grep(global search regular expression(RE) and print out the line,整行搜索并打印匹配成功的行
语法:grep [选项] 搜索词 搜索的文件
选项:
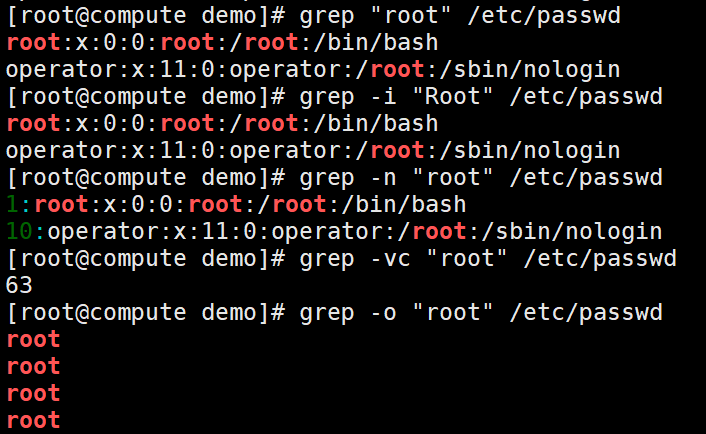
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号(number)
-w :全词(word)匹配,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :统计(count)含有搜索词的行有多少个,仅打印统计的数值而不打印行的内容。注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只(only)显示被匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
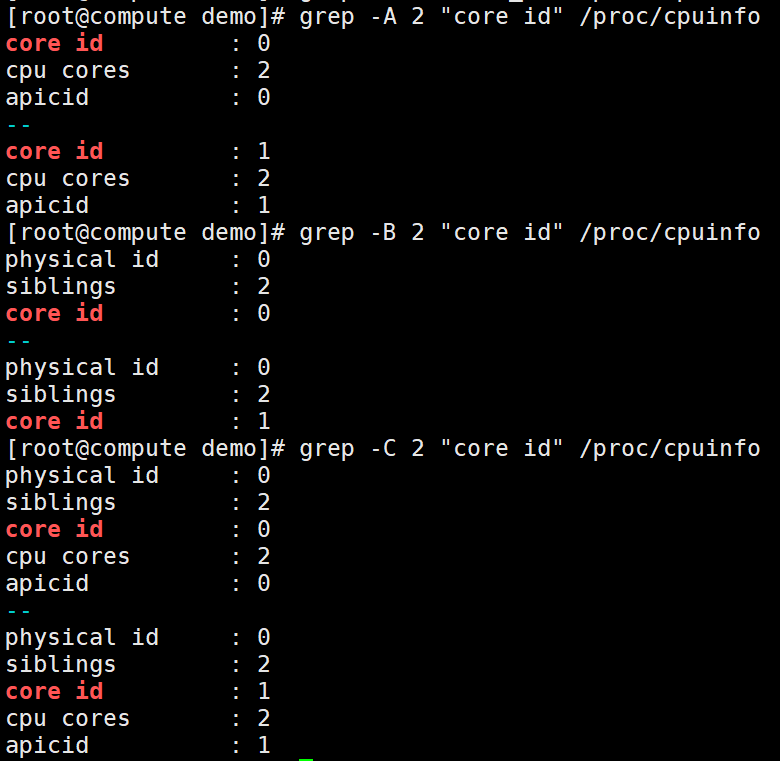
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
-E :开启扩展(Extend)的正则表达式。
示例:
搜索词:
1、直接输入要搜索的字符串,此时可以用fgrep(fast grep)来代替以提高查找速度,比如我要匹配一下hello.c文件中printf的个数:grep -c "printf" hello.c
