要整表缓存到 redis 中则使用 hash ,一条数据一个hash 一个hash 里则包含4个filed。
hset user_1 id 1 name 张三 age 16 sex 1
hset user_2 id 2 name 李四 age 16 sex 1
...
这样存储,如果用户的某个属性值改变,还可以单个修改。
例如 吧张三的年龄改为30 则可以使用命令: hset user_1 age 30
在比如如果要缓存应用整个首页 html ,或则某个商品的详情介绍(一般来说商品的详情介绍是makdown语法的富文本信息,或 html 格式的富文本信息) 则使用 则可以使用 set
又或则 应用中的 某个热点数据,都可以使用 set 存储一大段数据。