数据结构的概念
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
HashMap的底层数据存储过程
使用代码:
public class Demo01 {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("Kobe", 40);
map.put("James", 36);
map.put("Iverson", 45);
map.put("Jordan", 57);
map.put("Kobe", 41);
}
}
输出结果:
{Kobe=41, James=36, Jordan=57, Iverson=45}
具体存储过程
- 在jdk1.8之前,构造方法中创建一个长度是16的 Entry[] table 用来存储键值对数据的。在jdk1.8以后不是在HashMap的构造方法底层创建数组了,是在第一次调用put方法时创建的数组 Node[] table 用来存储键值对数据。
- 根据存储的数据中的key值,利用hashcode方法计算出哈希值,然后结合数组长度采用某种算法计算出向Node数组中存储数据的空间的索引值。若索引位置没有数据,则将数据存储。
- 根据上面的代码,如果根据Kobe计算出来的索引值为2,,根据Iverson计算出来的索引值也为2,那么此时数组空间不是null,此时底层会比较Kobe和Iverson的hash值是否一致,如果不一致,则在空间上划出一个结点来存储键值对数据<"Iverson", 45>,这种方式称为拉链法。
- 第一个存储的数据是Kobe,第五个存储的数据也是Kobe,根据Kobe计算出来的索引值肯定一样,那么就会直接比较二者哈希值,很明显哈希值一样,这个时候就会发生哈希碰撞,那么底层会调用Kobe所属类 String 中的 equals() 方法比较两个内容是否相等:相等:将后添加的数据的value覆盖之前的value。不相等:继续向下和其他的数据的key进行比较,如果都不相等,则划出一个结点存储数据,如果结点长度即链表长度大于阈值8并且数组长度大于64则将链表变为红黑树。
- 随着数据越存越多,就会涉及到数组的扩容问题,当超出数组阈值时,会发生扩容,且扩容为原数组的两倍,并将元素组内容复制到新数组中。
总结
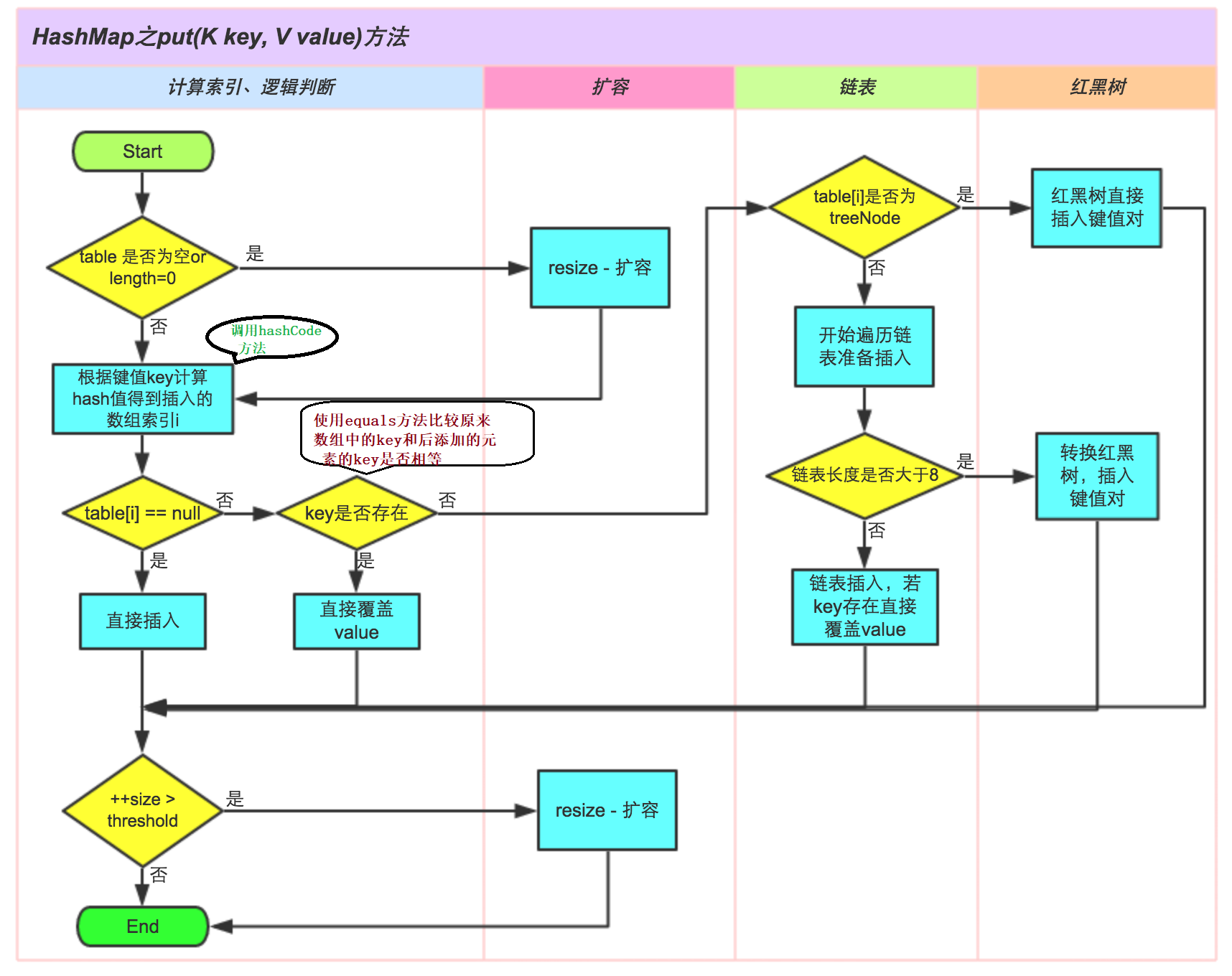
说明:
1.size表示 HashMap中K-V的实时数量 , 注意这个不等于数组的长度 。
2.threshold( 临界值) =capacity(容量) * loadFactor( 加载因子 )。这个值是当前已占用数组长度的最大值。size超过这个临界值就重新resize(扩容),扩容后的 HashMap 容量是之前容量的两倍 。