2、使用正则表达式描述搜索词,下面谈关于基本正则表达式的使用:
字符匹配:
. :任意一个字符。
[abc] :表示匹配一个字符,这个字符必须是abc中的一个。
[^123] :反向匹配,这个字符不能是1、2、3中的任意一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
对于一些常用的字符集,系统做了定义:
[A-Za-z] 等价于 [[:alpha:]]
[0-9] 等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z] 等价于 [[:upper:]]
[a-z] 等价于 [[:lower:]]
标点符号 [[:punct:]]

次数匹配:
x{m}:m 个连续的字符x
x{m,}:m个以上连续的字符x
x{m,n}:m~n个连续的字符x
x*:连续任意个字符x,例如: /[abc] */表示abc中任意字符的若干次
位置匹配:
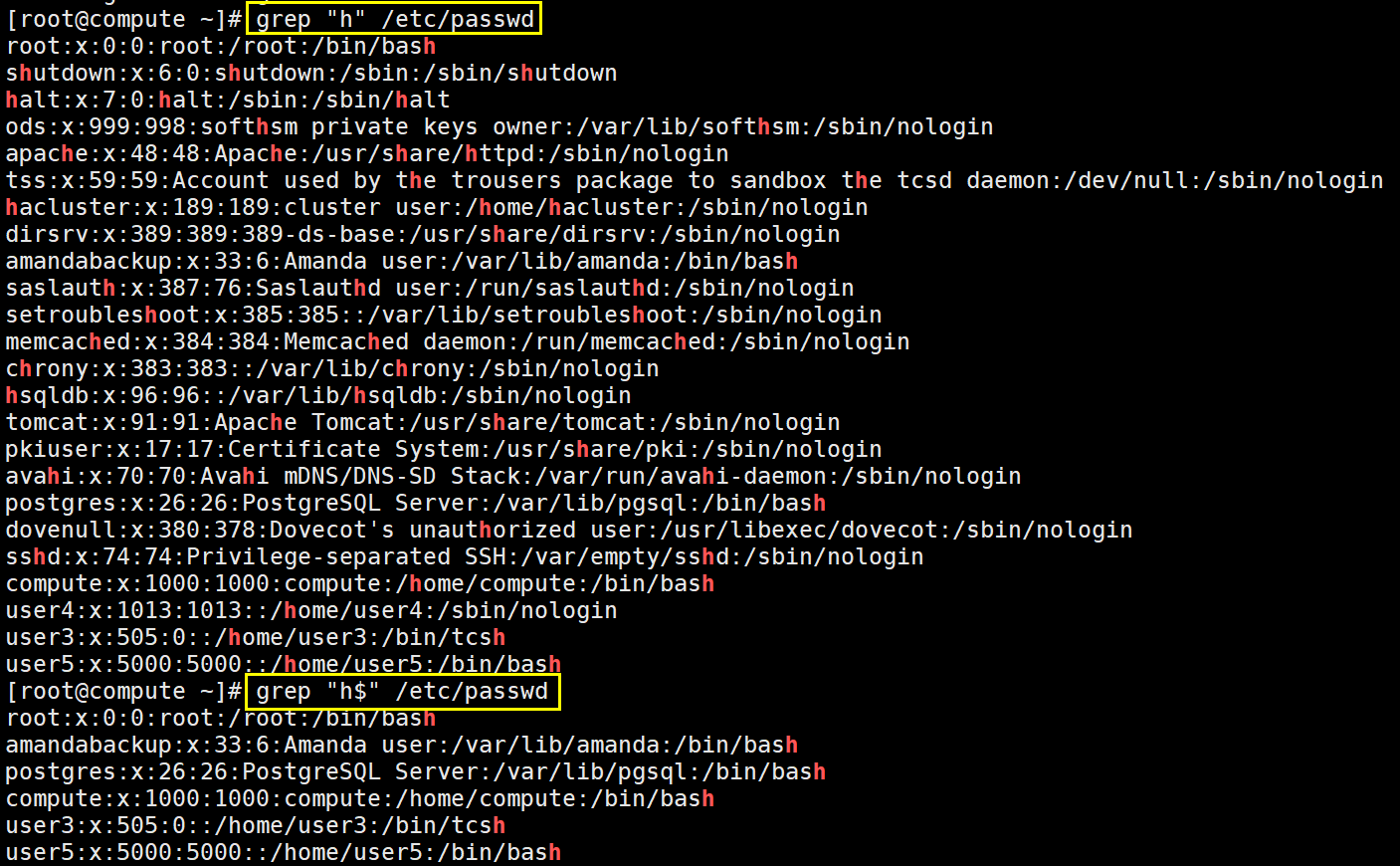
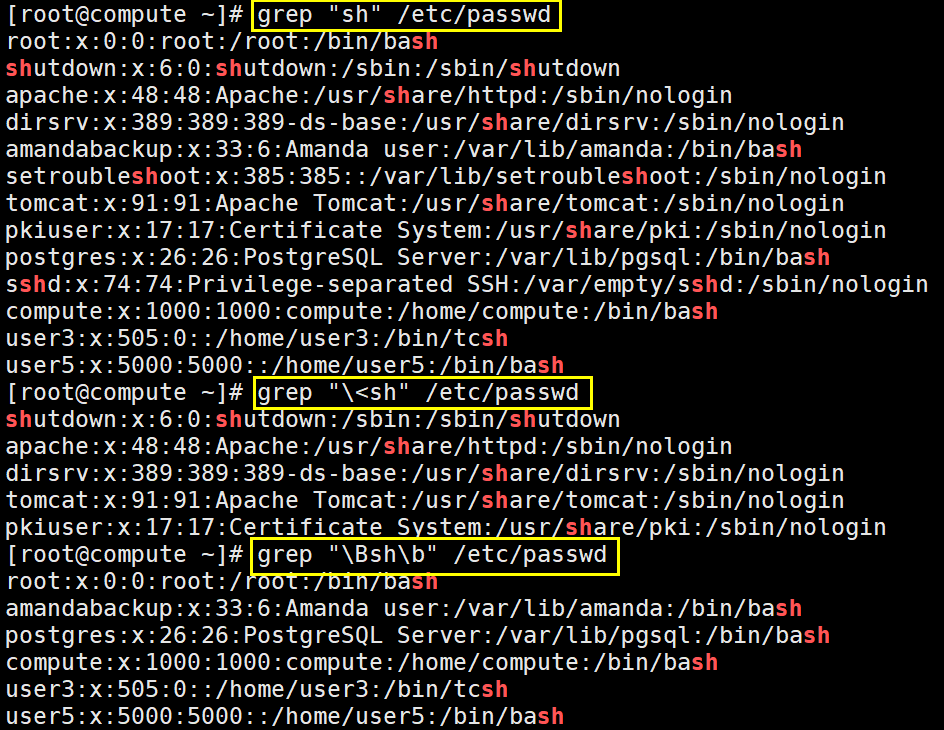
^ :行首匹配
$ :行尾匹配。技巧:"^$"用于匹配空白行。
<待匹配的字符串:词首匹配。如"<like"不会匹配alike,但是会匹配liker
待匹配的字符串>:词尾匹配。如"like>"不会匹配liker,只会匹配alike
本博客参照与:linux中grep命令的用法